 結合深度神經網絡和決策樹的完美方案
結合深度神經網絡和決策樹的完美方案
UCL、帝國理工和微軟的研究人員合作,將神經網絡與決策樹結合在一起,提出了一種新的自適應神經樹模型ANT,打破往局限,可以基于BP算法做訓練,在MNIST和CIFAR-10數據集上的準確率高達到99%和90%。
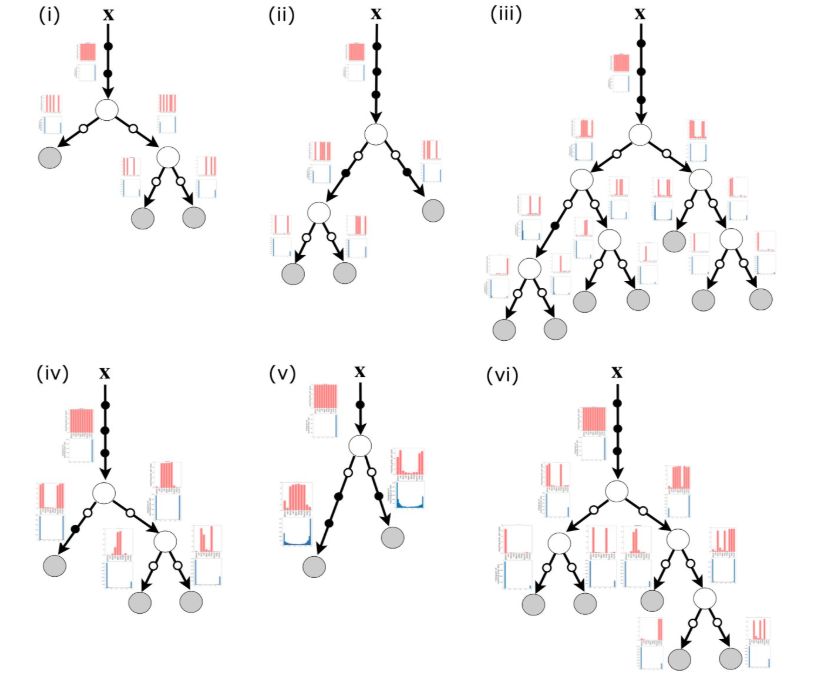
將神經網絡和決策樹結合在一起的自適應神經樹
神經網絡的成功關鍵在于其表示學習的能力。但是隨著網絡深度的增加,模型的容量和復雜度也不斷提高,訓練和調參耗時耗力。
另一方面,決策樹模型通過學習數據的分層結構,可以根據數據集的性質調整模型的復雜度。決策樹的可解釋性更高,無論是大數據還是小數據表現都很好。
如何借鑒兩者的優缺點,設計新的深度學習模型,是目前學術界關心的課題之一。
舉例來說,去年南大周志華教授等人提出“深度森林”,最初采用多層級聯決策樹結構(gcForest),探索深度神經網絡以外的深度模型。如今,深度深林系列已經發表了三篇論文,第三篇提出了可做表示學習的多層GBDT森林(mGBDT),在很多神經網絡不適合的應用領域中具有巨大的潛力。
日前,UCL、帝國理工和微軟的研究人員合作,提出了另一種新的思路,他們將決策樹和神經網絡結合到一起,生成了一種完全可微分的決策樹(由transformer、router和solver組成)。
他們將這種新的模型稱為“自適應神經樹”(Adaptive Neural Trees,ANT),這種新模型能夠根據驗證誤差,或者加深或者分叉。在推斷過程中,整個模型都可以作為一種較慢的分層混合專家系統,也可以是快速的決策樹模型。
自適應神經樹結合了神經網絡和決策樹的優點,尤其在處理分層數據結構方面,在CIFAR-10數據集上分類取得了99%的準確率。
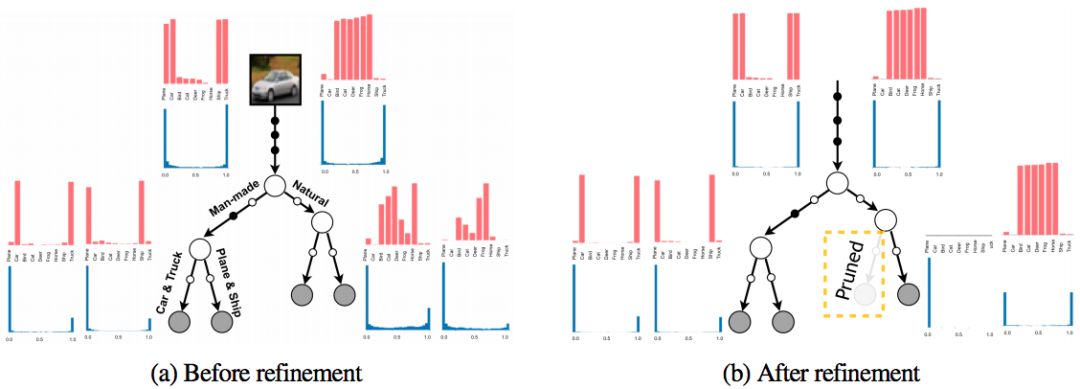
在 refinement 之前(a)和之后(b),ANT各個節點處的類別分布(紅色)和路徑概率(藍色)。(a)表明學習模型學會了可解釋的層次結構,在同一分支上對語義相似的圖像進行分組。(b)表明 refinement 階段極化路徑概率,修剪分支。來源:研究論文
論文共同第一作者、帝國理工學院博士生Kai Arulkumaran表示,更寬泛地看,ANT也屬于自適應計算(adaptive computation paradigm)的一種。由于數據的性質是各不相同的,因此我們在處理這些數據時,也要考慮不同的方式。
新智元亦采訪了“深度森林”系列研究的參與者之一、南京大學博士生馮霽。馮霽表示,這篇工作這是基于軟決策樹(可微分決策樹)這條路的一個最新探索。具體而言,將神經網絡同時嵌入到決策路徑和節點中,以提升單顆決策樹的能力。由于該模型可微分,整個系統可通過BP算法進行訓練。
“ANT的出發點與mGBDT類似,都是期望將神經網絡的表示學習和決策樹的特點做一個結合,不過,ANT依舊依賴神經網絡BP算法進行的實現,”馮霽說:“而深度森林(gcForest/mGBDT)的目的是探索構建多層不可微分系統的能力,換言之,沒有放棄樹模型非參/不可微這個特性,二者的動機和目標有所不同。”
ANT論文的其中一位作者、微軟研究院的Antonio Criminisi,在2011年與人合著了一本專著《決策森林:分類、回歸、密度估計、流形學習和半監督學習的統一框架》,可以稱得上領域大牛。
ANT:結合神經網絡和決策樹,各取雙方的優點
神經網絡(NN)和決策樹(DT)都是強大的機器學習模型,在學術和商業應用上都取得了一定的成功。然而,這兩種方法通常具有互斥的優點和局限性。
NN的特點是通過非線性變換的組合來學習數據的層次表示(hierarchical representation),與其他機器學習模型相比,一定程度上減輕了對特征工程的需求。此外,NN還使用隨機優化器(如隨機梯度下降)進行訓練,使訓練能夠擴展到大型數據集。因此,借助現代硬件,可以在大型數據集中訓練多層NN,以前所未有的精確度解決目標檢測、語音識別等眾多問題。然而,它們的結構通常需要手動設計并且對每個任務和數據集都要進行修整。對于大型模型來說,由于每個樣本都會涉及網絡中的每一部分,因此推理(reasoning)也是很重要的,例如容量(capacity)的增加會導致計算比例的增加。
DT的特點是通過數據驅動的體系結構,在預先指定的特征上學習層次結構。一顆決策樹會學習如何分割輸入空間,以便每個子集中的線性模型可以對數據做出解釋。與標準的NN相比,DT的結構是基于訓練數據進行優化的,因此在數據稀缺的情況下是十分有幫助的。由于每個輸入樣本只使用樹中的一個根到葉(root-to-leaf)的路徑,因此DT是享有輕量級推理(lightweight inference)的。然而,在使用DT的成功應用中,往往需要手動設計好的數據特征。由于DT通常使用簡單的路徑函數,它在表達能力(expressivity)方面是具有局限性的,例如軸對齊(axis-aligned)特征的拆分。用于優化硬分區(hard partitioning)的損失函數是不可微的,這就阻礙了基于梯度下降優化策略的使用,從而導致分割函數變得更加復雜。目前增加容量的技術主要是一些集成方法,例如隨機森林(RF)和梯度提升樹(GBT)等。
為結合NN和DT的優點,提出一種叫自適應神經樹(ANT)的方法,主要包括兩個關鍵創新點:
一種新穎的DT形式:計算路徑(computational path)和路由決策(routing decision)由NN來表示;
基于反向傳播的訓練算法:從簡單的模塊開始對結構進行擴展。ANT還解決了過去一些方法的局限性,如下圖所示:
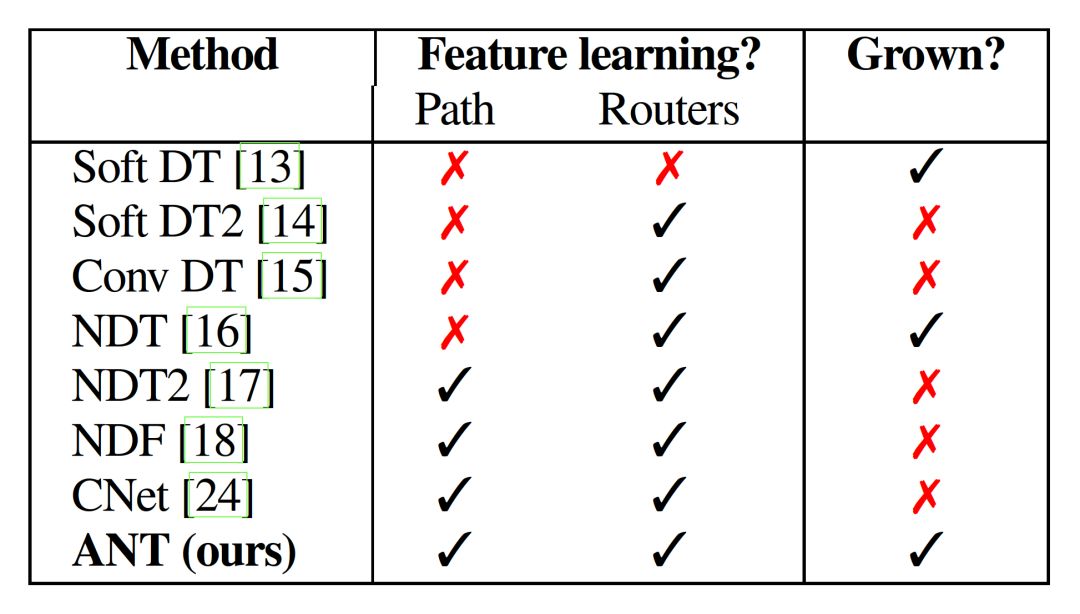
ANT從DT和NN中繼承了如下屬性:
表示學習(Representation learning):由于ANT中的每個根到葉(root-to-leaf)路徑都是NN,因此可以通過基于梯度的優化來端到端(end-to-end)地學習特征。訓練算法也適用于SGD。
結構學習(Architecture learning):通過逐步增長的ANT,結構可以適應數據的可用性和復雜性。增長過程可以看作是神經結構搜索的一種形式。
輕量級推理(Lightweight Inference):在推理時,ANT執行條件計算(conditional computation),基于每個樣本,在樹中選擇一個根到葉(root-to-leaf)的路徑,且只激活模型的一個子集。
自適應神經樹結構:路由器、轉換器、求解器
自適應神經樹(ANT)定義:用深度卷積表示(representation)來增強DT的一種形式。該方法旨在從一組被標簽的樣本N(訓練數據)(x(1),y(1)),...(x(n),y(n))∈X×Y學習條件分p(x|y)。值得注意的是,ANT也可以擴展到其它需要機器學習的任務中。
模型拓展與操作
簡而言之,ANT是一個樹形結構模型,其特點是輸入空間X擁有一組分層分區(hierarchical partition)、一系列非線性轉換以及在各個分量區域中有獨立的預測模型。更正式地說,ANT可以定義為一對(T,O),其中T表示模型拓撲,O表示操作集。
將T約束為二叉樹的實例,并定義為一組有限圖(finite graph),其中,每個節點要么是內部節點,要么是葉子節點,并且是一個父節點的子節點(除了無父節點外)。將樹的拓撲定義為T:={N,ε},其中N是所有節點的集合,ε是邊的集合。沒有孩子的節點是葉子節Nleaf,其它所有節點都是內部節Nint。每個內部節點都有兩個孩子節點,表示leftj和rightj。與標準樹不同,ε包含一條能夠將輸入數據X與根節點連接起來的邊。如下圖所示:
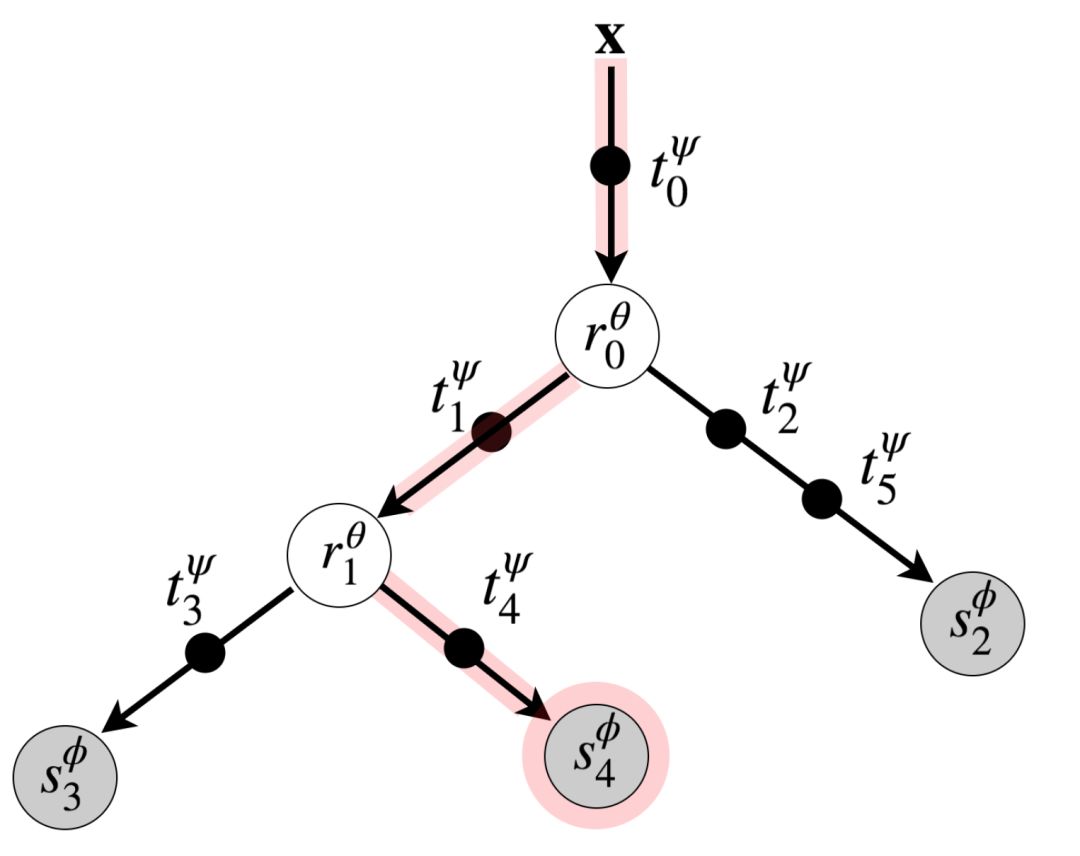
一個ANT是基于下面三個可微操作的基本模塊構建的:
路由器(Router),R:每個內部節點j∈Nint都有一個路由模塊,將來自傳入邊(incomming edge)的樣本發送到左子節點或右子節點。
轉換器(transformer),T:樹中的每條邊e∈ε都有一個或一組多轉換模塊( multiple transformermodule)。每個轉換teψ∈T都是一個非線性函數,將前一個模塊中的樣本進行轉換并傳遞給下一個模塊。
求解器(Solver),S:每個求解器模塊分配一個葉子節點,該求解器模塊對變換的輸入數據進行操作并輸出對條件分布p(y|x)的估計。
概率模型和推理
ANT對條件分布p(y|x)進行建模并作為層次混合專家網絡(HME),每個HME被定義為一個NN并對應于樹中特定的根到葉(root-to-leaf)路徑。假設我們有L個葉子節點,則完整的預測分布為:
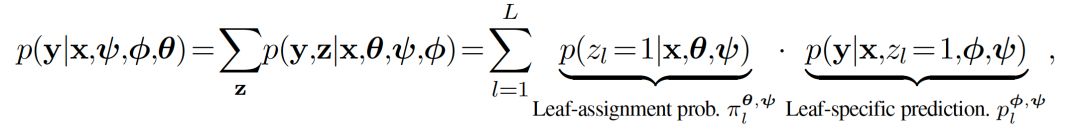
其中,
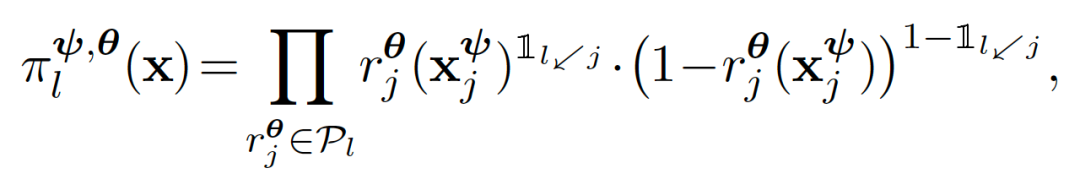
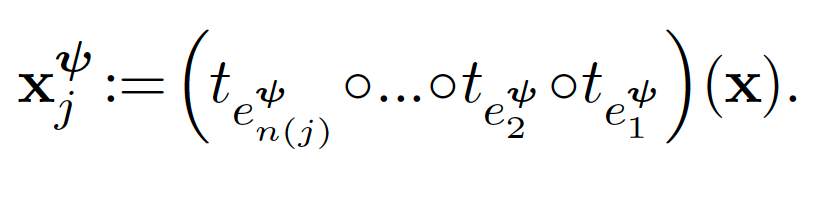
實驗結果:
其中,列“Error (Full)”和“Error (Path)”表示基于全分布和單路徑推斷(single-pathinference)的預測分類錯誤。列“Params(Full)”和“Params(Path)”分別表示模型中的參數總數和單路徑推斷的參數平均值。“Ensemble Size”表示集成的規模。“-”表示空值,“+”表示與ANT在相同的實驗設備進行訓練的方法,“*”表示參數是使用預先訓練的CNN初始化的。
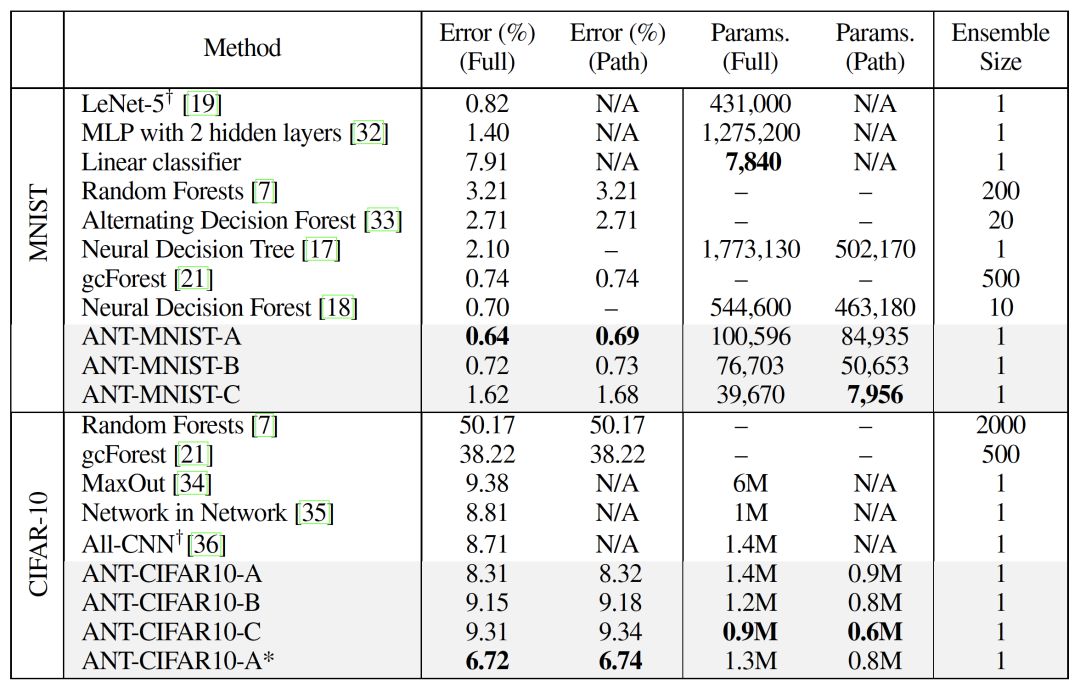
不同模型在MNIST和CIFAR-10上性能的比較
論文:自適應神經樹

摘要
深度神經網絡和決策樹很大程度上是相互獨立的。通常,前者是用預先指定的體系結構來進行表示學習(representation learning),而后者的特點是通過數據驅動的體系結構,在預先指定的特征上學習層次結構。通過自適應神經樹(Adaptive Neural Trees,ANT),一種將表示學習嵌入到決策樹的邊、路徑函數以及葉節點的模型,以及基于反向傳播的訓練算法(可自適應地從類似卷積層這樣的原始模塊對結構進行擴展)將兩者進行結合。在MNIST和CIFAR-10數據集上的準確率分別達到了99%和90%。ANT的優勢在于(i)可通過條件計算(conditional computation)進行更快的推斷;(ii)可通過分層聚類(hierarchical clustering)提高可解釋性;(iii)有一個可以適應訓練數據集規模和復雜性的機制。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
數據集
+關注
關注
4文章
1208瀏覽量
24703 -
決策樹
+關注
關注
3文章
96瀏覽量
13552
原文標題:UCL等三強聯手提出完全可微自適應神經樹:神經網絡與決策樹完美結合
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于決策樹,這些知識點不可錯過
決策樹的生成資料
斯坦福探索深度神經網絡可解釋性 決策樹是關鍵

決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
決策樹和隨機森林模型
什么是決策樹模型,決策樹模型的繪制方法






 工商網監
工商網監
評論