") 一種用于學(xué)習(xí)ZSL無偏嵌入的直接但有效的方法
一種用于學(xué)習(xí)ZSL無偏嵌入的直接但有效的方法
本文提出了一種用于學(xué)習(xí)ZSL無偏嵌入的直接但有效的方法。這種方法假設(shè)標(biāo)注的源數(shù)據(jù)和未標(biāo)注的目標(biāo)數(shù)據(jù)在模型訓(xùn)練的過程中可以使用,在各種基準(zhǔn)數(shù)據(jù)集上的實(shí)驗(yàn)表明,該方法大幅超過了現(xiàn)有的ZSL方法。
大多數(shù)現(xiàn)有的零樣本學(xué)習(xí)(Zero-Shot Learning,ZSL)方法都存在強(qiáng)偏問題:訓(xùn)練階段看不見(目標(biāo))類的實(shí)例在測試時往往被歸類為所看到的(源)類之一。因此,在廣義ZSL設(shè)置中部署后,它們的性能很差。在本文,我們提出了一個簡單而有效的方法,稱為準(zhǔn)完全監(jiān)督學(xué)習(xí)(QFSL),來緩解此問題。我們的方法遵循直推式學(xué)習(xí)的方式,假定標(biāo)記的源圖像和未標(biāo)記的目標(biāo)圖像都可用于訓(xùn)練。在語義嵌入空間中,被標(biāo)記的源圖像被映射到由源類別指定的若干個嵌入點(diǎn),并且未標(biāo)記的目標(biāo)圖像被強(qiáng)制映射到由目標(biāo)類別指定的其他點(diǎn)。在AwA2,CUB和SUN數(shù)據(jù)集上進(jìn)行的實(shí)驗(yàn)表明,我們的方法在遵循廣義ZSL設(shè)置的情況下比現(xiàn)有技術(shù)的方法優(yōu)越9.3%至24.5%,在遵循傳統(tǒng)ZSL設(shè)置下有0.2%至16.2%的提升。
歸納式和直推式零樣本學(xué)習(xí)
在大規(guī)模的訓(xùn)練數(shù)據(jù)集的支撐下,計(jì)算機(jī)視覺中的物體識別算法在近幾年取得了突破性的進(jìn)展。但是人工收集和標(biāo)注數(shù)據(jù)是一項(xiàng)十分耗費(fèi)人力物力的工作。例如,在細(xì)粒度分類中,需要專家來區(qū)分不同的類別。對于如瀕臨滅絕的物種,要收集到豐富多樣的數(shù)據(jù)就更加困難了。在給定有限或者沒有訓(xùn)練圖片的情況下,現(xiàn)在的視覺識別模型很難預(yù)測出正確的結(jié)果。
零樣本學(xué)習(xí)是一類可以用于解決以上問題的可行方法。零樣本學(xué)習(xí)區(qū)分2種不同來源的類,源類(source)和目標(biāo)類(target),其中源類是有標(biāo)注的圖像數(shù)據(jù),目標(biāo)類是沒有標(biāo)注的圖像數(shù)據(jù)。為了能夠識別新的目標(biāo)類(無標(biāo)注),零樣本學(xué)習(xí)假定源類和目標(biāo)類共享同一個語義空間。圖像和類名都可以嵌入到這個空間中。語義空間可以是屬性(attribute)、詞向量(word vector)等。在該假設(shè)下,識別來自目標(biāo)類的圖像可以通過在上述語義空間中進(jìn)行最近鄰搜索達(dá)成。
根據(jù)目標(biāo)類的無標(biāo)注數(shù)據(jù)是否可以在訓(xùn)練時使用,現(xiàn)有的ZSL可以分為2類:歸納式ZSL(inductive ZSL)和直推式ZSL(transductive ZSL)。對于歸納式ZSL,訓(xùn)練階段只能獲取得到源類數(shù)據(jù)。對于直推式ZSL,訓(xùn)練階段可以獲取到有標(biāo)注的源類數(shù)據(jù)和未標(biāo)注的目標(biāo)類數(shù)據(jù)。直推式ZSL希望通過同時利用有標(biāo)注的源類和無標(biāo)注的目標(biāo)類來完成ZSL任務(wù)。
在測試階段,大多數(shù)現(xiàn)有的歸納式ZSL和直推式ZSL都假定測試圖像都來源于目標(biāo)類。因此,對測試圖片分類的搜索空間被限制在目標(biāo)類中。我們把這種實(shí)驗(yàn)設(shè)定叫作傳統(tǒng)設(shè)定(conventional settings)。然而,在一個更加實(shí)際的應(yīng)用場景中,測試圖像不僅來源于目標(biāo)類,還可能來自源類。這種情況下,來自源類和目標(biāo)類的數(shù)據(jù)都應(yīng)該被考慮到。我們把這種設(shè)定叫作廣義設(shè)定(generalized settings)。
現(xiàn)有的ZSL方法在廣義設(shè)定下的效果遠(yuǎn)差于傳統(tǒng)設(shè)定。這種不良的表現(xiàn)的主要原因可以歸納如下:ZSL通過建立視覺嵌入和語義嵌入之間的聯(lián)系來實(shí)現(xiàn)新的類別的識別。在銜接視覺嵌入和語義嵌入的過程中,大多數(shù)現(xiàn)有的ZSL方法存在著強(qiáng)偏 (strong bias)的問題(如圖1所示):在訓(xùn)練階段,視覺圖片通常被投影到由源類確定的語義嵌入空間中的幾個固定的點(diǎn)。這樣就導(dǎo)致了在測試階段中,在目標(biāo)數(shù)據(jù)集中的新類圖像傾向于被分到源類當(dāng)中。
圖1
為了解決以上問題,本文提出了一種新的直推式ZSL方法。我們假定有標(biāo)注的源數(shù)據(jù)和目標(biāo)數(shù)據(jù)都可以在訓(xùn)練階段得到。一方面,有標(biāo)注的源數(shù)據(jù)可以用于學(xué)習(xí)圖像與語義嵌入之間的關(guān)系。另外一方面,沒有標(biāo)注的目標(biāo)數(shù)據(jù)可以用于減少由于源類引起的偏置問題。更確切地來說,我們的方法允許輸入圖像映射到其他的嵌入點(diǎn)上,而不是像其他ZSL方法將輸入圖像映射到固定的由源類確定的幾個點(diǎn)上。這樣有效地緩解了偏置問題。
我們將這種方法稱為準(zhǔn)全監(jiān)督學(xué)習(xí)(Quasi-Fully Supervised Learning, QFSL)。這種方法和傳統(tǒng)的全監(jiān)督分類工作方式相似,由多層神經(jīng)網(wǎng)絡(luò)和一個分類器組成,如圖2所示。神經(jīng)網(wǎng)絡(luò)模型架構(gòu)采用現(xiàn)有的主流架構(gòu),比如AlexNet、GoogleNet或者其他框架。在訓(xùn)練階段,我們的模型使用有標(biāo)注的源類數(shù)據(jù)和沒有標(biāo)注的目標(biāo)數(shù)據(jù)進(jìn)行端到端的訓(xùn)練。這使得我們的模型有一兩個個明顯的特性:(1)如果未來可以得到目標(biāo)類的標(biāo)注數(shù)據(jù),那么標(biāo)注數(shù)據(jù)可以直接用于進(jìn)一步訓(xùn)練和改進(jìn)現(xiàn)有的網(wǎng)絡(luò)模型;(2)在測試階段,我們得到的訓(xùn)練模型可以直接用于識別來自于源類和目標(biāo)類的圖像,而不需要進(jìn)行任何修改。
本論文的主要貢獻(xiàn)總結(jié)如下:
提出了準(zhǔn)全監(jiān)督學(xué)習(xí)的方法來解決零樣本學(xué)習(xí)中的強(qiáng)偏問題。據(jù)我們所知,這是第一個采用直推式學(xué)習(xí)方法來解決廣義設(shè)定下零樣本學(xué)習(xí)問題。
實(shí)驗(yàn)結(jié)果表明我們的方法在廣義設(shè)定下和傳統(tǒng)設(shè)定下都遠(yuǎn)超現(xiàn)有的零樣本學(xué)習(xí)方法。
問題的形式化
假設(shè)存在一個源數(shù)據(jù)集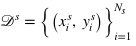 ? , 每張圖片
? , 每張圖片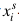 與相應(yīng)的標(biāo)簽
與相應(yīng)的標(biāo)簽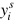 對應(yīng),其中
對應(yīng),其中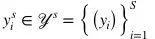 , S表示源類中類的個數(shù)。目標(biāo)數(shù)據(jù)集
, S表示源類中類的個數(shù)。目標(biāo)數(shù)據(jù)集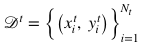 , 每張圖片
, 每張圖片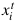 與相應(yīng)的標(biāo)簽
與相應(yīng)的標(biāo)簽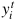 對應(yīng),其中
對應(yīng),其中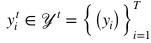 ,? T表示目標(biāo)類中類的個數(shù)。ZSL的目標(biāo)就是學(xué)習(xí)如下所示的預(yù)測函數(shù)
,? T表示目標(biāo)類中類的個數(shù)。ZSL的目標(biāo)就是學(xué)習(xí)如下所示的預(yù)測函數(shù)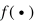 :
:
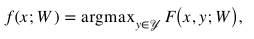
其中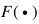 是一個得分函數(shù),其目標(biāo)是正確的標(biāo)注比其他不正確的標(biāo)注具有更高的得分。
是一個得分函數(shù),其目標(biāo)是正確的標(biāo)注比其他不正確的標(biāo)注具有更高的得分。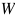 是模型
是模型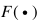
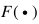
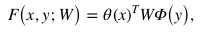
其中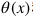
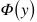 分別表示視覺嵌入和語義嵌入。得分函數(shù)通常使用帶正則化的目標(biāo)函數(shù)進(jìn)行優(yōu)化:
分別表示視覺嵌入和語義嵌入。得分函數(shù)通常使用帶正則化的目標(biāo)函數(shù)進(jìn)行優(yōu)化:
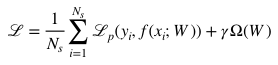
其中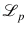 表示分類損失,用于學(xué)習(xí)視覺嵌入和語義嵌入之間的映射。
表示分類損失,用于學(xué)習(xí)視覺嵌入和語義嵌入之間的映射。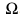 表示用于約束模型復(fù)雜度的正則項(xiàng)。
表示用于約束模型復(fù)雜度的正則項(xiàng)。
本文假設(shè)給定標(biāo)注源數(shù)據(jù)集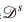 ,無標(biāo)注目標(biāo)數(shù)據(jù)集
,無標(biāo)注目標(biāo)數(shù)據(jù)集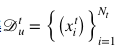 和語義嵌入
和語義嵌入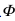 ,學(xué)習(xí)ZSL模型,使得其既能在傳統(tǒng)設(shè)定下又能在廣義設(shè)定下獲取良好的表現(xiàn)。
,學(xué)習(xí)ZSL模型,使得其既能在傳統(tǒng)設(shè)定下又能在廣義設(shè)定下獲取良好的表現(xiàn)。
QFSL模型
不同于以上描述的雙線性形式,我們將得分函數(shù)F設(shè)計(jì)成非線性形式。整個模型由深度神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)。模型包括4個模塊:視覺嵌入子網(wǎng)絡(luò),視覺-語義銜接子網(wǎng)絡(luò),得分子網(wǎng)絡(luò)和分類器。視覺嵌入子網(wǎng)絡(luò)將原始圖像映射到視覺嵌入空間。視覺-語義銜接子網(wǎng)絡(luò)將視覺嵌入映射到語義嵌入子網(wǎng)絡(luò)。得分子網(wǎng)絡(luò)在語義空間中產(chǎn)生每一類的得分。分類器根據(jù)得分輸出最終的預(yù)測結(jié)果。所有的模塊都是可微分的,包括卷積層,全連接層,ReLU層和softmax層。因此,我們的模型可以進(jìn)行端到端的訓(xùn)練。
視覺嵌入子網(wǎng)絡(luò)
現(xiàn)有的大多數(shù)模型采用了CNN提取得到的特征作為視覺嵌入。在這些方法中,視覺嵌入函數(shù)θ是固定的。這些方法并沒有充分利用深度CNN的強(qiáng)大的學(xué)習(xí)能力。本文采用了預(yù)訓(xùn)練的CNN模型來進(jìn)行視覺嵌入。我們的視覺嵌入模型的主要不同之處在于可以和其他模塊一起進(jìn)行優(yōu)化。視覺嵌入模塊的參數(shù)記為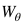 。除非特別說明,我們把第一個全連接層的輸出作為視覺嵌入。
。除非特別說明,我們把第一個全連接層的輸出作為視覺嵌入。
視覺-語義銜接子網(wǎng)絡(luò)
銜接圖像和語義嵌入之間的關(guān)系對ZSL來說很重要。這種關(guān)系可以通過線性函數(shù)或者非線性函數(shù)來建模。本文采用了非線性函數(shù)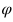 將視覺嵌入映射到語義嵌入。?
將視覺嵌入映射到語義嵌入。?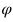
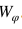 。
。
得分子網(wǎng)絡(luò)
銜接視覺嵌入和語義嵌入之后,識別任務(wù)可以通過在語義嵌入空間中使用最近鄰搜索來實(shí)現(xiàn)。
給定一張圖像,我們首先通過視覺嵌入子網(wǎng)絡(luò)得到它的視覺嵌入。然后,利用視覺-語義銜接子網(wǎng)絡(luò),完成從視覺嵌入到語義嵌入的映射。最后,我們通過內(nèi)積計(jì)算得到投影得到的視覺嵌入和語義嵌入的得分。因此,得分函數(shù)可以表示如下:
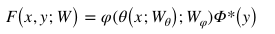
其中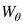
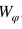
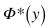 是 y 的歸一化語義嵌入:
是 y 的歸一化語義嵌入:
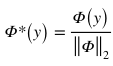
得分函數(shù)由單個全連接層來實(shí)現(xiàn)。它的權(quán)重使用源類和目標(biāo)類的歸一化語義: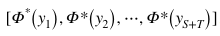 來初始化。和視覺嵌入子網(wǎng)絡(luò)和視覺-語義銜接子網(wǎng)絡(luò)不同的是,得分子網(wǎng)絡(luò)的權(quán)重是固定的,在訓(xùn)練階段不參與更新。通過這種方式,我們的模型將圖像
來初始化。和視覺嵌入子網(wǎng)絡(luò)和視覺-語義銜接子網(wǎng)絡(luò)不同的是,得分子網(wǎng)絡(luò)的權(quán)重是固定的,在訓(xùn)練階段不參與更新。通過這種方式,我們的模型將圖像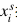 投影到與視覺嵌入
投影到與視覺嵌入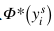 相近的方向上。
相近的方向上。
需要注意的是目標(biāo)類的數(shù)據(jù)沒有標(biāo)注,這些數(shù)據(jù)在我們的方法中用到了訓(xùn)練階段當(dāng)中。因此,在訓(xùn)練階段,我們的模型對于一張給定的圖像,產(chǎn)生了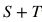 個得分。
個得分。
分類器
經(jīng)過得分函數(shù)后,我們使用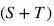 路的softmax分類器產(chǎn)生了所有類的概率。輸入圖像的預(yù)測結(jié)果為概率最高的那個類。
路的softmax分類器產(chǎn)生了所有類的概率。輸入圖像的預(yù)測結(jié)果為概率最高的那個類。
模型優(yōu)化
我們的方法采用了類似于由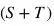
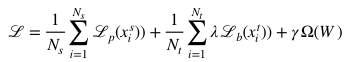
通常,傳統(tǒng)的全監(jiān)督分類器的損失函數(shù)包括分類損失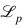 和正則化損失Ω。和傳統(tǒng)定義不同,我們提出的QFSL結(jié)合了一個額外的偏置損失
和正則化損失Ω。和傳統(tǒng)定義不同,我們提出的QFSL結(jié)合了一個額外的偏置損失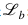 來緩解強(qiáng)偏問題:?
來緩解強(qiáng)偏問題:?
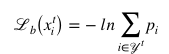
其中,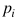 表示預(yù)測為類 i 的概率。給定一個來自目標(biāo)類的實(shí)例,該損失鼓勵模型增加所有目標(biāo)類的概率和。這樣可以防止目標(biāo)類被映射到源類中。
表示預(yù)測為類 i 的概率。給定一個來自目標(biāo)類的實(shí)例,該損失鼓勵模型增加所有目標(biāo)類的概率和。這樣可以防止目標(biāo)類被映射到源類中。
對于分類損失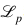
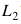 范數(shù)來約束訓(xùn)練參數(shù)
范數(shù)來約束訓(xùn)練參數(shù)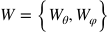 。
。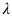 和
和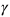 用于平衡不同損失之間的權(quán)重,通過交叉驗(yàn)證來確定。在訓(xùn)練階段,所有標(biāo)注的數(shù)據(jù)和未標(biāo)注的數(shù)據(jù)混合在一起作為訓(xùn)練數(shù)據(jù)。模型使用隨機(jī)梯度下降算法(SGD)進(jìn)行優(yōu)化。每一個批(batch)訓(xùn)練圖像從混合數(shù)據(jù)集中隨機(jī)抽取。實(shí)驗(yàn)結(jié)果表明我們的方法不僅有效地避免了偏置問題,還幫助建立起了更好的視覺嵌入和語義嵌入之間的聯(lián)系。
用于平衡不同損失之間的權(quán)重,通過交叉驗(yàn)證來確定。在訓(xùn)練階段,所有標(biāo)注的數(shù)據(jù)和未標(biāo)注的數(shù)據(jù)混合在一起作為訓(xùn)練數(shù)據(jù)。模型使用隨機(jī)梯度下降算法(SGD)進(jìn)行優(yōu)化。每一個批(batch)訓(xùn)練圖像從混合數(shù)據(jù)集中隨機(jī)抽取。實(shí)驗(yàn)結(jié)果表明我們的方法不僅有效地避免了偏置問題,還幫助建立起了更好的視覺嵌入和語義嵌入之間的聯(lián)系。
實(shí)驗(yàn)
數(shù)據(jù)集
我們在三個數(shù)據(jù)集上評估了我們的方法。這三個數(shù)據(jù)集分別為AwA2, CUB, SUN。在實(shí)驗(yàn)中,我們采用屬性作為語義空間,用類平均準(zhǔn)確度衡量模型效果。
在傳統(tǒng)設(shè)置下的效果比較
首先我們在傳統(tǒng)設(shè)置下對我們方法和現(xiàn)有方法。用來做對比的現(xiàn)有方法分為兩類:一類是是歸納式方法,包括DAP,CONSE,SSE,ALE,DEVISE,SJE,ESZSL,SYNC;另一類是直推式方法,包含UDA,TMV,SMS。與此同時,還比較了一個潛在的baseline(標(biāo)記為QFSL-):只用有標(biāo)注的源數(shù)據(jù)來訓(xùn)練我們的模型。實(shí)驗(yàn)效果如表1。可以看出,我們的方法大幅度(4.5~16.2%)提升了分類準(zhǔn)確度。
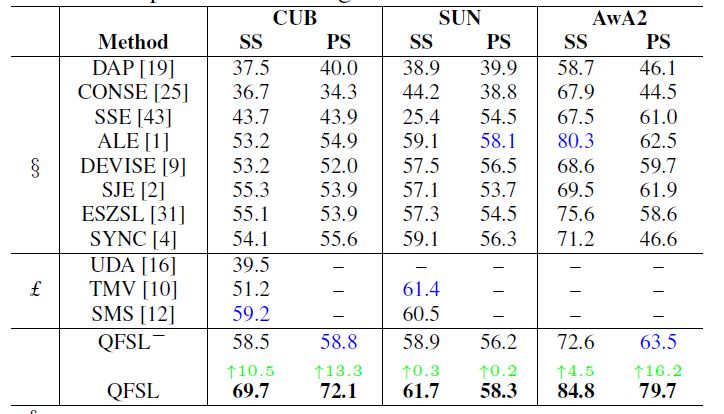
表1. 在傳統(tǒng)設(shè)置下的實(shí)驗(yàn)比較
在廣義設(shè)置下的效果比較
大多數(shù)現(xiàn)有直推式方法在測試階段都采用了同訓(xùn)練階段同樣的數(shù)據(jù)來評估性能。然而,如果我們的方法也采用這種方式來評估效果是很不合理的。因?yàn)槲覀兊姆椒ㄒ呀?jīng)利用到了無標(biāo)簽的數(shù)據(jù)來源于目標(biāo)類這一監(jiān)督信息。為了解決這一問題,我們將目標(biāo)數(shù)據(jù)平分為兩份,一份用來訓(xùn)練,另一份用來測試。然后交換這兩份數(shù)據(jù)的角色,再重新訓(xùn)練一個模型。最終的效果為這兩個模型的平均。我們比較了我們的方法和若干現(xiàn)有方法,以及一個隱含的baseline:先訓(xùn)練一個二分類器來區(qū)分源數(shù)據(jù)和目標(biāo)數(shù)據(jù),然后再在各自搜索空間中分類。實(shí)驗(yàn)結(jié)果如表2。
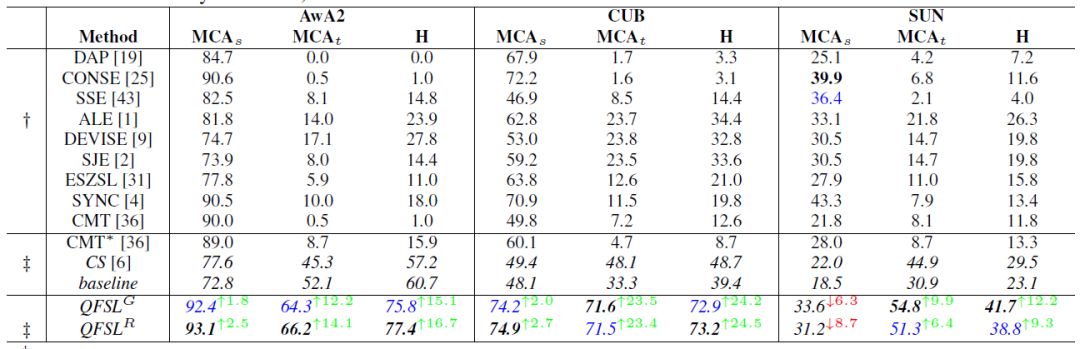
表2
可以看出,我們模型的整體性能(調(diào)和平均數(shù)H)有著9.3~24.5的明顯提高。該項(xiàng)指標(biāo)的提高主要得益于在目標(biāo)數(shù)據(jù)上的效果提升,同時又沒有在源數(shù)據(jù)上大幅度降低準(zhǔn)確度。該結(jié)果表明,我們的方法能夠很大程度上緩解強(qiáng)偏問題。
討論
現(xiàn)實(shí)世界中,目標(biāo)類的數(shù)量可能遠(yuǎn)遠(yuǎn)高于源類數(shù)量。然而,大多數(shù)現(xiàn)有ZSL數(shù)據(jù)集的源、目標(biāo)數(shù)據(jù)劃分都違背了這一點(diǎn)。比如,在AwA2中,40個類用來做訓(xùn)練,10個類用來做測試。我們在實(shí)驗(yàn)上給出了隨著源數(shù)據(jù)類別的增加,QFSL在效果上如何變化。該實(shí)驗(yàn)在SUN數(shù)據(jù)集上進(jìn)行,72類作為目標(biāo)類,隨機(jī)選取剩下的類作為源類。我們嘗試了7個大小不同的源類集,類的數(shù)量分別為{100,200,300,450,550,600,645}。用這些不同大小的源類作為訓(xùn)練集,測試我們的方法,效果如圖3。由圖可以看出,隨著類別增加,模型能夠?qū)W習(xí)到更多的知識,其在目標(biāo)數(shù)據(jù)集上準(zhǔn)確度越來越高。同時,由于源數(shù)據(jù)和目標(biāo)數(shù)據(jù)變得越來越不平衡,強(qiáng)偏問題越來越嚴(yán)重。我們方法能夠緩解強(qiáng)偏問題,因而其在效果上的優(yōu)越性也越來越明顯。
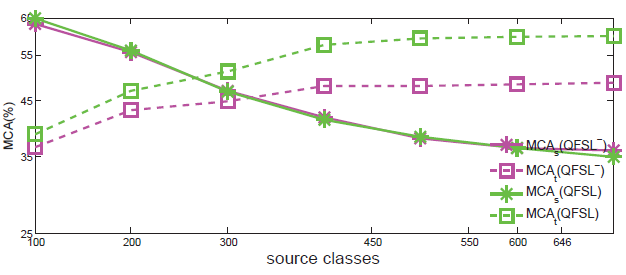
圖3. 準(zhǔn)全監(jiān)督在SUN數(shù)據(jù)集上效果
結(jié)論
本文提出了一種用于學(xué)習(xí)ZSL無偏嵌入的直接但有效的方法。這種方法假設(shè)標(biāo)注的源數(shù)據(jù)和未標(biāo)注的目標(biāo)數(shù)據(jù)在模型訓(xùn)練的過程中可以使用。一方面,將標(biāo)注的源數(shù)據(jù)映射到語義空間中源類對應(yīng)的點(diǎn)上。另外一方面,將沒有標(biāo)注的目標(biāo)數(shù)據(jù)映射到語義空間中目標(biāo)類對應(yīng)的點(diǎn)上,從而有效地解決了模型預(yù)測結(jié)果向源類偏置的問題。在各種基準(zhǔn)數(shù)據(jù)集上的實(shí)驗(yàn)表明我們的方法在傳統(tǒng)設(shè)定和廣義設(shè)定下,大幅超過了現(xiàn)有的ZSL方法。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100772 -
圖像
+關(guān)注
關(guān)注
2文章
1084瀏覽量
40468 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24703
原文標(biāo)題:CVPR 2018:阿里提出新零樣本學(xué)習(xí)方法,有效解決偏置問題
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
求一種基于UML的嵌入式系統(tǒng)可視化開發(fā)方法
求大佬分享一種嵌入式系統(tǒng)中串口通信幀的同步方法
介紹一種解決overconfidence簡潔但有效的方法
一種具有漸進(jìn)學(xué)習(xí)能力的融合方法
一種可生存嵌入式系統(tǒng)性能監(jiān)測方法研究
一種在U-BOOT中嵌入千兆網(wǎng)絡(luò)功能的方法
一種簡單有效的限流保護(hù)電路
一種在線學(xué)習(xí)的跟蹤注冊方法
實(shí)現(xiàn)機(jī)器學(xué)習(xí)的一種重要框架是深度學(xué)習(xí)
Abacus展示了一種用于深度學(xué)習(xí)的新方法的技術(shù)
一種有效的無監(jiān)督深度表示器(Mix2Vec)
一種無透鏡成像的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論