 如何建立起強大的視覺層次結構,并最終成為強大的圖像特征提取器
如何建立起強大的視覺層次結構,并最終成為強大的圖像特征提取器
近年來,隨著一些強大、通用的深度學習框架相繼出現,把卷積層添加進深度學習模型也成了可能。這個過程很簡單,只需一行代碼就能實現。但是,你真的理解“卷積”是什么嗎?當初學者第一次接觸這個詞時,看到堆疊在一起的卷積、核、通道等術語,他們往往會感到困惑。作為一個概念,“卷積”這個詞本身就是復雜、多層次的。
在這篇文章中,我們將分解卷積操作的機制,逐步將其與標準神經網絡聯系起來,探索它們是如何建立起強大的視覺層次結構,并最終成為強大的圖像特征提取器的。
2D卷積:操作
2D卷積是一個相當簡單的操作:我們先從一個小小的權重矩陣,也就是卷積核(kernel)開始,讓它逐步在二維輸入數據上“掃描”。卷積核“滑動”的同時,計算權重矩陣和掃描所得的數據矩陣的乘積,然后把結果匯總成一個輸出像素。
標準卷積
卷積核會在其經過的所有位置上都重復以上操作,直到把輸入特征矩陣轉換為另一個二維的特征矩陣。簡而言之,輸出的特征基本上就是原輸入特征的加權和(權重是卷積核自帶的值),而從像素位置上看,它們所處的地方大致相同。
那么為什么輸出特征的會落入這個“大致區域”呢?這取決于卷積核的大小。卷積核的大小直接決定了在生成輸出特征時,它合并了多少輸入特征,也就是說:卷積核越小,輸入輸出的位置越接近;卷積核越大,距離就越遠。
這和全連接層很不一樣。在上圖的例子中,我們的輸入有5×5=25個特征,而我們的輸出則是3×3=9個特征。如果這是一個全連接層,輸入25個特征后,我們會輸出包含25×9=225個參數的權重矩陣,每個輸出特征都是每個輸入特征的加權和。
這意味著對于每個輸入特征,卷積執行的操作是使用9個參數進行轉換。它關注的不是每個特征究竟是什么,而是這個大致位置都有什么特征。這一點很重要,理解了它,我們才能進行深入探討。
一些常用的技巧
在我們繼續討論前,我們先來看看卷積神經網絡中經常出現的兩種技巧:Padding和Strides。
Padding
如果你仔細看了上文中的gif,你會發現我們把5×5的特征矩陣轉換成了3×3的特征矩陣,輸入圖像的邊緣被“修剪”掉了,這是因為邊緣上的像素永遠不會位于卷積核中心,而卷積核也沒法擴展到邊緣區域以外。這是不理想的,通常我們都希望輸入和輸出的大小應該保持一致。
padding
Padding就是針對這個問題提出的一個解決方案:它會用額外的“假”像素填充邊緣(值一般為0),這樣,當卷積核掃描輸入數據時,它能延伸到邊緣以外的偽像素,從而使輸出和輸入大小相同。
Stride
如果說Padding的作用是使輸出與輸入同高寬,那么在卷積層中,有時我們會需要一個尺寸小于輸入的輸出。那這該怎么辦呢?這其實是卷積神經網絡中的一種常見應用,當通道數量增加時,我們需要降低特征空間維度。實現這一目標有兩種方法,一是使用池化層,二是使用Stride(步幅)。
步幅
滑動卷積核時,我們會先從輸入的左上角開始,每次往左滑動一列或者往下滑動一行逐一計算輸出,我們將每次滑動的行數和列數稱為Stride,在上節的圖片中,Stride=1;在上圖中,Stride=2。Stride的作用是成倍縮小尺寸,而這個參數的值就是縮小的具體倍數,比如步幅為2,輸出就是輸入的1/2;步幅為3,輸出就是輸入的1/3。以此類推。
在一些目前比較先進的網絡架構中,如ResNet,它們都選擇使用較少的池化層,在有縮小輸出需要時選擇步幅卷積。
多通道卷積
當然,上述例子都只包含一個輸入通道。實際上,大多數輸入圖像都有3個RGB通道,而通道數的增加意味著網絡深度的增加。為了方便理解,我們可以把不同通道看成觀察全圖的不同“視角”,它或許會忽略某些特征,但一定也會強調某些特征。
彩色圖像一般都有紅、綠、藍三個通道
這里就要涉及到“卷積核”和“filter”這兩個術語的區別。在只有一個通道的情況下,“卷積核”就相當于“filter”,這兩個概念是可以互換的;但在一般情況下,它們是兩個完全不同的概念。每個“filter”實際上恰好是“卷積核”的一個集合,在當前層,每個通道都對應一個卷積核,且這個卷積核是獨一無二的。
filter:卷積核的集合
卷積層中的每個filter有且只有一個輸出通道——當filter中的各個卷積核在輸入數據上滑動時,它們會輸出不同的處理結果,其中一些卷積核的權重可能更高,而它相應通道的數據也會被更加重視(例:如果紅色通道的卷積核權重更高,filter就會更關注這個通道的特征差異)。
卷積核處理完數據后,形成了三個版本的處理結果,這時,filter再把它們加在一起形成一個總的通道。所以簡而言之,卷積核處理的是不同通道的不同版本,而filter則是作為一個整體,產生一個整體的輸出。
最后,還有偏置項。我們都知道每個filter輸出后都要加上一個偏置項,那么為什么要放在這個位置呢?如果聯系filter的作用,這一點不難理解,畢竟只有在這里,偏置項才能和filter一起作用,產生最終的輸出通道。
以上是單個filter的情況,但多個filter也是一樣的工作原理:每個filter通過自己的卷積核集處理數據,形成一個單通道輸出,加上偏置項后,我們得到了一個最終的單通道輸出。如果存在多個filter,這時我們可以把這些最終的單通道輸出組合成一個總輸出,它的通道數就等于filter數。這個總輸出經過非線性處理后,繼續被作為輸入饋送進下一個卷積層,然后重復上述過程。
2D卷積:直覺
卷積仍是線性變換
盡管上文已經講解了卷積層的機制,但對比標準的前饋網絡,我們還是很難在它們之間建立起聯系。同樣的,我們也無法解釋為什么卷積可以進行縮放,以及它在圖像數據上的處理效果為什么會那么好。
假設我們有一個4×4的輸入,目標是把它轉換成2×2的輸出。這時,如果我們用的是前饋網絡,我們會把這個4×4的輸入重新轉換成一個長度為16的向量,然后把這16個值輸入一個有4個輸出的密集連接層中。下面是這個層的權重矩陣W:

總而言之,有64個參數
雖然卷積的卷積核操作看起來很奇怪,但它仍然是一個帶有等效變換矩陣的線性變換。如果我們在重構的4×4輸入上使用一個大小為3的卷積核K,那么這個等效矩陣會變成:
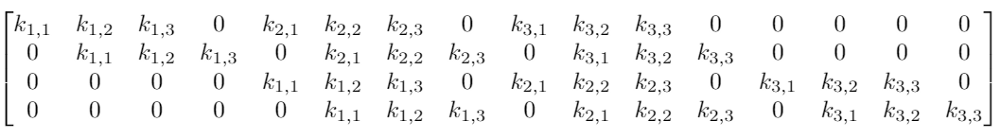
這里真的只有9個參數
注:雖然上面的矩陣是一個等效變換矩陣,但實際操作可能會不太一樣。
可以發現,整個卷積仍然是線性變換,但與此同時,它也是一種截然不同的變換。相比前饋網絡的64個參數,卷積得到的9個參數可以多次重復使用。由于權重矩陣中包含大量0權重,我們只會在每個輸出節點看到選定數量的輸入(卷積核的輸入)。
而更高效的是,卷積的預定義參數可以被視為權重矩陣的先驗。卷積核的大小、filter的數量,這些都是可以預定義的網絡參數。當我們使用預訓練模型進行圖像分類時,我們可以把預先訓練的網絡參數作為當前的網絡參數,并在此基礎上訓練自己的特征提取器。這會大大節省時間。
從這個意義上講,雖然同為線性變換,卷積相比前饋網絡的優勢就可以被解釋了。和隨機初始化不同,使用預訓練的參數允許我們只需要優化最終全連接層的參數,這意味著更好的性能。而大大削減參數數量則意味著更高的效率。
上圖中我們只展示了把64個獨立參數減少到9個共享參數,但在實際操作中,當我們從MNIST選擇784幅224×224×3的圖像時,它會有超過150,000個輸入,也就是超過100億個參數。相比之下,整個ResNet-50只有約2500萬個參數。
因此,將一些參數固定為0可以大大提高效率。那么對比遷移學習,我們是怎么判斷這些先驗會產生積極效果的呢?
答案在于先前引導參數學習的特征組合。
局部性
在文章開頭,我們就討論過這么幾點:
卷積核僅組合局部區域的幾個像素,并形成一個輸出。也就是說,輸出特征只代表這一小塊局部區域的輸入特征。
卷積核會在“掃描”完整張圖像后再生成輸出矩陣。
因此,隨著反向傳播從分類節點開始往前推移,卷積核就可以不斷調整權重,努力從一組本地輸入中提取有效特征。另外,因為卷積核本身應用于整個圖像,所以無論它學習的是哪個區域的特征,這些特征必須足夠通用。
如果這是任何其他類型的數據,比如應用程序的安裝序列號,卷積的這種操作完全不起作用。因為序列號雖然是一系列有順序的數字,但他們彼此間沒有共享的信息,也沒有潛在聯系。但在圖像中,像素總是以一致的順序出現,并且會始終對周圍像素產生影響:如果所有附近的像素都是紅色,那么我們的目標像素就很可能也是紅色的。如果這個像素最終被證明存在偏差,不是紅色的,那這個有趣的點就可能會被轉換為特征。
通過對比像素和臨近像素的差異來學習特征——這實際上是許多早期計算機視覺特征提取方法的基礎。例如,對于邊緣檢測,我們可以使用Sobel edge detection:
用于垂直邊緣檢測的Sobel算子
對于不包含邊緣的網格(如天空),因為大多數像素都是相同的值,所以它的卷積核的總輸出為0。對于具有垂直邊緣的網格,邊緣左側和右側的像素存在差異,所以卷積核的輸出不為零,激活邊緣區域。雖然這個卷積核一次只能掃描3×3的區域,提取其中的特征,但當它掃描完整幅圖像后,它就有能力在圖像中的任何位置檢測全局范圍內的某個特征。
那么深度學習和這種傳統方法的區別是什么?對于圖像數據的早期處理,我們確實可以用低級的特征檢測器來檢測圖中的線條、邊緣,那么,Sobel邊緣算子的作用能否被卷積學習到?
深度學習研究的一個分支是研究神經網絡模型可解釋性,其中最強大的是使用了優化的特征可視化。它的思路很簡單,就是通過優化圖像來盡可能強烈地激活filter。這確實具有直觀意義:如果優化后的圖像完全被邊緣填充,這其實就是filter本身正在尋找激活特征,并讓自己被激活的強有力證據。
GoogLeNet第一個卷積層的3個不同通道的特征可視化,請注意,雖然它們檢測到不同類型的邊緣,但它們仍然是低級邊緣檢測器
GoogLeNet第二個、第三個卷積層的12個通道的特征可視化
這里要注意一點,卷積圖像也是圖像。卷積核是從圖像左上角開始滑動的,相應的,它的輸出仍將位于左上角。所以我們可以在這個卷積層上在做卷積,以提取更深層的特征可視化。
然而,無論我們的特征檢測器如何深入,在沒有任何進一步改變的情況下,它們仍將在非常小的圖像塊上運行。無論檢測器有多深,它的大小就只有3×3,它是不可能檢測到完整的臉部的。這是感受野(Receptive field)的問題。
感受野
無論是什么CNN架構,它們的基本設計就是不斷壓縮圖像的高和寬,同時增加通道數量,也就是深度。如前所述,這可以通過池化和Stride來實現。局部性影響的是臨近層的輸入輸出觀察區域,而感受野決定的則是整個網絡原始輸入的觀察區域。
步幅卷積背后的想法是我們只滑動固定距離的間隔,并跳過中間的網格。
如上圖所示,把stride調整為2后,卷積得到的輸出大大縮小。這時,如果我們在這個輸出的基礎上做非線性激活,然后再上面再加一個卷積層,有趣的事就發生了。相比正常卷積得到的輸出,3×3卷積核在這個步幅卷積輸出上的感受野更大。
這是因為它的原始輸入區域就比正常卷積的輸入區域大,這會對后續特征提取產生影響。
這種感受野的擴大允許卷積層將低級特征(線條、邊緣)組合成更高級別的特征(曲線、紋理),正如我們在mixed3a層中看到的那樣。而隨著我們添加更多Stride層,網絡會顯示出更多高級特征,如mixed4a、mixed5a。
通過檢測低級特征,并使用它們來檢測更高級別的特征,使其在視覺層次結構中向前發展,最終能夠檢測到整個視覺概念,如面部,鳥類,樹木等。這就是卷積在圖像數據上如此強大、高效的一個原因。
結論
現如今,CNN已經允許開發者們從構建簡單的CV應用,到把它用于為復雜產品和服務提供技術動力,它既是照片庫中用于檢測人臉的小工具,也是臨床醫學中幫助醫生篩查癌細胞的貼心助手。它們可能是未來計算機視覺的一個關鍵,當然,一些新的突破也可能即將到來。
但無論如何,有一件事是確定的:CNN是當今許多創新應用的核心,而且它們的效果絕對令人驚嘆,這項技術本身也有掌握、了解的必要。
-
檢測器
+關注
關注
1文章
868瀏覽量
47733 -
神經網絡
+關注
關注
42文章
4777瀏覽量
100961 -
深度學習
+關注
關注
73文章
5510瀏覽量
121345
原文標題:什么是深度學習的卷積?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
使用機器學習改善庫特征提取的質量和運行時間
強大視覺方案:i.MX8MP與AR0144的完美結合

深度識別人臉識別在任務中為什么有很強大的建模能力
在進行開環分析時,Aol(開環增益)曲線與1/β(噪聲增益)曲線的交點頻率如何用等式建立起來?
圖像識別算法的核心技術是什么
圖像識別技術的原理是什么
什么是機器視覺opencv?它有哪些優勢?
卷積神經網絡誤差分析
人工智能神經網絡的一般結構有幾個層次
卷積神經網絡的各個層次及其作用
神經網絡在圖像識別中的應用
基于MATLAB的信號處理系統與分析
如何提取、匹配圖像特征點
視覺檢測設備的分類






 工商網監
工商網監
評論