 構建一個決策樹并查看它如何進行預測
構建一個決策樹并查看它如何進行預測
與支持向量機一樣,決策樹也是多功能的機器學習算法,既可以執行分類任務,也可以執行回歸任務,甚至可以執行多輸出任務。 它們是非常強大的算法,能夠完美契合復雜的數據集。 例如,在第 2 章中,我們在加利福尼亞住房數據集上訓練了一個 DecisionTreeRegressor 模型,并對其進行了完美擬合(實際上是對其進行過度擬合)。 決策樹也是隨機森林的基本組成部分(參見第 7 章),它是當今最強大的機器學習算法之一。 在本章中,我們將首先討論如何使用決策樹進行訓練,可視化和預測。 然后快速過一遍 Scikit-Learn 中使用的 CART 訓練算法,并且討論如何調整樹并將其用于回歸任務。 最后,我們會討論決策樹的一些局限性。
訓練和可視化決策樹
為了理解決策樹,我們只需構建一個決策樹并查看它如何進行預測。 以下代碼在鳶尾屬植物數據集上訓練決策樹分類器(請參閱第4章):
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier iris = load_iris() X = iris.data[:, 2:] # petal length and width y = iris.target tree_clf = DecisionTreeClassifier(max_depth=2) tree_clf.fit(X, y)
首先,我們可以通過使用 export_graphviz() 方法輸出一個名為 iris_tree.dot 的圖形定義文件來可視化已訓練出來的決策樹:
from sklearn.tree import export_graphviz export_graphviz( tree_clf, out_file=image_path("iris_tree.dot"), feature_names=iris.feature_names[2:], class_names=iris.target_names, rounded=True, filled=True )
然后,w我們可以使用 graphviz 軟件包中的 dot 命令行工具將此 .dot 文件轉換為各種格式,例如 PDF 或 PNG 。下面的命令行將 .dot 文件轉換為 .png 圖像文件:
$ dot -Tpng iris_tree.dot -o iris_tree.png
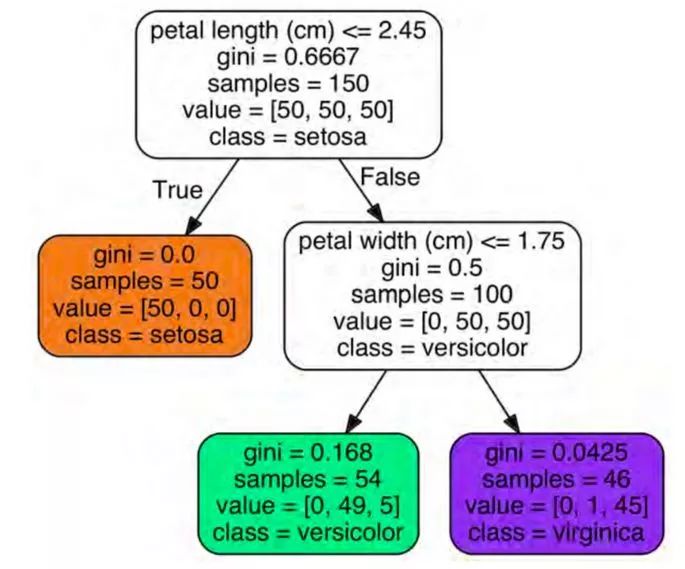
我們的第一個決策樹如圖6-1所示。
預測
讓我們看看圖 6-1 中所呈現的樹如何進行預測。假設我們找到了一種鳶尾花,并且想對它進行分類。我們從根節點開始(深度0,頂部):該節點詢問花朵的花瓣長度是否小于2.45厘米。如果是,則向下移動到根的左側子節點(深度1,左側)。在這種情況下,它是一個葉子節點(即它沒有任何子節點),所以它不會提出任何問題:我們可以簡單地查看該節點的預測類,決策樹預測我們的花是一個Iris-Setosa(class = setosa)。 現在假設你找到另一朵花,但這次花瓣長度大于2.45厘米。我們必須向下移動到根節點的右側(深度1,右側),這不是葉子節點,因此它會提出另一個問題:花瓣寬度是否小于1.75厘米?如果是這樣,那么我們的花很可能是一個 Iris-Versicolor(深度 2,左)。如果不是,它可能是一個 Iris-Virginica(深度 2,右)。就是這么簡單。
決策樹的許多特質之一是它們只需很少的數據準備。 特別是,它們不需要特征縮放或居中。
每個節點的樣本屬性計算它應用于的訓練實例的數量。 例如,100 個訓練樣本的花瓣長度大于 2.45 厘米(深度1,右側),其中 54 個花瓣寬度小于 1.75 厘米(深度2,左側)。 節點的值屬性告訴您此節點適用的每個類的訓練實例數量:例如,右下角節點適用于 0 Iris-Setosa,1 Iris-Versicolor和 45 Iris-Virginica。 最后,節點的 gini 屬性測量它的雜質:如果它適用的所有訓練實例屬于同一個類,則節點是“純的”(gini = 0)。 例如,由于深度 1 左節點僅適用于 Iris-Setosa 訓練實例,因此它是純的,其基尼分數為 0。等式 6-1 顯示訓練算法如何計算出第 i 個節點的 gini 分數Gi。 例如,深度 2 左節點的基尼分數等于
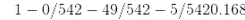
接下來討論另一種純度測量方法。
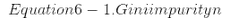
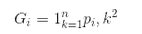
? 其中 p_{i,k} 是第 i 個節點中訓練實例之間的 k 類實例的比率。
Scikit-Learn使用只生成二叉樹的CART算法:非葉節點總是有兩個孩子(即問題只有yes / no的答案)。 但是,其他算法(如ID3)生成的決策樹,可以具有兩個以上孩子的節點。
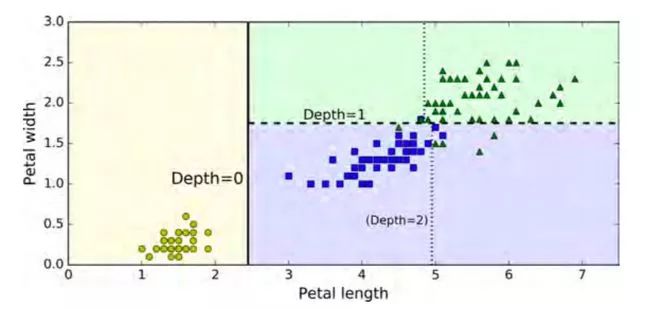
圖 6-2 顯示了決策樹的決策邊界。 粗的垂直線代表根節點(深度 0 )的決定邊界:花瓣長度 = 2.45厘米。 由于左側區域是純粹的(只有Iris-Setosa),所以不能再進一步分割。 然而,右側區域不純,所以深度 1 右節點在花瓣寬度 = 1.75厘米(用虛線表示)分裂。 由于 max_depth 設置為 2,因此決策樹在此處停止。 但是,如果將max_depth設置為3,那么兩個深度 2 節點將分別添加另一個決策邊界(用虛線表示)。
模型解讀:白盒與黑盒
正如你所看到的,決策樹非常直觀,他們的決策很容易解釋。 這種模型通常被稱為白盒模型。 相反,正如我們將看到的,隨機森林或神經網絡通常被認為是黑匣子模型。 他們做出了很好的預測,并且我們可以輕松檢查他們執行的計算以進行這些預測; 然而,通常很難用簡單的術語來解釋為什么會做出預測。 例如,如果一個神經網絡表示一個特定的人出現在圖片上,很難知道究竟是什么促成了這個預測:模型是否認出了這個人的眼睛? 她的嘴? 她的鼻子? 她的鞋子? 或者甚至坐在沙發上? 相反,決策樹提供了好且簡單的分類規則,甚至可以根據需要手動調參(例如,用于花卉分類)。
估計屬于各類的概率
決策樹還可以估計實例屬于特定類 k 的概率:首先遍歷樹來找到此實例的葉子節點,然后返回該節點中類 k 的訓練實例的比率。 例如,假設你已經找到一朵花長 5厘米,寬 1.5 厘米的花朵。 相應的葉子節點是深度為 2 的左節點,因此決策樹應該輸出以下概率:Iris-Setosa(0/54)為 0%,Iris-Versicolor為 (49/54),即 90.7%, Iris-Virginica (5/54),即 9.3 %。 當然,如果你讓它預測類別,它應該輸出Iris-Versicolor(類別 1),因為它具有最高的概率。 讓我們來檢查一下:
>>> tree_clf.predict_proba([[5, 1.5]]) array([[ 0. , 0.90740741, 0.09259259]]) >>> tree_clf.predict([[5, 1.5]]) array([1])
完美! 請注意,估計的概率在圖 6-2 的右下方矩形的其他任何地方都是相同的,比如說花瓣長 6 厘米,寬 1.5 厘米(盡管在這種情況下很明顯它更有可能是 Iris -Virginica)。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646 -
決策樹
+關注
關注
3文章
96瀏覽量
13552
原文標題:【翻譯】Sklearn 與 TensorFlow 機器學習實用指南 —— 第6章 決策樹
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
介紹支持向量機與決策樹集成等模型的應用
一個基于粗集的決策樹規則提取算法
決策樹的構建設計并用Graphviz實現決策樹的可視化
決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
什么是決策樹模型,決策樹模型的繪制方法





 工商網監
工商網監
評論