 關于大端模式與小端模式的介紹
關于大端模式與小端模式的介紹
數據組織是指數據的傳送順序。目前常見的32為處理器的數據總線粒度為1字節,在傳送時,一個32位數據的最高字節可以放在數據總線的最低8位傳送,也可以放在數據總線的最高8位傳送,因此出現了大端和小端兩種數據組織方法。大端是指一個數據的最高位放在數據總線的最低位傳送或者放在地址較小的存儲器位置存儲;小端是指一個數據的最高位放在數據總線的最高位傳送或者放在地址較高的存儲器位置存儲。Wishbone同時支持大端和小端兩者數據組織方式。當數據總線的粒度和寬度相同時,大端和小端是一樣的。
大端模式
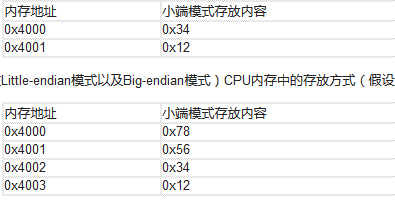
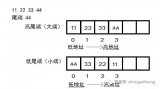
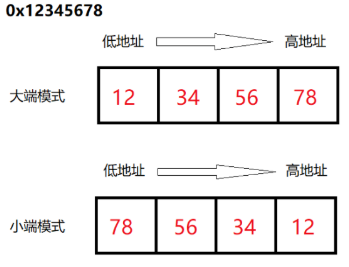
所謂的大端模式(Big-endian),是指數據的高字節,保存在內存的低地址中,而數據的低字節,保存在內存的高地址中,這樣的存儲模式有點兒類似于把數據當作字符串順序處理:地址由小向大增加,而數據從高位往低位放;
在大端模式下,前32位應該這樣讀: e6 84 6c 4e ( 假設int占4個字節)
記憶方法: 地址的增長順序與值的增長順序相反
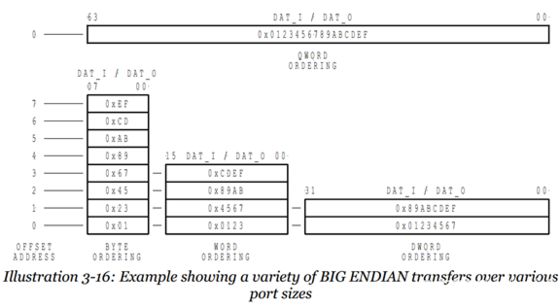
圖2一個大端的例子
小端模式
所謂的小端模式(Little-endian),是指數據的高字節保存在內存的高地址中,而數據的低字節保存在內存的低地址中,這種存儲模式將地址的高低和數據位權有效地結合起來,高地址部分權值高,低地址部分權值低,和我們的邏輯方法一致。
例子:
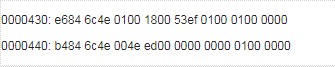
在小端模式下,前32位應該這樣讀: 4e 6c 84 e6( 假設int占4個字節)
記憶方法: 地址的增長順序與值的增長順序相同
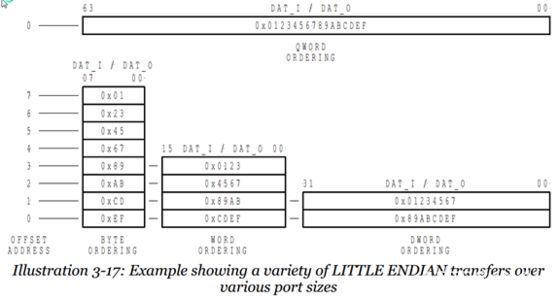
圖3一個小端的例子
現狀
目前Intel的80x86系列芯片是唯一還在堅持使用小端的芯片,ARM芯片默認采用小端,但可以切換為大端;而MIPS等芯片要么采用全部大端的方式儲存,要么提供選項支持大端——可以在大小端之間切換。另外,對于大小端的處理也和編譯器的實現有關,在C語言中,默認是小端(但在一些對于單片機的實現中卻是基于大端,比如Keil 51C),Java是平臺無關的,默認是大端。在網絡上傳輸數據普遍采用的都是大端。[
這兩者數據組織方式在一般文獻中都可以找到。總線標準只定義接口的通信協議,而數據的組織本質上取決于主設備和從設備的設計。有時需要將大端和小端的接口互聯起來,圖22給出了將數據組織為大端的IP A和數據組織為大端的IP B相連的情形。IP A和IP B的數據總線寬度都是32為,粒度為8位。
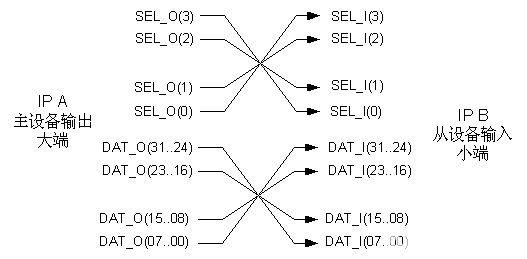
圖4 22大端和小端的接口互聯
-
數據總線
+關注
關注
2文章
57瀏覽量
17588 -
小端模式
+關注
關注
0文章
3瀏覽量
6357
原文標題:【博文連載】Wishbone總線周期之數據組織
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
cpu的大端模式小端模式優劣對比
大端模式與小端模式分析
tms320c6713的大小端模式介紹
存儲器的大端模式和小端模式

你真的懂CPU的大端和小端模式嗎?

ARM大小端模式






 工商網監
工商網監
評論