 一個擁有100多萬臺相變存儲器器件的脈沖神經網絡中對多記憶突觸結構進行了實驗演示
一個擁有100多萬臺相變存儲器器件的脈沖神經網絡中對多記憶突觸結構進行了實驗演示
眾所周知,目前將深度神經網絡和生物神經網絡進行匹配的研究正處于瓶頸期。而近期,IBM公司Irem Boybat等人在《Nature Communication》中發表的文章,有望改善此難題:他們設計了多記憶突觸結構(multi-memristive synaptic architecture),能夠在不增加功率密度的情況下提高突觸的精度,并在一個擁有100多萬臺相變存儲器(PCM)器件的脈沖神經網絡(SNN)中對多記憶突觸結構進行了實驗演示。
我們人類的大腦可以用低于20瓦的能量來驅動,再想想我們的筆記本電腦,大約需要消耗80瓦的能量。在能源效率和體積方面,我們的大腦比最先進的超級計算機要多出幾個數量級。自然,最先進的神經網絡與生物的神經網絡是完全無法抗衡的。造成這個結果的其中一個原因是現今的計算機的架構還是依照馮·諾依曼的思想,即內存和處理工作是分開的。這意味著數據需要不斷來回穿梭,產生熱量并且需要大量的能量——這是一個效率瓶頸。當然,大腦是不存在這個問題的。那么這便是改善該問題的一個突破口。
多記憶突觸(Multi-Memristive Synapse)
多記憶突觸的結構如下圖所示:
多記憶突觸概念
a.一個多記憶突觸的突觸凈權重(net synaptic weight)是由多記憶設備(multiple memristive devices)電導累加和( )表示。為了實現突觸效能(synaptic efficacy),所有設備都使用電壓讀取信號(read voltage signal),V。通過每個設備產生的電流被匯總起來,由此產生突觸輸出(synaptic output)。
)表示。為了實現突觸效能(synaptic efficacy),所有設備都使用電壓讀取信號(read voltage signal),V。通過每個設備產生的電流被匯總起來,由此產生突觸輸出(synaptic output)。
b.為了捕捉突觸可塑性(synaptic plasticity),在任何突觸更新時,都只選擇一個裝置。而突觸的更新是通過改變被選擇設備的電導率來決定的。這個過程是由對所選設備應用恰當的編程脈沖(programming pulse)來實現的。
c.采用一種基于計數的仲裁機制(counter-based arbitration scheme)來選擇用來編程以實現突觸可塑性的設備。此處使用一個最大值等于(表示一個突觸的)設備數量的全局選擇計數器。在任何突觸更新的情況下,被選擇計數器指向的設備將被編程。隨后,選擇計數器增加一個固定的量。除了選擇計數器之外,設置獨立的增強計數器和衰減計數器用來控制增強或衰減事件發生的頻率。
基于PCM設備的多記憶突觸
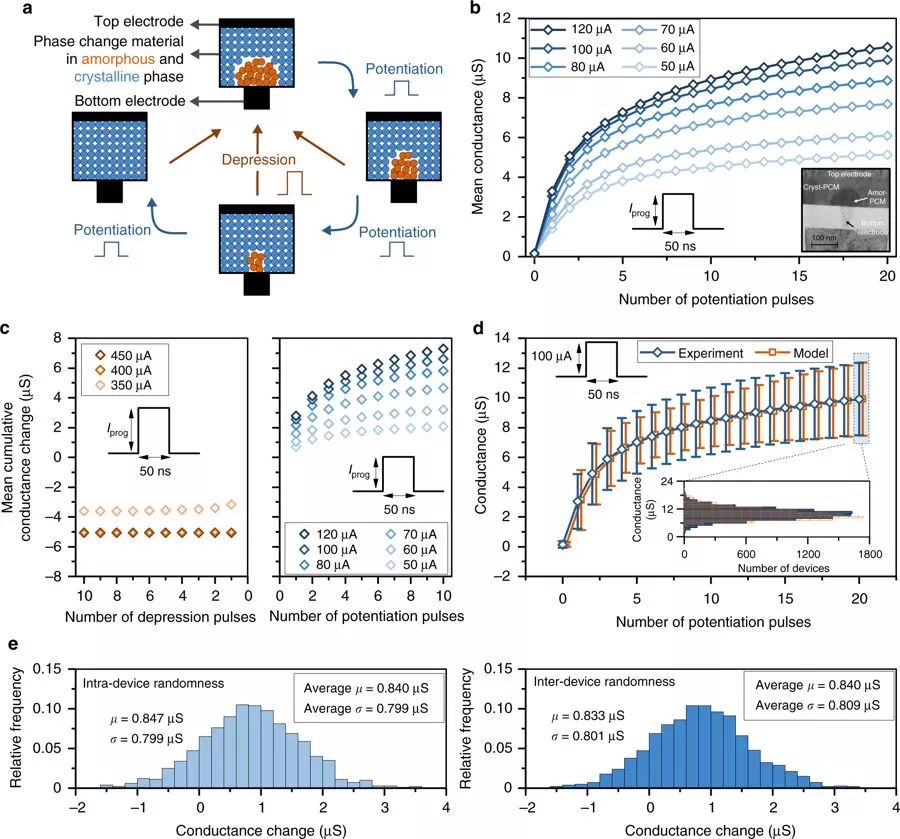
基于相變存儲器(PCM)的突觸
a.PCM器件由夾在頂部和底部電極之間的相變材料層組成。增強脈沖(potentiation pulses)的應用可以逐漸增加晶區(crystalline region)。衰弱脈沖(depression pulse)會產生一個非晶區,不論設備的原始狀態如何都會導致電導的驟然下降。
b.平均電導會隨著不同電流振幅(current amplitude) 的脈沖數而產生變化。每條曲線都是9700個設備電導測量值的平均。插圖顯示了本研究中使用的一種特征化PCM裝置的透射電子顯微圖。
的脈沖數而產生變化。每條曲線都是9700個設備電導測量值的平均。插圖顯示了本研究中使用的一種特征化PCM裝置的透射電子顯微圖。
c.當重復增強和衰弱脈沖時觀察得到的平均累積電導變化。設備的初始電導為~5μS。
d.當脈沖為 =100μA時,給9700臺設備測量電導值的平均和標準誤差(1σ),相應的模型也對應相同的設備數量。插圖顯示了在第20個增強脈沖后電導的分布,以及由模型所得到的對應分布。
=100μA時,給9700臺設備測量電導值的平均和標準誤差(1σ),相應的模型也對應相同的設備數量。插圖顯示了在第20個增強脈沖后電導的分布,以及由模型所得到的對應分布。
e.左圖顯示了在同一個PCM設備上應用1000次的單個脈沖所引起的電導變化的典型分布。該脈沖作為第四個增強脈沖,應用到設備上。用同樣的測量方式在不同的1000臺PCM設備上重復,并在插圖顯示這1000個設備的平均和標準誤差。右圖顯示了單個脈沖在1000個設備上引起的電導變化的典型分布。該脈沖作為第四個增強脈沖應用到設備上。同樣的測量在1000個電導變化中重復進行,插圖顯示了1000個電導變化中的平均和標準誤差。可以看出,設備間和設備內的可變性是可以比較的。
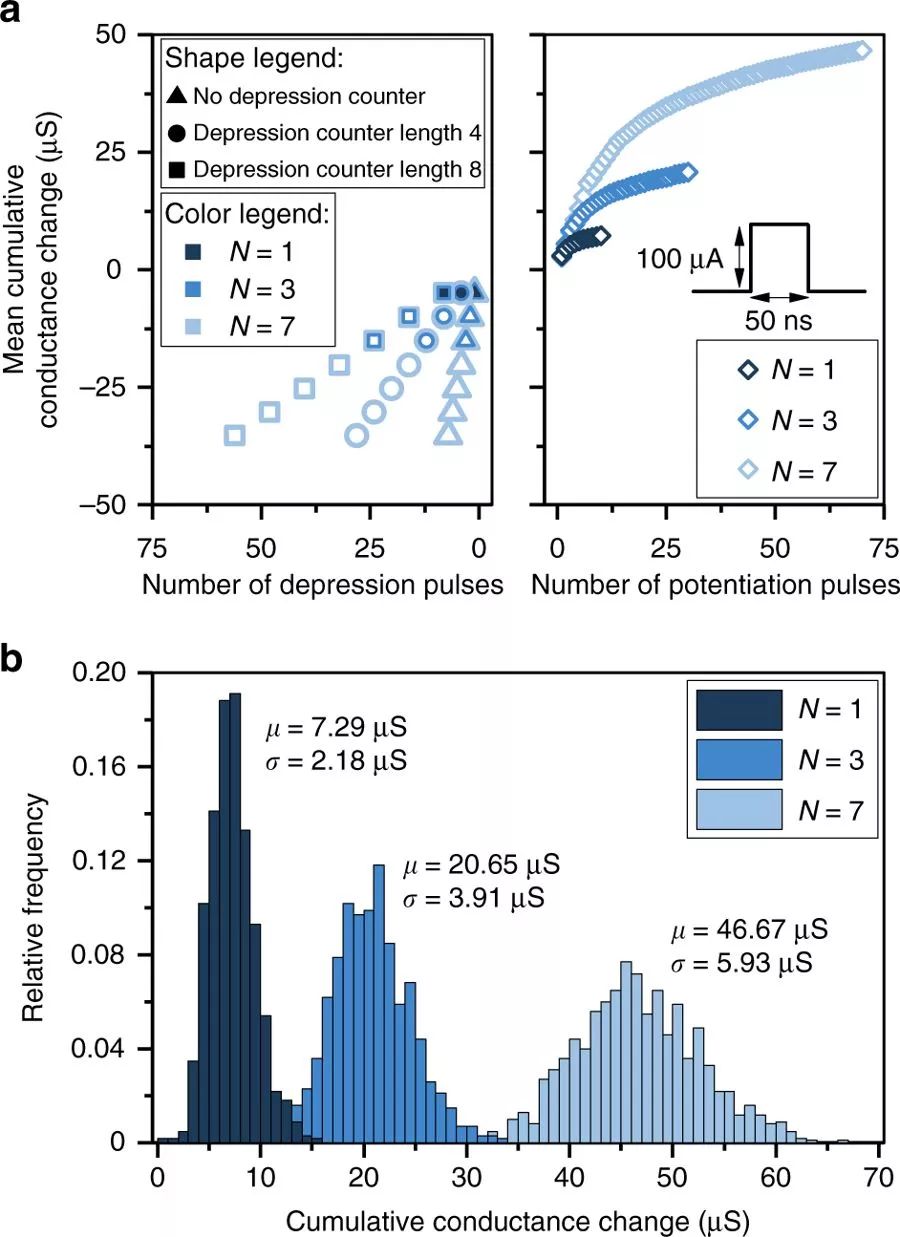
基于PCM的多記憶突觸
a.對第1、3和7PCM設備進行實驗,得到突觸的平均累積電導變化。測量是基于1000個突觸,每個設備的電導都初始化為~5μS。對于增強實驗,脈沖值選擇 μA,而衰弱實驗中,脈沖值選擇=450μA。
μA,而衰弱實驗中,脈沖值選擇=450μA。
b.分別用10、30和70個增強脈沖對第1、3和7個PCM突觸進行應用后,得到累積電導變化的分布。均值和方差幾乎與每個突觸設備數量呈線性關系,可引出一種改良的權重更新解決方案。
手寫體數字分類的仿真效果
多記憶突觸在神經網絡中的應用
a.利用反向傳播訓練人工神經網絡進行手寫數字分類。在輸入層和隱藏層中使用偏置神經元(bias neurons)(白色)。利用PCM器件的非線性電導響應,建立了一種多模態突觸模型,用于表征這些模擬中的突觸權重。增加多記憶突觸裝置的數量(包括有差別結構和無差別結構)可以提高測試的準確性。對五種不同的初始化權重進行了重復模擬。誤差條(error bars)表示標準偏差。虛線顯示了在雙精度浮點軟件上實驗得到的測試精度。
b.使用基于STDP的學習規則對手寫數字分類任務進行了脈沖神經網絡(SNN)的訓練。同樣地,在該模擬中一個多記憶突觸模型表示突觸權重(設備存在有差別和無差別)。網絡的分類精度隨著每個突觸的設備數量而增加。對五種不同的初始化權重進行了重復模擬。誤差條(error bars)表示標準偏差。虛線顯示了在雙精度浮點軟件上實驗得到的測試精度。
時間相關性檢測的實驗結果
多記憶突觸在神經網絡中的實驗演示
a.通過無監督學習訓練了脈沖神經網絡,完成時間相關檢測任務。我們的網絡由1000個多PCM突觸(在硬件上)組成,連接到一個Integrate-And-Fire(I&F)神經元上。突觸接收到由泊松分布產生的基于事件的數據流,作為前突觸(presynaptic)輸入峰值。100個突觸接收到相關數據流,相關系數為0.75,而其他突觸則接收到不相關的數據流。相關的和非相關的數據流都有相同的速率。由此產生的后突觸(postsynaptic)輸出在神經元膜上累積。基于輸入峰值和神經元峰值的時間,使用指數STDP規則進行權重更新的計算。如果期望的權重變化大于(小于)閾值,則應用具有固定振幅的增強(衰弱)脈沖。
b.在實驗結束時,顯示了由N = 1、3和7個PCM設備組成的突觸權重。可以看出,接受相關輸入的突觸的權重往往大于接受不相關輸入的突觸的權重。隨著N的增加,權重分布更加清晰。
c.在實驗的前300個步驟中,是六個突觸權重的變化。隨著每個突觸的設備數量的增加,權重也逐漸增加。
d.在最后的實驗中,顯示的是由144000多元PCM突觸(每個突觸有7臺設備)組成的一個SNN的突觸權重分布。14400個突觸接收到相關的輸入數據流,相關系數為0.75。這次大規模實驗共使用了1008000個PCM設備。下方板顯示了PCM設備模型預測的突觸權重分布。
-
存儲器
+關注
關注
38文章
7518瀏覽量
164081 -
神經網絡
+關注
關注
42文章
4776瀏覽量
100948 -
超級計算機
+關注
關注
2文章
464瀏覽量
41972
原文標題:非馮諾依曼新架構:IBM100萬憶阻器大規模神經網絡加速AI
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
神經網絡教程(李亞非)
非局部神經網絡,打造未來神經網絡基本組件
如何移植一個CNN神經網絡到FPGA中?
卷積神經網絡模型發展及應用
如何進行高效的時序圖神經網絡的訓練
《 AI加速器架構設計與實現》+第一章卷積神經網絡觀后感
基于記憶神經網絡研究
一種改進的多策略粒子群神經網絡在室內定位中應用
如何使用樹結構長短期記憶神經網絡進行金融時間序列預測





 工商網監
工商網監
評論