 Airbnb機器學習和數據科學團隊經驗分享
Airbnb機器學習和數據科學團隊經驗分享
Airbnb資深機器學習科學家Shijing Yao、前Airbnb數據科學負責人Qiang Zhu、Airbnb機器學習工程師Phillippe Siclait分享了在Airbnb產品上大規模應用深度學習技術的經驗。
Airbnb在舊金山的新辦公室
世界各地的旅行者在Airbnb平臺上尋找旅途中的民宿。除了位置和價格之外,展示照片是房客搜索時做出決策的最關鍵因素之一。然而,直到最近之前,我們對這些重要的照片所知甚少。當房客在交互界面查看展示照片時,我們之前沒有辦法能夠幫助房客找到信息量最大的圖像,也無法確保照片傳達的信息是精確的,也沒法以可伸縮的方式向房主建議如何提高照片的吸引力。
多虧了計算機視覺和深度學習方面的最新進展,我們得以利用技術手段在較大規模上解決這一問題。我們從一個歸類展示圖片的項目開始。一方面,歸類使得同一類房間的照片可以分為一組。另一方面,歸類也能幫助檢查是否基本的房間信息是正確的(驗證房間數)。我們還相信,未來有很多激動人心的機會可以進一步增強Airbnb的圖像內容的知識。我們將在本文結尾展示一些例子。
圖像分類
能夠正確分類給定的展示照片的房間類型,對優化用戶體驗而言是極有幫助的。從房客的角度來說,這使得Airbnb可以根據不同的房間類型重新排序、重新布局照片,優先展示人們最感興趣的照片。從房主的角度來說,這可以幫助Airbnb自動審核展示照片,以確保房主遵守了Airbnb的標準。精確的照片歸類是這些核心功能的基石。
我們打算分類的第一批房間類型包括臥室、浴室、起居室、廚房、游泳池、景觀。我們計劃基于產品團隊的需求增加其他房間類型。
房間類型分類問題大體上和ImageNet分類問題差不多,只不過我們的模型的輸出是定制的房間類型。這意味著VGG、ResNet、Inception之類現成的當前最先進深度神經網絡(DNN)模型無法直接應用于我們的案例。網上有很多非常棒的帖子告訴人們如何應對這一問題。基本上,我們應該:1) 修改DNN的最后幾層,確保輸出維度匹配我們的需求;2) 再訓練DNN的部分網絡層,直到取得滿意的表現。在一些嘗試之后,我們選擇了ResNet50,因為它在模型表現和計算時間方面平衡得很好。為了讓它兼容我們的案例,我們在最后附加了兩個額外的全連接層,以及softmax激活。我們也試驗了一些訓練選項,詳見下節。
再訓練修改過的ResNet50
修改過的ResNet50架構架構。基礎模型圖取自Kaiming He
再訓練ResNet50可以分為三大場景:
固定基礎ResNet50模型,僅僅使用最少的數據再訓練增加的兩層。這也經常稱為微調。
進行第一個場景中的微調,不過使用大量數據。
從頭開始重新訓練整個修改過的ResNet50模型。
大部分網上的教程使用的都是第一種方法,因為這很快,而且通常能夠取得不錯的結果。我們嘗試過第一種方法,并且確實得到了一些合理的初始結果。然而,為了運行高品質的圖像產品,我們需要戲劇性地提升模型的表現——我們的理想是達到95%+準確率,80%+召回。
為了能夠同時達到高準確率和高召回,我們意識到使用大規模數據重新訓練DNN是不可避免的。然而,我們遇到了兩大挑戰:1) 盡管我們有很多由房主上傳的展示照片,我們沒有相應的精確的房間類型標簽,實際上很多照片根本沒有標簽;2) 再訓練ResNet50這樣的DNN絕非易事——需要訓練超過兩千五百萬參數,需要強力的GPU支持。我們將在接下來的兩小節介紹我們是如何應對這兩項挑戰的。
監督學習圖像說明
許多公司利用第三方服務商取得圖像數據的高品質標簽。由于我們有數以百萬計的照片需要標注,顯然這不是最經濟的做法。為了平衡成本和表現,我們以一種混合的方式處理這一標注問題。一方面,我們請服務商標注了相對而言數量較少的照片,通常以千計,或以萬計。這部分標注過的數據將作為我們評估模型的金數據集。我們通過隨機采樣得到了這一金數據集的照片,并確保數據沒有偏差。另一方面,我們利用房主創建的圖像說明作為房間類型信息的代理,從中提取標簽。這一想法對我們而言意義重大,因為它使得昂貴的標注任務基本上變為免費。我們只需要一種明智的方法,確保從圖像說明中提取的房間類型標簽是精確可靠的。
一個很有吸引力的從圖像說明中提取標簽的方法是這樣的:如果我們在某張圖像的說明中找到了特定的關鍵詞,那么這張圖像就會被打上該類型的標簽。然而,現實世界要比這復雜得多。如果你檢查根據這一規則得到的結果,你將大失所望。我們發現由大量情形圖像說明和圖像的實際內容相差甚遠。下面是一些例子。
上圖展示了在圖像說明中搜尋特定關鍵詞導致的錯誤標簽:(黑體為錯誤標簽)
廚房:通往臥室和廚房的樓梯
起居室:從起居室通往臥室的過道
浴室:主臥包含浴室和特大床
臥室:從臥室往外看的景觀
游泳池:由大量空間可以散步,游泳池旁邊的花園
景觀:從廚房看到的起居室(譯者注:viewof liing space from Kitchen的view被錯誤提取為景觀標簽)
為了過濾這樣的例子,我們增加了額外的規則。經過若干回合的過濾和檢查,標簽的質量大大改善了。下面是一個規則的例子(過濾廚房圖像)。
AND LOWER(caption) like '%kitchen%'
AND LENGTH(caption) <= 22
AND LOWER(caption) NOT LIKE '%bed%'
AND LOWER(caption) NOT LIKE '%bath%'
AND LOWER(caption) NOT LIKE '%pool%'
AND LOWER(caption) NOT LIKE '%living%'
AND LOWER(caption) NOT LIKE '%view%'
AND LOWER(caption) NOT LIKE '%door%'
AND LOWER(caption) NOT LIKE '%table%'
AND LOWER(caption) NOT LIKE '%deck%'
AND LOWER(caption) NOT LIKE '%cabinet%'
AND LOWER(caption) NOT LIKE '%entrance%'
由于這些額外的過濾,我們損失了相當可觀的圖像數據。對于我們而言這不是很大的問題,因為即使經過了如此激進的過濾,我們還是得到了幾百萬照片,每種房間類型有幾十萬照片。不僅如此,這些照片的標簽質量要好很多。我們假定過濾并沒有改變數據分布,我們將在使用金數據集測試模型時驗證這一點。
話是這么說,或許我們本可以使用一些NLP技術來動態聚類圖像說明,而不是使用基于規則的啟發式方法。不過我們決定目前使用啟發式方法,在未來再嘗試NLP技術。
模型構建、評估、部署
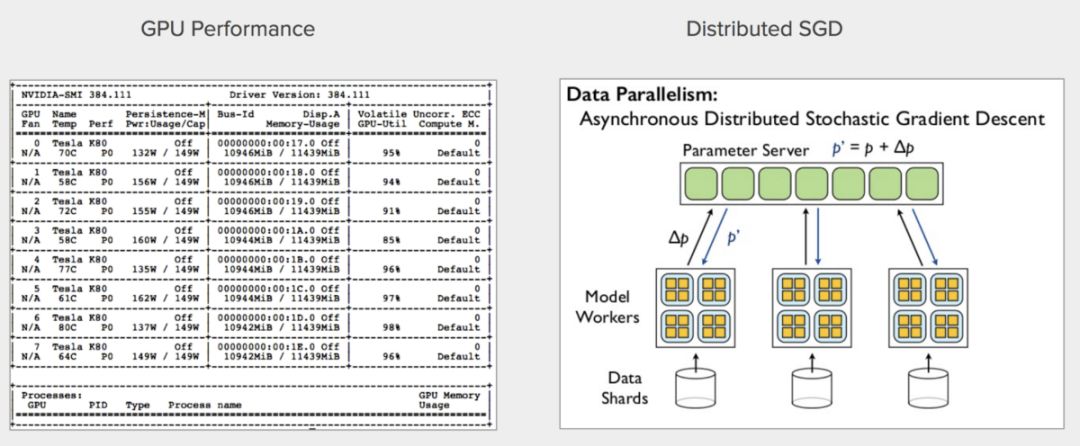
左:8核GPU并行訓練;右:分布式SGD(引用自Quoc V. Le)
使用幾百萬張圖像再訓練像ResNet50這樣的DNN需要大量的計算資源。我們的實現使用了一個AWS P2.8xlarge實例(Nvidia 8核K80 GPU),訓練的每一步傳送128張圖像至8個GPU核心。我們使用Tensorflow作為并行訓練的后端。我們在并行化模型之后編譯了模型,否則訓練無法進行。為了進一步加速訓練,我們使用預訓練的imagenet權重初始化模型權重(imagenet權重來自keras.applications.resnet50.ResNet50)。經過3個epoch的訓練(花了6小時)之后,我們得到了最佳模型。在此之后模型開始過擬合,驗證集上的表現停止提升。
我們在生產環境部署的是多個二元分類模型(對應于不同的房間類型),而不是覆蓋所有房間類型的多類模型。這并不理想,不過由于我們的模型服務基本上是離線的,因此多模型調用導致的額外延遲對我們的影響并不大。我們很快將在生產環境部署多類模型。
我們基于準確率和召回評估模型。我們也同時監控F1評分和精確度之類的測度。下面我們將要重述這些測度的定義。簡單概括一下,準確率描述了我們對陽性預測的精確度的自信程度,而召回描述了陽性預測在所有實際陽性值上的覆蓋率。準確率和召回通常彼此沖突。在我們的場景中,我們給準確率定了一個很高的標準(95%),因為當我們聲稱照片屬于特定房間類型時,我們應該對此高度自信。

TP 真陽性;TN 真陰性;FP 假陽性;FN 假陰性
混淆矩陣是計算這些測度的關鍵。我們模型的原始輸出是每個圖像0到1之間的概率。為了計算混淆矩陣,我們需要首先設定一個特定的閾值,將預測的概率轉換為0和1. 接著,以召回為x軸,以準確率為y軸,可以生成準確率-召回(P-R)曲線。原則上,P-R曲線的AUC(曲線下面積)越接近1,模型就越精確。
為了評估模型,我們使用了之間提到的金數據集,其中的標準答案標簽由人類提供。有趣的是,我們發現不同房間類型的精確程度不同。臥室模型和浴室模型是最精確的房間類型,而其他模型就不那么精確了。為了節省篇幅,我們將僅僅展示臥室和起居室的P-R曲線。虛線的十字交匯點代表給定特定閾值后的最終表現。我們在圖形中加上了測度總結。
臥室的P-R曲線
起居室的P-R曲線
兩點重要的觀察:
臥室模型的總體表現要比起居室模型好很多。可能的解釋為:1) 臥室比起居室更容易分類,因為臥室的布局相對標準,而起居室的變化較多。2) 從臥室照片中提取的標簽質量高于從起居室照片中提取的標簽,因為起居室偶爾也包括飯廳甚至廚房。
對每種房間類型而言,完全再訓練的模型(紅色曲線)表現優于部分再訓練的模型(藍色曲線)。同時,相比臥室模型,起居室模型上兩者之間的差距更大。這暗示了再訓練完整的ResNet50模型在不同房間類型上的影響不同。
我們交付的6個模型,準確率一般高于95%,召回一般高于50%。通過設定不同的閾值,可以折衷準確率和召回。模型支撐了Airbnb的多個產品團隊的不同產品。
用戶比較了我們的結果和知名的第三方圖像識別API。據報告我們的內部模型總體而言超越了第三方的通用模型。這暗示了利用你自己的數據的優勢,你有機會在你感興趣的特定任務上超過業界的當前最先進模型的表現。
我們想要展示一些具體的例子,作為本小節的結束。
分類之外
在進行這個項目的時候,我們也嘗試了房間類型分類以外的一些有趣的想法。我們想在這里展示兩個例子,讓讀者大致了解這些問題多么讓人激動。
無監督場景分類
當我們首次嘗試使用預訓練的ResNet50模型分類房間類型時,我們生成了圖像嵌入(2048x1向量)以展示題圖。為了解釋這些嵌入的含義,我們使用PCA技術將這些長向量投影至二維平面。出乎我們的意料,投影數據自然而然地聚類為兩組:其中一個聚類幾乎全是室內場景,另一個聚類則幾乎全是室外場景。這意味著,在沒有進行任何再訓練的情況下,僅僅通過圖像嵌入的主成分,我們就能判定室內場景和室外場景。這一發現開啟了通向某個非常有趣的領域——遷移學習(嵌入)與非監督學習——的大門。
目標檢測
我們嘗試追尋的另一個領域是目標檢測。在Open Images Dataset上預訓練的Faster R-CNN模型已經能提供酷炫的結果。如你在下面的例子中所見,模型已經能夠檢測出窗、門、飯桌及其位置。我們使用Tensorflow目標檢測API對展示照片做了一些快速評估。大量家用設施可以通過現成的模型檢測到。未來我們計劃使用Airbnb定制的設施標簽再訓練Faster R-CNN模型。由于開源數據中沒有包含部分Airbnb定制標簽,我們想要創建自行創建標簽。有了這些算法檢測到的設施,我們能夠驗證房主發布房源的質量,讓有特定設施需要的房客更容易找到心儀的房屋。這將把Airbnb的照片智能的前沿推進至下一等級。
成功檢測出窗、門、飯桌
結論
讓我們總結一些可能對其他深度學習開發者有幫助的關鍵點:
深度學習不過是一種特定的監督學習方法。因此再怎么強調數據的高質量標簽的重要性也不為過。由于深度學習通常需要大量訓練數據以達到當前最先進的表現,找到標注的有效方式非常關鍵。幸運的是,我們找到了一個經濟、可伸縮、可靠的混合方法。
從頭訓練像ResNet50這樣的DNN可能需要費很大的力氣。嘗試從簡單快速的方式開始——使用小數據集訓練頂上幾層。如果你確實有一個大型的可訓練數據集,從頭再訓練DNN可能提供當前最先進的表現。
如果可以的話,并行化訓練。在我們的案例中,我們通過使用8核GPU獲得了大約6倍(擬線性)速度提升。這使構建一個復雜的DNN模型在算力上變得可行,迭代超參數和模型結構也容易許多。
-
深度學習
+關注
關注
73文章
5503瀏覽量
121170 -
Airbnb
+關注
關注
0文章
14瀏覽量
5390
原文標題:歸類照片:Airbnb是如何應用大規模深度學習模型的
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
前百度深度學習研究院科學家分享:機器視覺開發實戰經驗
分析、數據科學和機器學習平臺最熱語言_Python
十大機器學習工具及數據科學工具
google機器學習團隊開發機器學習系統Seti的一些經驗教訓
Python網頁爬蟲,文本處理,科學計算,機器學習和數據挖掘工具集
機器學習的12大經驗總結
仔細研究用于機器學習和數據科學的十大Python工具
機器學習和數據科學技術在工業界開源應用的Github項目

機器學習與數據科學的區別
機器學習的成功應用需要具備哪些能力和技能?
20個必知的自動化機器學習庫(Python)






 工商網監
工商網監
評論