

編者按:物理學碩士、深度學習開發者Artem Oppermann介紹了受限玻爾茲曼機的原理。近幾年來,隨著受限玻爾茲曼機在協同過濾上的大放異彩,這一基于能量的神經網絡很受歡迎。
0. 導言
受限玻爾茲曼機(RBM)是一種屬于能量模型的神經網絡。本文的讀者對受限玻爾茲曼機可能不像前饋神經網絡或卷積神經網絡那樣熟悉。然而,隨著RBM在Netflix Prize(知名的協同過濾算法挑戰)上大放異彩(當前最先進的表現,擊敗了大多數競爭者),最近幾年這類神經網絡很受歡迎。
1. 受限玻爾茲曼機
1.1 架構
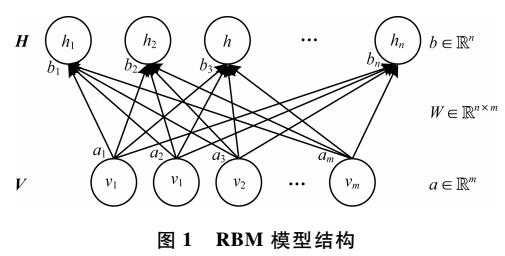
在我看來,RBM是所有神經網絡中最簡單的架構之一。如下圖所示,一個受限玻爾茲曼機包含一個輸入層(v1, ..., v6),一個隱藏層(h1, h2),以及相應的偏置向量a、b. 顯然,RBM沒有輸出層。不過之后我們會看到,RBM不需要輸出層,因為RBM進行預測的方式和通常的前饋神經網絡不同。
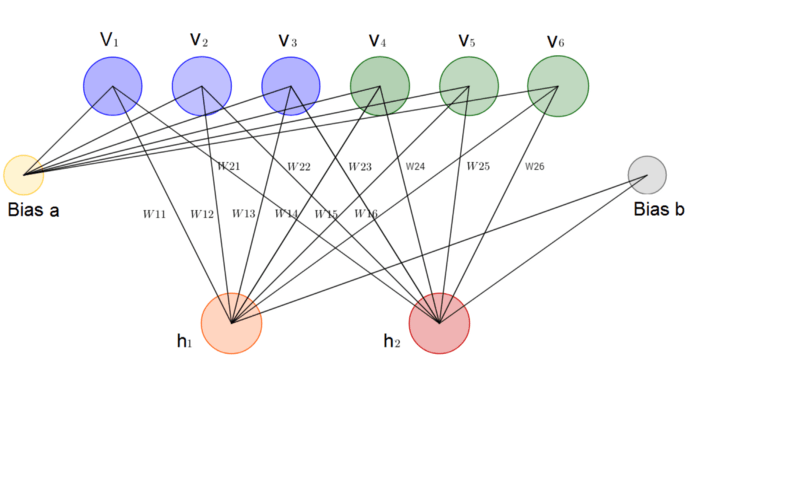
1.2 能量模型
乍看起來,能量這一術語和深度學習沒什么關系。相反,能量是一個物理概念,例如,重力勢能描述了具有質量的物體因重力而具有的相對其他質量體的潛在能量。不過,有些深度學習架構使用能量來衡量模型的質量。
深度學習模型的目的之一是編碼變量間的依賴關系。給變量的每種配置分配一個標量作為能量,可以描述這一依賴關系。能量較高意味著變量配置的兼容性不好。能量模型總是嘗試最小化一個預先定義的能量函數。
RBM的能量函數定義為:
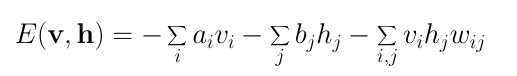
由定義可知,能量函數的值取決于變量/輸入狀態、隱藏狀態、權重和偏置的配置。RBM的訓練包括為給定的輸入值尋找使能量達到最小值的參數。
1.3 概率模型
受限玻爾茲曼機是一個概率模型。這一模型并不分配離散值,而是分配概率。在每一時刻RBM位于一個特定的狀態。該狀態指輸入層v和隱藏層h的神經元值。觀察到v和h的特定狀態的概率由以下聯合分布給出:
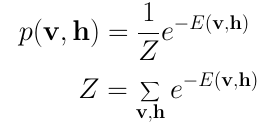
這里Z被稱為配分函數(partition function),該函數累加所有輸入向量和隱藏向量的可能組合。
這是受限玻爾茲曼機和物理學第二個相遇的地方。在物理學中,這一聯合分布稱為玻爾茲曼分布,它給出一個微粒能夠在能量E的狀態下被觀測到的概率。就像在物理中一樣,我們分配一個觀測到狀態v和h的概率,這一概率取決于整個模型的能量。不幸的是,由于配分函數Z中v和h所有可能的組合數目十分巨大,計算這一聯合分布十分困難。而給定狀態v計算狀態h的條件概率,以及給定狀態h計算狀態v的條件概率則要容易得多:
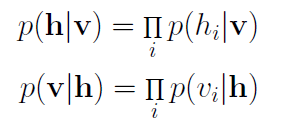
RBM中的每個神經元只可能是二元狀態0或1中的一種。我們最關心的因子是隱藏層或輸入層地神經元位于狀態1(激活)的概率。給定一個輸入向量v,單個隱藏神經元j激活的概率為:
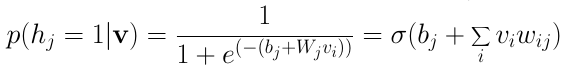
其中,σ為sigmoid函數。以上等式可由對之前的條件概率等式應用貝葉斯定理推導得出,這里不詳細介紹其中的推導過程。
類似地,單個輸入神經元i為1的概率為:
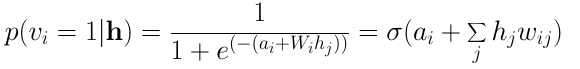
2. 基于受限玻爾茲曼機實現協同過濾
2.1 識別數據中的潛在因子
讓我們假定,我們找了一些人,讓他們給一批電影打分(一星到五星)。在經典因子分析背景下,每部電影可以通過一組潛在因子來解釋。例如,《哈利波特》和《速度與激情》可能分別與奇幻、動作這兩個潛在因子有密切的關系。另一方面,喜歡《玩具總動員》和《機器人總動員》的用戶可能和皮克斯這個潛在因子密切相關。RBM可以用來分析和找出這些潛在因子。經過一些epoch的訓練,神經網絡多次見到數據集中的每個用戶的所有評分。此時模型應該已經基于用戶的偏好和所有用戶的協同口味學習到了隱藏的潛在因子。
隱藏因子分析以二元的方式進行。用戶并不向模型提交具體的評分(例如,一到五星),而是簡單地告知喜歡(評分為1)還是不喜歡(評分為0)某部特定的電影。二元評分值表示輸入層的輸入。給定這些輸入,RBM接著嘗試找出數據中可以解釋電影選擇的潛在因子。每個隱藏神經元表示一個潛在因子。給定一個包含數以千計的電影的大規模數據集,我們相當確定用戶僅僅觀看和評價了其中一小部分電影。另外,有必要給尚未評分的電影分配一個值,例如,-1.0,這樣在訓練階段網絡可以識別未評分的電影,并忽略相應的權重。
讓我們看一個例子。一個用戶喜歡《指環王》和《哈利波特》,但不喜歡《黑客帝國》、《搏擊俱樂部》、《泰坦尼克》。用戶還沒有看過《霍比特人》,所以相應的評分為-1. 給定這些輸入,玻爾茲曼機可能識別出三個對應電影類型的隱藏因子戲劇、奇幻、科幻。
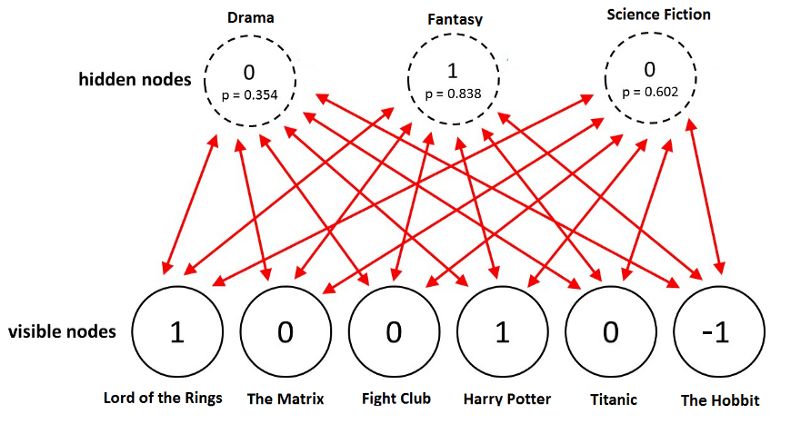
給定電影,RBM為每個隱藏神經元分配一個概率p(h|v)。使用概率p從伯努利分布中取樣得到最終的神經元的二元值。
在這個例子中,只有表示類型奇幻的隱藏神經元被激活。給定這些電影評分,受限玻爾茲曼機能夠正確識別用戶最喜歡奇幻類型的電影。
2.2 將潛在因子用于預測
訓練之后,我們的目標是預測沒看過的電影的二元評分。給定特定用戶的訓練數據,網絡能夠基于用戶的偏好識別潛在因子。由于潛在因子由隱藏神經元表示,我們可以使用p(v|h)從伯努利分布取樣,以找出哪個輸入神經元處于激活狀態。
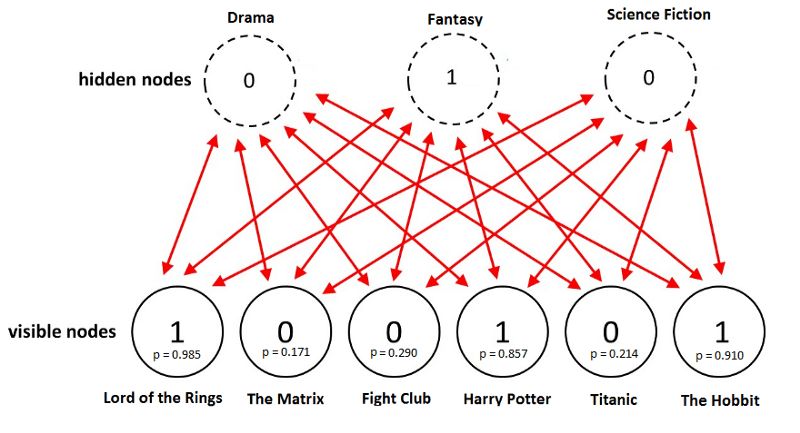
上圖中,網絡成功地識別出奇幻為用戶偏愛的電影類型,并預測用戶會喜歡《霍比特人》。
總結一下,從訓練到預測的全過程如下:
基于所有用戶的數據訓練網絡。
在推理時刻,獲取某個特定用戶的訓練數據。
基于這一數據得出激活的隱藏神經元。
基于隱藏神經元的值得出激活的輸入神經元。
輸入神經元的新值顯示了用戶將對沒看過的電影作出的評價。
3. 訓練
受限玻爾茲曼機的訓練過程和基于梯度下降的常規神經網絡的訓練過程不同。本文不會詳細介紹具體的訓練過程(感興趣的讀者可以閱讀受限玻爾茲曼機的原始論文),相反,我們將簡單地概覽一下其中的兩個主要的訓練步驟。
3.1 吉布斯采樣
訓練的第一個關鍵步驟稱為吉布斯采樣(Gibbs Sampling)。給定輸入向量v,我們使用前面提到的p(h|v)公式預測隱藏值h。得到了隱藏值之后,我們又使用前面提到的p(v|h)公式預測新輸入值v。這一過程輾轉重復k次。經過k個迭代后,我們得到了輸入向量vk,這是基于原始輸入值v0的重建值。
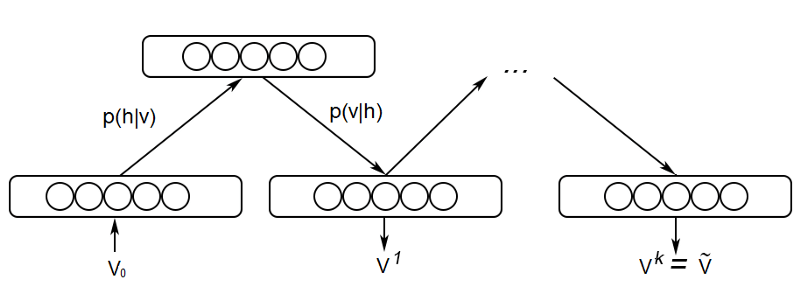
3.2 對比發散
在對比發散(Contrastive Divergence)這一步驟中,模型更新權重矩陣。使用向量v0和vk計算隱藏值h0和hk的激活概率。這些概率的外積和輸入向量v0、vk的差別為更新矩陣(update matrix):
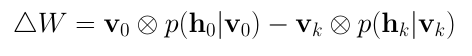
基于更新矩陣,使用梯度上升(gradient ascent)方法更新權重:

-
神經網絡
+關注
關注
42文章
4793瀏覽量
102028 -
深度學習
+關注
關注
73文章
5536瀏覽量
122196
原文標題:深度學習邂逅物理:受限玻爾茲曼機原理解析
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于能量模型的神經網絡架構受限玻爾茲曼機

用實驗證明,二極管PN結中的玻爾茲曼常數
絕對干貨!HarmonyOS開發者日資料全公開,鴻蒙開發者都在看
HDC 2022 開發者主題演講與技術分論壇干貨分享(附課件)
稀疏受限玻爾茲曼機研究綜述
關于機器學習的15大框架分析
深度學習的機會網絡鏈路預測
融入受限玻爾茲曼機的偏最小二乘優化方法
人工智能機器學習之受限玻爾茲曼機(RBM)算法
快速了解神經網絡與深度學習的教程資料免費下載





 工商網監
工商網監

評論