") 一些解決文本分類問題的機(jī)器學(xué)習(xí)最佳實(shí)踐
一些解決文本分類問題的機(jī)器學(xué)習(xí)最佳實(shí)踐
編者按:文本分類是各類應(yīng)用中的一種基礎(chǔ)機(jī)器學(xué)習(xí)問題,近日,一篇關(guān)于文本分類的文章成功引起學(xué)界大牛和競賽機(jī)構(gòu)注意,讓他們在twitter上爭相轉(zhuǎn)載。那么,它到底講述了什么內(nèi)容呢?考慮到原文過長,本文是其中的(上)篇。
文本分類是一種應(yīng)用廣泛的算法,它是各種用于大規(guī)模處理文本數(shù)據(jù)的軟件系統(tǒng)的核心,常被用于垃圾郵件識(shí)別及幫助論壇機(jī)器人標(biāo)記不當(dāng)評(píng)論。
當(dāng)然,以上只是文本分類的兩種常規(guī)應(yīng)用,它們處理的是預(yù)定義的二元分類問題。在多元分類任務(wù)中,算法分類主要基于本文中的關(guān)鍵詞
分類器標(biāo)記垃圾郵件,并把它們過濾到垃圾郵件文件夾中
另一種常見的文本分類是情感分析,它的目標(biāo)是識(shí)別文本內(nèi)容積極與否:文字所表達(dá)的思想類型。同樣的,這也是多元分類問題,我們可以采用二元的喜歡/不喜歡評(píng)級(jí)形式,也可以進(jìn)一步細(xì)化,如設(shè)成1星到5星的星級(jí)評(píng)級(jí)。情感分析的常見應(yīng)用包括分析影評(píng),判斷消費(fèi)者是否喜歡這部電影,或者是分析大型商場的評(píng)論,推測普通大眾對某個(gè)品牌新產(chǎn)品的看法。
本指南將介紹一些解決文本分類問題的機(jī)器學(xué)習(xí)最佳實(shí)踐,你可以從中學(xué)到:
用機(jī)器學(xué)習(xí)解決文本分類問題
如何為文本分類問題挑選正確的模型
如何用TensorFlow實(shí)現(xiàn)你選擇的模型
文本分類流程
第一步:收集數(shù)據(jù)
第二步:探索數(shù)據(jù)
第2.5步:選擇一個(gè)模型
第三步:準(zhǔn)備數(shù)據(jù)
第四步:構(gòu)建、訓(xùn)練、評(píng)估模型
第五步:調(diào)整超參數(shù)
第六步:部署模型

文本分類流程
第一步:收集數(shù)據(jù)
收集數(shù)據(jù)是解決任何監(jiān)督學(xué)習(xí)問題的最重要一步,數(shù)據(jù)的質(zhì)量和數(shù)量直接決定著文本分類器的性能上限。
如果你沒有想要解決的的特定問題,或者只是對一般的文本分類感興趣,你可以直接用已經(jīng)開源的大量數(shù)據(jù)集。這個(gè)GitHub repo里可能包含不少你可以用到的鏈接:github.com/google/eng-edu/blob/master/ml/guides/textclassification/loaddata.py。
但是,如果你有一個(gè)待解決的特定問題,你就得先收集必要數(shù)據(jù)。當(dāng)然,有些數(shù)據(jù)是現(xiàn)成的,一些組織會(huì)提供訪問其數(shù)據(jù)的公共API,比如Twitter API或NY Times API,如果有用,你可以直接通過它們來解決自己的問題。
以下是收集數(shù)據(jù)過程中的一些注意事項(xiàng):
如果使用公共API,請?jiān)谑褂们跋乳喿x它們的使用限制,比如某些API會(huì)對你的訪問速度設(shè)限。
收集訓(xùn)練樣本的量永遠(yuǎn)是越多越好,這有助于模型更好地概括。
如果涉及分類,確保每個(gè)類的樣本數(shù)量不會(huì)過度失衡,換句話說,每個(gè)類中都應(yīng)該有相當(dāng)數(shù)量的樣本。
確保你的樣本可以覆蓋所有可能的輸入空間,而不僅僅是最常見的幾種情況。
在本指南中,我們將以斯坦福大學(xué)開源的大型電影評(píng)論數(shù)據(jù)集(IMDb)為例,說明整個(gè)本文分類流程。該數(shù)據(jù)集包含人們在IMDb網(wǎng)站上發(fā)布的電影評(píng)論,以及評(píng)論者是否喜歡電影的相應(yīng)標(biāo)簽(“positive”或“negative”)。這是用于情緒分析問題的一個(gè)經(jīng)典數(shù)據(jù)集。
第二步:探索數(shù)據(jù)
構(gòu)建、訓(xùn)練模型只是整個(gè)流程的一部分,如果事先能了解數(shù)據(jù)特征,這會(huì)對之后的模型構(gòu)建大有裨益,比如更高的準(zhǔn)確率,或是更少的數(shù)據(jù)和更少的計(jì)算資源。
加載數(shù)據(jù)集
首先,讓我們將數(shù)據(jù)集加載到Python中:
def load_imdb_sentiment_analysis_dataset(data_path, seed=123):
"""Loads the IMDb movie reviews sentiment analysis dataset.
# Arguments
data_path: string, path to the data directory.
seed: int, seed for randomizer.
# Returns
A tuple of training and validation data.
Number of training samples: 25000
Number of test samples: 25000
Number of categories: 2 (0 - negative, 1 - positive)
# References
Mass et al., http://www.aclweb.org/anthology/P11-1015
Download and uncompress archive from:
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
"""
imdb_data_path = os.path.join(data_path, 'aclImdb')
# Load the training data
train_texts = []
train_labels = []
for category in ['pos', 'neg']:
train_path = os.path.join(imdb_data_path, 'train', category)
for fname in sorted(os.listdir(train_path)):
if fname.endswith('.txt'):
with open(os.path.join(train_path, fname)) as f:
train_texts.append(f.read())
train_labels.append(0if category == 'neg'else1)
# Load the validation data.
test_texts = []
test_labels = []
for category in ['pos', 'neg']:
test_path = os.path.join(imdb_data_path, 'test', category)
for fname in sorted(os.listdir(test_path)):
if fname.endswith('.txt'):
with open(os.path.join(test_path, fname)) as f:
test_texts.append(f.read())
test_labels.append(0if category == 'neg'else1)
# Shuffle the training data and labels.
random.seed(seed)
random.shuffle(train_texts)
random.seed(seed)
random.shuffle(train_labels)
return ((train_texts, np.array(train_labels)),
(test_texts, np.array(test_labels)))
檢查數(shù)據(jù)
加載完數(shù)據(jù)后,最好對其一一檢查:選擇一些樣本,手動(dòng)檢查它們是否符合你的預(yù)期。比如示例用的電影評(píng)論數(shù)據(jù)集,我們可以輸出一些隨機(jī)樣本,檢查情緒標(biāo)簽和評(píng)論包含的情緒是否一致。
“十分鐘的故事非要講兩小時(shí),要不是沒什么大事,我早就中途起身走人了。”
這是數(shù)據(jù)集中被標(biāo)記為“negative”的評(píng)論,很顯然,評(píng)論者覺得電影非常拖沓、無聊,這和標(biāo)簽是匹配的。
收集關(guān)鍵指標(biāo)
完成檢查后,你需要收集以下重要指標(biāo),它們有助于表征文本分類任務(wù):
樣本數(shù):數(shù)據(jù)集中的樣本總數(shù)。
類別數(shù):數(shù)據(jù)集中的主題或分類數(shù)。
每個(gè)類的樣本數(shù):如果是均衡的數(shù)據(jù)集,所有類應(yīng)該包含數(shù)量相近的樣本;如果是不均衡的數(shù)據(jù)集,每個(gè)類所包含的樣本數(shù)會(huì)有巨大差異。
每個(gè)樣本中的單詞數(shù):這是文本分類問題,所以要統(tǒng)計(jì)樣本所包含單詞數(shù)的中位數(shù)。
單詞詞頻分布:數(shù)據(jù)集中每個(gè)單詞的出現(xiàn)頻率(出現(xiàn)次數(shù))。
樣本長度分布:數(shù)據(jù)集中每個(gè)樣本的
第2.5步:選擇一個(gè)模型
到目前為止,我們已經(jīng)匯總了數(shù)據(jù),也深入了解了數(shù)據(jù)中的關(guān)鍵特征。接下來,根據(jù)第二步中收集的各個(gè)指標(biāo),我們就要開始考慮應(yīng)該使用哪種分類模型了。這也意味著我們會(huì)提出以下這些問題:“我們該怎么把文本數(shù)據(jù)轉(zhuǎn)成算法輸入?”(數(shù)據(jù)預(yù)處理和向量化),“我們應(yīng)該使用什么類型的模型?”,“我們的模型應(yīng)該實(shí)用什么參數(shù)配置?”……
得益于數(shù)十年的研究,現(xiàn)在數(shù)據(jù)預(yù)處理和模型配置的選擇非常多元化,但這么多的選擇其實(shí)也帶來了不少麻煩,我們手頭只有一個(gè)特定問題,它的范圍也很寬泛,那么怎么選才是最好的呢?最老實(shí)的方法是一個(gè)個(gè)試過去,去掉不好的,留下最好的,但這種做法并不現(xiàn)實(shí)。
在本文中,我們嘗試著簡化選擇文本分類模型的過程。對于給定數(shù)據(jù)集,我們的目標(biāo)只有兩個(gè):準(zhǔn)確率接近最高,訓(xùn)練時(shí)間盡可能最低。我們針對不同類型的問題(特別是情感分析和主題分類問題)進(jìn)行了大量(~450K)實(shí)驗(yàn),共計(jì)使用12個(gè)數(shù)據(jù)集,交替測試了不同數(shù)據(jù)預(yù)處理技術(shù)和不同模型架構(gòu)的情況。這個(gè)過程有助于我們獲得影響優(yōu)化的各個(gè)參數(shù)。
下面的模型選擇和流程圖是以上實(shí)驗(yàn)的總結(jié)。
數(shù)據(jù)準(zhǔn)備與模型算法構(gòu)建
計(jì)算比率:樣本數(shù)/單個(gè)樣本平均單詞數(shù)
如果以上比率小于1500,對文本進(jìn)行分詞,然后用簡單的多層感知器(MLP)模型對它們進(jìn)行分類(下圖左側(cè)分支)
a.用n元模型對句子分詞,并把詞轉(zhuǎn)換成詞向量
b.根據(jù)向量的重要程度評(píng)分,從中抽出排名前2萬的詞
c.構(gòu)建MLP模型
如果以上比率大于1500,則將文本標(biāo)記成序列,用sepCNN模型對它們進(jìn)行分類(下圖右側(cè)分支)
a.對樣本進(jìn)行分詞,根據(jù)單詞詞頻選擇其中的前2萬個(gè)
b.將樣本轉(zhuǎn)換為單詞序列向量
c.如果比率小于1500,用預(yù)訓(xùn)練的sepCNN模型進(jìn)行詞嵌入,效果可能會(huì)很好
調(diào)整超參數(shù),尋找模型的最佳參數(shù)配置
在下面的流程圖中,黃色框表示數(shù)據(jù)和模型的準(zhǔn)備階段,灰色框和綠色框表示過程中的每個(gè)選擇,其中綠色表示“推薦選擇”。你可以把這張圖作為構(gòu)建第一個(gè)實(shí)驗(yàn)?zāi)P偷钠瘘c(diǎn),因?yàn)樗芤暂^低的計(jì)算成本提供較良好的性能。之后如果有需要,你可以再在這基礎(chǔ)上繼續(xù)改進(jìn)迭代。
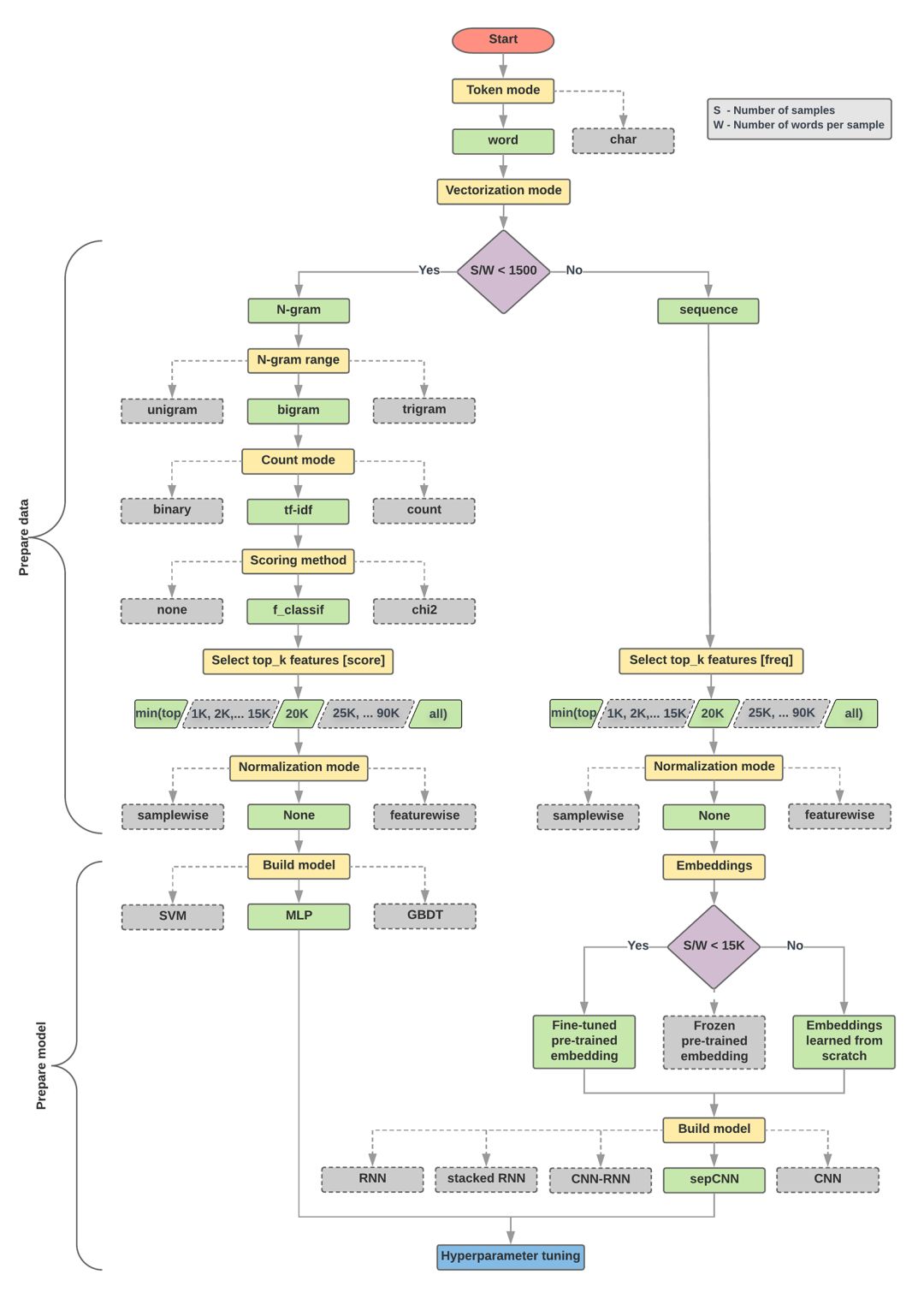
文本分類流程圖
這個(gè)流程圖回答了兩個(gè)關(guān)鍵問題:
我們應(yīng)該使用哪種學(xué)習(xí)算法或模型?
我們應(yīng)該如何準(zhǔn)備數(shù)據(jù)以有效地學(xué)習(xí)文本和標(biāo)簽之間的關(guān)系?
其中,第二個(gè)問題取決于第一個(gè)問題的答案,我們預(yù)處理數(shù)據(jù)的方式取決于選擇的具體模型。文本分類模型大致可分為兩類:使用單詞排序信息的序列模型和把文本視為一組單詞的n-gram模型。其中序列模型的類型包括卷積神經(jīng)網(wǎng)絡(luò)(CNN)、遞歸神經(jīng)網(wǎng)絡(luò)(RNN)及其變體。n-gram模型的類型包括邏輯回歸、MLP、DBDT和SVM。
對于電影評(píng)論數(shù)據(jù)集,樣本數(shù)/單個(gè)樣本平均單詞數(shù)約為144,所以我們會(huì)構(gòu)建一個(gè)MLP模型。
-
文本分類
+關(guān)注
關(guān)注
0文章
18瀏覽量
7331 -
分類器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13203 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8428瀏覽量
132778
原文標(biāo)題:ML通用指南:文本分類詳細(xì)教程(上)
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
pyhanlp文本分類與情感分析
NLPIR平臺(tái)在文本分類方面的技術(shù)解析
基于文章標(biāo)題信息的漢語自動(dòng)文本分類
基于apiori算法改進(jìn)的knn文本分類方法
運(yùn)用多種機(jī)器學(xué)習(xí)方法比較短文本分類處理過程與結(jié)果差別
textCNN論文與原理——短文本分類
文本分類的一個(gè)大型“真香現(xiàn)場”來了
基于深度神經(jīng)網(wǎng)絡(luò)的文本分類分析

融合文本分類和摘要的多任務(wù)學(xué)習(xí)摘要模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論