 DeepMind最新提出“神經算術邏輯單元”,旨在解決神經網絡數值模擬能力不足的問題
DeepMind最新提出“神經算術邏輯單元”,旨在解決神經網絡數值模擬能力不足的問題
DeepMind最新提出“神經算術邏輯單元”,旨在解決神經網絡數值模擬能力不足的問題。與傳統架構相比,NALU在訓練期間的數值范圍內和范圍外都得到了更好的泛化。論文引起大量關注,本文附上大神的Keras實現。
在昆蟲、哺乳動物和人類等許多物種的行為中,表示和操縱數值的能力都是顯而易見的。這表明基本的定量推理是智能(intelligence)的一個基本組成部分。
雖然神經網絡能夠在給出適當的學習信號的情況下成功地表示和操縱數值量,但它們學習的行為通常不會表現出系統的泛化。具體來說,當在測試時遇到訓練時使用的數值范圍之外的數值時,即使目標函數很簡單(例如目標函數僅取決于聚合計數或線性外推),也經常會出現失敗。
這種失敗表明,神經網絡學習行為的特點是記憶,而不是系統的抽象。觸發外推失敗的輸入分布變化是否具有實際意義,取決于訓練過的模型將在何處運行。然而,有相當多的證據表明,像蜜蜂這樣簡單的動物都能夠表現出系統的數值外推(numerical extrapolation)能力,這表明基于數值的系統化推理具有生態學上的優勢。
DeepMind、牛津大學和倫敦大學學院的多名研究人員最新發表的論文“Neural Arithmetic Logic Units”,旨在解決這個問題。研究人員開發了一種新的模塊,可以與標準的神經網絡結構(如LSTM或convnet)結合使用,但偏向于學習系統的數值計算。他們的策略是將數值表示為沒有非線性的單個神經元。對于這些single-value的神經元,研究人員應用能夠表示簡單函數的運算符(例如 +, - ,×等)。這些運算符由參數控制,這些參數決定用于創建每個輸出的輸入和操作。盡管有這樣的組合特征,但它們是可微的,因此可以通過反向傳播來學習。
摘要
神經網絡可以學習表示和操作數值信息,但它們很少能很好地推廣到訓練中遇到的數值范圍之外。為了支持更系統的數值外推(numerical extrapolation),我們提出一種新的架構,它將數值表示為線性激活函數,使用原始算術運算符進行操作,并由學習門(learned gates)控制。
我們將這個模塊稱為神經算術邏輯單元(neural arithmetic logic unit, NALU),參照自傳統處理器中的算術邏輯單元。實驗表明,NALU增強的神經網絡可以學習跟蹤時間,對數字圖像執行算術運算,將數字語言轉化為實值標量,執行計算機代碼,以及對圖像中的對象進行計數。與傳統架構相比,我們在訓練期間的數值范圍內和范圍外都得到了更好的泛化,外推經常超出訓練數值范圍幾個數量級之外。
這篇論文一經發表即引起很多關注,有人認為這篇論文比一眼看上去要更重要,Reddit用戶claytonkb表示:“結合最近的D2NN,我們可以構建超低功耗的芯片,可以在恒定時間計算超級復雜的函數,我們很快就會轉向異構計算架構。”
很快有大神在Keras做出了NALU網絡的實現,感受一下:
https://github.com/kgrm/NALU
神經累加器和神經算術邏輯單元
算術邏輯單元(Arithmetic Logic Unit, ALU)是中央處理器的執行單元,是所有中央處理器的核心組成部分,由與門和或門構成的算數邏輯單元,主要功能是進行二進制的算術運算,如加減乘。
在這篇論文中,研究者提出兩種能夠學習以系統的方式表示和操作數字的模型。第一種方法支持累加積累量(accumulate quantities additively)的能力,這是線性外推的理想歸納偏差。這個模型構成了第二個模型的基礎,即支持乘法外推(multiplicative extrapolation)。該模型還說明了如何將任意算術函數的歸納偏差有效地合并到端到端模型中。
第一個模型是神經累加器(Neural Accumulator,NAC),它是線性層的一種特殊情況,其變換矩陣W僅由-1,0和1組成;也就是說,它的輸出是輸入向量中行的加法或減法。這可以防止層在將輸入映射到輸出時更改數字表示的比例,這意味著無論將多少個操作鏈接在一起,它們在整個模型中都是一致的。我們通過以下方式鼓勵W內的0,1和-1來改善簡單線性層的歸納偏差。
由于硬約束強制W的每個元素都是{-1,0,1}中的一個,這會使學習變得困難,我們提出W在無約束參數方面的連續和可微分參數化: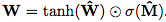 。 這種形式便于用梯度下降進行學習,并產生矩陣,其元素保證在[-1,1]并且偏向接近-1,0或1。
。 這種形式便于用梯度下降進行學習,并產生矩陣,其元素保證在[-1,1]并且偏向接近-1,0或1。
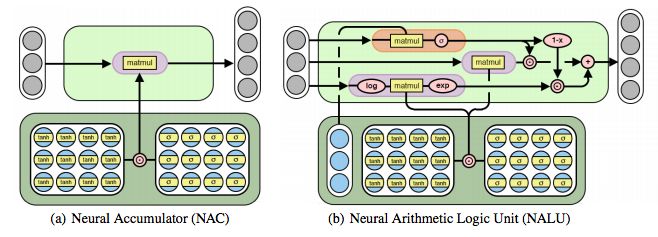
圖2:神經累加器(NAC)是其輸入的線性變換。 變換矩陣是tanh(W)和σ(M)的元素乘積。 神經算術邏輯單元(NALU)使用兩個帶有綁定權重的NAC來啟用加/減(較小的紫色cell)和乘法/除法(較大的紫色cell),由門(橙色的cell)控制
雖然加法和減法使得許多有用的系統泛化成為可能,但是可能需要學習更復雜的數學函數(例如乘法)的強健能力。 圖2描述了這樣一個單元:神經算術邏輯單元(NALU),它學習兩個子單元之間的加權和,一個能夠執行加法和減法,另一個能夠執行乘法,除法和冪函數,如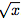 。 重要的是,NALU演示了NAC如何通過門控子操作進行擴展,從而促進了新類型數值函數的端到端學習。
。 重要的是,NALU演示了NAC如何通過門控子操作進行擴展,從而促進了新類型數值函數的端到端學習。
NALU由兩個NAC單元(紫色單元)組成,這兩個單元由學習的S形門g(橙色單元)內插,這樣如果加/減子單元的輸出值應用權重為1(on),則乘法/除法子單元為0(off),反之亦然。 第一個NAC(較小的紫色子單元)計算累加向量a,存儲NALU的加法/減法運算的結果; 它與原始NAC的計算方式相同(即a = Wx)。 第二個NAC(較大的紫色子單元)在對數空間中運行,因此能夠學習乘法和除法,將結果存儲在m:
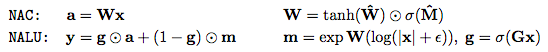
總之,這個單元可以學習由乘法,加法,減法,除法和冪函數組成的算術函數,其推斷方式是在訓練期間觀察到的范圍之外的數字。
實驗和結果
我們在多個任務領域(合成、圖像、文本和代碼)、學習信號(監督學習和強化學習)和結構(前饋和循環)進行實驗。結果表明,我們提出的模型可以學習捕獲數據潛在數值性質的表示函數,并將其推廣到比訓練中觀察到的數值大幾個數量級的數值。我們還觀察到,即使不需要外推,我們的模塊相對于線性層也顯示出優越的計算偏差。在一種情況下,我們的模型在誤差率上超過了最先進的圖像計數網絡54%。
任務1:簡單的函數學習任務
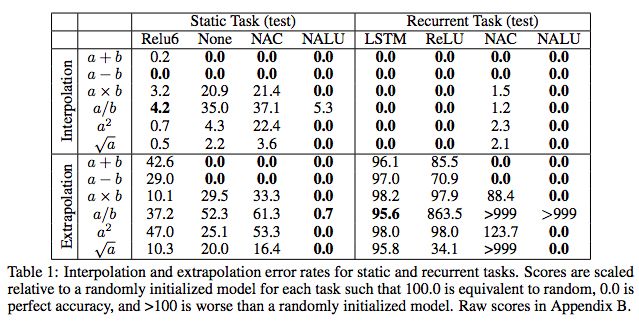
表1:靜態和循環任務的插值和外推誤差率。
任務2;MNIST計數和算術任務

表2:長度為1,10,100和1000的序列的MNIST計數和加法任務的準確度。
結果顯示,NAC和NALU都能很好地推斷和插值。
任務3:語言到數字的翻譯任務

表3:將數字串轉換為標量的平均絕對誤差(MAE)比較。

圖3:對先前未見過的查詢的中間NALU預測。
圖3顯示了隨機選擇的測試實例中NALU的中間狀態。 在沒有監督的情況下,模型學會跟蹤當前token的未知數的合理估計,這允許網絡預測它以前從未見過的token。
程序評估

圖4:簡單的程序評估,外推到更大的值。
我們比較了三種流行的RNN(UGRNN,LSTM和DNC),結果顯示即使域增加了兩個數量級,外推也是穩定的。
學習在網格世界環境中跟蹤時間
圖5 :(上)Grid-World環境中時間跟蹤任務的幀。 智能體(灰色)必須在指定時間移動到目的地(紅色)。 (下)NAC提高了A3C智能體所學到的外推能力。
MNIST奇偶校驗預測任務和消融研究
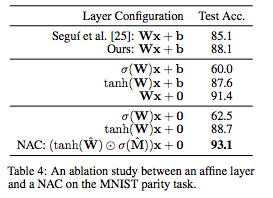
表4:關于MNIST奇偶校驗任務的affine層和NAC之間的消融研究。
表4總結了變體模型的性能。結果顯示,去除偏差并對權重應用非線性顯著提高了端到端模型的準確性,即使大多數參數不在NAC中,NAC將先前最佳結果的誤差減少了54%。
結論
目前神經網絡中數值模擬的方法還不夠完善,因為數值表示方法不能推廣到訓練中觀察到的范圍之外。我們已經展示了NAC和NALU是如何在廣泛的任務領域中糾正這兩個缺點的,它促進了數字表示和在訓練過程中觀察到的范圍之外的數值表示函數。然而,NAC或NALU不太可能是每個任務的完美解決方案。相反,它們舉例說明了一種通用設計策略,用于創建具有針對目標函數類的偏差的模型。這種設計策略是通過我們提出的單神經元數值表示(single-neuron number representation)來實現的,它允許將任意(可微的)數值函數添加到模塊中,并通過學習門控制,正如NALU在加法/減法和乘法/除法之間實現的那樣。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100792 -
函數
+關注
關注
3文章
4332瀏覽量
62640
原文標題:DeepMind重磅:神經算術邏輯單元,Keras實現
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論