 NLP概述及文本自動分類算法詳解
NLP概述及文本自動分類算法詳解
自然語言處理一直是人工智能領域的重要話題,更是18年的熱度話題,為了在海量文本中及時準確地獲得有效信息,文本分類技術獲得廣泛關注,也給大家帶來了更多應用和想象的空間。本文根據AI科技大本營、CSDN學院聯合達觀數據分享的直播內容《NLP概述及文本自動分類算法詳解》整理而成。
一、NLP概述
1.文本挖掘任務類型的劃分
文本挖掘任務大致分為四個類型:類別到序列、序列到類別、同步的(每個輸入位置都要產生輸出)序列到序列、異步的序列到序列。
同步的序列到序列的例子包括中文分詞,命名實體識別和詞性標注。一部的序列到序列包括機器翻譯和自動摘要。序列到類別的例子包括文本分類和情感分析。類別(對象)到序列的例子包括文本生成和形象描述。
2.文本挖掘系統整體方案
達觀數據一直專注于文本語義,文本挖掘系統整體方案包含了NLP處理的各個環節,從處理的文本粒度上來分,可以分為篇章級應用、短串級應用和詞匯級應用。
篇章級應用有六個方面,已經有成熟的產品支持企業在不同方面的文本挖掘需求:
垃圾評論:精準識別廣告、不文明用語及低質量文本。
黃反識別:準確定位文本中所含涉黃、涉政及反動內容。
標簽提取:提取文本中的核心詞語生成標簽。
文章分類:依據預設分類體系對文本進行自動歸類。
情感分析:準確分析用戶透過文本表達出的情感傾向。
文章主題模型:抽取出文章的隱含主題。
為了實現這些頂層應用,達觀數據掌握從詞語短串分析個層面的分析技術,開發了包括中文分詞、專名識別、語義分析和詞串分析等模塊。
3.序列標注應用:中文分詞
同步的序列到序列,其實就是序列標注問題,應該說是自然語言處理中最常見的問題。序列標注的應用包括中文分詞、命名實體識別和詞性標注等。序列標注問題的輸入是一個觀測序列,輸出的是一個標記序列或狀態序列。
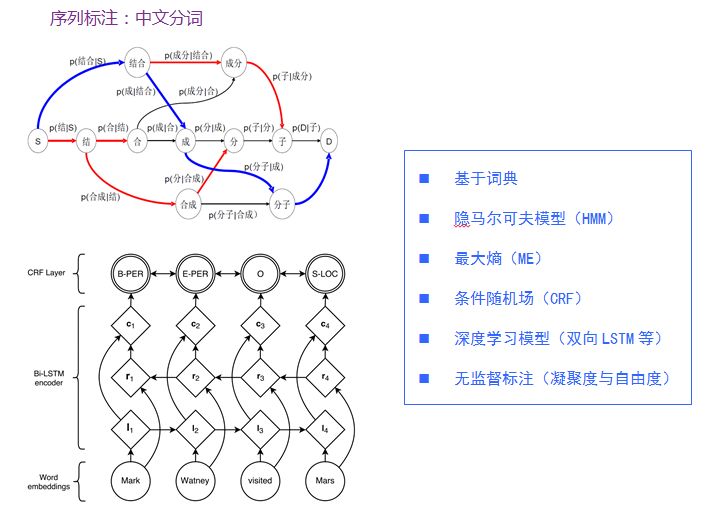
舉中文分詞為例,處理“結合成分子”的觀測序列,輸出“結合/成/分子”的分詞標記序列。針對中文分詞的這個應用,有多種處理方法,包括基于詞典的方法、隱馬爾可夫模型(HMM)、最大熵模型、條件隨機場(CRF)、深度學習模型(雙向LSTM等)和一些無監督學習的方法(基于凝聚度與自由度)。
4.序列標注應用:NER
命名實體識別:Named Entity Recognition,簡稱NER,又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等。通常包括實體邊界識別和確定實體類別。

對與命名實體識別,采取不同的標記方式,常見的標簽方式包括IO、BIO、BMEWO和BMEWO+。其中一些標簽含義是:
B:begin
I:一個詞的后續成分
M:中間
E:結束
W:單個詞作為實體
大部分情況下,標簽體系越復雜準確度也越高,但相應的訓練時間也會增加。因此需要根據實際情況選擇合適的標簽體系。通常我們實際應用過程中,最難解決的還是標注問題。所以在做命名實體識別時,要考慮人工成本問題。
5.英文處理
在NLP領域,中文和英文的處理在大的方面都是相通的,不過在細節方面會有所差別。其中一個方面,就是中文需要解決分詞的問題,而英文天然的就沒有這個煩惱;另外一個方面,英文處理會面臨詞形還原和詞根提取的問題,英文中會有時態變換(made==>make),單復數變換(cats==>cat),詞根提取(arabic==>arab)。
在處理上面的問題過程中,不得不提到的一個工具是WordNet。WordNet是一個由普林斯頓大學認識科學實驗室在心理學教授喬治·A·米勒的指導下建立和維護的英語字典。在WordNet中,名詞、動詞、形容詞和副詞各自被組織成一個同義詞的網絡,每個同義詞集合都代表一個基本的語義概念,并且這些集合之間也由各種關系連接。我們可以通過WordNet來獲取同義詞和上位詞。
6.詞嵌入
在處理文本過程中,我們需要將文本轉化成數字可表示的方式。詞向量要做的事就是將語言數學化表示。詞向量有兩種實現方式:One-hot 表示,即通過向量中的一維0/1值來表示某個詞;詞嵌入,將詞轉變為固定維數的向量。
word2vec是使用淺層和雙層神經網絡產生生詞向量的模型,產生的詞嵌入實際上是語言模型的一個副產品,網絡以詞表現,并且需猜測相鄰位置的輸入詞。word2vec中詞向量的訓練方式有兩種,cbow(continuous bags of word)和skip-gram。cbow和skip-gram的區別在于,cbow是通過輸入單詞的上下文(周圍的詞的向量和)來預測中間的單詞,而skip-gram是輸入中間的單詞來預測它周圍的詞。
7.文檔建模
要使計算機能夠高效地處理真實文本,就必須找到一種理想的形式化表示方法,這個過程就是文檔建模。文檔建模一方面要能夠真實地反映文檔的內容,另一方面又要對不同文檔具有區分能力。文檔建模比較通用的方法包括布爾模型、向量空間模型(VSM)和概率模型。其中最為廣泛使用的是向量空間模型。
二、文本分類的關鍵技術與重要方法
1.利用機器學習進行模型訓練
文本分類的流程包括訓練、文本語義、文本特征處理、訓練模型、模型評估和輸出模型等幾個主要環節。其中介紹一下一些主要的概念。
文檔建模:概率模型,布爾模型,VSM;
文本語義:分詞,命名實體識別,詞性標注等;
文本特征處理:特征降維,包括使用評估函數(TF-IDF,互信息方法,期望交叉熵,QEMI,統計量方法,遺傳算法等);特征向量權值計算;
樣本分類訓練:樸素貝葉斯分類器,SVM,神經網絡算法,決策樹,Ensemble算法等;
模型評估:召回率,正確率,F-測度值;
輸出模型。
2.向量空間模型
向量空間模型是常用來處理文本挖掘的文檔建模方法。VSM概念非常直觀——把對文本內容的處理簡化為向量空間中的向量運算,并且它以空間上的相似度表達語義的相似度,直觀易懂。
當文檔被表示為文檔空間的向量時,就可以通過計算向量之間的相似性來度量文檔間的相似性。它的一些實現方式包括:
1)N-gram模型:基于一定的語料庫,可以利用N-Gram來預計或者評估一個句子是否合理;
2)TF-IDF模型:若某個詞在一篇文檔中出現頻率TF高,卻在其他文章中很少出現,則認為此詞具有很好的類別區分能力;
3)Paragraph Vector模型:其實是word vector的一種擴展。Gensim中的Doc2Vec 以及Facebook開源的Fasttext工具也是采取了這么一種思路,它們將文本的詞向量進行相加/求平均的結果作為Paragraph Vector。
3.文本特征提取算法
目前大多數中文文本分類系統都采用詞作為特征項,作為特征項的詞稱作特征詞。這些特征詞作為文檔的中間表示形式,用來實現文檔與文檔、文檔與用戶目標之間的相似度計算。如果把所有的詞都作為特征項,那么特征向量的維數將過于巨大。有效的特征提取算法,不僅能降低運算復雜度,還能提高分類的效率和精度。
文本特征提取的算法包含下面三個方面:
1)從原始特征中挑選出一些最具代表文本信息的特征,例如詞頻、TF-IDF方法;
2)基于數學方法找出對分類信息共現比較大的特征,主要例子包括互信息法、信息增益、期望交叉熵和統計量方法;
3)以特征量分析多元統計分布,例如主成分分析(PCA)。
4.文本權重計算方法
特征權重用于衡量某個特征項在文檔表示中的重要程度或區分能力的強弱。選擇合適的權重計算方法,對文本分類系統的分類效果能有較大的提升作用。
特征權重的計算方法包括:
1) TF-IDF;
2) 詞性;
3)標題;
4)位置;
5)句法結構;
6)專業詞庫;
7)信息熵;
8)文檔、詞語長度;
9)詞語間關聯;
10)詞語直徑;
11)詞語分布偏差。
其中提幾點,詞語直徑是指詞語在文本中首次出現的位置和末次出現的位置之間的距離。詞語分布偏差所考慮的是詞語在文章中的統計分布。在整篇文章中分布均勻的詞語通常是重要的詞匯。
5.分類器設計
由于文本分類本身是一個分類問題,所以一般的模式分類方法都可以用于文本分類應用中。
常用分類算法的思路包括下面四種:
1)樸素貝葉斯分類器:利用特征項和類別的聯合概率來估計文本的類別概率;
2)支持向量機分類器:在向量空間中找到一個決策平面,這個平面能夠最好的切割兩個分類的數據點,主要用于解決二分類問題;
3)KNN方法:在訓練集中找到離它最近的k個臨近文本,并根據這些文本的分類來給測試文檔分類;
4)決策樹方法:將文本處理過程看作是一個等級分層且分解完成的復雜任務。
6.分類算法融合
聚合多個分類器,提高分類準確率稱為Ensemble方法。
利用不同分類器的優勢,取長補短,最后綜合多個分類器的結果。Ensemble可設定目標函數(組合多個分類器),通過訓練得到多個分類器的組合參數(并非簡單的累加或者多數)。

我們這里提到的ensemble可能跟通常說的ensemble learning有區別。主要應該是指stacking。Stacking是指訓練一個模型用于組合其他各個模型。即首先我們先訓練多個不同的模型,然后再以之前訓練的各個模型的輸出為輸入來訓練一個模型,以得到一個最終的輸出。在處理ensemble方法的時候,需要注意幾個點。基礎模型之間的相關性要盡可能的小,并且它們的性能表現不能差距太大。
多個模型分類結果如果差別不大,那么疊加效果也不明顯;或者如果單個模型的效果距離其他模型比較差,也是會對整體效果拖后腿。
三、文本分類在深度學習中的應用
1.CNN文本分類
采取CNN方法進行文本分類,相比傳統方法會在一些方面有優勢。
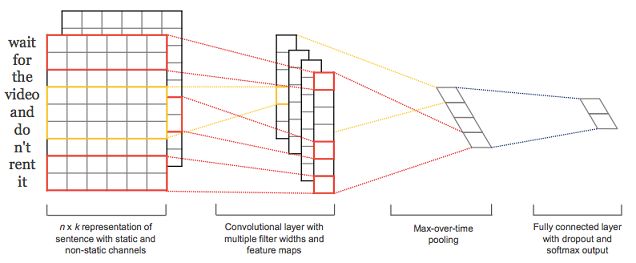
基于詞袋模型的文本分類方法,沒有考慮到詞的順序。
基于卷積神經網絡(CNN)來做文本分類,可以利用到詞的順序包含的信息。如圖展示了比較基礎的一個用CNN進行文本分類的網絡結構。CNN模型把原始文本作為輸入,不需要太多的人工特征。CNN模型的一個實現,共分四層:
第一層是詞向量層,doc中的每個詞,都將其映射到詞向量空間,假設詞向量為k維,則n個詞映射后,相當于生成一張n*k維的圖像;
第二層是卷積層,多個濾波器作用于詞向量層,不同濾波器生成不同的feature map;
第三層是pooling層,取每個feature map的最大值,這樣操作可以處理變長文檔,因為第三層輸出只依賴于濾波器的個數;
第四層是一個全連接的softmax層,輸出是每個類目的概率,中間一般加個dropout,防止過擬合。
有關CNN的方法一般都圍繞這個基礎模型進行,再加上不同層的創新。
比如第一個模型在輸入層換成RNN,去獲得文本通過rnn處理之后的輸出作為卷積層的輸入。比如說第二個是在pooling層使用了動態kmax pooling,來解決樣本集合文本長度變化較大的問題。比如說第三種是極深網絡,在卷積層做多層卷積,以獲得長距離的依賴信息。CNN能夠提取不同長度范圍的特征,網絡的層數越多,意味著能夠提取到不同范圍的特征越豐富。不過cnn層數太多會有梯度彌散、梯度爆炸或者退化等一系列問題。
為了解決這些問題,極深網絡就通過shortcut連接。殘差網絡其實是由多種路徑組合的一個網絡,殘差網絡其實是很多并行子網絡的組合,有些點評評書殘差網絡就說它其實相當于一個Ensembling。
2.RNN與LSTM文本分類
CNN有個問題是卷積時候是固定 filter_size ,就是無法建模更長的序列信息,雖然這個可以通過多次卷積獲得不同范圍的特征,不過要付出增加網絡深度的代價。
Rnn的出現是解決變長序列信息建模的問題,它會將每一步中產生的信息都傳遞到下一步中。
首先我們在輸入層之上,套上一層雙向LSTM層,LSTM是RNN的改進模型,相比RNN,能夠更有效地處理句子中單詞間的長距離影響;而雙向LSTM就是在隱層同時有一個正向LSTM和反向LSTM,正向LSTM捕獲了上文的特征信息,而反向LSTM捕獲了下文的特征信息,這樣相對單向LSTM來說能夠捕獲更多的特征信息,所以通常情況下雙向LSTM表現比單向LSTM或者單向RNN要好。
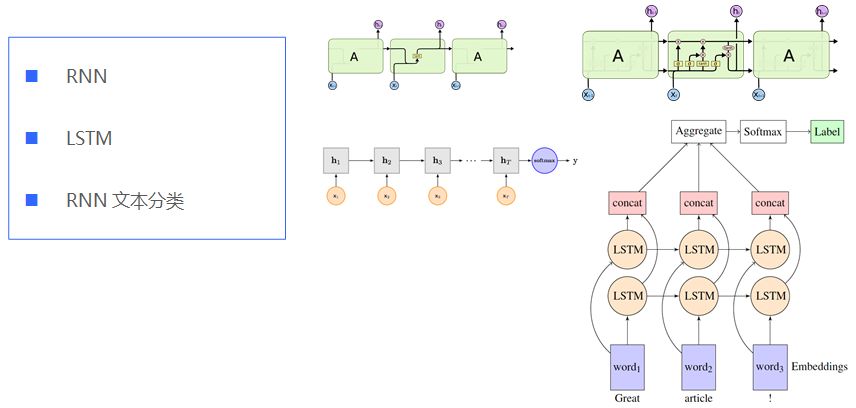
如何從物理意義上來理解求平均呢?這其實可以理解為在這一層,兩個句子中每個單詞都對最終分類結果進行投票,因為每個BLSTM的輸出可以理解為這個輸入單詞看到了所有上文和所有下文(包含兩個句子)后作出的兩者是否語義相同的判斷,而通過Mean Pooling層投出自己寶貴的一票。
3.Attention Model與seq2seq
注意力模型Attention Model是傳統自編碼器的一個升級版本。傳統RNN的Encoder-Decoder模型,它的缺點是不管無論之前的context有多長,包含多少信息量,最終都要被壓縮成固定的vector,而且各個維度維度收到每個輸入維度的影響都是一致的。為了解決這個問題,它的idea其實是賦予不同位置的context不同的權重,越大的權重表示對應位置的context更加重要。

現實中,舉一個翻譯問題:jack ma dances very well 翻譯成中文是馬云跳舞很好。其中,馬云應該是和jack ma關聯的。
AttentionModel是當前的研究熱點,它廣泛地可應用于文本生成、機器翻譯和語言模型等方面。
4.Hierarchical Attention Network
下面介紹層次化注意力網絡。
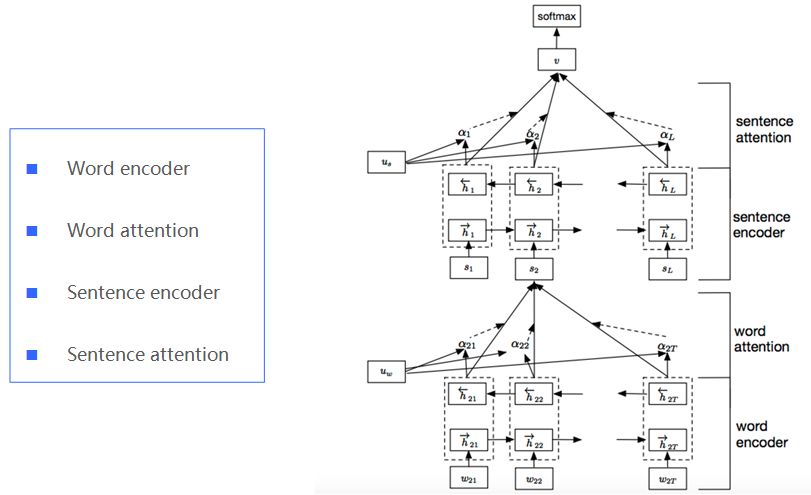
詞編碼層是首先把詞轉化成詞向量,然后用雙向的GRU層,可以將正向和反向的上下文信息結合起來,獲得隱藏層輸出。第二層是word attention層。attention機制的目的是要把一個句子中,對句子的含義最重要,貢獻最大的詞語找出來。
為了衡量單詞的重要性,我們用u_it和一個隨機初始化的上下文向量u_w的相似度來表示,然后經過softmax操作獲得了一個歸一化的attention權重矩陣a_it,代表句子i中第t個詞的權重。結合詞的權重,句子向量s_i看作組成這些句子的詞向量的加權求和。
第三層是句子編碼層,也是通過雙向GRU層,可以將正向和反向的上下文信息結合起來,獲得隱藏層輸出。
到了第四層是句子的注意力層,同詞的注意力層差不多,也是提出了一個句子級別的上下文向量u_s,來衡量句子在文中的重要性。輸出也是結合句子的權重,全文的向量表示看做是句子向量的加權求和。
到了最后,有了全文的向量表示,我們就直接通過全連接softmax來進行分類。
四、案例介紹
1.新聞分類
新聞分類是最常見的一種分類。其處理方法包括:
1)定制行業專業語料,定期更新語料知識庫,構建行業垂直語義模型。
2)計算term權重,考慮到位置特征,網頁特征,以及結合離線統計結果獲取到核心的關鍵詞。
3)使用主題模型進行語義擴展
4)監督與半監督方式的文本分類

2.垃圾廣告黃反識別
垃圾廣告過濾作為文本分類的一個場景有其特殊之處,那就是它作為一種防攻擊手段,會經常面臨攻擊用戶采取許多變換手段來繞過檢查。
處理這些變換手段有多重方法:
一是對變形詞進行識別還原,包括要處理間雜特殊符號,同音、簡繁變換,和偏旁拆分、形近變換。
二是通過語言模型識別干擾文本,如果識別出文本是段不通順的“胡言亂語”,那么他很可能是一段用于規避關鍵字審查的垃圾文本。
三是通過計算主題和評論的相關度匹配來鑒別。
四是基于多種表達特征的分類器模型識別來提高分類的泛化能力。
3.情感分析
情感分析的處理辦法包括:
1)基于詞典的情感分析,主要是線設置情感詞典,然后基于規則匹配(情感詞對應的權重進行加權)來識別樣本是否是正負面。
2)基于機器學習的情感分析,主要是采取詞袋模型作為基礎特征,并且將復雜的情感處理規則命中的結果作為一維或者多維特征,以一種更為“柔性”的方法融合到情感分析中,擴充我們的詞袋模型。
3)使用dnn模型來進行文本分類,解決傳統詞袋模型難以處理長距離依賴的缺點。
他應
NLP在達觀的其他一些應用包括:
1)標簽抽取;
2)觀點挖掘;
3)應用于推薦系統;
4)應用于搜索引擎。
標簽抽取有多種方式:基于聚類的方法實現。此外,現在一些深度學習的算法,通過有監督的手段實現標簽抽取功能。
就觀點挖掘而言,舉例:床很破,睡得不好。我抽取的觀點是“床破”,其中涉及到語法句法分析,將有關聯成本提取出來。
搜索及推薦,使用到NLP的地方也很多,如搜索引擎處理用戶查詢的糾錯,就用到信道噪聲模型實行糾錯處理。
-
機器翻譯
+關注
關注
0文章
139瀏覽量
14937 -
nlp
+關注
關注
1文章
489瀏覽量
22093
原文標題:NLP概述和文本自動分類算法詳解 | 公開課筆記
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NLPIR平臺在文本分類方面的技術解析
詳解概述步進電機的分類與結構
基于文章標題信息的漢語自動文本分類
示波器探頭概述及應用
基于KNN的煙草企業檔案文本分類
基于標題的文本自動分類研究
結合BERT模型的中文文本分類算法
一種基于BERT模型的社交電商文本分類算法






 工商網監
工商網監
評論