 一種自動生成反向傳播方程的方法
一種自動生成反向傳播方程的方法
大神 Geffery Hinton 是反向傳播算法的發明者,但他也對反向傳播表示懷疑,認為反向傳播顯然不是大腦運作的方式,為了推動技術進步,必須要有全新的方法被發明出來。今天介紹的谷歌大腦多名研究人員發表的最新論文Backprop Evolution,提出一種自動發現反向傳播方程新變體的方法,該方法發現了一些新的方程,訓練速度比標準的反向傳播更快,訓練時間也更短。
大神 Geoffrey Hinton提出的反向傳播算法是深度學習的基石。
1986 年,Geoffrey Hinton 與人合著了一篇論文:Learning representations by back-propagation errors,30 年之后,反向傳播算法成了這一波人工智能爆炸的核心。
但去年,Hinton 在接受采訪時表示,他對反向傳播算法 “深感懷疑”,認為應該徹底拋棄反向傳播,另起爐灶。Hinton 認為,反向傳播不是大腦運作的方式,我們的大腦顯然不需要對所有數據進行標注。為了推動進步,必須要有全新的方法被發明出來。
盡管Hinton、以及無數研究者仍未提出全新的、能夠代替傳播的方法,但最近機器學習自動搜索方法取得很多成功,反向傳播算法的變體也得到越來越多的研究。
柏林工業大學、谷歌大腦的多名研究人員在最新發表的論文Backprop Evolution,提出一種自動發現反向傳播方程新變體的方法。研究人員使用領域特定語言將更新的方程描述為原函數列表。

具體來說,研究人員采用一種基于進化的方法來發現新的傳播規則,這些規則在幾個epoch的訓練之后可以最大限度地提高其泛化表現。他們發現了一些新的方程,它們的訓練速度比標準的反向傳播更快,訓練時間更短,并且在收斂時類似標準反向傳播。
自動生成反向傳播方程
反向傳播算法是機器學習中最重要的算法之一。已有研究對反向傳播方程的變體進行了一些嘗試,并取得一定程度的成功 (e.g., Bengio et al. (1994); Lillicrap et al. (2014); Lee et al. (2015); N?kland (2016); Liao et al. (2016))。但盡管有這些嘗試,反向傳播方程的修改并沒有得到廣泛應用,因為這些修改很少對實際應用有改進,甚至有時會造成損害。
受近期機器學習自動搜索方法取得成功的啟發,我們提出一種自動生成反向傳播方程的方法。
為此,我們提出一種領域特定語言(domain specific language),以將這些數學公式描述為原始函數列表,并使用一種基于進化(evolution-based)的方法來發現新的傳播規則。在經過幾個epoch的訓練后,搜索條件是使 generalization 最大化。我們找到了和標準反向傳播效果同樣好的幾個變體方程。此外,在較短的訓練時間內,這幾種變體可以提高準確率。這可以用來改進 Hyperband 之類的算法,在訓練過程中做出基于準確性的決策。
反向傳播
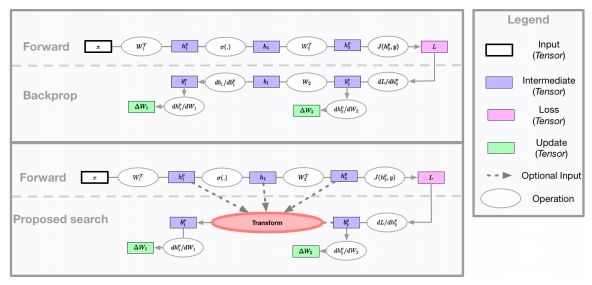
圖1:神經網絡可以看作是一些計算圖。前向圖(forward graph)由網絡設計者定義,而反向傳播算法隱式地為參數更新定義了一個計算圖。本研究的主要貢獻是探索如何利用evolution來找到一個比標準反向傳播更有效的參數更新計算圖。

其中,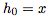 是網絡的輸入,
是網絡的輸入,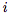 對layer進行索引,
對layer進行索引,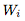 為第
為第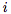
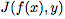 的偏導數,這跟權重矩陣
的偏導數,這跟權重矩陣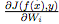 有關。利用反向傳播算法中的鏈式法則可以計算出這個量。為了計算隱藏激活
有關。利用反向傳播算法中的鏈式法則可以計算出這個量。為了計算隱藏激活
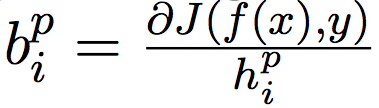
的偏導數,要應用一系列運算:
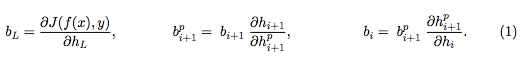
一旦計算出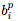 ,就可以將權重更新計算為:
,就可以將權重更新計算為: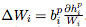
如圖1所示,神經網絡可以表示為前向和后向的計算圖。給定一個由網絡設計者定義的前向計算圖,反向傳播算法定義了一個用于更新參數的反向計算圖。但是,有可能找到一個改進的反向計算圖,從而得到更好的泛化。
最近,用于機器學習的自動搜索方法已經在各種任務上取得了很好的結果,這些方法涉及修改前向計算圖,依靠反向傳播來定義適當的反向圖。與之不同,在這項工作中,我們關注的是修改反向計算圖,并使用搜索方法為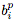
方法
為了找到改進的更新規則,我們使用進化算法來搜索可能的更新方程(update equation)的空間。在每次迭代中,進化控制器將一批突變的更新方程發送給workers池進行評估。每個worker使用其接收到的變異方程來訓練一個固定的神經網絡結構,并將獲得的驗證精度報告給控制器。
搜索空間
受到Bello et al. (2017) 的啟發,我們使用領域特定語言(domain-specific language,DSL)來描述用于計算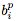
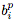
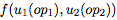 ,其中
,其中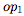
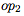 是可能的操作數,
是可能的操作數,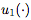 和
和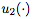 是一元函數,
是一元函數,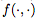 是二元函數。一元函數和二元函數的集合是手動指定的,但是函數和操作數的各個選擇由控制器選擇。每個組件的示例如下:
是二元函數。一元函數和二元函數的集合是手動指定的,但是函數和操作數的各個選擇由控制器選擇。每個組件的示例如下:
操作數(Operands):W(當前層的權重矩陣),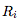 (高斯矩陣),
(高斯矩陣),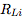 (從
(從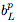 到
到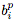
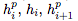 (前向傳播的隱藏激活),
(前向傳播的隱藏激活),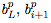 (反向傳播的值)。
(反向傳播的值)。
一元函數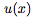
二元函數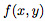
其中,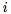
結果得到的量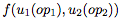 在方程1中被用作
在方程1中被用作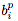
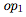 。在實驗中,我們探索了由1到3個二元運算組成的方程。這種DSL雖然簡單,但可以表示復雜的方程,例如標準的反向傳播,feedback alignment,以及direct feedback alignment。
。在實驗中,我們探索了由1到3個二元運算組成的方程。這種DSL雖然簡單,但可以表示復雜的方程,例如標準的反向傳播,feedback alignment,以及direct feedback alignment。
進化算法
進化控制器(evolutionary controller)維護一組已發現的方程。在每次迭代中,控制器執行以下操作之一:1)概率為p的情況下,控制器在搜索期間找到的N個最優競爭力的方程中隨機選擇一個方程,2)概率為1 - p時,控制器從population的其他方程中隨機選擇一個方程。
控制器隨后將k個突變(mutation)應用于所選方程,其中k是從分類分布中提取的。這k個突變中的每一個只是簡單地選擇一個隨機一致的方程組件(例如,一個操作數,一個一元函數,或者一個二元函數),然后將它與另一個隨機選擇的同類組件交換。某些突變會導致數學上不可行的方程,在這種情況下,控制器會重新啟動突變過程,直到成功。N、p和k的分類分布是算法的超參數。
為了創建初始 population,我們簡單地從搜索空間中隨機抽樣N個方程。此外,在我們的一些實驗中,我們從一小部分預定義的方程開始(通常是正常的反向傳播方程或其反饋對齊方程變體)。從現有方程出發的能力是基于強化學習的進化方法具有的優勢。
實驗和結果
在該方法中,用于評估每個新方程的模型的選擇是一個重要的設置。規模更大、更深的網絡會更真實,但需要更長的時間來訓練,而較小的模型訓練更快,但可能導致更新網絡無法推廣。我們通過使用Wide ResNets (WRN) 來平衡這兩個標準,其中WRN有16層,寬度multiplier為2,并且在CIFAR-10數據集中進行訓練。
基線搜索和泛化
在第一次搜索中,控制器提出新方程訓練WRN 16-2網絡20個epoch,并且分別在有或沒有動量的情況下用SGD訓練。根據驗證準確性收集前100個新方程,然后在不同場景下進行測試:
(A1)使用20個epoch訓練WRN 16-2 ,復制搜索設置;
(A2)使用20個epoch訓練WRN 28-10 ,將其推廣到更大的模型(WRN 28- 10的參數是WRN 16-2的10倍);
(A3)使用100個epoch訓練WRN 16-2 ,測試推廣到更長的訓練機制。
實驗結果如表1所示:
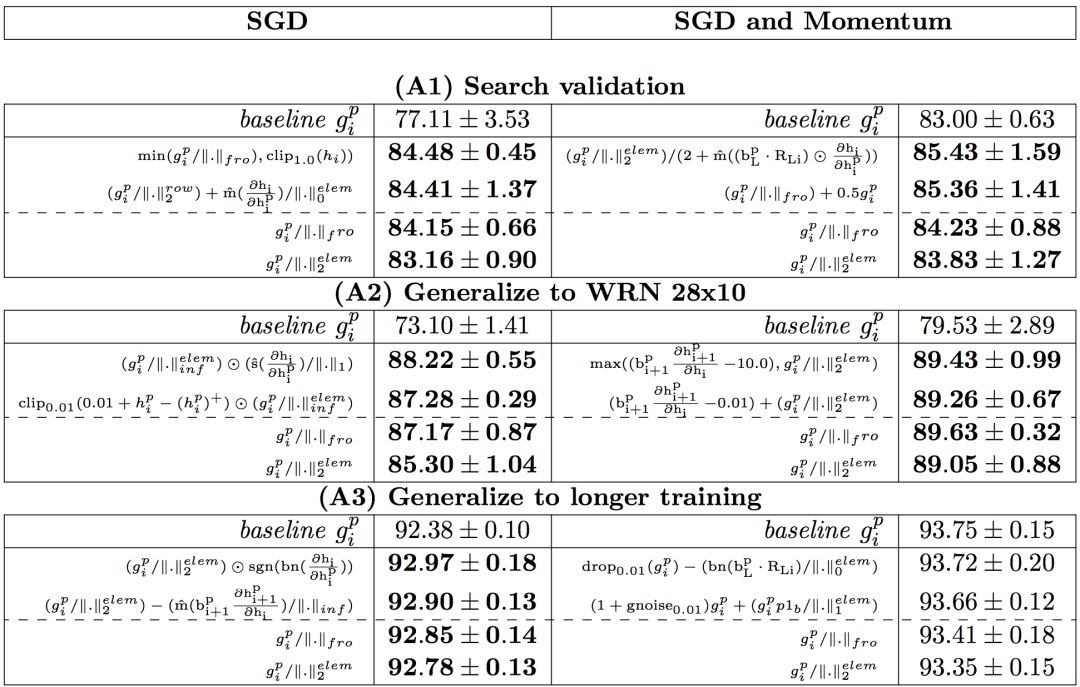

表1:實驗結果
從A1到A3,在每個設置中展示了兩個性能最好的方程,以及兩個在所有設置中都表現良好的方程。在B1中展示了4個性能最好的方程,所有結果均為5次以上的平均測試準確率。基線是梯度反向傳播。比基線性能優于0.1%的結果都用粗體表示。我們用
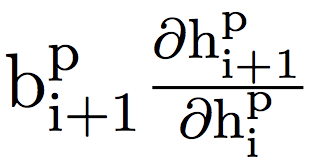
表示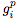 。
。
增加訓練次數的搜索
之前的搜索實驗發現新方程在訓練開始時運行良好,但在收斂時不優于反向傳播。后一種結果可能是由于搜索和測試機制之間的不匹配,因為搜索使用20個epoch來訓練子模型,而測試機制使用100個epoch。
一個后續方案是匹配這兩個機制。在第二次搜索實驗中,使用100個epoch訓練每個子模型。為了補償由于使用較多的epoch進行訓練而導致的實驗時間增加,使用較小的網絡(WRN 10-1)作為子模型。使用較小的模型是可以接受的,因為新方程傾向于推廣到更大,更真實的模型,如(A2)。
實驗結果在表1中的(B1),與(A3)較為相似,即,可以找到對SGD表現較好的更新規則,但是對有動量的SGD的結果與基線相當。(A3)和(B1)結果的相似性表明,訓練時間的差異可能不是誤差的主要來源。此外,具有動量的SGD對于不同的新方程是幾乎不變的。
總結
在這項工作中,提出了一種自動查找可以取代標準反向傳播的方程的方法。使用了一種進化控制器(在方程分量空間中工作),并試圖最大化訓練網絡的泛化。探索性研究的結果表明,對于特定的場景,有一些方程的泛化性能比基線更好,但要找到一個在一般場景中表現更好的方程還需要做更多的工作。
-
谷歌
+關注
關注
27文章
6168瀏覽量
105381 -
人工智能
+關注
關注
1791文章
47279瀏覽量
238497 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
原文標題:谷歌大作:自動改良反向傳播算法,訓練速度再提升!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于路測數據的傳播模型校正方法
一種同步通訊板的網絡電路碼表的生成
一種自動生成循環摘要的方法
一種新的DEA公共權重生成方法
一種支持用戶隱私保護的信息傳播方法

一種全新的遙感圖像描述生成方法

一種基于改進的DCGAN生成SAR圖像的方法

一種免反向傳播的 TTA 語義分割方法
CVPR 2023 中的領域適應: 一種免反向傳播的TTA語義分割方法





 工商網監
工商網監
評論