 以驍龍845為例 比較X86與ARM真正的區別
以驍龍845為例 比較X86與ARM真正的區別
高通馬上要推曉龍855,華為也要推出麒麟980處理器了,通過媒體的泛濫宣揚,感覺到現在手機端的處理器真是越來越強大了,有很多人應該都有疑問,如此強大的ARM架構的移動處理器現在到底相當于x86的哪個級別的處理器?
帶著疑問,我們找到了幾個知乎大神的解答,推送給大家。以曉龍845為例,主要通過理論分析的方法來做出比較。
雖然是以驍龍845來做比較,但我認為要比的應該是CPU,最多再帶個GPU的對比,至于845相當于Intel哪個處理器,無非就是要跨平臺對比一下,但是問題在于盡管性能可以使用標準C/C++規范編寫相應的通用計算項目來計算(比如geekbench,比如SPEC),但是由于他們往往運行在不同的平臺,所以對于他們的差異民間一直都有各種說法,通過個人體驗,模擬器,游戲畫面來衡量的說法層出不窮,但實際上,如果只是理論比較,其實已經沒有太大難度。
很多人說很難看到結論,所以我把結論放在前面,A75的845在大的架構設計規模上更接近Nehalem,比如ROB條目128,后端執行單元Intel有大量復用端口的計算單元,執行單元規模相比A75互有高低,但A75復用的程度低,某些情況效率更高,向量計算能力也接近SSE4的Nehalem,也就是一代酷睿i系列,在很多細節上有一定改進,某些方面能接近Sandy bridge,所以理論上能達到同頻率的一代酷睿i或者二代酷睿i系列之間的性能,相比同樣是三發射的apollolake和Gemini Lake,A75的ROB和后端執行單元也稍有優勢,但是某些方面較差,比如APL和Gemini lake都有3個ALU,A75只有2個,所以嚴格地說A75也是Gemini Lake左右的架構產品。
X86與ARM真的區別很大嗎?
如果你問他們的出身,那他們的確有很大區別,很多人會說CISC或者RISC的區別,但事實上X86歷經40年,ARM已經30多年了,如果會傻到不吸取對方優秀的特性,那他們早就被淘汰了,如今X86和ARM在架構和執行單元層面已經有大量相似之處,排除內存模型一個還在用TSO-Modle,一個用weak-modle外,ARM和X86已經高度接近,IntelCPU從486開始就已經有了RISC的影子,從奔騰開始一個新的復雜譯碼邏輯電路開始加入到CPU前端,它會將CISC指令翻譯為RISC風格的指令,這被稱為μop,之后處理器的前后端就會按一個亂序RISC處理器一樣執行,同樣ARM處理器也在A9開始擁有了亂序超標量流水線,A8開始有了NEON向量指令集,如今ARM處理器也有了共享式的三級緩存,所以,糾結ARM和X86是精簡還是復雜意義不大,歸根結底還是架構設計到底多大規模,執行一些使用標準C/C++語句編譯出來的benchmark 表現出來的性能說話。
A75與Intel哪個架構最接近
A75簡單的一個架構流水線框圖,前端解碼寬度為3,dispatch總計高達9μops(6個標量,3個向量),實際亂序重排窗口(ROB)條目數和A72/73一樣,都是128,后端EU 8個,三個向量EU,2個int標量EU和2個內存子系統EU(Load/store)以及一個雙倍的分支跳轉單元,其中兩個NEON FP單元(其實應該是執行計算的單元,不僅僅是浮點)實現1X128 MUL+1X128 ADD,或1X128 FMA。
那Intel這邊的架構呢,Intel架構近年演進大致如下
從架構層面來說nehalem/sandy bridge/haswell/Skylake是新架構,這些架構有明顯的改變,我們先來看Skylake,目前Intel最先進的架構
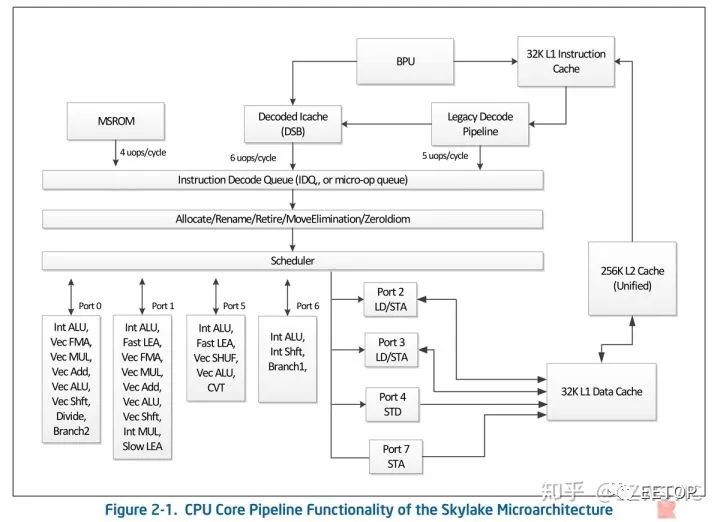
前端解碼寬度為5(4簡單1復雜),但由于實際執行和分發單元的限制,SKL依舊是4發射處理器,亂序重排緩沖區高達224條目,后端與A75一樣,8個EU端口,但是每個端口掛的計算單元就很多了,比如A75分開掛載的NEON向量單元和標量int單元,在Intel這端口0,1,5具備同時有向量和標量單元的特點,同時,Intel SKL的內存子系統端口2.3.4.7,2個可以實現L/S,另外兩個分別實現STD(store data)和STA(store address),顯示Intel處理器同時會擁有較好的內存性能,同時向量和標量單元大量復用同一個端口,表現Intel認為這樣能做到最大化的后端利用率,這一點與之相反的是9810擁有12個后端EU
這樣看來,A75是比不過SKL的,實際上,即使是GB4上,單核2.8Ghz的A75也就2400分,而SKL 3.2Ghz就能做到4000分。
那接下來我們再看Haswell,
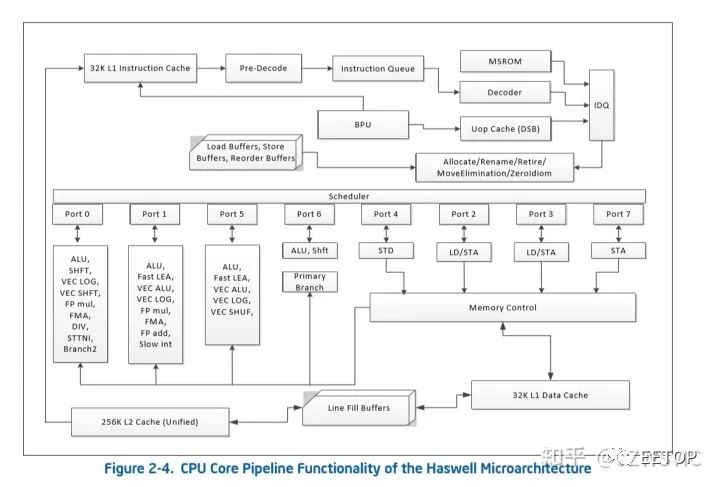
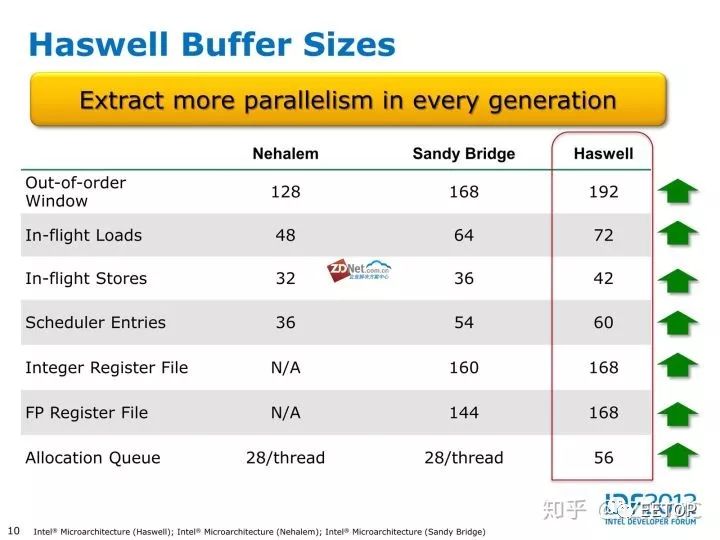
類似SKL那樣的架構流水線圖我暫時沒有那么好的圖,但是大致來說,相比SKL,ROB條目數從224降為192,前端解碼寬度從5變成4(3簡單1復雜),(依舊4發射),寄存器,allocation深度,都有下降,后端EU依舊是8端口,0.1.5三個端口依舊同時掛載向量和標量單元,依舊是2.3.4.7四個端口負責內存子系統,但是值得注意的是,Haswel開始intel主流處理器開始擁有2個FMA 256bit向量單元(端口0.1)但是與SKL不同的是,如果執行向量浮點加法只有端口1才能實現,端口0的FMA單元不能執行向量浮點加法,所以HSW/BDW的向量浮點加法是1X256峰值,乘法是2X256,乘加混合峰值是2X256 FMA,但是SKL則是2個FMA單元所在端口均可執行向量浮點加法
總的來說,HSW作為4發射,192ROB,8EU,雙256 FMA,4內存子系統EU的處理器,架構依舊優秀于A75,根據Intel數據,SKL比HSW IPC平均高14-15%,所以按這樣去換算GB4成績,HSW依舊IPC高于A75。
HSW之前的便是SNB架構
SNB的情況很明顯了,之前上面的圖也有寫SNB和HSW的對比,相比之下,寄存器,分發隊列深度,ROB進一步下降,ROB數目為168(就這樣還比A75多),前端依舊為四指令解碼,但是這里可以看出,SNB的后端端口只有6了,這樣在后端執行效率上A75有了一定機會追趕,同時內存子系統下降為3,2個L/STA,1個STD,這樣來看內存性能并不會比A75高太多,同時Intel一直將branch,JMP,shuffle之類的單元與計算單元掛在同一個端口,雖然大幅提高了后端端口利用率,但是這樣也在某些情況成為瓶頸,根據Intel數據,HSW又比SNB高了14-15%的IPC
同時SNB的向量單元下降為1X256 FP ADD/1X256 FP MUL/2X256 MUL+ADD(無FMA),向量int則為128bit(AVX2開始整數SIMD才升級為256)
從intel公布的IPC來看,SKL要比SNB IPC高30%以上,如果按GB4 4000分/3.2Ghz換算,假設完全符合Intel的數據,且頻率對性能影響呈線性,SNB 2.8Ghz的GB4成績大約為2600-2700分,這樣算是很接近A75了,我查了一下,2410M(單核2.9Ghz)就是2700分左右,說明還是很準的。
最后便是NHM,
NHM的ROB終于減到128,前端解碼寬度依舊為4,(3簡單1復雜),總的μops為7(A75 9),同時NHM也沒有了AVX,SSE SIMD向量寬度和NEON一樣是128bit,執行1X128 FADD/1X128 FMUL,無FMA,同時6個后端執行端口,總體來說A75的架構指標和NHM接近,包括向量單元,根據Intel數據,SNB比NHM IPC高11%,這樣依舊按GB4來推,2600/2700減去11%,大概的確和A75的GB4成績很接近,而這從架構層面也是大致說得通的。
相比之下現今的Apollo Lake的Goldmont(包括Gemini Lake的Goldmont+,兩者略有不同)更接近A75,比如前端三解碼寬度,后端retired寬度增加到4,48-scheduler entries(介于NHM與SNB之間),后端來看Goldmont+也是8EU,4ALU,2FP ALU,1個L/S和一個AGU,Intel提到ROB會更大,但是并沒有說明實際數值。
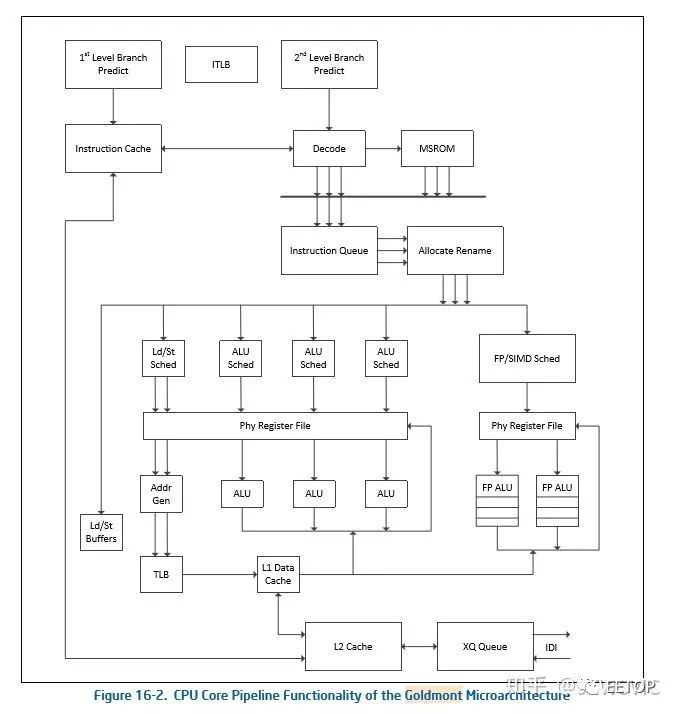
Goldmont
Goldmont+
GB4可靠嗎?
我認為GB4的測試項目不是什么大問題,因為他有FFT和GEMM項目,這些項目支持到了AVX-512指令集,這足以讓一堆古董測試軟件汗顏,如果X86派喜歡安慰自己,看看GEMM和FFT成績足以滿足你的需要,當然ARM也可以堆SIMD單元,蘋果的SIMD成績依舊不差,從他的編譯角度來說,Windows使用VS2015編譯為windows運行程序(沒用X86最快ICC)蘋果用Xcode,測試內容從PDF,HTML,到ray-trace/FFT/GEMM,我認為這些項目是沒什么大問題的,相對來說,Geekbench的問題是很多項目測試時間太短,以致于性能超強的處理器重載時間極短甚至沒來得及重載就結束了,但是項目我認為不是什么問題,很多成績其實也可以解釋的通
14核7940X只比8核7820X多了這么一點點
Intel官方的IPC變化數據(見右圖),SKL相比BDW高10%(見最上面的SKL架構流水線圖)
所以從架構角度來說,A75的845和NHM/SNB架構比較接近,相當于4核NHM-SNB(當然還要看A75四大核全開的頻率)而且因為設計的時代A75更晚,高通可以規避很多當初設計的一些問題,某些方面效率更高),但是也不代表ARM就沒有猛男,蘋果A11的架構(嚴格的說A7就是了)和9810的架構就是一個很多方面超過SKL的規模的胖核心,而很多人說那為什么835跑win10那么差,這里要提到一個往事,
Transmeta公司曾經對x86指令集的Emulation(Emulation這個詞很難翻譯)。簡單地說,Emulation就是把x86指令集看成一個虛擬機的指令集,然后用類似JIT編譯器的技術
如今最廣為人知的Emulator是Qemu,x86、MIPS、PowerPC、Sparc、MC68000它都可以支持。一般而言,Emulation會導致性能下降一個甚至若干個數量級,根本不足為慮。
1995年,Transmeta公司成立,經過艱苦的秘密研發,于2000年推出了Crusoe處理器,用Emulation的方式,在一款VLIW(超長指令字)風格的CPU上執行x86的程序,這樣就規避了沒有x86指令集授權的問題。Transmeta的牛X在于,雖然是Emulation,但實現了相對接近Intel處理器的性能,同時功耗低很多。2000年年底Transmeta的IPO大獲成功,其風光程度,直到后來谷歌IPO的時候才被超過。
Transmeta最后還是失敗了,Intel在渠道上打壓它是次要原因,性能不足是主要原因。雖然VLIW在90年代中后期被廣為推崇,但事實證明,它的性能比起亂序執行的超標量架構,還是差一截。
而微軟也是用了這么一個技術,實現了直接的驍龍835運行原本編譯為X86指令集的程序,但是這樣不可避免性能要下降,而且未經許可翻譯別人的ISA做CPU是有違反專利可能的,為此,Intel在去年發表博客 Intel's X86: Approaching 40 and Still Going Strong。
細數X86擴展的同時也強調專利問題,暗指某些公司試圖仿真X86 ISA(try to emulate Intel’s proprietary x86 ISA without Intel’s authorization),不過實踐證明,這樣的仿真并沒有真正構成侵犯專利,高通和微軟這樣做造成的性能損失已經比直接使用虛擬機好很多,但是內存模型導致的差異,Emulation造成的性能損失不可避免。
作者:AiHaibara
由于搭載驍龍845的Windows設備還沒出現,可以用驍龍835做一個推測。
目前驍龍835已經被用在了筆記本上,跑Windows系統后,跑分大幅下降。這是現在市面上兩款搭載驍龍835的筆記本,華碩NovaGo和惠普Envy X2,跑分差不多單核850,多核3000上下。
華碩NovaGo跑分
▲惠普Envy X2跑分
我們都知道安卓系統下,驍龍835跑分是單核1900左右,多核6500左右,而驍龍845是單核2400左右,多核8500左右。單核和多核分別差不多有25%和30%的提升,按照這個提升幅度,推測驍龍845跑Windows系統大概是單核1100左右,多核4000左右。Windows系統下符合這個分數的英特爾處理器大概是奔騰N4200,賽揚J3455這種低頻U的水平。主頻過2GHz的奔騰或賽揚單核分數就很高了。
像超低壓版的i5-4300Y,驍龍845也就憑借多出四倍的核心數和兩倍的線程在多核分數持平,單核完全被按在地上摩擦。
總之驍龍845雖然放手機里很強,但是和電腦處理器還是沒法比,不是一個級別的東西。 以上均為個人的推測觀點。
作者:張殺豬
定調:845綜合性能肯定是遠遠不如高端桌面平臺的,目測大概是CM水平。量化方式基本就是整數浮點內存帶寬IO速度,GPGPU通用計算紋理頂點等等。
這個答案給我最大的啟示就是,不要和“本不打算講道理的人”講道理。建議蜜汁尬杠的人先想一想什么是性能,什么決定了性能,只有在達成這一共識之后,接下來的討論才有意義。
本題是討論845相當于桌面的哪個檔次,不是討論手機電腦誰強,更不是討論簡單/復雜指令集的問題。從定位上來看,845最多算民用旗艦級,因為手機芯片本身定位的劃定就沒有桌面端復雜,和服務器端的E5并不是對應的,桌面端在定位上類似的最多就是民用i7,如果硬要討論手機端和電腦端整體性能差距,那就對比845是i7 8700k的幾分之一就行了,在市場占有率上這兩者是比較普及的。如果硬要抬杠,arm端也不是沒有服務器設備,非得說cisc或者risc什么的,建議抬出神威太湖之光(alpha是簡單指令集的)。
另外提一下,這么多人張口閉口就說簡單指令集什么的,我敢說至少有百分之八十的人除了幾個詞以外一無所知,根本不知道指令集是什么。
該問題以下,大量的反智答案和評論,很難想象科學如此普及的今天,玄學主義還如此盛行。
pps:和智商不夠的人辯論本身就是我的失誤,我強烈建議和我抬杠這種問題的人先把本科的數電模電過了,再學學簡單的COMS相關,有條件讀兩年安卓開發,否則我說的術語連看都看不懂,直接瞎掰真絕了,說atom秒arm旗艦的被打臉之后,開始扯a11和至尊i7甚至i9強弱問題了,并且開始積極的百度出部分服務器處理器型號。在此奉勸一下,這是一個關于驍龍845性能的問題,我的答案也從來沒那么極端的說秒這個那個的,從一開始我也就說845cpu性能基本六七代CM,初代i3到i5水平,抬杠的自行滾蛋,沒時間和民科浪費,強烈建議卸載知乎,去今日頭條淘寶頭條秀優越。
ps:每一次受邀請回答問題,都是抱著一個和平交流的心態,然而總是有人試圖無腦噴,那么我在此鄭重重復一下,對于只用生殖器交流的人,我就只能盡力把對方生殖器賽進對方本人的呼吸道。
有些人確實很可惡,就好比連初中數學題都搞不定,非要去解本科難度的高階偏微分線性方程,雖然自己完全不會算,但是卻毫無根據的指責其他算出來的人不正確,并且完全不講邏輯,上來就一句欽定不對。那么我很不友善的提醒一句,就您這兩把刷子,just pee as the mirror(惡搞英語,不要當真)。
我水平不高,但是我不裝逼啊,我不罵人啊,我不懂的我不說行吧。
對樓上某些答案。為什么你們愿意相信一個專門為x86架構設計的系統,能夠完整發揮arm的性能?
說我連uwp都不知道,神tm邏輯,莫不是活在十年前,uwp用過嗎你,這次835平板是虛擬機上的win10,可以運行32bit .exe應用的,win10uwp和win10都分不清,硬件軟件常識都不知道就想來我答案下拉屎,還出來掛我,給你留點面子本來不想說太多,自己出來找丟人。果斷拉黑。
科普一下:UWP即Windows 10中的Universal Windows Platform簡稱。即Windows通用應用平臺,在Win 10 Mobile/Surface(Windows平板電腦)/PC/Xbox/HoloLens等平臺上運行,uwp不同于傳統pc上的exe應用,也跟只適用于手機端的app有本質區別。它并不是為某一個終端而設計,而是可以在所有windows10設備上運行。
對于掛我的那位,諾基亞lumia1520上那個才是uwp,不懂裝懂別丟人了,uwp上跑分你見過嗎,驍龍800GPU就吊打BT,cpu整數差不多,整個bt只有atom z3740以上才算湊合,845比800綜合提升六倍不止,cpu提升不少于三倍,還提賽揚?起碼來說845相當于core m檔次,賽揚除了CPU多核跑分以外也沒別的了。
我估計很多人非常難以接受,n多年前大幾千配的電腦,還不如現在兩千多塊錢的手機。況且前者的功耗是后者的幾十倍。
在目前的CMOS技術中,刨除英特爾,其他工藝基本上高頻性能功耗比都不怎么地,比方說三星本代旗艦Exynos9810的 M3核心,采用三星10nmLPP工藝。在同樣3w功耗下,單核心能跑到2.7GHz,雙核心2.4,四核心則是1.8GHz,也就是說當頻率到一個高度之后,再提高一點可能都要巨大的功耗代價。所以不要想當然的認為功耗高就性能強。
回到x86和ARM這樣老生常談的問題,我有一個答案愿意拋磚引玉,不太專業,但是可以作為一個科普的參考。
原文:用845帶模擬器跑分,然后用賽揚跑原生win10,虧你們想的出來。還不如反過來跑安兔兔,被動散熱的845手機能27萬分,主動散熱i5 6300h+950m開模擬器也就30萬。用以上的邏輯就能認為i5 6300h等于845等于n3450了?i5 4210m等于835等于atom z8500?用賽揚以及核顯開個模擬器打個崩壞3,刺激戰場啥的讓我見識一下。我五百塊買的寨板賺大了。要懷疑最多也就是從跑分軟件入手,這么雙標真無解。
這就是傳說中的arm版win10,Win10把x86轉成arm讓835跑,不知道有沒有硬件編譯層,本人英語一般,就不翻譯了,大家自己看這效率和native比如何。目測還不如x86模擬器跑安卓。
-
ARM
+關注
關注
134文章
9097瀏覽量
367555 -
X86
+關注
關注
5文章
294瀏覽量
43467 -
驍龍845
+關注
關注
4文章
536瀏覽量
57042
原文標題:高通驍龍845到底相當于哪一個級別的英特爾PC端處理器?
文章出處:【微信號:eetop-1,微信公眾號:EETOP】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
X86與ARM,江湖廝殺鹿死誰手?
Powerpc架構與X86架構的區別
ARM版和x86版Windows 8的區別
驍龍820支持Win10運行x86程序 性能可媲美i3!
驍龍835相當于酷睿幾代_驍龍835相當于intel的哪個級別
什么叫arm架構_X86架構與ARM架構有什么區別
一文看懂arm架構和x86架構有什么區別
醫療設備逐漸從X86轉到ARM平臺主要原因是什么
X86主板與ARM硬件平臺之間的區別是什么
ARM架構和X86架構二者之間的區別是什么
X86架構與Arm架構的區別





 工商網監
工商網監
評論