") TensorFlow.js 的基本構建塊及其操作,如何創(chuàng)建一些復雜的模型
TensorFlow.js 的基本構建塊及其操作,如何創(chuàng)建一些復雜的模型
這創(chuàng)造了一個標量張量。我們還可以將數(shù)組轉換為張量。
Tensorflow.js 是一個基于 deeplearn.js 構建的庫,可直接在瀏覽器環(huán)境中創(chuàng)建深度學習模型。使用它可以在瀏覽器上創(chuàng)建 CNNs,RNNs 等,并使用客戶端的 GPU 處理能力訓練這些模型。因此,訓練 NN 并不一定需要服務器級別的 GPU。本教程首先解釋 TensorFlow.js 的基本構建塊及其操作。然后,我們描述了如何創(chuàng)建一些復雜的模型。
我在 Observable 上創(chuàng)建了一個交互式編碼會話,可用于代碼演示。此外,我創(chuàng)建了許多迷你項目,包括簡單分類,樣式轉換,姿勢評估和 pix2pix 翻譯。
入門
由于 TensorFlow.js 在瀏覽器上運行,您只需將以下腳本包含在 html 文件的 header 中即可:
1
以上會自動加載最新版本的 TensorFlow.js。
張量(Tensor)
如果您熟悉 TensorFlow 等深度學習平臺,您應該能夠認識到張量是 Operators 使用的 n 維數(shù)組。因此,它們代表了任何深度學習應用程序的構建塊。讓我們創(chuàng)建一個張量:
1const tensor = tf.scalar(2);
以上創(chuàng)建了一個張量。我們還可以將數(shù)組轉換為張量:
1const input = tf.tensor([2,2]);
這會創(chuàng)建一個恒定的數(shù)組張量[2,2]。換句話說,我們通過應用張量函數(shù)將一維數(shù)組轉換為張量。我們可以使用 input.shape 獲取張量大小。
1const tensor_s = tf.tensor([2,2]).shape;
我們還可以創(chuàng)建具有特定大小的張量:
1const input = tf.zeros([2,2]);
操作(Operators)
為了使用張量,我們需要創(chuàng)建操作。如下所示,可以獲取到張量的平方:
1const a = tf.tensor([1,2,3]);
2a.square().print();
TensorFlow.js 還允許鏈接操作。例如,要評估我們使用的張量的二次冪:
1const x = tf.tensor([1,2,3]);
2const x2 = x.square().square();
Tensor Disposal
通常我們會生成大量的中間張量。例如,在前面的例子中,我們不需要生成 const x。為了做到這一點,我們可以調用 dispose():
1const x = tf.tensor([1,2,3]);
2x.dispose();
請注意,我們在以后的操作中不再使用張量 x。現(xiàn)在,對于每個張量來說,這可能有點不方便。
TensorFlow.js 提供了一個特殊的操作 tidy() 來自動處理中間張量:
1function f(x)
2{
3return tf.tidy(()=>{
4const y = x.square();
5const z = x.mul(y);
6return z
7});
8}
請注意,張量 y 的值將被處理,因為我們在評估 z 的值之后不再需要它。
優(yōu)化問題
在這里,我們將學習如何解決優(yōu)化問題。給定函數(shù) f(x),基于 x = a 評估最小化 f(x)。為此,我們需要一個優(yōu)化器。優(yōu)化器是一種通過漸變來最小化函數(shù)的算法。文獻中有許多優(yōu)化器,如 SGD,Adam 等......這些優(yōu)化器的速度和準確性各不相同。Tensorflowjs 支持最重要的優(yōu)化器。
我們將舉一個簡單的例子:f(x)=x?+2x?+3x2+ x + 1。函數(shù)圖如下所示。我們看到函數(shù)的最小值在區(qū)間內 [-0.5,0] 。我們將使用優(yōu)化器來查找確切的值。
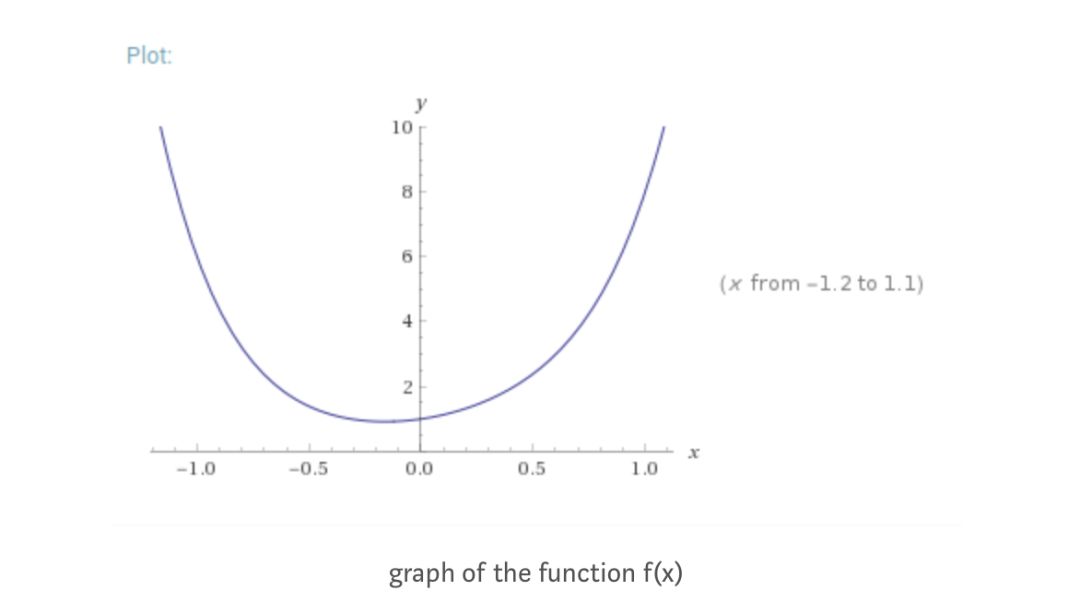
首先,我們定義需要最小化的函數(shù)
1function f(x)
2{
3const f1 = x.pow(tf.scalar(6, 'int32')) //x^6
4const f2 = x.pow(tf.scalar(4, 'int32')).mul(tf.scalar(2)) //2x^4
5const f3 = x.pow(tf.scalar(2, 'int32')).mul(tf.scalar(3)) //3x^2
6const f4 = tf.scalar(1) //1
7return f1.add(f2).add(f3).add(x).add(f4)
8}
現(xiàn)在我們可以迭代該函數(shù)以找到最小值。我們將以 a = 2 的初始值開始。學習速率定義了我們達到最小值的速度。我們將使用 Adam 優(yōu)化器
1function minimize(epochs , lr)
2{
3let y = tf.variable(tf.scalar(2)) //initial value
4const optim = tf.train.adam(lr); //gadient descent algorithm
5for(let i = 0 ; i < epochs ; i++) //start minimiziation ?? ?
6optim.minimize(() => f(y));
7return y
8}
當學習速率為 0.9 時,迭代 200 次之后找到最小值 -0.16092407703399658。
一個簡單的神經(jīng)網(wǎng)絡
現(xiàn)在我們學習如何創(chuàng)建一個神經(jīng)網(wǎng)絡來學習 XOR,這是一個非線性操作。代碼類似于 keras 實現(xiàn)。我們首先創(chuàng)建了兩個輸入和一個輸出的訓練集。
1xs = tf.tensor2d([[0,0],[0,1],[1,0],[1,1]])
2ys = tf.tensor2d([[0],[1],[1],[0]])
然后我們創(chuàng)建兩個具有不同非線性激活函數(shù)的密集層。我們使用具有交叉熵損失的隨機梯度下降。學習速率是 0.1
1function createModel()
2{
3var model = tf.sequential()
4model.add(tf.layers.dense({units:8, inputShape:2, activation: 'tanh'}))
5model.add(tf.layers.dense({units:1, activation: 'sigmoid'}))
6model.compile({optimizer: 'sgd', loss: 'binaryCrossentropy', lr:0.1})
7return model
8}
然后我們對模型進行 5000 次迭代
1await model.fit(xs, ys, {
2batchSize: 1,
3epochs: 5000
4})
最后我們預測訓練集
1model.predict(xs).print()
輸出預期應該是 [[0.0064339], [0.9836861], [0.9835356], [0.0208658]]。
CNN 模型
TensorFlow.js 使用計算圖來自動區(qū)分。我們只需要創(chuàng)建圖層,優(yōu)化器并編譯模型。讓我們創(chuàng)建一個順序模型:
1model = tf.sequential();
現(xiàn)在我們可以為模型添加不同的圖層。讓我們添加帶輸入的第一個卷積層 [28,28,1]
1const convlayer = tf.layers.conv2d({
2inputShape: [28,28,1],
3kernelSize: 5,
4filters: 8,
5strides: 1,
6activation: 'relu',
7kernelInitializer: 'VarianceScaling'
8});
在這里,我們創(chuàng)建了一個 convlayer 接受輸入圖層為 [28,28,1]。輸入將是大小為 28 x 28 的灰色圖像。然后我們對其進行初始化。之后,我們應用一個激活函數(shù),它基本上取張量中的負值并用零替換它們。現(xiàn)在我們可以將此 convlayer 添加到模型中:
1model.add(convlayer);
使用 Tensorflow.js 我們不需要為下一層指定輸入大小,因為在編譯模型后它將自動評估。我們還可以添加最大池,密集層等。這是一個簡單的模型:
1const model = tf.sequential();
2
3//create the first layer
4model.add(tf.layers.conv2d({
5inputShape: [28, 28, 1],
6kernelSize: 5,
7filters: 8,
8strides: 1,
9activation: 'relu',
10kernelInitializer: 'VarianceScaling'
11}));
12
13//create a max pooling layer
14model.add(tf.layers.maxPooling2d({
15poolSize: [2, 2],
16strides: [2, 2]
17}));
18
19//create the second conv layer
20model.add(tf.layers.conv2d({
21kernelSize: 5,
22filters: 16,
23strides: 1,
24activation: 'relu',
25kernelInitializer: 'VarianceScaling'
26}));
27
28//create a max pooling layer
29model.add(tf.layers.maxPooling2d({
30poolSize: [2, 2],
31strides: [2, 2]
32}));
33
34//flatten the layers to use it for the dense layers
35model.add(tf.layers.flatten());
36
37 //dense layer with output 10 units
38model.add(tf.layers.dense({
39units: 10,
40kernelInitializer: 'VarianceScaling',
41activation: 'softmax'
42}));
為了檢查輸出張量,我們可以為任何層應用張量。但是這里的輸入需要的是一個形狀為[BATCH_SIZE,28,28,1],其中BATCH_SIZE表示我們一次應用于模型的數(shù)據(jù)集元素的數(shù)量。以下是如何評估卷積層的示例:
1const convlayer = tf.layers.conv2d({
2inputShape: [28, 28, 1],
3kernelSize: 5,
4filters: 8,
5strides: 1,
6activation: 'relu',
7kernelInitializer: 'VarianceScaling'
8});
9
10const input = tf.zeros([1,28,28,1]);
11const output = convlayer.apply(input);
在檢查 output 張量的形狀后,我們看到它的形狀為 [1,24,24,8]。使用公式評估:
1const outputSize = Math.floor((inputSize-kernelSize)/stride +1);
回到我們的模型,我們意識到我們使用的 flatten() 基本上將輸入從形狀 [BATCH_SIZE,a,b,c] 轉換為形狀 [BATCH_SIZE,axbxc]。這很重要,因為在密集層中我們不能應用 2d 數(shù)組。最后,我們使用了帶有輸出單元的密集層,10 代表了我們識別系統(tǒng)中所需的類別。實際上,該模型用于識別所謂的 MNIST 數(shù)據(jù)集中的手寫數(shù)字。
優(yōu)化和編譯
創(chuàng)建模型后,我們需要一種優(yōu)化參數(shù)的方法。像 SGD 和 Adam 優(yōu)化器都有不同的方法。如下所示創(chuàng)建優(yōu)化器:
1const LEARNING_RATE = 0.0001;
2const optimizer = tf.train.adam(LEARNING_RATE);
這將使用指定的學習速率創(chuàng)建 Adam 優(yōu)化器。現(xiàn)在,我們已準備好編譯模型
1model.compile({
2optimizer: optimizer,
3loss: 'categoricalCrossentropy',
4metrics: ['accuracy'],
5});
在這里,我們創(chuàng)建了使用 Adam 來優(yōu)化損失函數(shù)的模型,該函數(shù)評估預測輸出和真實標簽的交叉熵。
訓練
在編譯模型之后,我們準備在數(shù)據(jù)集上訓練模型。我們需要使用 fit() 函數(shù):
1const batch = tf.zeros([BATCH_SIZE,28,28,1]);
2const labels = tf.zeros([BATCH_SIZE, NUM_CLASSES]);
3
4const h = await model.fit(batch, labels,
5{
6batchSize: BATCH_SIZE,
7validationData: validationData,
8epochs: BATCH_EPOCHs
9});
10
請注意,我們正在為一組訓練集提供 fit 函數(shù)。fit 函數(shù)的第二個變量表示模型的真實標簽。最后,我們有配置參數(shù),如 batchSize 和 epochs。請注意,它 epochs 表示我們迭代當前批次而不是整個數(shù)據(jù)集的次數(shù)。因此,我們可以將該代碼包裝在 for 循環(huán)中,該循環(huán)遍歷訓練集的所有批次。
注意我們使用了特殊的關鍵字 await,它阻塞并等待函數(shù)執(zhí)行完成。這就像運行另一個線程,主線程正在等待擬合函數(shù)完成執(zhí)行。
熱編碼
通常給定的標簽是代表該類的數(shù)字。例如,假設我們有兩個類,一個橙色類和一個蘋果類。然后我們將給出橙色類標簽 0 和蘋果類標簽 1。但是,我們的網(wǎng)絡接受一個大小為 [BATCH_SIZE,NUM_CLASSES] 的張量。因此,我們需要使用熱編碼:
1const output = tf.oneHot(tf.tensor1d([0,1,0]), 2);
2
3//the output will be [[1, 0],[0, 1],[1, 0]]
4
5
因此,我們將 1d 張量標簽轉換為張量形狀[BATCH_SIZE,NUM_CLASSES]。
損失和準確性
為了檢查我們模型的性能,我們需要知道損失和準確性。為此,我們需要使用歷史模型獲取結果。
1//h is the output of the fitting module
2const loss = h.history.loss[0];
3const accuracy = h.history.acc[0];
請注意,我們正在評估 validationData 的損失性和準確性。
預測
假設我們完成了對模型的訓練,并且給出了良好的損失和準確性。是時候預測看不見的數(shù)據(jù)元素的結果了。假設我們的瀏覽器中有一個圖像,或者我們直接從我們的網(wǎng)絡攝像頭拍攝,那么我們就可以使用我們訓練有素的模型來預測它的類。首先,我們需要將圖像轉換為張量
1//retrieve the canvas
2const canvas = document.getElementById("myCanvas");
3const ctx = canvas.getContext("2d");
4
5//get image data
6imageData = ctx.getImageData(0, 0, 28, 28);
7
8//convert to tensor
9const tensor = tf.fromPixels(imageData);
在這里我們創(chuàng)建了一個 canvas 并從中獲取imageData,然后我們轉換為張量。現(xiàn)在張量大小為 [28,28,3] 但模型采用 4 維向量。因此,利用 expandDims 我們可以為張量添加額外的維度。
1const eTensor = tensor.expandDims(0);
因此,輸出張量大小為 [1,28,28,3] 因為我們在索引 0 處添加了維度。現(xiàn)在我們使用 predict() 進行預測。
1model.predict(eTensor);
函數(shù) predict 將返回我們最后一層的值。
轉移學習
在前面的部分中,我們必須從頭開始訓練我們的模型。然而,這是一項昂貴的操作,因為它需要更多的訓練迭代。因此,我們使用稱為 mobilenet 的預訓練模型。它是一款輕巧的 CNN,經(jīng)過優(yōu)化可在移動應用中運行。Mobilenet 受過 ImageNet 訓練。
要加載模型,如下所示:
1const mobilenet = await tf.loadModel(
2 'https://storage.googleapis.com/tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json');
我們可以使用輸入,輸出來檢查模型的結構:
1//The input size is [null, 224, 224, 3]
2const input_s = mobilenet.inputs[0].shape;
3
4//The output size is [null, 1000]
5const output_s = mobilenet.outputs[0].shape;
6
因此,我們需要大小為 [1,224,224,3] 的圖像,輸出將是一個大小為 [1,1000] 的張量,它保存 ImageNet 數(shù)據(jù)集中每個類的概率。
為了簡便起見,我們將采取零值數(shù)組,并試圖預測出 1,000 種類別。
1var pred = mobilenet.predict(tf.zeros([1, 224, 224, 3]));
2pred.argMax().print();
運行代碼后,我得到 class = 21:
現(xiàn)在我們需要檢查模型的內容。為此,我們可以獲得模型圖層和名稱:
1//The number of layers in the model '88'
2const len = mobilenet.layers.length;
3
4//this outputs the name of the 3rd layer 'conv1_relu'
5const name3 = mobilenet.layers[3].name;
當基于另一個數(shù)據(jù)集再次訓練具有 88 個圖層的模型時,是非常昂貴的。因此,基本的技巧是使用這個模型來評估激活(我們不會重新訓練)。
假設我們需要一個模型來區(qū)分胡蘿卜和黃瓜。我們將使用 mobilene tmodel 來計算我們選擇的某個層的激活。然后我們使用具有輸出大小為 2 的密集層來預測正確的類。因此,我們只需要訓練密集層。
首先,我們需要擺脫模型的密集層。
1const layer = mobilenet.getLayer('conv_pw_13_relu');
現(xiàn)在讓我們更新我們的模型,讓這個圖層成為一個輸出
1mobilenet = tf.model({inputs: mobilenet.inputs, outputs: layer.output});
最后,我們創(chuàng)建了可訓練模型,但我們需要知道最后一層輸出形狀:
1//this outputs a layer of size [null, 7, 7, 256]
2const layerOutput = layer.output.shape;
我們看到形狀為 [null,7,7,256],現(xiàn)在我們可以將它輸入到我們的密集層:
1trainableModel = tf.sequential({
2layers: [
3tf.layers.flatten({inputShape: [7, 7, 256]}),
4tf.layers.dense({
5units: 100,
6activation: 'relu',
7kernelInitializer: 'varianceScaling',
8useBias: true
9}),
10tf.layers.dense({
11units: 2,
12kernelInitializer: 'varianceScaling',
13useBias: false,
14activation: 'softmax'
15})
16]
17});
如您所見,我們創(chuàng)建了一個帶有 100 個神經(jīng)元的密集層和帶有大小為 2 的輸出層。
1const activation = mobilenet.predict(input);
2const predictions = trainableModel.predict(activation);
我們可以使用前面的部分來使用某個優(yōu)化器訓練模型。
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4777瀏覽量
100974 -
深度學習
+關注
關注
73文章
5511瀏覽量
121355 -
tensorflow
+關注
關注
13文章
329瀏覽量
60575
原文標題:TensorFlow.js 入門指南
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
如何使用TensorFlow構建機器學習模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論