") 利用Attention模型為圖像生成字幕
利用Attention模型為圖像生成字幕
近期,TensorFlow官方推文推薦了一款十分有趣的項目——用Attention模型生成圖像字幕。而該項目在GitHub社區(qū)也收獲了近十萬“點贊”。項目作者Yash Katariya十分詳細的講述了根據(jù)圖像生成字幕的完整過程,并提供開源的數(shù)據(jù)和代碼,對讀者的學習和研究都帶來了極大的幫助與便利。
TensorFlow官方推文近期力薦了一款在Github上獲贊十萬之多的爆款項目——利用Attention模型為圖像生成字幕。
Image Captioning是一種為圖像生成字幕或者標題的任務。給定一個圖像如下:
我們的目標就是為這張圖生成一個字幕,例如“海上沖浪者(a surfer riding on a wave)”。此處,我們使用一個基于Attention的模型。該模型能夠在生成字幕的時候,讓我們查看它在這個過程中所關注的是圖像的哪一部分。
預測字幕:一個人在海上沖浪(the person is riding a surfboard in the ocean)
該模型的結構與如下鏈接中模型結構類似:https://arxiv.org/abs/1502.03044
代碼使用的是tf.keras和eager execution,讀者可以在鏈接指南中了解更多信息。
tf.keras:https://www.tensorflow.org/guide/keras
eager execution:https://www.tensorflow.org/guide/eager
這款筆記是一種端到端(end-to-end)的樣例。如果你運行它,將會下載MS-COCO數(shù)據(jù)集,使用Inception V3來預處理和緩存圖像的子集、訓練出編碼-解碼模型,并使用它來在新的圖像上生成字幕。
如果你在Colab上面運行,那么TensorFlow的版本需要大于等于1.9。
在下面的示例中,我們訓練先訓練較少的數(shù)據(jù)集作為例子。在單個P100 GPU上訓練這個樣本大約需要2個小時。我們先訓練前30,000個字幕(對應約20,000個圖像,取決于shuffling,因為數(shù)據(jù)集中每個圖像有多個字幕)。
# Import TensorFlow and enable eager execution# This code requires TensorFlow version >=1.9import tensorflow as tf tf.enable_eager_execution()# We'll generate plots of attention in order to see which parts of an image# our model focuses on during captioningimport matplotlib.pyplot as plt# Scikit-learn includes many helpful utilitiesfrom sklearn.model_selection import train_test_splitfrom sklearn.utils import shuffleimport reimport numpy as npimport osimport timeimport jsonfrom glob import globfrom PIL import Imageimport pickle下載并準備MS-COCO數(shù)據(jù)集
我們將使用MS-COCO數(shù)據(jù)集來訓練我們的模型。 此數(shù)據(jù)集包含的圖像大于82,000個,每個圖像都標注了至少5個不同的字幕。 下面的代碼將自動下載并提取數(shù)據(jù)集。
注意:需做好提前下載的準備工作。 該數(shù)據(jù)集大小為13GB!!!
annotation_zip = tf.keras.utils.get_file('captions.zip', cache_subdir=os.path.abspath('.'), origin = 'https://images.cocodataset.org/annotations/annotations_trainval2014.zip', extract = True) annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'name_of_zip = 'train2014.zip'if not os.path.exists(os.path.abspath('.') + '/' + name_of_zip): image_zip = tf.keras.utils.get_file(name_of_zip, cache_subdir=os.path.abspath('.'), origin = 'https://images.cocodataset.org/zips/train2014.zip', extract = True) PATH = os.path.dirname(image_zip)+'/train2014/'else: PATH = os.path.abspath('.')+'/train2014/'限制數(shù)據(jù)集大小以加速訓練(可選)
在此示例中,我們將選擇30,000個字幕的子集,并使用這些字幕和相應的圖像來訓練我們的模型。 當然,如果你選擇使用更多數(shù)據(jù),字幕質量將會提高。
# read the json filewith open(annotation_file, 'r') as f: annotations = json.load(f)# storing the captions and the image name in vectorsall_captions = [] all_img_name_vector = []for annot in annotations['annotations']: caption = '
接下來,我們將使用InceptionV3(在Imagenet上預訓練過的)對每個圖像進行分類。 我們將從最后一個卷積層中提取特征。
首先,我們需要將圖像按照InceptionV3的要求轉換格式:
調整圖像大小為(299,299)
使用preprocess_input方法將像素放置在-1到1的范圍內(以匹配用于訓練InceptionV3的圖像的格式)。
def load_image(image_path): img = tf.read_file(image_path) img = tf.image.decode_jpeg(img, channels=3) img = tf.image.resize_images(img, (299, 299)) img = tf.keras.applications.inception_v3.preprocess_input(img) return img, image_path初始化InceptionV3并加載預訓練的Imagenet權重
為此,我們將創(chuàng)建一個tf.keras模型,其中輸出層是InceptionV3體系結構中的最后一個卷積層。
每個圖像都通過networkd傳遞(forward),我們將最后得到的矢量存儲在字典中(image_name -- > feature_vector)。
因為我們在這個例子中使用了Attention,因此我們使用最后一個卷積層。 該層的輸出形狀為8x8x2048。
在所有圖像通過network傳遞之后,我們挑選字典并將其保存到磁盤。
image_model = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet') new_input = image_model.input hidden_layer = image_model.layers[-1].output image_features_extract_model = tf.keras.Model(new_input, hidden_layer)將InceptionV3中提取出來的特征進行緩存
我們將使用InceptionV3預處理每個圖像并將輸出緩存到磁盤。 緩存RAM中的輸出會更快但內存會比較密集,每個映像需要8 x 8 x 2048個浮點數(shù)。 這將超出Colab的內存限制(盡管這些可能會發(fā)生變化,但實例似乎目前有大約12GB的內存)。
通過更復雜的緩存策略(例如,通過分割圖像以減少隨機訪問磁盤I / O)可以改善性能(代價是編寫更多的代碼)。
使用一個GPU在Colab中運行大約需要10分鐘。 如果你想查看進度條,可以:安裝tqdm(!pip install tqdm),然后將下面這行代碼:
for img,path in img_dataset:
改為:
for img,path in dqtm(img_dataset):
# getting the unique imagesencode_train = sorted(set(img_name_vector))# feel free to change the batch_size according to your system configurationimage_dataset = tf.data.Dataset.from_tensor_slices( encode_train).map(load_image).batch(16)for img, path in image_dataset: batch_features = image_features_extract_model(img) batch_features = tf.reshape(batch_features, (batch_features.shape[0], -1, batch_features.shape[3])) for bf, p in zip(batch_features, path): path_of_feature = p.numpy().decode("utf-8") np.save(path_of_feature, bf.numpy())預處理并標注字幕
首先,我們將標記字幕(例如,通過空格拆分)。 這將為我們提供數(shù)據(jù)中所有單個單詞的詞匯表(例如,“沖浪”,“足球”等)。
接下來,我們將詞匯量限制在前5,000個單詞以節(jié)省內存。 我們將用“UNK”(對應于unknown)替換所有其他單詞。
最后,我們創(chuàng)建一個word→index的映射,反之亦然。
然后我們將所有序列填充到與最長序列相同的長度。
# This will find the maximum length of any caption in our datasetdef calc_max_length(tensor): return max(len(t) for t in tensor)# The steps above is a general process of dealing with text processing# choosing the top 5000 words from the vocabularytop_k = 5000tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k, oov_token="
# Create training and validation sets using 80-20 split
img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,
cap_vector,
test_size=0.2,
random_state=0)
len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)
圖片和字幕已就位!
接下來,創(chuàng)建一個tf.data數(shù)據(jù)集來訓練模型。
# feel free to change these parameters according to your system's configuration
BATCH_SIZE = 64
BUFFER_SIZE = 1000
embedding_dim = 256
units = 512
vocab_size = len(tokenizer.word_index)
# shape of the vector extracted from InceptionV3 is (64, 2048)
# these two variables represent that
features_shape = 2048
attention_features_shape = 64
# loading the numpy files
def map_func(img_name, cap):
img_tensor = np.load(img_name.decode('utf-8')+'.npy')
return img_tensor, cap
dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))
# using map to load the numpy files in parallel
# NOTE: Be sure to set num_parallel_calls to the number of CPU cores you have
# https://www.tensorflow.org/api_docs/python/tf/py_func
dataset = dataset.map(lambda item1, item2: tf.py_func(
map_func, [item1, item2], [tf.float32, tf.int32]), num_parallel_calls=8)
# shuffling and batching
dataset = dataset.shuffle(BUFFER_SIZE)
# https://www.tensorflow.org/api_docs/python/tf/contrib/data/batch_and_drop_remainder
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(1)
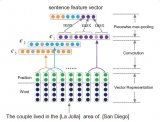
我們的模型
有趣的是,下面的解碼器與具有Attention的神經(jīng)機器翻譯的示例中的解碼器相同。
模型的結構靈感來源于上述的那篇文獻:
在這個示例中,我們從InceptionV3的下卷積層中提取特征,給出了一個形狀向量(8,8,2048)。
我們將其壓成(64,2048)的形狀。
然后該矢量經(jīng)過CNN編碼器(由單個完全連接的層組成)處理。
用RNN(此處為GRU)處理圖像,來預測下一個單詞。
def gru(units):
# If you have a GPU, we recommend using the CuDNNGRU layer (it provides a
# significant speedup).
if tf.test.is_gpu_available():
return tf.keras.layers.CuDNNGRU(units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
else:
return tf.keras.layers.GRU(units,
return_sequences=True,
return_state=True,
recurrent_activation='sigmoid',
recurrent_initializer='glorot_uniform')
classBahdanauAttention(tf.keras.Model):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, features, hidden):
# features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)
# hidden shape == (batch_size, hidden_size)
# hidden_with_time_axis shape == (batch_size, 1, hidden_size)
hidden_with_time_axis = tf.expand_dims(hidden, 1)
# score shape == (batch_size, 64, hidden_size)
score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))
# attention_weights shape == (batch_size, 64, 1)
# we get 1 at the last axis because we are applying score to self.V
attention_weights = tf.nn.softmax(self.V(score), axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * features
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
class CNN_Encoder(tf.keras.Model):
# Since we have already extracted the features and dumped it using pickle
# This encoder passes those features through a Fully connected layer
def __init__(self, embedding_dim):
super(CNN_Encoder, self).__init__()
# shape after fc == (batch_size, 64, embedding_dim)
self.fc = tf.keras.layers.Dense(embedding_dim)
def call(self, x):
x = self.fc(x)
x = tf.nn.relu(x)
return x
class RNN_Decoder(tf.keras.Model):
def __init__(self, embedding_dim, units, vocab_size):
super(RNN_Decoder, self).__init__()
self.units = units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.units)
self.fc1 = tf.keras.layers.Dense(self.units)
self.fc2 = tf.keras.layers.Dense(vocab_size)
self.attention = BahdanauAttention(self.units)
def call(self, x, features, hidden):
# defining attention as a separate model
context_vector, attention_weights = self.attention(features, hidden)
# x shape after passing through embedding == (batch_size, 1, embedding_dim)
x = self.embedding(x)
# x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# passing the concatenated vector to the GRU
output, state = self.gru(x)
# shape == (batch_size, max_length, hidden_size)
x = self.fc1(output)
# x shape == (batch_size * max_length, hidden_size)
x = tf.reshape(x, (-1, x.shape[2]))
# output shape == (batch_size * max_length, vocab)
x = self.fc2(x)
return x, state, attention_weights
def reset_state(self, batch_size):
return tf.zeros((batch_size, self.units))
encoder = CNN_Encoder(embedding_dim)
decoder = RNN_Decoder(embedding_dim, units, vocab_size)
optimizer = tf.train.AdamOptimizer()
# We are masking the loss calculated for padding
def loss_function(real, pred):
mask = 1 - np.equal(real, 0)
loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=real, logits=pred) * mask
return tf.reduce_mean(loss_)
開始訓練
我們提取存儲在各個.npy文件中的特征,然后通過編碼器傳遞這些特征。
編碼器輸出,向解碼器傳奇隱藏狀態(tài)(初始化為0)和解碼器輸入(開始標記)。
解碼器返回預測值并隱藏狀態(tài)。
然后將解碼器隱藏狀態(tài)傳遞回模型,并使用預測值來計算損失。
使用teacher-forcing決定解碼器的下一個輸入(teacher-forcing是一種將目標單詞作為下一個輸入傳遞給解碼器的技術)。
最后一步是計算gradients并將其應用于優(yōu)化器并反向傳遞。
# adding this in a separate cell because if you run the training cell
# many times, the loss_plot array will be reset
loss_plot = []
EPOCHS = 20
for epoch in range(EPOCHS):
start = time.time()
total_loss = 0
for (batch, (img_tensor, target)) in enumerate(dataset):
loss = 0
# initializing the hidden state for each batch
# because the captions are not related from image to image
hidden = decoder.reset_state(batch_size=target.shape[0])
dec_input = tf.expand_dims([tokenizer.word_index['
with tf.GradientTape() as tape:
features = encoder(img_tensor)
for i in range(1, target.shape[1]):
# passing the features through the decoder
predictions, hidden, _ = decoder(dec_input, features, hidden)
loss += loss_function(target[:, i], predictions)
# using teacher forcing
dec_input = tf.expand_dims(target[:, i], 1)
total_loss += (loss / int(target.shape[1]))
variables = encoder.variables + decoder.variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables), tf.train.get_or_create_global_step())
if batch % 100 == 0:
print ('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,
batch,
loss.numpy() / int(target.shape[1])))
# storing the epoch end loss value to plot later
loss_plot.append(total_loss / len(cap_vector))
print ('Epoch {} Loss {:.6f}'.format(epoch + 1,
total_loss/len(cap_vector)))
print ('Time taken for 1 epoch {} sec '.format(time.time() - start))
plt.plot(loss_plot)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Loss Plot')
plt.show()
字幕“誕生”了!
評估函數(shù)類似于training-loop(除了不用teacher-forcing外)。
在每個時間步驟對解碼器的輸入是其先前的預測以及隱藏狀態(tài)和編碼器輸出。
當模型預測到最后一個token的時候停止預測。
每個時間步驟都存儲attention權重。
def evaluate(image):
attention_plot = np.zeros((max_length, attention_features_shape))
hidden = decoder.reset_state(batch_size=1)
temp_input = tf.expand_dims(load_image(image)[0], 0)
img_tensor_val = image_features_extract_model(temp_input)
img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))
features = encoder(img_tensor_val)
dec_input = tf.expand_dims([tokenizer.word_index['
result = []
for i in range(max_length):
predictions, hidden, attention_weights = decoder(dec_input, features, hidden)
attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()
predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()
result.append(index_word[predicted_id])
if index_word[predicted_id] == '
return result, attention_plot
dec_input = tf.expand_dims([predicted_id], 0)
attention_plot = attention_plot[:len(result), :]
return result, attention_plot
def plot_attention(image, result, attention_plot):
temp_image = np.array(Image.open(image))
fig = plt.figure(figsize=(10, 10))
len_result = len(result)
for l in range(len_result):
temp_att = np.resize(attention_plot[l], (8, 8))
ax = fig.add_subplot(len_result//2, len_result//2, l+1)
ax.set_title(result[l])
img = ax.imshow(temp_image)
ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())
plt.tight_layout()
plt.show()
# captions on the validation set
rid = np.random.randint(0, len(img_name_val))
image = img_name_val[rid]
real_caption = ' '.join([index_word[i] for i in cap_val[rid] if i notin [0]])
result, attention_plot = evaluate(image)
print ('Real Caption:', real_caption)
print ('Prediction Caption:', ' '.join(result))
plot_attention(image, result, attention_plot)
# opening the image
Image.open(img_name_val[rid])
在你的圖像上試一下吧!
-
圖像
+關注
關注
2文章
1084瀏覽量
40465 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24701
原文標題:TensorFlow官方力推、GitHub爆款項目:用Attention模型自動生成圖像字幕
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于擴散模型的圖像生成過程

利用Matlab的simulink搭建模型生成C代碼
利用Matlab的simulink搭建模型生成C代碼
為什么生成模型值得研究
YouTube測試谷歌字幕自動生成技術
深度學習模型介紹,Attention機制和其它改進
日本YouTube推出字幕生成系統(tǒng)
Eros Now利用Google Cloud實現(xiàn)AI驅動的字幕功能
基于生成器的圖像分類對抗樣本生成模型

一種基于改進的DCGAN生成SAR圖像的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論