") 上海交大提出切片循環(huán)神經(jīng)網(wǎng)絡(luò),其速度是標(biāo)準(zhǔn)RNN的136倍
上海交大提出切片循環(huán)神經(jīng)網(wǎng)絡(luò),其速度是標(biāo)準(zhǔn)RNN的136倍
上海交通大學(xué)最新提出切片循環(huán)神經(jīng)網(wǎng)絡(luò)(SRNN),其速度是標(biāo)準(zhǔn)RNN的136倍,并且還能更快!對(duì)六個(gè)大型情緒分析數(shù)據(jù)集的實(shí)驗(yàn)表明,SRNN的性能均優(yōu)于標(biāo)準(zhǔn)RNN。
在許多NLP任務(wù)中,循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)取得了巨大的成功。但是,這種循環(huán)的結(jié)構(gòu)使它們難以并行化,因此,訓(xùn)練RNN需要大量的時(shí)間。
上海交通大學(xué)的Zeping Yu和Gongshen Liu,在論文“Sliced Recurrent Neural Networks”中,提出了全新架構(gòu)“切片循環(huán)神經(jīng)網(wǎng)絡(luò)”(SRNN)。SRNN可以通過將序列分割成多個(gè)子序列來實(shí)現(xiàn)并行化。SRNN能通過多個(gè)層獲得高級(jí)信息,而不需要額外的參數(shù)。
研究人員證明了當(dāng)使用線性激活函數(shù)時(shí),標(biāo)準(zhǔn)RNN是SRNN的一個(gè)特例。在不改變循環(huán)單元的情況下,SRNN的速度是標(biāo)準(zhǔn)RNN的136倍,并且當(dāng)訓(xùn)練更長的序列時(shí)可能會(huì)更快。對(duì)六個(gè)大型情緒分析數(shù)據(jù)集的實(shí)驗(yàn)表明,SRNN的性能優(yōu)于標(biāo)準(zhǔn)RNN。
提高RNN訓(xùn)練速度的多種方法
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)已經(jīng)被廣泛用于許多NLP任務(wù),包括機(jī)器翻譯、問題回答、圖像說明和文本分類。RNN能夠獲得輸入序列的順序信息。最受歡迎的兩個(gè)循環(huán)單元是長短期記憶(LSTM)和門控循環(huán)單元(GRU),兩者都可以將先前的記憶存儲(chǔ)在隱藏狀態(tài),并使用門控機(jī)制來確定應(yīng)該在何種程度將先前的記憶應(yīng)與當(dāng)前的輸入結(jié)合。但是,由于其循環(huán)的結(jié)構(gòu),RNN不能并行計(jì)算。因此,訓(xùn)練RNN需要花費(fèi)大量時(shí)間,這限制了學(xué)術(shù)研究和工業(yè)應(yīng)用。
為了解決這個(gè)問題,一些學(xué)者嘗試在NLP領(lǐng)域使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)來代替RNN。但是,CNN無法獲得序列的順序信息,而順序信息在NLP任務(wù)中非常重要。
一些學(xué)者試圖通過改進(jìn)循環(huán)單元來提高RNN的速度,并取得了良好的效果。通過將CNN與RNN相結(jié)合,準(zhǔn)循環(huán)神經(jīng)網(wǎng)絡(luò)(QRNN)的速度提高了16倍。2017年Tao Lei等人提出了簡(jiǎn)單循環(huán)單元SRU(simple recurrent unit),比LSTM快5-10倍。類似地, strongly-typed循環(huán)神經(jīng)網(wǎng)絡(luò)(T-RNN)和最小門控單元(MGU)也是可以改進(jìn)循環(huán)單元的方法。
雖然RNN在這些研究中實(shí)現(xiàn)了更快的速度,并且循環(huán)單元得到了改善,但整個(gè)序列中的循環(huán)結(jié)構(gòu)是保持不變的。我們?nèi)匀恍枰却弦徊降妮敵觯虼薘NN的瓶頸仍然存在。在本文中,我們提出切片循環(huán)神經(jīng)網(wǎng)絡(luò)(SRNN),它在不改變循環(huán)單元的情況下,能夠比標(biāo)準(zhǔn)RNN快得多。我們證明了當(dāng)使用線性激活函數(shù)時(shí),標(biāo)準(zhǔn)RNN是SRNN的一個(gè)特例,SRNN能夠獲得序列的高級(jí)信息。
為了將我們的模型與標(biāo)準(zhǔn)RNN進(jìn)行比較,我們選擇GRU作為循環(huán)單元。其他的循環(huán)單元也可以用于我們的結(jié)構(gòu),因?yàn)槲覀兏倪M(jìn)了整個(gè)序列中的整體RNN結(jié)構(gòu),而不僅僅是改變循環(huán)單元。我們?cè)?個(gè)大型數(shù)據(jù)集上完成了實(shí)驗(yàn),證明SRNN在所有數(shù)據(jù)集上的性能優(yōu)于標(biāo)準(zhǔn)RNN。
我們開源了實(shí)現(xiàn)代碼:
https://github.com/zepingyu0512/srnn
切片循環(huán)神經(jīng)網(wǎng)絡(luò)SRNN的結(jié)構(gòu)
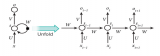
我們構(gòu)建了一個(gè)新的RNN結(jié)構(gòu),稱為切片循環(huán)神經(jīng)網(wǎng)絡(luò)(SRNN),如圖2所示。在圖2中,循環(huán)單位也稱為A。
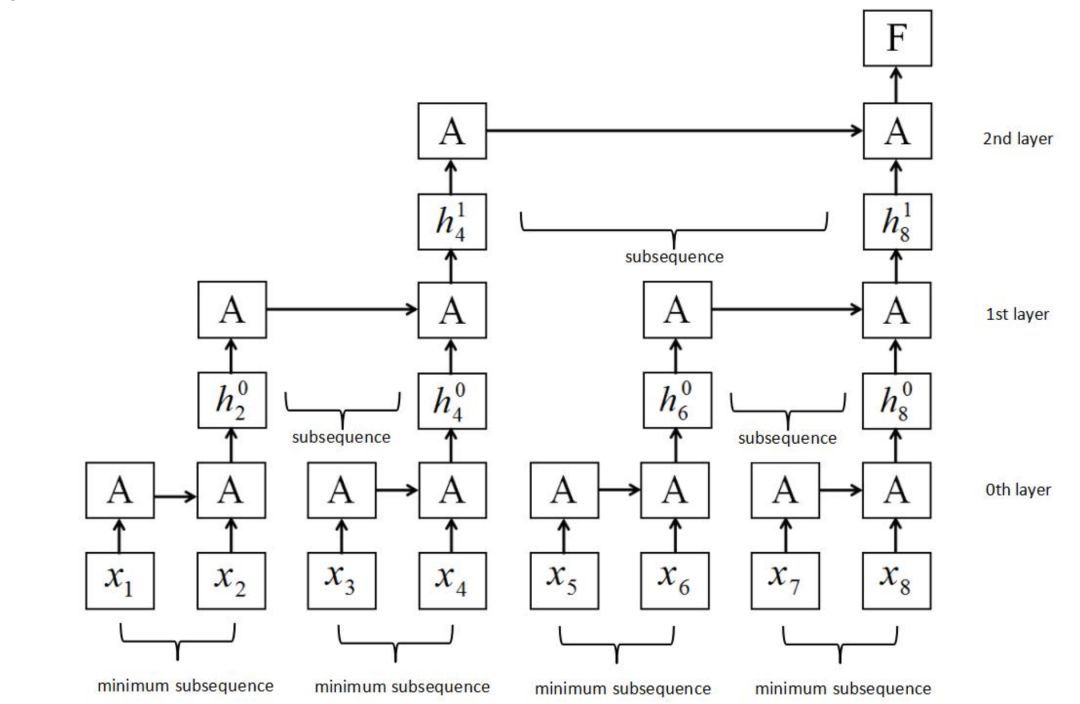
圖2:SRNN結(jié)構(gòu)。它是通過將輸入序列分割成幾個(gè)長度相等的最小子序列來構(gòu)造的。循環(huán)單元可以在每層子序列上同時(shí)工作,信息可以通過多層傳遞。
輸入序列X的長度為T,輸入序列為:
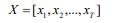
其中x是每個(gè)步驟的輸入,它可能具有多個(gè)維度,例如單詞嵌入。然后將X分割成長度相等的n個(gè)子序列,每個(gè)子序列的長度n為:
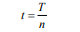
其中n為切片數(shù),序列X可表示為:
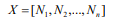
其中每個(gè)子序列是:
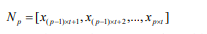
類似地,我們將每個(gè)子序列N再次切割成相等長度的n個(gè)子序列,然后重復(fù)該切片操作k次,直到我們?cè)诘讓佑幸粋€(gè)適當(dāng)?shù)淖钚∽有蛄虚L度(我們稱之為第0層,如圖2所示), 通過切片k次獲得k + 1層。 第0層的最小子序列長度為:
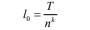
第0層的最小子序列數(shù)為:
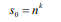
因?yàn)榈趐層(p> 0)上的每個(gè)父序列被切成n個(gè)部分,所以第p層上的子序列的數(shù)量是:
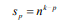
并且第p層的子序列長度為:
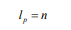
以圖2為例。 序列長度T為8,切片操作次數(shù)k為2,每個(gè)第p層的切片編號(hào)n為2。將序列切片兩次后,在第0層得到4個(gè)最小子序列,每個(gè)最小子序列的長度為 2。如果序列的長度或其子序列的長度不能除以n,我們可以利用填充法或在每一層上選擇不同的切片編號(hào)。 不同的k和n可以用于不同的任務(wù)和數(shù)據(jù)集。
SRNN和標(biāo)準(zhǔn)RNN之間的區(qū)別在于SRNN將輸入序列切分為許多最小子序列,并利用每個(gè)子序列上的循環(huán)單元。通過這種方式,子序列可以很容易地并行化。在第0層,循環(huán)單元通過連接結(jié)構(gòu)對(duì)每個(gè)最小子序列起作用。 接下來,我們獲得第0層上每個(gè)最小子序列的最后隱藏狀態(tài),這些狀態(tài)在第1層用作其父序列的輸入。 然后我們使用第(p-1)層上每個(gè)子序列的最后隱藏狀態(tài)作為其第p層上的父序列的輸入,并計(jì)算第p層上子序列的最后隱藏狀態(tài):
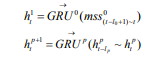
其中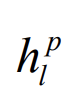 為第p層上的數(shù)l隱藏狀態(tài),mss為第0層上的最小子序列,不同層上可以使用不同的GRU。在每層上的每個(gè)子父序列之間重復(fù)該操作,直到我們得到頂層(第k層)的最終隱藏狀態(tài)F:
為第p層上的數(shù)l隱藏狀態(tài),mss為第0層上的最小子序列,不同層上可以使用不同的GRU。在每層上的每個(gè)子父序列之間重復(fù)該操作,直到我們得到頂層(第k層)的最終隱藏狀態(tài)F:
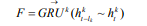
實(shí)驗(yàn):序列長度越長,SRNN處理的速度優(yōu)勢(shì)就越大
數(shù)據(jù)集
我們?cè)诹鶄€(gè)大規(guī)模情緒分析數(shù)據(jù)集上評(píng)估SRNN。表1列出了數(shù)據(jù)集的信息。我們選擇80%的數(shù)據(jù)用于訓(xùn)練,10%用于驗(yàn)證,10%用于測(cè)試。
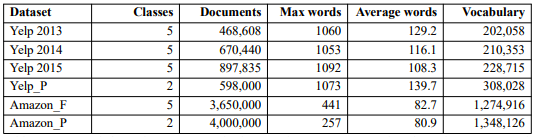
表1:數(shù)據(jù)集信息。Max words表示最大序列長度,Average words表示每個(gè)數(shù)據(jù)集中句子的平均長度。
結(jié)果和分析
每個(gè)數(shù)據(jù)集的結(jié)果如表2所示。我們選擇不同的n和k值,得到不同的SRNN。例如,SRNN(16,1)表示n = 16且k = 1,當(dāng)T為512時(shí),可以得到長度為32的最小子序列;當(dāng)T為256時(shí),可以得到長度為16的最小子序列。我們將4個(gè)SRNN與標(biāo)準(zhǔn)RNN進(jìn)行了比較。每個(gè)數(shù)據(jù)集中,粗體字表示性能最高的模型和速度最快的模型。
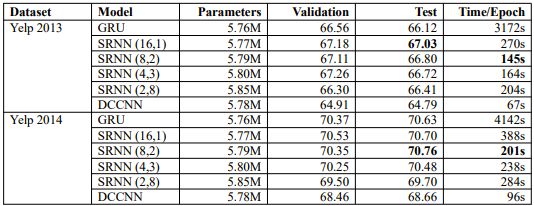
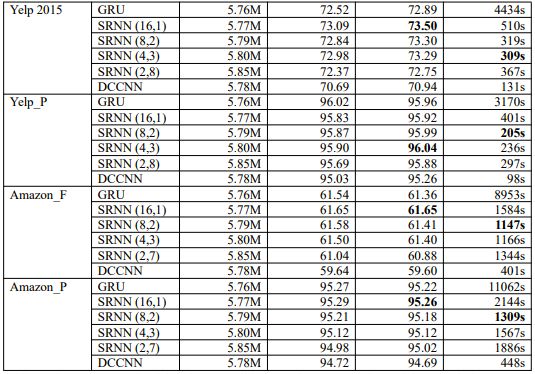
表2:每個(gè)數(shù)據(jù)集上模型驗(yàn)證和測(cè)試的準(zhǔn)確度和訓(xùn)練時(shí)間。我們構(gòu)建了四種不同的SRNN結(jié)構(gòu)。DCCNN是dilated casual卷積神經(jīng)網(wǎng)絡(luò)。
結(jié)果表明,在幾乎沒有額外參數(shù)的條件下,SRNN在所有數(shù)據(jù)集上的性能和速度都優(yōu)于標(biāo)準(zhǔn)RNN。不同的SRNN在不同的數(shù)據(jù)集上都實(shí)現(xiàn)了最佳性能:
SRNN(16,1)在Yelp 2013,Yelp 2015,Amazon_F和Amazon_P上都獲得最高的準(zhǔn)確度;
SRNN(8,2)在Yelp 2014上的性能最佳;
SRNN(4,3)在Yelp_P上表現(xiàn)最好。
K大于1時(shí),SRNN在Yelp數(shù)據(jù)集上比標(biāo)準(zhǔn)RNN快了將近15倍,可見速度的優(yōu)勢(shì)取決于k,n和T。
SRNN(4,3)在Yelp 2015上速度最快, 而SRNN(8,2)在其余數(shù)據(jù)集最快(DCCNN除外)。
我們注意到,Yelp數(shù)據(jù)集上的SRNN(2,8)和Amazon數(shù)據(jù)集上的SRNN(2,7)沒有達(dá)到最佳性能,但也沒有在準(zhǔn)確性方面減弱太多。這意味著SRNN能夠通過多個(gè)層傳輸信息,因此,當(dāng)我們訓(xùn)練非常長的序列時(shí),SRNN可以獲得顯著的效果。當(dāng)n為2時(shí),SRNN具有與DCCNN相同的層數(shù),并且SRNN的精度比DCCNN高得多。因此,這表明SRNN中的循環(huán)結(jié)構(gòu)優(yōu)于dilated casual卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
我們使用NVIDIA GTX 1080 GPU在5120個(gè)文檔上訓(xùn)練模型,因?yàn)槿绻褂酶嗟臄?shù)據(jù),訓(xùn)練標(biāo)準(zhǔn)RNN需要花費(fèi)太多時(shí)間。訓(xùn)練時(shí)間如表3所示。
從表3中得到驚人的結(jié)果:序列長度越長,SRNN實(shí)現(xiàn)的速度優(yōu)勢(shì)就越大。當(dāng)序列長度為32768時(shí),SRNN僅需52s,而標(biāo)準(zhǔn)RNN需要花費(fèi)近2小時(shí)。SRNN的速度是標(biāo)準(zhǔn)RNN的136倍!并且如果使用更長的序列,速度優(yōu)勢(shì)可能更大。因此,SRNN可以在長序列任務(wù)上實(shí)現(xiàn)更快的速度,例如語音識(shí)別、字符級(jí)文本分類和語言建模。
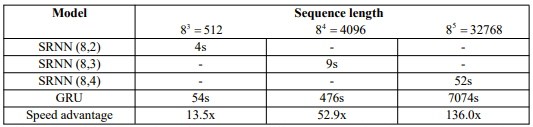
表3:不同序列長度的訓(xùn)練時(shí)間和速度優(yōu)勢(shì)。對(duì)于每個(gè)序列長度,我們選擇不同的SRNN結(jié)構(gòu)。
SRNN的優(yōu)勢(shì)和重要意義
在這一部分,我們將討論SRNN的優(yōu)勢(shì)和重要意義。隨著RNN在許多NLP任務(wù)中取得成功,許多學(xué)者提出了不同的結(jié)構(gòu)來提高RNN的速度。通過改善循環(huán)單元,很多研究都能加快RNN的速度。但是,RNN的傳統(tǒng)連接結(jié)構(gòu)幾乎沒有被質(zhì)疑過,而這種結(jié)構(gòu)里每個(gè)步驟都與它的前一步驟相關(guān)聯(lián)。正是這種連接結(jié)構(gòu)限制了RNN的速度。SRNN改進(jìn)了傳統(tǒng)的連接方法。我們構(gòu)建了一種切片結(jié)構(gòu)(sliced structure)來實(shí)現(xiàn)RNN的并行化。在六個(gè)大規(guī)模情感分析數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果表明,SRNN比標(biāo)準(zhǔn)RNN具有更好的性能。原因如下:
(1)當(dāng)使用標(biāo)準(zhǔn)RNN連接結(jié)構(gòu)時(shí),具門控結(jié)構(gòu)的循環(huán)單元(例如GRU和LSTM)是有用的,但是當(dāng)序列很長時(shí),它們就無法存儲(chǔ)所有的重要信息。SRNN可以將長序列分成許多短的子序列,并用短序列來獲取重要信息。SRNN能夠通過從第0層到頂層的多層結(jié)構(gòu)傳輸重要信息。
(2)SRNN能夠從序列中獲取高級(jí)信息,而不僅僅是單詞級(jí)信息。我們?cè)?12個(gè)單詞的文本中使用SRNN(8,2)時(shí),第0層可以從單詞嵌入中獲得句子級(jí)信息,第1層可以從句子級(jí)信息中獲得段落級(jí)信息,第2層可以生成段落級(jí)信息的最終文檔級(jí)表示。而標(biāo)準(zhǔn)RNN只能獲得詞匯級(jí)信息。雖然不可能每個(gè)文檔有8個(gè)段落,每個(gè)段落有8個(gè)句子,每個(gè)句子有8個(gè)單詞,但是總體的順序信息和結(jié)構(gòu)信息是統(tǒng)一的。以段落信息為例,人們總是在文章的開頭或結(jié)尾表達(dá)自己的觀點(diǎn),并在文章中間舉例說明。與標(biāo)準(zhǔn)RNN相比,SRNN更容易在頂層獲得這些信息。
(3)在處理序列方面,SRNN類似于人腦的機(jī)制。例如,我們作為人類在得到一篇文章,并被要求回答一些問題時(shí),我們通常不需要深入閱讀整篇文章。我們會(huì)試圖找到提及具體信息的段落,然后在段落中找到可以回答問題的句子和單詞。SRNN可以通過多個(gè)層輕松做到這一點(diǎn)。
除了提高準(zhǔn)確性之外,SRNN的最大優(yōu)勢(shì)是可以并行計(jì)算,實(shí)現(xiàn)更快的速度。我們?cè)诓煌蛄虚L度的實(shí)驗(yàn)表明SRNN的運(yùn)行速度比標(biāo)準(zhǔn)RNN快得多。而且,在更長的序列上,SRNN可能更快。隨著互聯(lián)網(wǎng)的發(fā)展,每天都有數(shù)以億計(jì)的數(shù)據(jù)產(chǎn)生,SRNN可以作為處理這些數(shù)據(jù)的新方法。
結(jié)論和未來工作
在這篇論文中,我們提出切片循環(huán)神經(jīng)網(wǎng)絡(luò)(SRNN),這是RNN的整體結(jié)構(gòu)改進(jìn)。 SRNN可以達(dá)到比標(biāo)準(zhǔn)RNN快得多的速度,并在六個(gè)大規(guī)模情感數(shù)據(jù)集上實(shí)現(xiàn)更好的性能。
SRNN在文本分類方面取得了成功。在未來的工作中,我們希望將其推廣到其他NLP應(yīng)用,例如問答、文本摘要和機(jī)器翻譯。在序列到序列模型中,SRNN可以用作編碼器,并且可以通過使用反向SRNN結(jié)構(gòu)來改進(jìn)解碼器。此外,我們希望在一些長序列任務(wù)中使用SRNN,例如語言模型、音樂生成和音頻生成。我們想探索更多SRNN的變體,例如,可以添加雙向結(jié)構(gòu)和注意力機(jī)制。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100899 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4338瀏覽量
62751 -
rnn
+關(guān)注
關(guān)注
0文章
89瀏覽量
6895
原文標(biāo)題:比RNN快136倍!上交大提出SRNN,現(xiàn)在RNN也能做并行計(jì)算了
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是RNN (循環(huán)神經(jīng)網(wǎng)絡(luò))?
遞歸神經(jīng)網(wǎng)絡(luò)(RNN)
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的詳細(xì)介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論