 衛星圖像進行目標識別仍然困難重重,美國提出了一種方法
衛星圖像進行目標識別仍然困難重重,美國提出了一種方法
編者按:CV中的目標物體識別進步非常快,但是想對衛星圖像進行目標識別仍然困難重重。美國研究者就提出了一種方法——You Only Look Twice,能清晰地看到衛星圖像中的汽車、飛機場上的飛機及建筑物,并開放了代碼(見文末)。以下是論智帶來的編譯。
在大范圍圖像中對小目標進行檢測是衛星圖像分析的主要問題。雖然深度學習方法為基于地面的目標檢測提供了許多方法,將這種技術轉化為圖片是非常重要的步驟。其中最大的挑戰就是所有像素的數量和每張圖片的地理內容:一張DigitalGlobe(美國的一家商業空間圖像和地理空間內容提供商,并操控數臺遙感航天器)衛星圖片涵蓋了64m2以上的土地,有超過2.5億個像素。另一個挑戰是,我們想要觀察的對象物體非常小(經常在10像素左右),這對傳統的計算機視覺技術來說是一項很復雜的任務。為了解決這個問題,我們提出了一個流程,即“You Only Look Twice”(只需看兩眼),它能以每秒大于0.5平方米的速度對衛星圖像進行評估掃描,可以快速地在不同范圍內對目標物體進行檢測,同時只需較少的訓練數據。我們在圖片的原始分辨率下對圖片進行評估,同時生成的車輛定位F1分數大于0.8。之后我們又系統地測試了降低分辨率和目標物體尺寸后的效果,最后得出當尺寸降至5像素時,系統的識別率仍然很高。
遇到的挑戰
深度學習方法在傳統目標檢測上的應用是非常重要的。而衛星圖像的特殊性使能夠解決空間前景內容、能進行旋轉變換以及大范圍搜索的算法成為必要的。除了安裝細節,算法還必須滿足以下四個條件:
小空間范圍(small spatial extent):與ImageNet數據集中的清晰大圖不同,衛星圖像中的目標物體通常很小,并且分布較密集。在衛星成像領域,分辨率通常被定義為“地面采樣距離(GSD)”,它描述了一個像素的實際距離。商業用途的圖像尺寸在DigitalGlobe的30厘米GSD到衛星成像的3—4米GSD左右。這意味著,即使在最高的分辨率下,汽車之類的小目標也只有15像素左右大小。
完全的旋轉不變性(rotation invariance):從空中看到的物體可能會有各種朝向。比如,船行進的方向可能有許多中,但是像ImageNet中的大樹卻總是垂直的。
訓練樣本頻率(training example frequency):訓練數據相對不足。
極高分辨率(ultra high resolution):輸入的圖像非常大,常常有百萬像素。所以簡單地對輸入圖像尺寸進行下采樣不合適。
DigitalGlobe在巴拿馬運河附近拍攝的8×8km(約16000×16000像素)的圖像,GSD為50cm。紅框表示416×416像素大小的區域
You Only Look Twice
為了解決模型無法檢測像素過小的目標、難以生成全新比例的圖像等限制,我們提出了一種經過優化的為衛星圖像目標檢測框架:You Only Look Twice(YOLT)。我們擴展了Darknet神經網絡框架,同時更新了一些C函數庫一共地理空間圖像分析,并且整合了外部Python庫。我們選擇Python用戶社群來進行預處理和后處理。在更新完C代碼和進行預處理和后處理之間,參與者無需對C有深入了解。
網絡結構
為了減少模型的粗糙度同時增強檢測密集物體時的精確度,我們所使用的是一個具有22層的網絡,并且以16為系數進行降采樣。所以輸入一張416×416像素的圖片會生成一個26×26的網格。該網絡受30層的YOLO啟發,經過優化后專為檢測小型密集對象。密集網格對散布型場景(如機場)可能不太重要,但是對高密度場景(如停車場)非常重要。
空中成像的目標物體檢測對標準網絡架構的挑戰。兩張圖片來自統一數據集。左圖中的模型將4000×4000像素的測試圖像降采樣到416×416,圖中共有1142輛車,沒有一輛被識別出來。右圖中的模型同樣是416×416,漏報率過多是由于車輛密度太大,13×13的網格無法將它們分辨出來
為了提高模型識別小物體的準確度,我們還加入了一個穿透層,與最后的52×52圖層連接起來成為最后的卷積層,可以讓探測器獲得擴展后的特征向量更細微的特征。
測試過程
在測試時,我們將不同尺寸的測試圖片分割成可操作的小圖,并將每個小圖在訓練過的模型上進行實驗。如下圖所示:
測試過程是從左圖移動到右圖,重疊部分在右下圖中用紅色表示。重疊部分的非極大抑制對于改善小圖邊緣的目標檢測是非常有必要的
許多衛星成像的性能都依賴于其內部拍攝全局大圖的能力。所以,小型圖像芯片遠不如由衛星平臺自己拍攝的大型圖像。物體檢測的最后一步就是將成百上千張測試芯片連接到最后的圖像層中。
目標檢測結果
最初,我們想只訓練一個分類器,讓其能夠辨認交通工具、基礎設施等許多種類的物體。但是結果并不理想,在對機場的識別中,我們發現這樣的結果:
這一通用模型產生了較差的結果。檢測到的飛機被紅框圈起來,可以看到還有幾架被遺漏。另外藍框內是被模型誤解的“跑道”
要解決這一問題,我們試著利用衛星成像中的規模信息,運行兩個不同的分類器:一個用于識別交通工具和建筑,另一個用來檢查機場。第一種分類器的尺寸為200m,第二種為2500m。我們將測試照片分成合適尺寸的小圖,然后將每張小圖輸入到分類器中。最終將多個分類器的結果結合成最后一張圖像,我們發現檢測率在0.3和0.4之間的生成的F1分數最高。以下是目標檢測器在各個類別下的表現:
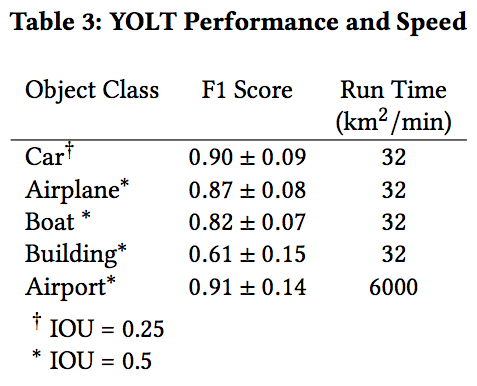
可以看到,YOLT在機場、飛機和船幾個類別中表現得很好
細節表現分析
接著,我們在COWC數據集上測試了YOLT對汽車的檢測結果,下圖是在每個場景中模型的F1分數以及對汽車數量計算的精確度:
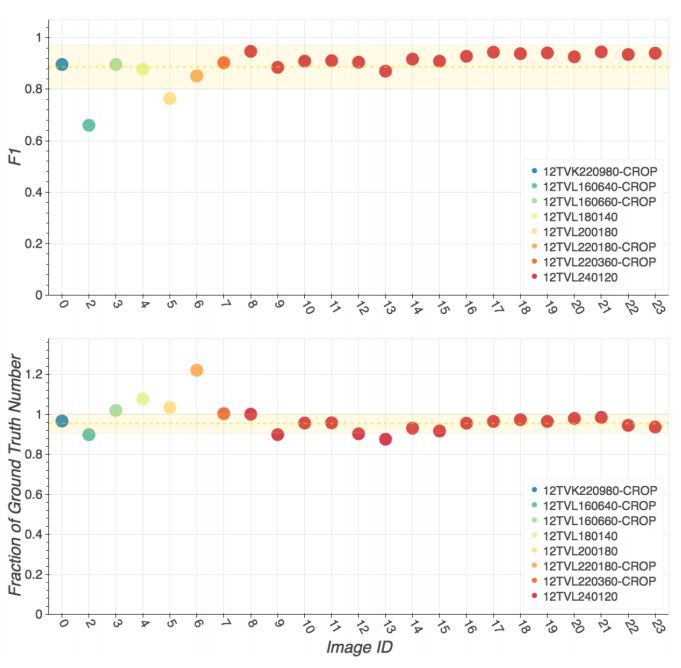
上面的圖示COWC中每個測試場景的F1分數,下面的圖是將檢測次數作為標準數值的一部分
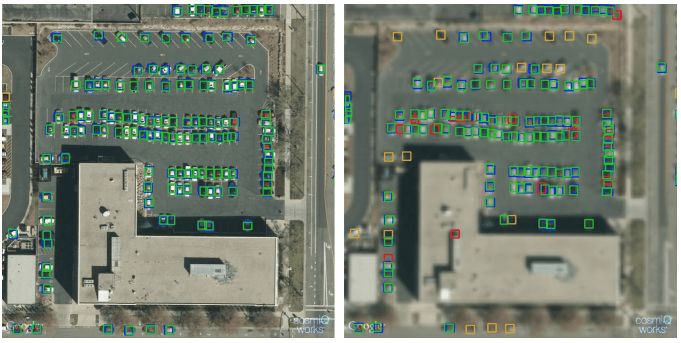
不同分辨率下的目標檢測。左圖的GSD為15cm,F1分數為0.94。右圖的GSD為90cm,F1分數為0.84
結語
目標檢測算法在定位類似ImageNet數據集中的圖片上取得了巨大進步,但是這類算法通常不適合用于衛星圖片中的目標檢測。為了解決這一限制,我們提出了一種完全卷積的神經網絡模型(YOLT),它能快速定位衛星圖片中的汽車、建筑和機場。最終的F1分數從0.6到0.9不等,取決于不同的檢測種類。代碼目前已在GitHub上開放.
-
神經網絡
+關注
關注
42文章
4776瀏覽量
100945 -
數據集
+關注
關注
4文章
1208瀏覽量
24748 -
深度學習
+關注
關注
73文章
5510瀏覽量
121334
原文標題:“只需看兩次”——對衛星圖像進行快速目標識別的新方法
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于圖像平移的目標檢測框架
一種適用于空間觀測任務的實時多目標識別算法分享
基于USB和目標識別的圖像采集系統的設計實現
軍事假目標識別的新方法
基于SIFT視覺詞匯的目標識別算法
基于擴展字典稀疏表示分類的遙感目標識別
基于8片TMS320C6416的衛星圖像目標提取高速處理系統

機器視覺的圖像目標識別方法綜述






 工商網監
工商網監
評論