") DeepMind的最新研究結(jié)合了神經(jīng)網(wǎng)絡(luò)和隨機過程的優(yōu)點提出神經(jīng)過程模型
DeepMind的最新研究結(jié)合了神經(jīng)網(wǎng)絡(luò)和隨機過程的優(yōu)點提出神經(jīng)過程模型
函數(shù)逼近是機器學(xué)習(xí)中許多問題的核心,DeepMind的最新研究結(jié)合了神經(jīng)網(wǎng)絡(luò)和隨機過程的優(yōu)點,提出神經(jīng)過程模型,在多任務(wù)上實現(xiàn)了很好的性能和高計算效率。
函數(shù)逼近(Function approximation)是機器學(xué)習(xí)中許多問題的核心,在過去十年來,這個問題的一種非常流行的方法是深度神經(jīng)網(wǎng)絡(luò)。高級神經(jīng)網(wǎng)絡(luò)由黑盒函數(shù)逼近器構(gòu)成,它們學(xué)習(xí)從大量訓(xùn)練數(shù)據(jù)點參數(shù)化單個函數(shù)。因此,網(wǎng)絡(luò)的大部分工作負(fù)載都落在訓(xùn)練階段,而評估和測試階段則被簡化為快速的前向傳播。雖然高的測試時間性能對于許多實際應(yīng)用是有價值的,但是在訓(xùn)練之后就無法更新網(wǎng)絡(luò)的輸出,這可能是我們不希望的。例如,元學(xué)習(xí)(Meta-learning)是一個越來越受歡迎的研究領(lǐng)域,解決的正是這種局限性。
作為神經(jīng)網(wǎng)絡(luò)的一種替代方案,還可以對隨機過程進(jìn)行推理以執(zhí)行函數(shù)回歸。這種方法最常見的實例是高斯過程( Gaussian process, GP),這是一種具有互補性質(zhì)的神經(jīng)網(wǎng)絡(luò)模型:GP不需要昂貴的訓(xùn)練階段,可以根據(jù)某些觀察結(jié)果對潛在的ground truth函數(shù)進(jìn)行推斷,這使得它們在測試時非常靈活。
此外,GP在未觀察到的位置表示無限多不同的函數(shù),因此,在給定一些觀察結(jié)果的基礎(chǔ)上,它能捕獲其預(yù)測的不確定性。但是,GP在計算上是昂貴的:原始GP對數(shù)據(jù)點數(shù)量是3次方量級的scale,而當(dāng)前最優(yōu)的逼近方法是二次逼近。此外,可用的kernel通常以其函數(shù)形式受到限制,需要一個額外的優(yōu)化過程來為任何給定的任務(wù)確定最合適的kernel及其超參數(shù)。
因此,將神經(jīng)網(wǎng)絡(luò)和隨機過程推理結(jié)合起來,彌補兩種方法分別具有的一些缺點,這作為一種潛在解決方案越來越受到關(guān)注。在這項工作中,DeepMind研究科學(xué)家Marta Garnelo等人的團(tuán)隊提出一種基于神經(jīng)網(wǎng)絡(luò)并學(xué)習(xí)隨機過程逼近的方法,他們稱之為神經(jīng)過程(Neural Processes, NPs)。NP具有GP的一些基本屬性,即它們學(xué)習(xí)在函數(shù)之上建模分布,能夠根據(jù)上下文的觀察估計其預(yù)測的不確定性,并將一些工作從訓(xùn)練轉(zhuǎn)移到測試時間,以實現(xiàn)模型的靈活性。
更重要的是,NP以一種計算效率非常高的方式生成預(yù)測。給定n個上下文點和m個目標(biāo)點,一個經(jīng)過訓(xùn)練的NP的推理對應(yīng)于一個深度神經(jīng)網(wǎng)絡(luò)的前向傳遞,它以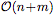 scale,而不是像經(jīng)典GP那樣以
scale,而不是像經(jīng)典GP那樣以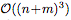 。此外,該模型通過直接從數(shù)據(jù)中學(xué)習(xí)隱式內(nèi)核(implicit kernel)來克服許多函數(shù)設(shè)計上的限制。
。此外,該模型通過直接從數(shù)據(jù)中學(xué)習(xí)隱式內(nèi)核(implicit kernel)來克服許多函數(shù)設(shè)計上的限制。
本研究的主要貢獻(xiàn)是:
提出神經(jīng)過程(Neural Processes),這是一種結(jié)合了神經(jīng)網(wǎng)絡(luò)和隨機過程的優(yōu)點的模型。
我們將神經(jīng)過程(NP)與元學(xué)習(xí)(meta-learning)、深層潛變量模型(deep latent variable models)和高斯過程(Gaussian processes)的相關(guān)工作進(jìn)行了比較。鑒于NP與這些領(lǐng)域多有相關(guān),它們讓許多相關(guān)主題之間可以進(jìn)行比較。
我們通過將NP應(yīng)用于一系列任務(wù),包括一維回歸、真實的圖像補完、貝葉斯優(yōu)化和contextual bandits來證明了NP的優(yōu)點和能力。
神經(jīng)過程模型
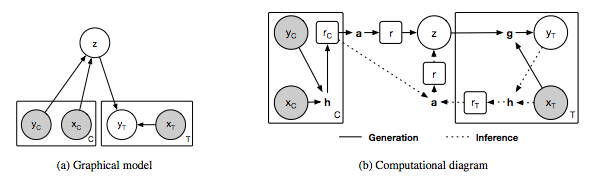
圖1:神經(jīng)過程模型。
(a)neural process的圖模型,x和y分別對應(yīng)于y = f(x)的數(shù)據(jù),C和T分別表示上下文點和目標(biāo)點的個數(shù),z表示全局潛變量。灰色背景表示觀察到變量。
(b)neural process的實現(xiàn)示意圖。圓圈中的變量對應(yīng)于(a)中圖模型的變量,方框中的變量表示NP的中間表示,粗體字母表示以下計算模塊:h - encoder, a - aggregator和g - decoder。在我們的實現(xiàn)中,h和g對應(yīng)于神經(jīng)網(wǎng)絡(luò),a對應(yīng)于均值函數(shù)。實線表示生成過程,虛線表示推理過程。
在我們的NP實現(xiàn)中,我們提供了兩個額外的需求:上下文點的順序和計算效率的不變性(invariance)。
最終的模型可歸結(jié)為以下三個核心組件(見圖1b):
從輸入空間到表示空間的編碼器(encoder)h,輸入是成對的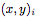 上下文值,并為每對生成一個表示
上下文值,并為每對生成一個表示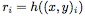 。我們把h參數(shù)化為一個神經(jīng)網(wǎng)絡(luò)。
。我們把h參數(shù)化為一個神經(jīng)網(wǎng)絡(luò)。
聚合器(aggregator)a,匯總編碼器的輸入。
條件解碼器(conditional decoder)g,它將采樣的全局潛變量z以及新的目標(biāo)位置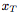 作為輸入,并為對應(yīng)的
作為輸入,并為對應(yīng)的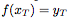 的值輸出預(yù)測
的值輸出預(yù)測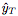 。
。
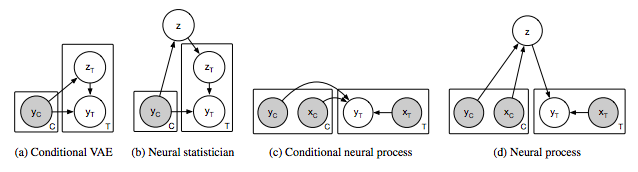
圖2:相關(guān)模型(a-c)和神經(jīng)過程(d)的圖模型。灰色陰影表示觀察到變量。C表示上下文變量,T表示目標(biāo)變量,即給定C時要預(yù)測的變量。
結(jié)果
圖4. MNIST和CelebA上的像素化回歸
左邊的圖展示了一張圖像完成像素化可以框定為一個2-D回歸任務(wù),其中f(像素坐標(biāo))=像素亮度。右邊的圖展示了圖像實現(xiàn)MNIST和CelebA的結(jié)果。頂部的圖像對應(yīng)提供給模型的上下文節(jié)點。為了能夠更清晰的展現(xiàn),未被觀察到的點在MNIST和CelebA中分別標(biāo)記為藍(lán)色和白色。在給定文本節(jié)點的情況下,每一行對應(yīng)一個不同的樣本。隨著文本節(jié)點的增加,預(yù)測像素越來越接近底層像素,且樣本間的方差逐漸減小。

圖5. 用神經(jīng)過程對1-D目標(biāo)函數(shù)進(jìn)行湯普森抽樣
這些圖展示了5次迭代優(yōu)化的過程。每個預(yù)測函數(shù)(藍(lán)色)是通過對一個潛變量(latent variable)的采樣來繪制的,其中該變量的條件是增加文本節(jié)點(黑色)的數(shù)量。底層的ground truth函數(shù)被表示為一條黑色虛線。紅色三角形表示下一個評估點(evaluation point),它對應(yīng)于抽取的NP曲線的最小值。下一個迭代中的紅色圓圈對應(yīng)于這個評估點,它的底層ground truth指將作為NP的一個新文本節(jié)點。

表1. 使用湯普森抽樣對貝葉斯優(yōu)化
優(yōu)化步驟的平均數(shù)需要達(dá)到高斯過程生成的1-D函數(shù)的全局最小值。這些值是通過隨機搜索采取步驟數(shù)來標(biāo)準(zhǔn)化的。使用恰當(dāng)?shù)暮耍╧ernel)的高斯過程的性能等同于性能的上限。
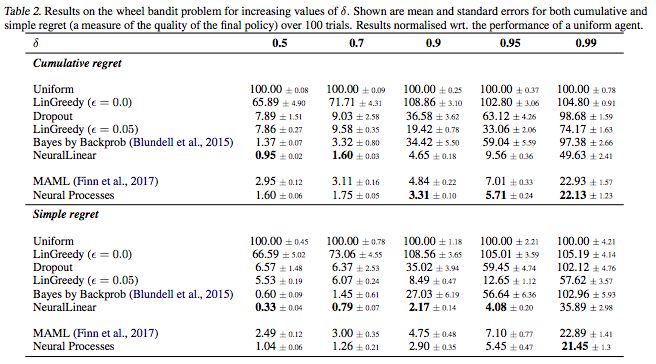
表2. 增加δ值后wheel bandit問題的結(jié)果
結(jié)果表示的是超過100次的累加regret和簡單regret的平均誤差和標(biāo)準(zhǔn)誤差。結(jié)果歸一化了一個統(tǒng)一體(uniform agent)的性能。
討論
我們介紹了一組結(jié)合隨機過程和神經(jīng)網(wǎng)絡(luò)優(yōu)點的模型,叫做神經(jīng)過程。NPs學(xué)會在函數(shù)上表示分布,并且測試時根據(jù)一些文本輸入做出靈活的預(yù)測。NPs不需要親自編寫內(nèi)核,而是直接從數(shù)據(jù)中學(xué)習(xí)隱式度量(implicit measure)。
我們將NPs應(yīng)用于一些列回歸任務(wù),以展示它們的靈活性。本文的目的是介紹NPs,并將它與目前正在進(jìn)行的研究做對比。因此,我們呈現(xiàn)的任務(wù)是雖然種類很多,但是維數(shù)相對較低。將NPs擴(kuò)展到更高的維度,可能會大幅度降低計算復(fù)雜度和數(shù)據(jù)驅(qū)動表示(data driven representations)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100824 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121213 -
DeepMind
+關(guān)注
關(guān)注
0文章
130瀏覽量
10876
原文標(biāo)題:【ICML Oral】DeepMind提出深度學(xué)習(xí)新方向:神經(jīng)過程模型
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論