 神經網絡、機器翻譯、情感分類和自動評論等研究方向的5篇論文
神經網絡、機器翻譯、情感分類和自動評論等研究方向的5篇論文
第 56 屆計算語言學協會年會ACL 2018將于當地時間7月15-20日在澳大利亞墨爾本舉辦。騰訊AI Lab 今年共有5 篇論文入選,涉及到神經機器翻譯、情感分類和自動評論等研究方向。下面將介紹這 5 篇論文的研究內容。
1、通往魯棒的神經網絡機器翻譯指路(Towards Robust Neural MachineTranslation)
論文地址:https://arxiv.org/abs/1805.06130
在神經機器翻譯(NMT)中,由于引入了循環神經網絡(RNN)和注意機制,上下文中的每個詞都可能影響模型的全局輸出結果,這有些類似于“蝴蝶效應”。也就是說,NMT對輸入中的微小擾動極其敏感,比如將輸入中某個詞替換成其近義詞就可能導致輸出結果發生極大變化,甚至修改翻譯結果的極性。針對這一問題,研究者在本論文中提出使用對抗性穩定訓練來同時增強神經機器翻譯的編碼器與解碼器的魯棒性。
上圖給出了該方法的架構示意,其工作過程為:給定一個輸入句子x,首先生成與其對應的擾動輸入x',接著采用對抗訓練鼓勵編碼器對于x 和x' 生成相似的中間表示,同時要求解碼器端輸出相同的目標句子y。這樣能使得輸入中的微小擾動不會導致目標輸出產生較大差異。
研究者在論文中提出了兩種構造擾動輸入的方法。第一種是在特征級別(詞向量)中加入高斯噪聲;第二種是在詞級別中用近義詞來替換原詞。
研究表明,該框架可以擴展應用于各種不同的噪聲擾動并且不依賴于特定的 NMT 架構。實驗結果表明該方法能夠同時增強神經機器翻譯模型的魯棒性和翻譯質量,下表給出了在NIST 漢語-英語翻譯任務上的大小寫不敏感 BLEU 分數。
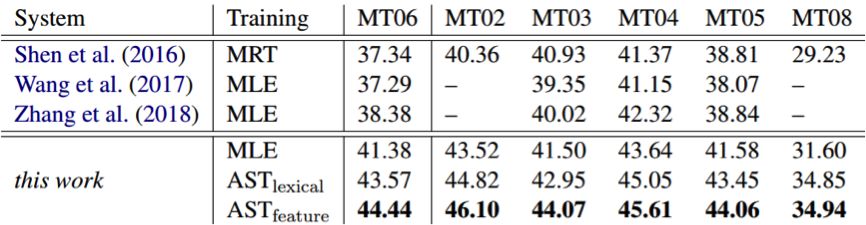
可以看到,研究者使用極大似然估計(MLE)訓練的 NMT 系統優于其它最好模型大約3 BLEU。
2、hyperdoc2vec:超文本文檔的分布式表示(hyperdoc2vec:Distributed Representations of Hypertext Documents)
論文地址:https://arxiv.org/abs/1805.03793
現實世界中很多文檔都具有超鏈接的結構。例如,維基頁面(普通網頁)之間通過URL互相指向,學術論文之間通過引用互相指向。超文檔的嵌入(embedding)可以輔助相關對象(如實體、論文)的分類、推薦、檢索等問題。然而,針對普通文檔的傳統嵌入方法往往偏重建模文本/鏈接網絡中的一個方面,若簡單運用于超文檔,會造成信息丟失。
本論文提出了超文檔嵌入模型在保留必要信息方面應滿足的四個標準并且表明已有的方法都無法同時滿足這些標準。這些標準分別為:
內容感知度(content awareness):超文檔的內容自然在描述該超文檔方面起主要作用
上下文感知度(context awareness):超鏈接上下文通常能提供目標文檔的總結歸納
新信息友好度(newcomer friendliness):對于沒有被其它任何文檔索引的文檔,需要采用適當的方式得到它們的嵌入
語境意圖感知度(context intent awareness):超鏈接周圍的“evaluate... by”這樣的詞通常指示了源超文檔使用該引用的原因
為此,研究者提出了一種新的嵌入模型hyperdoc2vec。不同于大多數已有方法,hyperdoc2vec會為每個超文檔學習兩個向量,以表征其引用其它文檔的情況和被引用的情況。因此,hyperdoc2vec可以直接建模超鏈接或引用情況,而不損失其中包含的信息。下面給出了hyperdoc2vec 模型示意圖:
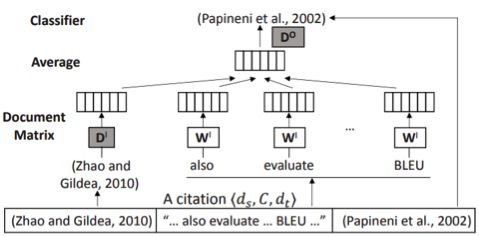
為了評估所學習到的嵌入,研究者在三個論文領域數據集以及論文分類和引用推薦兩個任務上系統地比較了hyperdoc2vec 與其它方法。模型分析和實驗結果都驗證了hyperdoc2vec 在以上四個標準下的優越性。下表展示了在DBLP 上的 F1 分數結果:
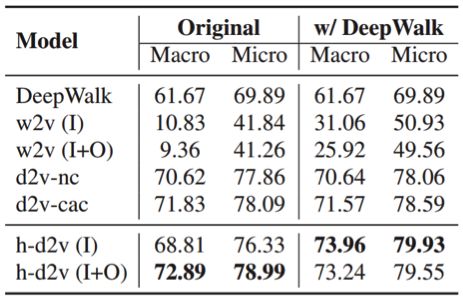
可以看到,添加了 DeepWalk 信息后基本都能得到更優的結果;而不管是否使用了 DeepWalk,hyperdoc2vec的結果都是最優的。
3、TNet:面向評論目標的情感分類架構(TransformationNetworks for Target-Oriented Sentiment Classification)
論文地址:https://arxiv.org/abs/1805.01086
開源項目:https://github.com/lixin4ever/TNet
面向評論目標(opinion target)的情感分類任務是為了檢測用戶對于給定評論實體的情感傾向性。直觀上來說,帶注意機制的循環神經網絡(RNN)很適合處理這類任務,以往的工作也表明基于這類模型的工作確實取得了很好的效果。
研究者在這篇論文中嘗試了一種新思路,即用卷積神經網絡(CNN)替代基于注意機制的RNN去提取最重要的分類特征。
由于CNN 很難捕捉目標實體信息,所以研究者設計了一個特征變換組件來將實體信息引入到單詞的語義表示當中。但這個特征變換過程可能會使上下文信息丟失。針對這一問題,研究者又提出了一種“上下文保留”機制,可將帶有上下文信息的特征和變換之后的特征結合起來。
綜合起來,研究者提出了一種名為目標特定的變換網絡(TNet)的新架構,如下左圖所示。其底部是一個BiLSTM,其可將輸入變換成有上下文的詞表示(即 BiLSTM 的隱藏狀態)。其中部是TNet 的核心部分,由 L 個上下文保留變換(CPT)層構成。最上面的部分是一個可感知位置的卷積層,其首先會編碼詞和目標之間的位置相關性,然后提取信息特征以便分類。
右圖則展示了一個CPT 模塊的細節,其中有一個全新設計的TST 組件,可將目標信息整合進詞表示中。此外,其中還包含一個上下文保留機制。
研究者在三個標準數據集上評估了新提出的框架,結果表明新方法的準確率和F1值全面優于已有方法;下表給出了詳細的實驗結果。
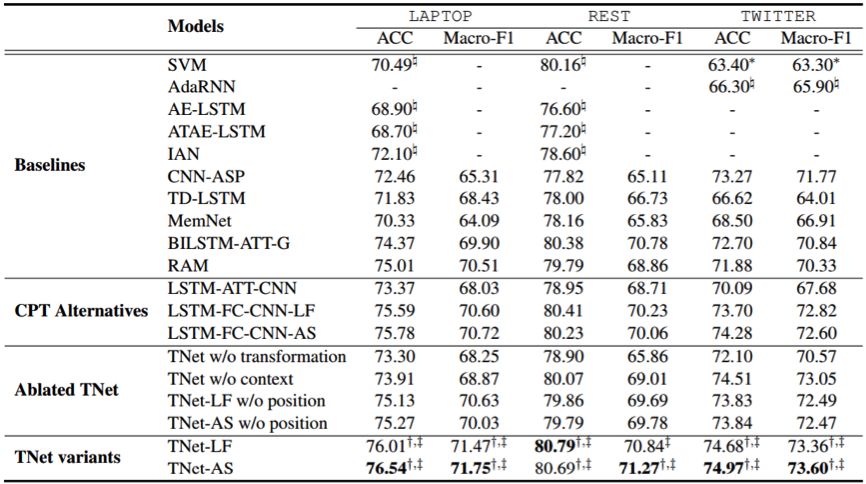
本研究的相關代碼已經開源。
4、兼具領域適應和情感感知能力的詞嵌入學習(Learning Domain-Sensitive andSentiment-Aware Word Embeddings)
論文地址:https://arxiv.org/abs/1805.03801
詞嵌入是一種有效的詞表示方法,已被廣泛用于情感分類任務中。一些現有的詞嵌入方法能夠捕捉情感信息,但是對于來自不同領域的評論,它們不能產生領域適應的詞向量。另一方面,一些現有的方法可以考慮多領域的詞向量自適應,但是它們不能區分具有相似上下文但是情感極性相反的詞。
在這篇論文中,研究者提出了一種學習領域適應和情感感知的詞嵌入(DSE)的新方法,可同時捕獲詞的情感語義和領域信息。本方法可以自動確定和生成領域無關的詞向量和領域相關的詞向量。模型可以區分領域無關的詞和領域相關的詞,從而使我們可以利用來自于多個領域的共同情感詞的信息,并且同時捕獲來自不同領域的領域相關詞的不同語義。
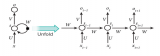
在 DSE 模型中,研究者為詞匯表中的每個詞都設計了一個用于描述該詞是領域無關詞的概率的分布。這個概率分布的推理是根據所觀察的情感和上下文進行的。具體而言,其推理算法結合了期望最大化(EM)方法和一種負采樣方案,其過程如下算法1 所示。

其中,E 步驟使用了貝葉斯規則來評估每個詞的 zw(一個描述領域相關性的隱變量)的后驗分布以及推導目標函數。而在M 步驟中則會使用梯度下降法最大化該目標函數并更新相應的嵌入。
研究者在一個亞馬遜產品評論數據集上進行了實驗,下表給出了評論情感分類的實驗結果:
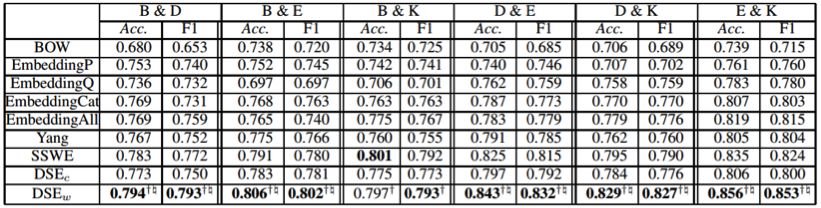
實驗結果表明,本工作提供了一個有效的學習兼具領域適應和情感感知能力的詞嵌入的方法,并提高了在句子層面和詞匯層面的情感分類任務的性能。
5、自動評論文章:任務和數據集(Automatic Article Commenting: theTask and Dataset)
論文地址:https://arxiv.org/abs/1805.03668
公開數據集:https://ai.tencent.com/upload/PapersUploads/article_commenting.tgz
在線文章的評論可以提供延伸的觀點以及提升用戶的參與度。因而,自動產生評論正成為在線論壇和智能聊天機器人中的一個很有價值的功能。
本論文提出了一個新的自動評論文章任務,并為這個任務構建了一個大規模的中文數據集:它包含數百萬條真實評論和一個人工標注的、能夠表達評論質量的子集。下圖給出了這個數據集的統計信息和分類情況:
這個數據集是從騰訊新聞(news.qq.com)收集的。其中每個實例都有一個標題以及文章的文本內容,還有一組讀者評論及輔助信息(sideinformation),該輔助信息中包含編輯為該文章劃分的類別以及每個評論獲得的用戶點贊數。
研究者爬取了 2017 年 4 月到 8 月的新聞文章及相關內容,然后使用Python 庫Jieba 對所有文本進行了token 化,并過濾掉了文本少于 30 詞的短文章和評論數少于 20 的文章。所得到的語料又被分成了訓練集、開發集和測試集。該數據集的詞匯庫大小為1858452。文章標題和內容的平均長度分別為 15 和 554 中文詞(不是漢字)。平均評論長度為17 詞。輔助信息方面,每篇文章都關聯了44 個類別中的一個。每條評論的點贊數量平均在 3.4-5.9 之間,盡管這個數字看起來很小,但該分布表現出了長尾模式——受歡迎的評論的點贊數可達成千上萬。
該數據集已開放下載。
通過引入評論質量的人工偏好,本論文還提出了多個自動評價度量(W-METEOR、W-BLEU、W-ROUGE、W-CIDEr),它們拓展了現有主流的基于參考答案的度量方法而且它們獲得了與人類評價更好的相關度。研究者也演示了該數據集和相關評價度量在檢索和生成模型上的應用。
-
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14886
原文標題:【ACL2018】騰訊AI Lab入選5篇論文解讀:神經機器翻譯、情感分類等
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論