 基本的k-means算法流程
基本的k-means算法流程
1、引言
k-means與kNN雖然都是以k打頭,但卻是兩類算法——kNN為監督學習中的分類算法,而k-means則是非監督學習中的聚類算法;二者相同之處:均利用近鄰信息來標注類別。
聚類是數據挖掘中一種非常重要的學習流派,指將未標注的樣本數據中相似的分為同一類,正所謂“物以類聚,人以群分”嘛。k-means是聚類算法中最為簡單、高效的,核心思想:由用戶指定k個初始質心(initial centroids),以作為聚類的類別(cluster),重復迭代直至算法收斂。
2、基本算法
在k-means算法中,用質心來表示cluster;且容易證明k-means算法收斂等同于所有質心不再發生變化。基本的k-means算法流程如下:
選取k個初始質心(作為初始cluster); repeat: 對每個樣本點,計算得到距其最近的質心,將其類別標為該質心所對應的cluster; 重新計算k個cluser對應的質心; until 質心不再發生變化
對于歐式空間的樣本數據,以平方誤差和(sum of the squared error, SSE)作為聚類的目標函數,同時也可以衡量不同聚類結果好壞的指標:

表示樣本點 到cluster
到cluster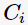 的質心
的質心 距離平方和;最優的聚類結果應使得SSE達到最小值。
距離平方和;最優的聚類結果應使得SSE達到最小值。
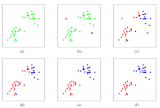
下圖中給出了一個通過4次迭代聚類3個cluster的例子:

k-means存在缺點:
k-means是局部最優的,容易受到初始質心的影響;比如在下圖中,因選擇初始質心不恰當而造成次優的聚類結果(SSE較大):
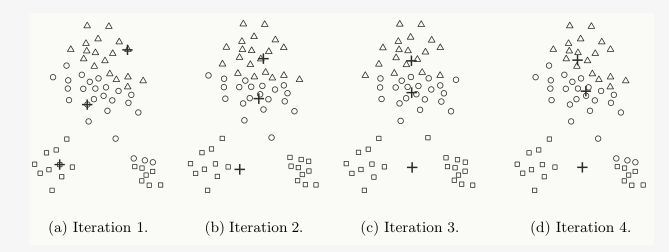
同時,k值的選取也會直接影響聚類結果,最優聚類的k值應與樣本數據本身的結構信息相吻合,而這種結構信息是很難去掌握,因此選取最優k值是非常困難的。
3、優化
為了解決上述存在缺點,在基本k-means的基礎上發展而來二分 (bisecting) k-means,其主要思想:一個大cluster進行分裂后可以得到兩個小的cluster;為了得到k個cluster,可進行k-1次分裂。算法流程如下:
初始只有一個cluster包含所有樣本點; repeat: 從待分裂的clusters中選擇一個進行二元分裂,所選的cluster應使得SSE最小; until 有k個cluster
上述算法流程中,為從待分裂的clusters中求得局部最優解,可以采取暴力方法:依次對每個待分裂的cluster進行二元分裂(bisect)以求得最優分裂。二分k-means算法聚類過程如圖:

從圖中,我們觀察到:二分k-means算法對初始質心的選擇不太敏感,因為初始時只選擇一個質心。
-
函數
+關注
關注
3文章
4331瀏覽量
62622 -
聚類算法
+關注
關注
2文章
118瀏覽量
12129 -
K-means
+關注
關注
0文章
28瀏覽量
11309
原文標題:【十大經典數據挖掘算法】k-means
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
改進的k-means聚類算法在供電企業CRM中的應用
Web文檔聚類中k-means算法的改進
K-means+聚類算法研究綜述

基于密度的K-means算法在聚類數目中應用
K-Means算法改進及優化
基于布谷鳥搜索的K-means聚類算法
熵加權多視角核K-means算法
k-means算法原理解析





 工商網監
工商網監
評論