 一種基于機器視覺和深度學習的智能路牌識別系統
一種基于機器視覺和深度學習的智能路牌識別系統
摘要:提出了一種基于機器視覺和深度學習的智能路牌識別系統。采用嵌入式的ARM9作為前端采集系統,在服務器上采用圖像處理算法先對前端采集的路牌圖像進行文字區域的提取和分割,然后用訓練好的卷積神經網絡對分割的文字進行識別,最后將識別信息以語音的形式反饋給使用者。使用前端硬件在高速公路上采集路牌圖像并在服務器的CAFFE框架上進行測試,結果表明該系統能實時準確地將路牌信息以語音的方式播報給使用者。
0 引言
隨著社會的快速發展,現今的生活中,汽車已經成為主要的交通工具,路牌也成為一種重要的導航工具。無論是高速公路還是國道、省道,到處都樹立著路牌。然而,由于路牌常常被豎立在路的兩邊,當司機需要了解路旁路牌的信息時,注意力很容易被分散,當駕駛者對自己所在道路不熟悉的時候,前方路況和各種標志的路牌會讓駕駛者的心里壓力變大,駕駛者由于減速觀看路牌很容易發生交通堵塞和交通事故,使得交通狀況變得更加惡劣。對此,國內外一些研究學者對路牌的識別進行了研究[1],但效果不是很理想,將路牌識別系統實現的更是少之又少。智能路牌識別系統能有效地提取路牌信息,幫助駕駛者理解路牌的信息,對于安全駕駛有著極其重要意義,對將來智能駕駛戰略也將做出突出的貢獻。
1 智能路牌識別控制系統的總體設計
本系統由基于嵌入式技術的前端采集、通信傳輸系統和遠程云服務器識別系統組成。前端采集傳輸采用基于三星Cortex-A9架構的核心板,配備一千萬像素攝像頭、語音播報模塊和4G通信模塊構建智能路牌識別系統的硬件平臺。攝像頭采集含有路牌的圖像,由主控芯片對圖像進行壓縮,壓縮后的圖像在4G模塊下通過SOCKET程序傳送到云服務器上。采用云平臺服務器作為智能路牌識別器的數據處理中心,在服務器上通過深度學習算法訓練文字識別網絡,將分割后的圖像在訓練好的網絡上進行識別,然后將得到的結果傳輸到前端,通過語音模塊播報給使用者。智能路牌識別器的總體設計如圖1所示。
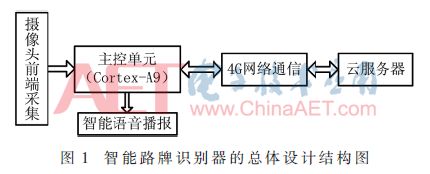
2 智能路牌識別控制系統的硬件設計
2.1 主控單元模塊
該模塊采用ARM9核心的處理器作為中央控制單元模塊,用它實現對前端采集系統各個單元模塊所采集的數據信息進行匯總分析和處理,對各個功能模塊發出控制指令,協調整個系統穩定運行。中央控制單元完成圖像采集,根據預先板載的壓縮算法程序完成圖像壓縮,通常可達到6:1的壓縮率,并發給云服務器,減小了傳輸時間,保證了信息傳輸的實時性。中央控制單元同時接收來自云服務器發送的識別結果,并將結果通過語音模塊反饋給使用者。
2.2 前端采集模塊
前端采集采用的是一千萬像素的CMOS高清攝像頭,它能夠清晰地拍攝前方場景信息,用于智能路牌識別系統對路牌信息的采集。得到的高清圖片存儲在中央控制單元,并由中央控制單元對其進行處理。
2.3 無線通信模塊
無線通信模塊由外圍電路和4G通信芯片構成,使用SOCKET通信和4G通信技術,完成智能路牌識別系統和云端服務器的相互連接。在中央處理器模塊的控制下,前端采集壓縮的圖片在無線通信模塊的作用下發送給云端服務器,同時云端服務器將處理完成的信息通過無線傳輸模塊發送給中央控制單元,把結果實時反饋給使用者。
2.4 語音文字播報模塊
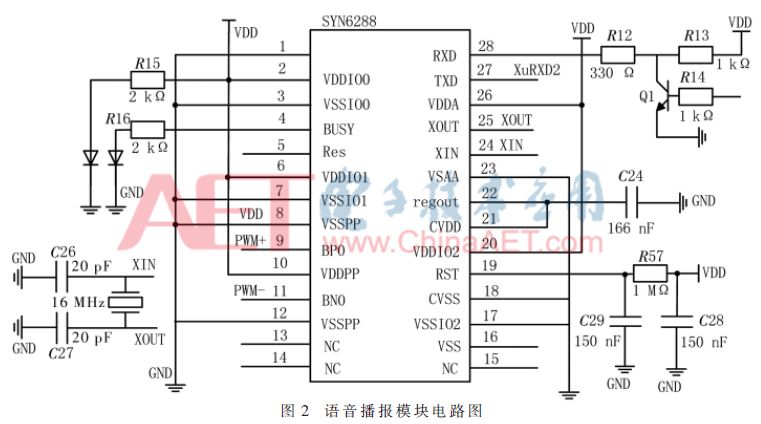
語音播報模塊主要作用是將云端服務器處理的路牌文字信息以語音播報的形式展現給駕駛者,使得駕駛者不用因環顧四周的路牌文字而分心。該模塊主要采用SYN6288中文語音合成芯片實現對語音文字的播報,把云端服務器發送的文本文字轉化為音頻信息。SYN6288語音芯片采用UART和SPI兩種通信方式,實現文本智能分析處理、多音字處理功能。該模塊的電路如圖2所示。
3 智能路牌識別控制系統的軟件設計
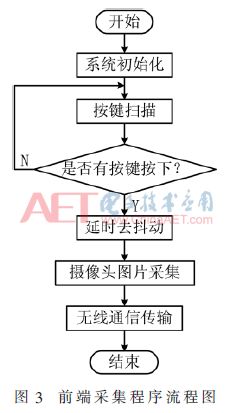
本系統軟件的設計由兩部分組成。一部分是前端ARM9加載Linux系統的設計,完成前端信息的采集壓縮、云端服務器通信和語音播報的功能。前端采集程序流程圖如圖3所示。
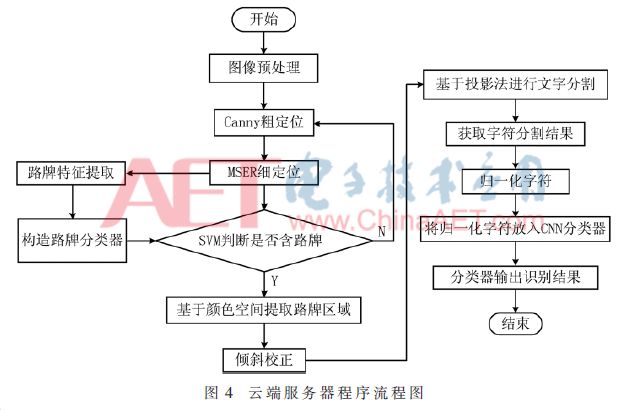
另一部分是在云端服務器上實現對采集圖像的預處理、檢測、分割和分類識別功能。云端服務器首先對前端發送的圖像解壓縮、預處理,利用支持向量機(SVM)算法檢測是否含有路牌。檢測到路牌之后對路牌區域進行提取,對提取后的路牌進行圖像處理,然后利用投影法對文字進行分割,最后進行文字識別。其中文字識別部分采用的是目前流行的深度學習框架——CAFFE框架,主要采用C++/CUDA高級語言來實現對深度學習網絡的訓練和文字的識別。云端服務器程序流程圖如圖4所示。
4 基于卷積神經網絡的文字識別算法
卷積神經網絡(CNN)是深度學習領域的一個重要算法,在很多應用上表現出卓越的效果[2-3]。目前字符識別算法有很多種,但對漢字的識別,特別是自然場景的文字識別都有一定的局限[4-5]。將多種文檔字符識別算法與CNN比較,會發現CNN算法比其他算法的效果都好。在本文的智能路牌識別系統中,主要利用CNN對日常生活中常見的3 000個漢字進行訓練然后識別。CNN是在BP神經網絡的結構上改進得到的,它們都是采用了向前傳播計算網絡的輸出值,通過誤差計算公式,向后傳播修正權重和偏置的值。與傳統的特征提取方法相比,CNN最大的改進就是卷積神經網絡是利用卷積核進行特征提取,相鄰層之間不是全連接,而只是部分進行連接,從而得到局部特征。在一個特征平面采用權值共享機制,很大程度上減少了權值的數量。
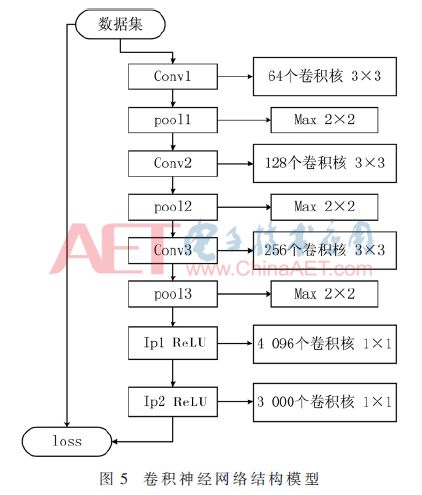
本文設計的網絡結構如圖5所示,輸入的數據為一張40×40像素的圖片,第一層為卷積層,由64個3×3卷積核組成,每個卷積核都各自提取不同的一種特征,通過輸入與卷積核運算來提取圖像的局部特征。然后進入池化層,在2×2的窗口中選取最大值作為一個輸出值,從而降低了數據維度。以此類推,計算第二層128個卷積核和第三層256個卷積核的卷積運算。全連接層分別采用4 096和3 000個1×1的卷積核進行全連接來提取圖片文字的全局特征進行分類。然后根據誤差輸出公式進行誤差計算,反向進行權值和偏置更新。為了防止過擬合,采用dropout對網絡權值和偏置進行部分更新。反復進行計算多次實現對網絡參數進行訓練的目的。
在智能路牌識別系統中,挑選日常常用的3 000個漢字進行了訓練,基于國家標準規定——道路路牌采用方正黑體格式漢字,實驗中通過計算機生成了相應圖像數據。利用C#語言生成40像素×40像素的漢字圖片作為測試集和訓練集,如圖6所示。
考慮到前端采集模塊在實際采集圖片時會出現各種干擾,如硬件發熱、外界環境干擾、光線的亮暗等因素的影響,使得圖像帶有噪聲點、圖片模糊、字跡不清或者產生旋轉和扭曲等狀況,因此,需將生成的每個漢字圖像進行圖像處理,分別對其進行各種隨機的噪聲點生成、腐蝕膨脹以及不同角度的旋轉和扭曲。這樣對每一個漢字圖片產生300張不同的圖片,獲得了更多的數據量,這樣測試集和訓練集一共有900 000個數據。通過圖5所示的卷積神經網絡進行訓練。
5 系統的測試與分析
由于現在路牌場景種類繁多,測試實驗中采用比較規范、應用比較多、文字方向從左自右的路牌進行實驗。如圖7(a)所示,對前端發送到服務器的圖像,先通過Canny算子邊緣檢測粗定位和MSER算法細定位,使用SVM算法來判斷是否含有路牌,判斷出路牌標識后對圖像進行路牌區域提取。
路牌區域提取采用基于HSI顏色空間的方法。基于我國以綠底和藍底作為路牌的背景,采用HSI空間中的H分量將路牌區域提取出來。本實驗將H參數設定在[150,190]區間,得出實驗結果如圖7(b)所示。
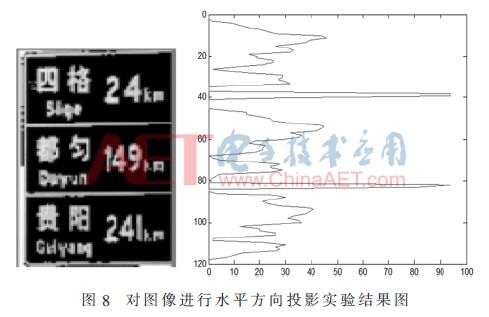
在文字檢測部分,采用Canny算子進行邊緣檢測[6],提取漢字的邊緣,然后用形態學對漢字進行處理,將文字與文字分開同時將文字的各個部分進行連接,以便于進行文字分割。在文字分割部分,采用投影法,根據像素值的特征進行分割。首先對路牌進行二值化處理,先進行水平投影像素值相加,進行行分割,分割效果如圖8所示。
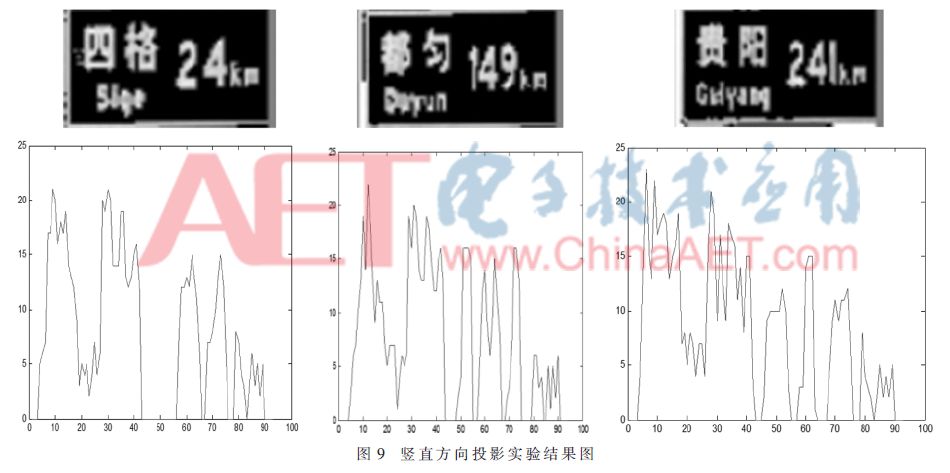
然后豎直方向投影進行像素值相加,進行豎直方向分割,分割效果如圖9所示。通過連通區域算法分析得到各個文字區域,最后歸一化為40像素×40像素圖像,送入深度學習卷積神經網絡進行分類識別。
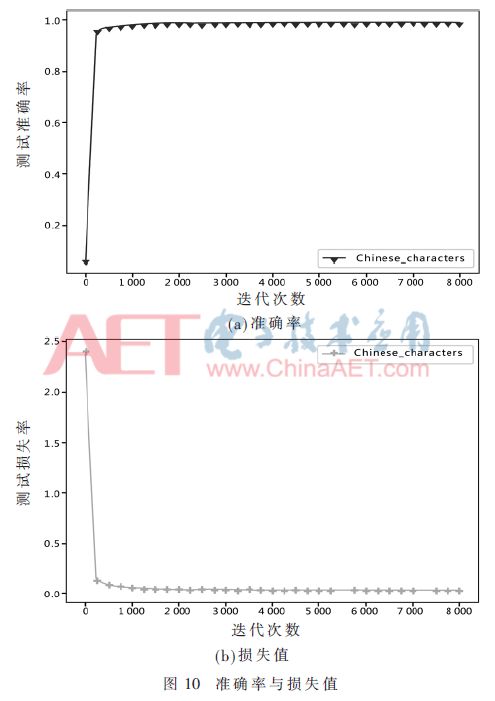
采用本實驗設計的網絡結構,將數據集的800 000個數據作為訓練集,100 000個數據集作為測試集,在云服務器上迭代8 000次,得到99%的準確率,測試的準確率和損失值如圖10所示,當迭代次數達到900次左右時,準確率趨于平穩,由此可見CNN在路牌漢字識別上具有優勢和潛在的應用價值。
6 結論
本文完成了智能路牌識別系統從硬件到軟件的設計,實現了硬件的圖像采集壓縮和軟件的圖像處理、區域檢測和文字分割,最后通過語音模塊播報給使用者的功能。該系統對駕駛者有十分重要的作用,并可運用在無人駕駛領域,對新世紀的智能交通也將做出突出的貢獻。本文系統未考慮前端動態拍攝時的模糊圖像處理問題,即當車輛行駛太快情況下,前端采集的圖像可能會不清晰,這也是下一步將努力的方向。
-
機器視覺
+關注
關注
162文章
4396瀏覽量
120476 -
嵌入式技術
+關注
關注
10文章
360瀏覽量
36355 -
深度學習
+關注
關注
73文章
5510瀏覽量
121330
原文標題:【學術論文】基于深度學習的智能路牌識別系統設計
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求一種非接觸式3D指紋識別系統的設計方案
什么是人工智能、機器學習、深度學習和自然語言處理?
智能車目標識別系統的設計實現資料推薦
英特爾發布了RealSense ID 開發了一種面部識別系統
基于視覺的手勢識別系統的設計與研究






 工商網監
工商網監
評論