 人工智能如何處理數據?長期共存的方式大概有兩種
人工智能如何處理數據?長期共存的方式大概有兩種
人工智能如何處理數據?如果把重點放在數據的處理方式上,那么長期共存的方式大概有兩種:
特征學習(feature learning),又叫表示學習(representation learning)或者表征學習 。
特征工程(feature engineering),主要指對于數據的人為處理提取,有時候也代指“洗數據” 。
不難看出,兩者的主要區別在于前者是“學習的過程”,而后者被認為是一門“人為的工程”。用更加白話的方式來說,特征學習是從數據中自動抽取特征或者表示的方法,這個學習過程是模型自主的。而特征工程的過程是人為的對數據進行處理,得到我們認為的、適合后續模型使用的樣式。
舉個簡單的例子,深度學習就是一種表示學習,其學習過程是一種對于有效特征的抽取過程。有用的特征在層層學習后抽取了出來,最終交給了后面的分類層進行預測。
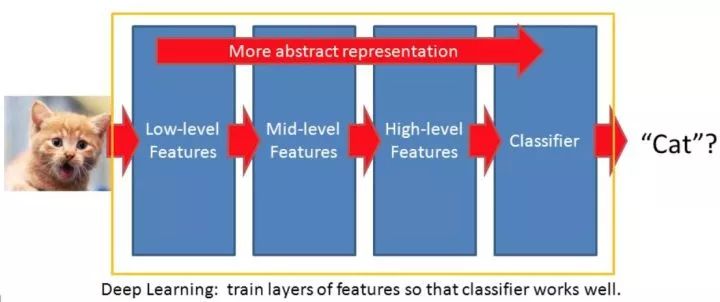
一種比較不嚴謹但直觀的理解可以是,假設一個n層的深度學習網絡,那么輸入數據在被網絡逐層抽象化,靠前的層(1~k)學到了低階特征(low level features),中間層(k+1~m)學到了中階特征(middle level features),而靠后的層上(m+1~n-1)特征達到了高度的抽象化獲得了高階特征(high level features),最終高度的抽象化的特征被應用于分類層(n)上,從而得到了良好的分類結果。
一個常用例子是說卷積網絡的前面幾層可以學到“邊的概念”,之后學到了“角的概念”,并逐步學到了更加抽象復雜的如“圖形的概念”。
下圖就給出了一個直觀的例子,即圖像經過深度網絡學習后得到了高度抽象的有效特征,從而作為預測層的輸入數據,并最終預測目標是一只貓。
另一個常見的例子就是下圖中,深度信念網絡(deep belief network)通過堆疊的受限玻爾茲曼機(Stacked RBM)來學習特征,和cnn不同這個過程是無監督的。將RBF堆疊的原因就是將底層RBF學到的特征逐漸傳遞的上層的RBF上,逐漸抽取復雜的特征。比如下圖從左到右就可以是低層RBF學到的特征到高層RBF學到的復雜特征。在得到這些良好的特征后就可以傳入后端的傳統神經網絡進行學習。

換個不嚴謹的白話說法,深度學習的層層網絡可以從數據中自動學習到有用的、高度抽象的特征,而最終目的是為了幫助分類層做出良好的預測。而深度學習為什么效果好?大概和它能夠有效的抽取到特征脫不了關系。
當然,深度學習的一大特點是其對數據的分布式表示(distributed representation)(*也和稀疏性表示等其他特性有關),最直觀的例子可以是nlp中的word2vec,每個單詞不再是割裂的而互相有了關聯。類似的,不少網絡中的參數共享就是分布式表示,不僅降低了參數量需求也提高對于數據的描述能力。僅看分類層的話,深度學習和其他的機器學習似乎沒有天壤之別,但正因為有了種種良好的表示學習能力使其有了過人之處。
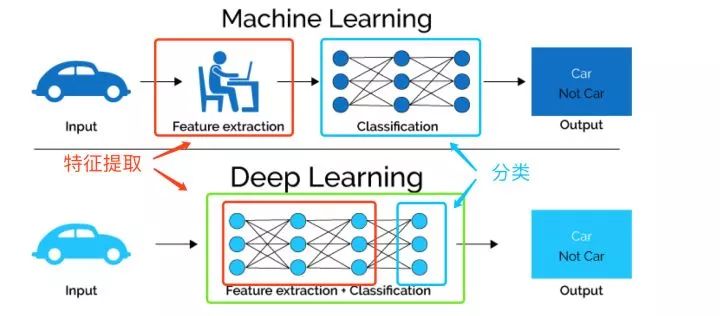
下圖直觀的對比了我們上文提到的兩種特征的學習方式,傳統的機器學習方法主要依賴人工特征處理與提取,而深度學習依賴模型自身去學習數據的表示。
綜上,機器學習模型對于數據的處理可以被大致歸類到兩個方向: 表示學習:模型自動對輸入數據進行學習,得到更有利于使用的特征(*可能同時做出了預測)。
代表的算法大致包括: 深度學習,包括大部分常見的模型如cnn/rnn/dbn,也包括遷移學習等 某些無監督學習算法,如主成分分析(PCA)通過對數據轉化而使得輸入數據更有意義 某些樹模型可以自動的學習到數據中的特征并同時作出預測 特征工程:模型依賴人為處理的數據特征,而模型的主要任務是預測,比如簡單的線性回歸期待良好的輸入數據(如離散化后的數據) 需要注意的是,這種歸類方法是不嚴謹的,僅為了直觀目的而已。并沒有一種劃分說a算法是表示學習,而b算法不是,只是為了一種便于理解的劃分。
因此,大部分的模型都處于純粹的表示學習和純粹的依賴人工特征之間,程度不同而已,很少有絕對的自動學習模型。
那么好奇的讀者會問:
1. 是不是自動的特征抽取(表示學習)總是更好?
答案是不一定的:
在數據量不夠的時候,自動特征抽取的方法往往不如人為的特征工程。
當使用者對于數據和問題有深刻的理解時,人工的特征工程往往效果更好。
一個極端的例子是,在kaggle比賽中的特征工程總能帶來一些提升,因此人工的特征抽取和處理依然有用武之地。
同時也值得注意,表示學習的另一好處是高度抽象化的特征往往可以被應用于相關的領域上,這也是我們常說的遷移學習(transfer learning)的思路。比如有了大量貓的圖片以后,不僅可以用于預測一個物體是不是貓,也可以用于將抽取到的特征再運用于其他類似的領域從而節省數據開銷。
2. 特征學習(表示學習),特征工程,特征選擇,維度壓縮之間有什么關系?
從某個角度來看,表示學習有“嵌入式的特征選擇”(embedded feature selection)的特性,其表示學習嵌入到了模型中。
舉個簡單的例子,決策樹模型在訓練過程中可以同時學習到不同特征的重要性,而這個過程是建模的一部分,是一種嵌入式的特征選擇。
巧合的看,表示學習也是一種嵌入表示(embedded representation)。如維度壓縮方法PCA,也是一種將高維數據找到合適的低維嵌入的過程,前文提到的word2vec也是另一種“嵌入”。至于這種“嵌入”是否必須是高維到低維,不一定但往往是因為特征被抽象化了。以上提到的兩種嵌入一種是對于模型的嵌入,一種是在維度上嵌入,主要是名字上的巧合。
3. 理解不同數據處理方法對于我們有什么幫助?
首先對于模型選擇有一定的幫助: 當我們數據量不大,且對于數據非常理解時,人為的特征處理也就是特征工程是合適的。比如去掉無關數據、選擇適合的數據、合并數據、對數據做離散化等。 當數據量較大或者我們的人為先驗理解很有限時,可以嘗試表示學習,如依賴一氣呵成的深度學習,效果往往不錯。
4. 為什么有的模型擁有表示學習的能力,而有的沒有?
這個問題需要分模型討論。以深度學習為例,特征學習是一種對于模型的理解,并不是唯一的理解,而為什么泛化效果好,還缺乏系統的理論研究。
5. 特征工程指的是對于數據的清理,和學習有什么關系?
此處我們想再次強調的是,這個不是一個嚴謹的科學劃分,是一種直觀的理解。如果所使用的模型擁有對于數據的簡化、特征表示和抽取能力,我們都可以認為它是有表示學習的特性。
至于哪個模型算,哪個模型不算,不必糾結這點。而狹義的特征工程指的是處理缺失值、特征選擇、維度壓縮等各種預處理手段,而從更大的角度看主要目的是提高數據的表示能力。對于數據的人為提煉使其有了更好的表達,這其實是人工的表示學習。
寫在最后是,這篇回答僅僅是一種對于機器學習中數據處理方法的理解,并不是唯一正確的看法。有鑒于機器學習領域的知識更迭速度很快,個人的知識儲備也有限,僅供參考。
-
人工智能
+關注
關注
1793文章
47532瀏覽量
239305 -
機器學習
+關注
關注
66文章
8429瀏覽量
132854 -
深度學習
+關注
關注
73文章
5511瀏覽量
121354
原文標題:人工智能是如何處理數據的?
文章出處:【微信號:jingzhenglizixun,微信公眾號:機器人博覽】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論