 谷歌提出能夠自動Debug神經網絡的新方法
谷歌提出能夠自動Debug神經網絡的新方法
眾所周知,神經網絡難以debug。谷歌大腦的Augustus Odena和Ian Goodfellow提出了一種新方法,能夠自動Debug神經網絡。Goodfellow表示,希望這將成為涉及ML的復雜軟件回歸測試的基礎,例如,在推出新版本的網絡之前,使用fuzz來搜索新舊版本之間的差異。
眾所周知,由于各種原因,機器學習模型難以調試(debug)或解釋。這造成了最近機器學習的“可重復性危機”(reproducibility crisis)——對難以調試的技術做出可靠的實驗結論是很棘手的。
神經網絡又特別難以debug,因為即使是相對直接的關于神經網絡的形式問題,解決的計算成本也很高,而且神經網絡的軟件實現可能與理論模型有很大的差異。
在這項工作中,我們利用傳統軟件工程中的一種技術——覆蓋引導模糊測試(coverage guided fuzzing,CGF),并將其應用于神經網絡的測試。
具體來說,這項工作有以下貢獻:
我們對神經網絡引入了CGF的概念,并描述了如何用快速近似最近鄰算法( fast approximate nearest neighbors algorithms)以通用的方式檢查覆蓋率。
我們使用TensorFuzz在已訓練的神經網絡中查找數值問題,在神經網絡及其量化版本之間查找分歧,以及在字符級語言模型中查找不良行為。
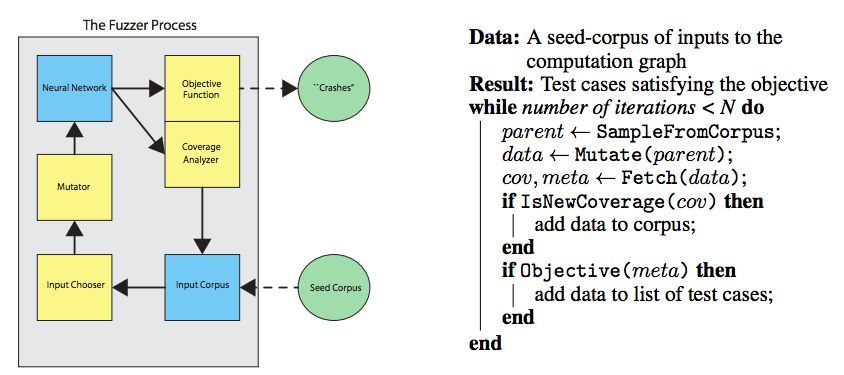
圖1:fuzzing主循環的簡略描述。左:模糊測試程序圖,表示數據的flow。右:用算法的形式描述了模糊測試過程的主循環。
覆蓋引導模糊測試(Coverage-guided fuzzing)
在實際的軟件測試中,覆蓋引導模糊測試(Coverage-guided fuzzing)被用來查找許多嚴重的bug。最常用的兩種coverage-guided模糊測試器是AFL和libFuzzer。這些模糊測試器已經以各種方式被擴展,以使它們更快、或增加代碼中特定部分可以被定位的范圍。
在CGF的過程中,模糊測試過程維護一個輸入語料庫,其中包含正在考慮的程序的輸入。根據一些突變程序對這些輸入進行隨機變化,并且當它們行使新的“覆蓋”時,突變輸入( mutated inputs)被保存在語料庫中。
“覆蓋率”(coverage)是什么呢?這取決于模糊器的類型和當前的目標。一種常見的衡量標準是已經執行的代碼部分的集合。在這種度量下,如果一個新的輸入導致代碼在if語句中以不同于先前的方式分支,那么覆蓋率就會增加。
CGF在識別傳統軟件中的缺陷方面非常成功,因此我們很自然地會問,CGF是否可以應用于神經網絡?
傳統的覆蓋率度量標準要跟蹤哪些代碼行已經執行。在最基本的形式中,神經網絡被實現為一系列的矩陣乘法,然后是元素運算。這些操作的底層軟件實現可能包含許多分支語句,但其中大多都是基于矩陣的大小,或基于神經網絡的架構。因此,分支行為大多獨立于神經網絡輸入的特定值。在幾個不同的輸入上運行的神經網絡通常會執行相同的代碼行,并使用相同的分支,但是由于輸入和輸出值的變化,會產生一些有趣的行為變化。因此,使用現有的CGF工具(如AFL)可能不會發現神經網絡的這些行為。
在這項工作中,我們選擇使用快速近似最近鄰算法來確定兩組神經網絡的“激活”是否有意義上的不同。這提供了一個覆蓋率的度量(coverage metric),即使神經網絡的底層軟件實現沒有使用很多依賴于數據的分支,也能為神經網絡生成有用的結果。
TensorFuzz庫
從前面描述的模糊測試器中獲得靈感,我們做了一個工具,稱之為TensorFuzz。它的工作方式與其他模糊測試器類似,但它更適合神經網絡的測試。
TensorFuzz不是用C或C++編寫的,而是向任意的TensorFlow graph提供輸入。TensorFuzz也不是通過查看基本的blocks或控制流中的變化來測量覆蓋率,而是通過查看計算圖的“激活”。我們在論文中詳細討論了模糊測試器的總體架構,包括數據流和基本構建塊,以及語料庫如何抽樣,如何執行突變,如何評估覆蓋率和目標函數等,具體請閱讀原論文。
實驗結果
我們簡要介紹了CGF技術的各種應用,證明它在一般設置中是有用的。
CGF可以有效地發現訓練好的神經網絡中的數值誤差
由于神經網絡使用浮點數學,因此無論是在訓練期間還是在評估期間,它們都容易受到數值問題的影響。眾所周知,這些問題很難debug,部分原因是它們可能只由一小部分很少遇到的輸入觸發。這是CGF可以提供幫助的一個例子。我們專注于查找導致非數(NaN)值的輸入。
CGF可以快速地找到數值誤差(numerical errors):使用CGF,我們應該能夠簡單地將檢查數值運算添加到元數據并運行模糊測試器(fuzzer)。為了驗證這一假設,我們訓練了一個完全連接的神經網絡來對MNIST數據集里的數字進行分類。我們故意用了一個很糟糕的交叉熵損失,這樣就有可能出現數值誤差。我們對模型進行了35000步的訓練, mini-batch size為100,驗證精度為98%。然后檢查MNIST數據集中是否有導致數值誤差的元素。
如圖2所示,TensorFuzz在多個隨機初始化過程中快速發現了NaN。
圖2:我們使用一些不安全的數值運算訓練了一個MNIST分類器。然后,對來自MNIST數據集的隨機種子運行10次fuzzer。fuzzer每次運行都發現了一個non-finite元素,而隨機搜索從未發現過non-finite元素。左:fuzzer運行時的累計語料庫大小,運行10次。右:fuzzer找到一個滿意的圖像。
其他發現:
基于梯度的搜索技術可能無助于查找數值誤差
隨機搜索對于查找數值誤差來說效率極低
CGF反映了模型與其量化版本之間的分歧
量化(Quantization)是一個存儲神經網絡權重的過程,并使用由較少內存位組成的數值表示來執行神經網絡計算。量化是降低神經網絡計算成本或減小網絡尺寸的流行方法,并廣泛用于在手機上運行神經網絡推理,例如 Android Neural Networks API或TFLite,以及在自定義機器學習硬件中運行推理,例如谷歌的TPU或NVIDIA的TensorRT。
找到量化產生的誤差很重要:當然,如果量化顯著地降低了模型的準確性,那么量化就沒有多大用處。給定一個量化模型,檢查量化在多大程度上降低了精度是有用的。
通過檢查現有數據幾乎找不到錯誤:作為基線實驗,我們使用32位浮點數訓練了一個MNIST分類器(這次沒有故意引入數值問題)。 然后,將所有權重和激活截斷為16-bits,我們在MNIST測試集上比較了32-bit和16-bit模型的預測精度,沒有發現不一致。
但是,CGF可以快速地在數據周圍的小區域找到許多錯誤,如圖3所示。
圖3:我們訓練了一個32-bit浮點數的MNIST分類器,然后將相關的TensorFlow graph截為16-bit 浮點數。左:fuzzer運行時的累計語料庫大小,運行10次。右:fuzzer找到了16-bit 和32-bit 的神經網絡分類不同的圖像
結果顯示,fuzzer在我們嘗試的70%的示例中產生了分歧。也就是說,CGF可以找到在測試時可能發生的真正錯誤。
在給定與CGF相同數量的突變的情況下,隨機搜索未能找到新的錯誤。
結論
我們提出了神經網絡的覆蓋引導模糊測試的概念,并描述了如何在這種情況下構建一個有用的覆蓋率檢查器。我們已經通過使用TensorFuzz查找數值誤差、發現神經網絡和它們的量化版本之間的分歧、以及在RNN中找到不良行為等試驗,證明了TensorFuzz的實用性。最后,我們將同時發布TensorFuzz的實現,以便其他研究人員既可以在我們的工作基礎上進行研究,也可以使用fuzzer來查找實際的問題。
-
谷歌
+關注
關注
27文章
6176瀏覽量
105677 -
神經網絡
+關注
關注
42文章
4776瀏覽量
100948
原文標題:谷歌大腦開源TensorFuzz,自動Debug神經網絡!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于LabVIEW8.2提取ECG特征點的新方法
容差模擬電路軟故障診斷的小波與量子神經網絡方法設計
人工神經網絡實現方法有哪些?
神經網絡移植到STM32的方法
卷積神經網絡模型發展及應用
提高傳感器精度的神經網絡方法
神經網絡電力電子裝置故障診斷技術
基于神經網絡的傳感器故障監測與診斷方法研究
基于神經網絡的傳感器故障監測與診斷方法研究
提高傳感器精度的神經網絡方法
傳感器故障檢測的Powell神經網絡方法
神經網絡在電磁場數值問題中的應用
DENSER是一種用進化算法自動設計人工神經網絡(ANNs)的新方法






 工商網監
工商網監
評論