 一個優秀的算法工程師必須具備哪些素質?
一個優秀的算法工程師必須具備哪些素質?
導言
怎樣成為一名優秀的算法工程師?這是很多從事人工智能學術研究和產品研發的同學都關心的一個問題。面對市場對人才的大量需求與供給的嚴重不足,以及高薪水的誘惑,越來越多的人開始學習這個方向的技術,或者打算向人工智能轉型。市面上各種魚龍混雜的培訓班以及誤導人的文章會把很多初學者帶入歧途,浮躁的跟風將會讓你最后收獲甚微,根本達不到企業的用人要求。為了更好的幫助大家學習和成長,少走彎路,在今天的文章里,SIGAI的作者以自己的親身經歷和思考,為大家寫下對這一問題的理解與答案。
首先來看一個高度相關的問題:一個優秀的算法工程師必須具備哪些素質?我們給出的答案是這樣的:
數學知識
編程能力
應用方向的知識
對自己所做的問題的思考和經驗
除去教育背景,邏輯思維,學習能力,溝通能力等其他方面的因素,大多數公司在考察算法工程師的技術水平時都會考慮上面這幾個因素。接下來我們將按照這幾個方面進行展開,詳細的說明如何學習這些方面的知識以及積累經驗。
數學知識
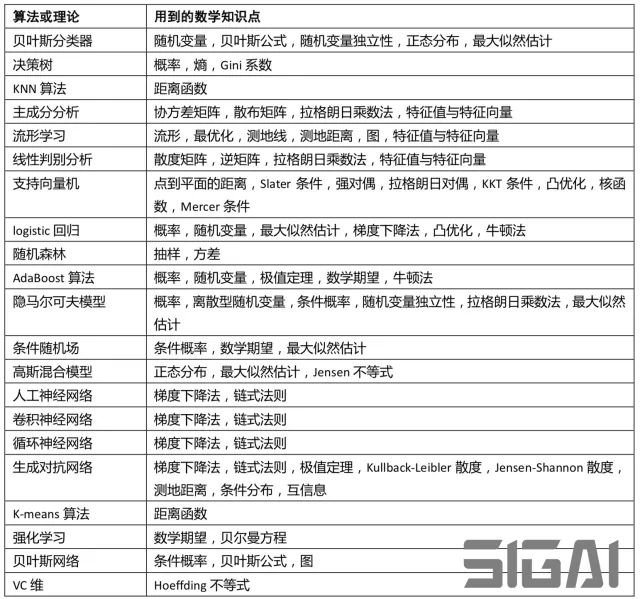
與其他工作方向如app、服務器開發相比,以及與計算機科學的其他方向如網絡,數據庫,分布式計算等相比,人工智能尤其是機器學習屬于數學知識密集的方向。在各種書籍,論文,算法中都充斥著大量的數學公式,這讓很多打算入門的人或者開始學習的人感到明顯的壓力。首先我們考慮一個最核心的問題:機器學習和深度學習究竟需要哪些數學知識?在SIGAI之前的公眾號文章“學好機器學習需要哪些數學知識”里,我們已經給出了答案。先看下面這張表:
更多算法工程師的必讀文章,請關注SIGAICN公眾號
上面的表給出了各種典型的機器學習算法所用到的數學知識點。我們之前已經總結過,理解絕大多數算法和理論,有微積分/高等數學,線性代數,概率論,最優化方法的知識就夠了。除流形學習需要簡單的微分幾何概念之外,深層次的數學知識如實變函數,泛函分析等主要用在一些基礎理論結果的證明上,即使不能看懂證明過程,也不影響我們使用具體的機器學習算法。概率圖模型、流形學習中基于圖的模型會用到圖論的一些基本知識,如果學習過離散數學或者數據結構,這些概念很容易理解。除此之外,某些算法會用到離散數學中的樹的概念,但很容易理解。
如果你已經學過這些大學數學課,只要把所需的知識點復習一遍就夠了。對于微積分,通俗易懂而又被廣為采用的是同濟版的高等數學:
在機器學習中主要用到了微分部分,積分用的非常少。具體的,用到了下面的概念:
導數和偏導數的定義與計算方法,與函數性質的關系
梯度向量的定義
極值定理,可導函數在極值點處導數或梯度必須為0
雅克比矩陣,這是向量到向量映射函數的偏導數構成的矩陣,在求導推導中會用到
Hessian矩陣,這是2階導數對多元函數的推廣,與函數的極值有密切的聯系
凸函數的定義與判斷方法
泰勒展開公式
拉格朗日乘數法,用于求解帶等式約束的極值問題
其中最核心的是多元函數的泰勒展開公式,根據它我們可以推導出梯度下降法,牛頓法,擬牛頓法等一系列最優化方法。
如果你想要深入的學習微積分,可以閱讀數學系的教程,稱為數學分析:
與工科的高等數學偏重計算不同,它里面有大量的理論證明,對于鍛煉數學思維非常有幫助。北大張筑生先生所著的數學分析可謂是國內這方面教材的精品。
下面來看線性代數,同樣是同濟版的教材:
如果想更全面系統的學習線性代數,可以看這本書:
相比之下,線性代數用的更多。具體用到的知識點有:
向量和它的各種運算,包括加法,減法,數乘,轉置,內積
向量和矩陣的范數,L1范數和L2范數
矩陣和它的各種運算,包括加法,減法,乘法,數乘
逆矩陣的定義與性質
行列式的定義與計算方法
二次型的定義
矩陣的正定性
特征值與特征向量
奇異值分解
線性方程組的數值解
機器學習算法處理的數據一般都是向量、矩陣或者張量。經典的機器學習算法輸入的數據都是特征向量,深度學習算法在處理圖像時輸入的2維的矩陣或者3維的張量。掌握這些概念是你理解機器學習和深度學習算法的基礎。
概率論國內理工科專業使用最多的是浙大版的教材:
如果把機器學習所處理的樣本數據看作隨機變量/向量,就可以用概率論的方法對問題進行建模,這代表了機器學習中很大一類方法。在機器學習里用到的概率論知識點有:
隨機事件的概念,概率的定義與計算方法
隨機變量與概率分布,尤其是連續型隨機變量的概率密度函數和分布函數
條件概率與貝葉斯公式
常用的概率分布,包括正態分布,伯努利二項分布,均勻分布
隨機變量的均值與方差,協方差
隨機變量的獨立性
最大似然估計
這些知識不超出普通理工科概率論教材的范圍。
最后來說最優化,幾乎所有機器學習算法歸根到底都是在求解最優化問題。求解最優化問題的指導思想是在極值點出函數的導數/梯度必須為0。因此你必須理解梯度下降法,牛頓法這兩種常用的算法,它們的迭代公式都可以從泰勒展開公式而得到。
凸優化是機器學習中經常會提及的一個概念,這是一類特殊的優化問題,它的優化變量的可行域是凸集,目標函數是凸函數。凸優化最好的性質是它的所有局部最優解就是全局最優解,因此求解時不會陷入局部最優解。如果一個問題被證明為是凸優化問題,基本上已經宣告此問題得到了解決。在機器學習中,線性回歸、嶺回歸、支持向量機、logistic回歸等很多算法求解的都是凸優化問題。
拉格朗日對偶為帶等式和不等式約束條件的優化問題構造拉格朗日函數,將其變為原問題,這兩個問題是等價的。通過這一步變換,將帶約束條件的問題轉換成不帶約束條件的問題。通過變換原始優化變量和拉格朗日乘子的優化次序,進一步將原問題轉換為對偶問題,如果滿足某種條件,原問題和對偶問題是等價的。這種方法的意義在于可以將一個不易于求解的問題轉換成更容易求解的問題。在支持向量機中有拉格朗日對偶的應用。
KKT條件是拉格朗日乘數法對帶不等式約束問題的推廣,它給出了帶等式和不等式約束的優化問題在極值點處所必須滿足的條件。在支持向量機中也有它的應用。
如果你沒有學過最優化方法這門課也不用擔心,這些方法根據微積分和線性代數的基礎知識可以很容易推導出來。如果需要系統的學習這方面的知識,可以閱讀《凸優化》,《非線性規劃》兩本經典教材。
編程能力
編程能力是學好機器學習和深度學習的又一大基礎。對于計算機類專業的學生,由于本科已經學了c語言,c++,數據結構與算法,因此這方面一般不存在問題。對于非計算機專業的人來說,要真正學好機器學習和深度學習,這些知識是繞不開的。
雖然現在大家熱衷于學習python,但要作為一名真正的算法工程師,還是應該好好學習一下c++,至少,機器學習和深度學習的很多底層開源庫都是用它寫的;很多公司線上的產品,無論是運行在服務器端,還是嵌入式端,都是用c++寫的。此外,如果你是應屆生,在校園招聘時不少公司都會面試你c++的知識。
C++最經典的教材無疑是c++ primer:
對做算法的人來說,這本書其實不用全部看,把常用的點學完就夠了。對于進階,Effective c++是很好的選擇,不少公司的面試題就直接出自這本書的知識點:
接下來說python,相比c++來說,學習的門檻要低很多,找一本通俗易懂的入門教程學習一遍即可。
數據結構和算法是編寫很多程序的基礎,對于機器學習和深度學習程序也不例外。很多算法的實現都依賴于數組,鏈表,數,排序,查找之類的數據結構和基礎算法。如果有時間和精力,把算法導論啃一遍,你會有不一樣的感受:
對于應屆生來說,學完它對于你通過大互聯網和人工智能公司校園招聘的技術面試也非常有用。
上面說的只是編程語言的程序設計的理論知識,我們還要考慮實際動手能力。對于開發環境如gcc/g++,visual studio之類的工具,以及gdb之類的調試工具需要做到熟練使用。如果是在linux上開發,對linux的常用命令也要熟記于心。這方面的知識看各種具體的知識點和教程即可。另外,對于編程的一些常識,如進程,線程,虛擬內存,文件系統等,你最好也要進行了解。
機器學習與深度學習
在說完了數學和編程基礎之后,下面我來看核心的內容,機器學習和深度學習知識。機器學習是現階段解決很多人工智能問題的核心方法,尤其是深度學習,因此它們是算法工程師的核心知識。在這里有一個問題:是否需要先學機器學習,還是直接學深度學習?如果是一個專業的算法工程師,我的建議是先學機器學習。至少,你要知道機器學習中的基本概念,過擬合,生成模型,ROC曲線等,上來就看深度學習,如沒有背景知識你將不知所云。另外,神經網絡只是機器學習中的一類方法,對于很多問題,其他機器學習算法如logistic回歸,隨機森林,GBDT,決策樹等還在被大規模使用,因此你不要把自己局限在神經網絡的小圈子里。
首先來看機器學習,這方面的教材很多,周志華老師的機器學習,李航老師的統計學習方法是國內的經典。這里我們介紹國外的經典教材,首先是PRML:
此書深厚,內容全面,涵蓋了有監督學習,無監督學習的主要方法,理論推導和證明詳細深入,是機器學習的經典。此外還有模式分類這本書,在這里不詳細介紹。
深度學習目前最權威的教程是下面這本書:
它涵蓋了深度學習的方方面面,從理論到工程,但美中不足的是對應于介紹的相對較少。
強化學習是機器學習很獨特的一個分支,大多數人對它不太了解,這方面的教程非常少,我們推薦下面這本書:
美中不足的是這本書對深度強化學習沒有介紹,因為出版的較早。不知最新的版本有沒有加上這方面的內容。
在這里需要強調的是,你的知識要系統化,有整體感。很多同學都感覺到自己學的機器學習太零散,缺乏整體感。這需要你多思考算法之間的關系,演化歷史之類的問題,這樣你就做到胸中有圖-機器學習算法地圖。其實,SIGAI在之前的公眾號文章“機器學習算法地圖”里已經給你總結出來了。
開源庫
上面介紹了機器學習和深度學習的理論教材,下面來說實踐問題。我們無需重復造車輪子,熟練的使用主流的開源庫是需要掌握的一項技能。對于經典的機器學習,常用的庫的有:
libsvm
liblinear
XGBoost
OpenCV
HTK
Weka
在這里我們不一一列舉。借助于這些庫,我們可以方便的完成自己的實驗,或是研發自己的產品。對于深度學習,目前常用的有:
Caffe
MXNet
除此之外,還有其他的。對于你要用到的開源庫,一定要理解它的原理,以及使用中的一些細節問題。例如很多算法要求輸入的數據先做歸一化,否則效果會非常差,而且面臨浮點數溢出的問題,這些實際經驗需要你在使用中摸索。如果有精力把這些庫的核心代碼分析一遍,你對實現機器學習算法將會更有底氣。以深度學習為例,最核心的代碼無非是實現:
各種層,包括它們的正向傳播和反向傳播
激活函數的實現
損失函數的實現
輸入數據的處理
求解器,實現各種梯度下降法
這些代碼的量并不大,沉下心來,我相信一周之內肯定能分析完。看完之后你會有一種豁然開朗的感覺。
應用方向的知識
接下來是各個方向的知識,與機器學習有關的應用方向當前主要有:
自然語言處理
數據挖掘
知識圖譜
推薦系統
除此之外,還有其他一些特定小方向,在這里不一一列舉。這些具體的應用方向一般都有自己的教材,如果你以后要從事此方向的研究,系統的學習一遍是必須的。
實踐經驗與思考
在說完理論與實踐知識之后,最后我們來說經驗與思考。在你確定要做某一個方向之后,對這個方向的方法要有一個全面系統的認識,很多方法是一脈相承的,如果只追求時髦看最新的算法,你很難做出學術上的創新,以及工程上的優化。對于本問題所有的經典論文,都應該化時間細度,清楚的理解它們解決了什么問題,是怎么解決的,還有哪些問題沒有解決。例如:
機器視覺目標檢測中的遮擋問題
推薦系統中的冷啟動問題
自然語言處理中文分詞中的歧義切分問題
只有經過大量的編程和實驗訓練,以及持續的思考,你才能算得上對這個方向深刻理解,以至于有自己的理解。很多同學對自己實現輪上的算法沒有底氣,解決這個問題最快的途徑就是看論文算法的開源代碼,在github上有豐富的資源,選擇一些合適的,研究一下別人是怎么實現的,你就能明白怎么實現自己的網絡結構和損失函數,照葫蘆畫瓢即可。
計算機以及人工智能是一個偏實踐的學科,它的方法和理論既需要我們有扎實的理論功底,又需要有豐富的實踐能力與經驗。這兩個方面構成了算法工程師最主要的素質。科學的學習路徑能夠讓你取得好的學習效果,同時也縮短學習時間。錯誤和浮躁的做法則會讓你最后事倍功半。這是SIGAI對想進入這個領域,或者剛進入這個領域的每個人要說的!
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238511 -
函數
+關注
關注
3文章
4331瀏覽量
62622 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646
原文標題:怎樣成為一名優秀的算法工程師
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論