 如何用深度學習模型,模仿人類的教練過程?
如何用深度學習模型,模仿人類的教練過程?
DeepMind日前公開了他們首款醫療AI落地產品,能診斷50多種眼疾,精度超越人類醫生。為了訓練這個系統,DeepMind 用了近1.5萬個人工標注的數據。盡管這項工作非常了不起,但從更廣闊的視角看,從不會學習的電子計算機,到需要大數據才能“教會”的深度學習,有沒有可能更進一步,實現像人類一樣只需要小數據就能學習的方法?本文作者復星集團AI首席科學家、大數醫達創始人鄧侃博士認為,Deep Coaching 或許是一種可行之道。
DeepMind是Google旗下專注于人工智能研究的公司,DeepMind最出名的成就是AlphaGo系統,它戰勝了當今世界所有圍棋高手。
2018年8月13日,DeepMind一組研究員,在Nature Medicine上發表了一篇論文,題為“Clinically applicabledeep learning for diagnosis and referral in retinal disease”,用深度學習算法,學習視網膜疾病的診斷和轉診,并付諸臨床實踐。
這篇論文的內容,媒體上已經有不少報導,似乎沒有必要進一步讀解。但是我們不妨退后幾步,用更廣闊的視角,審視從電子計算機到智能機器的演進。我們已經實現了哪些成就,目前主要的障礙有哪些,并探討如何解決這些問題。
三位大師成就電子計算機,但只能服從指令不會學習
說到電子計算機,就必須仰望三位大師:圖靈、馮·諾依曼、香農。
電子計算機與傳統機器的本質區別是,計算機把指令與操作分離,機器預先不知道要進行哪些操作,根據實時下達的指令完成操作。而且,計算機還可以把一系列指令,編制成程序,動態地生成指令,讓機器完成更復雜的復合操作。
計算機的原理,由圖靈首創。用電子器件完成計算機的工程實現,由馮·諾依曼首創。而數碼信息的通訊,包括編碼解碼和傳輸通道,由香農首創。
但是,電子計算機只是機械地執行程序賦予的指令,并不會像人類那樣思考,尤其是不會像人類那樣學習。
神經網絡會“學習”,但需要大數據,與人腦思考方式不符
那什么是“學習”?
有一種觀點認為,學習=函數擬合。如果把函數表達為y = f(x),又有一大堆訓練數據,也就是一大堆 (x,y)數組,那么學習過程,就是從訓練數據中,得出對原函數的近似模擬
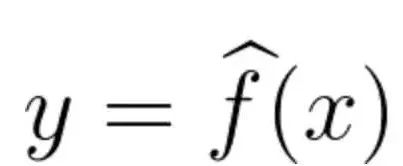
。
1940年代,科學家們模仿神經元的解剖學構造,發明了一種數據結構——神經元perceptron。科學家們發現,把多個神經元組合在一起,構成神經網絡,神經網絡能夠表達幾乎任何函數。換而言之,神經網絡是通用的函數,學習的過程,等同于猜測神經網絡的參數。海量訓練數據的用途,在于不斷地優化對神經網絡參數的猜測,使神經網絡能夠更好地模擬目標函數。
“學習”等于猜測神經網絡的參數,大數據用于不斷優化對參數的猜測
但是,要表達復雜函數,需要規模龐大的神經網絡,神經網絡包括上百層神經元,每層包含幾千個神經元。Geoffrey Hinton教授,給這種超大規模的神經網絡取了一個名字——深度神經網絡。
深度學習(Deep Learning)也是由此而來。
深度學習是一種通用的方法,能夠應用在很多領域,尤其在圖像識別、語音識別、自然語言處理三大領域的應用,與傳統方法相比較,深度學習取得了突破性的進展。
但是,深度學習經常遭人詬病的弱點有三:
1.需要大量訓練數據。譬如DeepMind昨天發表的論文中提到,他們用14,884個經過人工標注的訓練數據(醫學圖像),學習50 多種視網膜疾病的診斷。人工標注14,884張醫學圖像,工作量不小。但對于深度學習來說,經常需要百萬級訓練數據。從百萬數量級,降低到14,884張標注圖片,已經是很了不起的進步了。
2.黑盒子。神經網絡的內部參數,沒有明確的物理意義,無法用人類聽得懂的語言,解釋深度學習的結果。
3.沒有仿生學基礎。人類不需要幾萬張圖片的訓練,就能學習掌握讀片的訣竅。很顯然,人類大腦的學習過程,與深度學習并不相符。
DeepMind的方法:分兩步降低數據量,符合人類醫生診斷習慣
DeepMind的改進方法,是把讀片分成兩步:第一步從原始圖像中,提取病灶特征,類似于人類醫生讀片報告中“檢查所見”的段落內容;第二步根據檢查所見的病灶特征,用分類的辦法,診斷出罹患的疾病,類似于人類醫生撰寫的讀片報告中“檢查結論”的段落內容。
把讀片分成兩步,好處有三,
1.把一大步分解為兩小步,每一小步的復雜度降低,導致神經模型的規模降低,導致訓練神經模型所需的訓練數據的數量降低。
論文自豪地聲稱,他們只用了14,884個經過人工標注的訓練數據,就訓練出了圖像識別系統,其精度媲美人類醫生對視網膜疾病的診斷精度。
不同設備拍攝出的圖像效果不同,因此每一種設備,最好都配有自己專用的深度學習模型(也即N種設備有N個模型)。但是,這些模型的輸出,卻都是標準化的“檢查所見”的病灶特征。從標準化的病灶特征,到“檢查結論”的疾病診斷,只需要一個模型(因此,總共需要N+1個模型)。
雖然不同設備的專屬模型,理論上各不相同。但是在生成新設備的專屬模型時,可以在已經生成了的其它設備的專屬模型的基礎上,做進一步調優。調優需要的訓練數據,數量大大降低。
2.通過分析診斷模型的參數,可以窺探到哪些輸入的病灶特征,對診斷結果的影響更大。也就是說,可以基于從輸入到輸出的敏感性分析,來解釋深度學習模型的內在邏輯。
3.把讀片的過程,從一個大步,分解為兩個小步(檢查所見與檢查結論),符合人類醫生讀片的習慣。
遺留的問題,是如何進一步降低對訓練數據(人工標注過的醫學圖片)的數量要求,尤其是第一步,從不同設備拍攝的照片中,提取病灶特征。
深度教練:讓深度學習模仿人類教學過程,大幅減少訓練數據
假如我們把深度學習(Deep Learning),改進為深度教練(Deep Coaching),或許可以大幅度降低對訓練數據的數量要求。
深度教練(Deep Coaching)模仿人類老師指導人類學生的過程。
人類老師指著一張醫學圖片說:“看這里,這里是某種病灶。注意,某種病灶的形狀和紋理,具有這些特點。”
學生指著圖片中另一個區域說:“老師,這里也是病灶嗎?”
老師說:“不是的,因為病灶的面積太小。”
學生又指著圖片中第三個區域說:“老師,這里應該是病灶了吧?”
。。。
如何用深度學習模型,模仿人類的教練過程?需要解決以下幾個問題:
1.如何識別形狀、紋理和大小?
形狀、紋理、大小,是圖像識別中的通用特征,有大量已經被人工標注過了的圖片,可以用于模型的訓練。問題在于如何窺探深度學習模型中哪一層的哪些神經元,分別代表形狀、紋理和大小。這個問題,有多種解決方案,譬如dropout等等。
2.如何讓深度學習模型,理解“看這里,這里是某種病灶。注意,某種病灶的形狀和紋理,具有這些特點”。
沿用CNN的辦法,把整個圖像分割成若干小區域。然后對深度學習模型進行調參,盡可能放大病灶區域,與其它區域的差別,假設其它區域是無病灶區域。如果老師明確說,形狀和紋理是關鍵特征,那么對于深度學習模型而言,等同于先驗地放大相關參數的初始設置。
3.如何讓深度學習模型模仿學生,指著圖片中另一個區域說:“老師,這里也是病灶嗎?”
用第二步訓練出來的模型,掃描整個圖像,標記出其它疑似病灶區域。
4.如何讓深度學習模型理解老師的糾正,“不是的,因為病灶的面積太小。”
等同于對深度學習模型進行調參,尤其是與病灶面積相關的參數,使得模型的輸出正確。
。。。
完成深度教練的全部過程,應該最多只需要幾十個回合。所需的訓練數據,也就是標注過的圖片,估計不超過十張。而且每張標注的圖片,不需要把所有病灶都標注出來。
深度學習vs深度教練的比較研究,似乎值得探討。
有志者,不妨來合作。
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100966 -
大數據
+關注
關注
64文章
8900瀏覽量
137591 -
深度學習
+關注
關注
73文章
5510瀏覽量
121349
原文標題:深度教練:讓深度學習模擬人類教學過程,大幅減少訓練數據和時間!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習中過擬合/欠擬合的問題及解決方案
labview調用深度學習tensorflow模型非常簡單,附上源碼和模型
深度學習模型優于人類醫生?

模型化深度強化學習應用研究綜述






 工商網監
工商網監
評論