") 一種無(wú)需監(jiān)督的目標(biāo)追蹤新方法——給視頻上色
一種無(wú)需監(jiān)督的目標(biāo)追蹤新方法——給視頻上色
追蹤視頻中的對(duì)象目標(biāo)是計(jì)算機(jī)視覺的基本問題,這對(duì)于動(dòng)作辨識(shí)、目標(biāo)對(duì)象交互或者視頻風(fēng)格化等應(yīng)用非常重要。然而,教機(jī)器在視覺上追蹤物體是非常有挑戰(zhàn)性的,因?yàn)樗枰笮偷摹⒈粯?biāo)記的數(shù)據(jù)集進(jìn)行訓(xùn)練,但是這些跟蹤數(shù)據(jù)無(wú)法大規(guī)模標(biāo)記。論智君昨天在六種人體姿態(tài)估計(jì)的深度學(xué)習(xí)模型和代碼總結(jié)一文中談到了對(duì)人體姿態(tài)估計(jì)的方法,感興趣的讀者可以閱讀一下。
今天,谷歌AI博客發(fā)表文章,稱他們找到了一種無(wú)需監(jiān)督的目標(biāo)追蹤新方法——給視頻上色。在之前的Tracking Emerges by Colorizing Videos一文中,谷歌研究者介紹了一種卷積神經(jīng)網(wǎng)絡(luò),它可以給灰度視頻上色,但是無(wú)法從單個(gè)參照系中復(fù)制顏色。為了達(dá)到這一目的,這次提出的的網(wǎng)絡(luò)學(xué)會(huì)了如何在沒有監(jiān)督的情況下自動(dòng)對(duì)目標(biāo)物體進(jìn)行視覺追蹤。重要的是,雖然模型不能直接訓(xùn)練用于追蹤,但它可以跟蹤多個(gè)物體,同時(shí)在圖形變換上能保持較高的魯棒性,并且不需要任何標(biāo)記過(guò)的訓(xùn)練數(shù)據(jù)。以下是論智對(duì)原文的編譯。
上圖是在DAVIS 2017數(shù)據(jù)集上的追蹤預(yù)測(cè)示例。學(xué)會(huì)給視頻上色后,一種用于追蹤的機(jī)制就自動(dòng)出現(xiàn),不需要監(jiān)督。我們?cè)诘谝粠貌煌伾珮?biāo)出了需要識(shí)別的對(duì)象,之后模型不需要學(xué)習(xí)或監(jiān)督就可以在接下來(lái)的視頻中自動(dòng)延續(xù)需要上色的部分。
學(xué)習(xí)對(duì)視頻重新上色
我們假設(shè),只在第一幀顯示出的顏色可以提供大量訓(xùn)練數(shù)據(jù),能讓機(jī)器學(xué)習(xí)在視頻中追蹤所選定的區(qū)域。顯然,有些情況下,顏色會(huì)暫時(shí)變得不連貫,比如光線突然改變,但是總體來(lái)說(shuō),顏色是穩(wěn)定的。另外,大多數(shù)視頻帶有顏色,同時(shí)還有大量的自監(jiān)督學(xué)習(xí)信號(hào)。我們對(duì)視頻去顏色化,在給它們上色,是因?yàn)榭赡芏鄠€(gè)物體的顏色都相同,但是通過(guò)上色,我們可以教機(jī)器追蹤具體的物體或區(qū)域。
為了訓(xùn)練我們的系統(tǒng),我們用的是Kinestics數(shù)據(jù)集中的視頻,該數(shù)據(jù)集中的視頻記錄的大多是日常活動(dòng)。我們把視頻中除了第一幀之外的所有幀都轉(zhuǎn)換成了灰調(diào),并訓(xùn)練一個(gè)卷積網(wǎng)絡(luò)預(yù)測(cè)原本的顏色。我們希望模型學(xué)習(xí)如何追蹤區(qū)域,從而能準(zhǔn)確地復(fù)原顏色。我們主要的關(guān)注點(diǎn)在于,跟蹤物體將會(huì)讓模型自動(dòng)學(xué)習(xí)。
我們用DAVIS 2017數(shù)據(jù)集中的視頻說(shuō)明這一過(guò)程,在模型中輸入灰度視頻和一幀帶有顏色的視頻,讓其判斷剩下視頻的顏色。模型學(xué)會(huì)從第一幀中復(fù)制顏色,即它可以不在人類監(jiān)督下學(xué)會(huì)追蹤目標(biāo)物體。
想從單一參照視頻中復(fù)制顏色,模型需要在內(nèi)部學(xué)會(huì)如何找到正確的區(qū)域,這樣才能填充正確的顏色。這就迫使它學(xué)習(xí)一種可以用來(lái)追蹤的機(jī)制。下面是模型上色的過(guò)程:
左:第一幀上色;中:輸入視頻;右:輸出視頻
雖然網(wǎng)絡(luò)在訓(xùn)練時(shí)沒有標(biāo)準(zhǔn)參照,我們的模型學(xué)會(huì)了以第一幀為參照對(duì)任意區(qū)域進(jìn)行上色。我們可以跟蹤任一物體甚至視頻中的某個(gè)點(diǎn)。唯一的不同是,我們不是改變顏色,而是添加代表這一區(qū)域的標(biāo)簽。
分析跟蹤器
由于模型在大量未標(biāo)記的視頻上訓(xùn)練,我們想掌握模型到底學(xué)到了什么。下面的動(dòng)圖展現(xiàn)了如何用模型學(xué)習(xí)來(lái)的可視化方法將嵌入映射到三維空間中,這一過(guò)程用到了主成分分析(PCA)并將其變成RGB格式的圖像。結(jié)果顯示,在與學(xué)到的嵌入空間最近的區(qū)域似乎更對(duì)應(yīng)目標(biāo)物體的識(shí)別,即使變了形或改變了視角。
第一行:DAVIS 2017數(shù)據(jù)集中的視頻;第二行:上色模型內(nèi)部的嵌入。相似的嵌入會(huì)在視覺表示中有相似的顏色,這說(shuō)明目標(biāo)識(shí)別將學(xué)習(xí)到的嵌入進(jìn)行像素劃分
姿態(tài)跟蹤
我們發(fā)現(xiàn),如果在開頭幀中給定幾個(gè)關(guān)鍵點(diǎn),模型還可以跟蹤人類的姿態(tài)。我們展示了JHMDB數(shù)據(jù)集中的幾個(gè)結(jié)果,其中我們追蹤了人類的關(guān)節(jié)骨架。
在這個(gè)例子中,輸入的是第一幀人類的動(dòng)作,接下來(lái)的動(dòng)作模型會(huì)自動(dòng)追蹤。即使之前沒有訓(xùn)練過(guò)此種場(chǎng)景,模型也能追蹤到人類動(dòng)作
雖然我們的模型還不足以超越監(jiān)督模型,但是與最近基于光流的模型相比,它所學(xué)到的視頻分割和人類姿勢(shì)追蹤表現(xiàn)已經(jīng)勝出了。我們的模型比光流追蹤方面更穩(wěn)定,尤其在復(fù)雜的情況下,例如動(dòng)態(tài)背景、快速運(yùn)動(dòng)和障礙物面前。想了解更多細(xì)節(jié),請(qǐng)閱讀原論文。
結(jié)語(yǔ)
我們的工作表示,給視頻上色可以用作在無(wú)監(jiān)督情況下學(xué)習(xí)追蹤視頻中的目標(biāo)物體。另外,我們發(fā)現(xiàn)系統(tǒng)的失敗會(huì)導(dǎo)致給視頻上色時(shí)出現(xiàn)錯(cuò)誤,這也說(shuō)明,未來(lái)改善視頻的上色模型可以提高姿態(tài)追蹤系統(tǒng)的表現(xiàn)
-
谷歌
+關(guān)注
關(guān)注
27文章
6176瀏覽量
105677 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4776瀏覽量
100948 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24749
原文標(biāo)題:另辟蹊徑!谷歌通過(guò)給視頻上色實(shí)現(xiàn)無(wú)監(jiān)督姿態(tài)追蹤
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一種求解非線性約束優(yōu)化全局最優(yōu)的新方法
一種繞線轉(zhuǎn)子感應(yīng)電機(jī)控制的新方法
機(jī)場(chǎng)場(chǎng)面監(jiān)視雷達(dá)目標(biāo)檢測(cè)新方法
一種級(jí)數(shù)混合運(yùn)算產(chǎn)生SPWM波新方法
一種求解動(dòng)態(tài)及不確定性優(yōu)化問題的新方法
一種新方法來(lái)檢測(cè)這些被操縱的換臉視頻的“跡象”
一種復(fù)制和粘貼URL的新方法
一種改善微波模塊增益指標(biāo)溫度特性的新方法

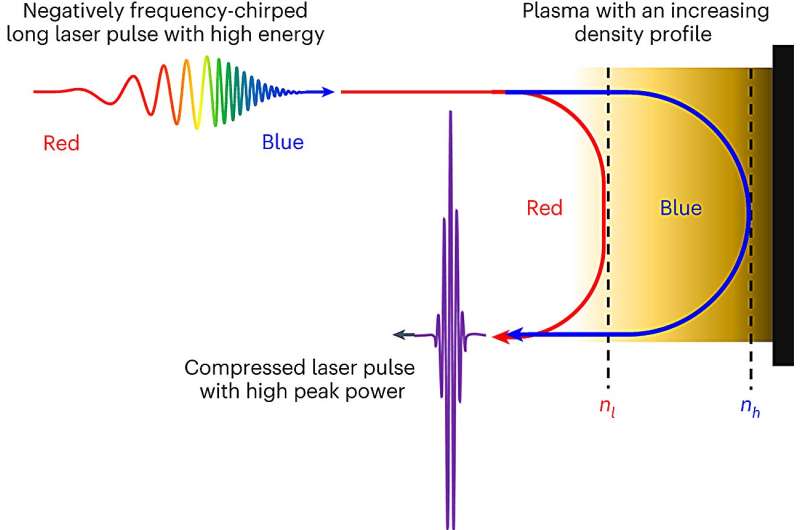
一種產(chǎn)生激光脈沖的新方法
一種產(chǎn)生激光脈沖新方法
一種無(wú)透鏡成像的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論