 面向NLP任務的遷移學習新模型ULMFit
面向NLP任務的遷移學習新模型ULMFit
本文介紹了面向NLP任務的遷移學習新模型ULMFit,只需使用極少量的標記數據,文本分類精度就能和數千倍的標記數據訓練量達到同等水平。在數據標記成本高數量少的情況下,這個通用語言微調模型可以大幅降低你的NLP任務訓練時間和成本。
在本文中,我們將介紹自然語言處理(NLP)在遷移學習上的最新應用趨勢,并嘗試執行一個分類任務:使用一個數據集,其內容是亞馬遜網站上的購物評價,已按正面或負面評價分類。然后在你可以按照這里的說明,用你自己的數據重新進行實驗。
遷移學習模型的思路是這樣的:既然中間層可以用來學習圖像的一般知識,我們可以將其作為一個大的特征化工具使用。下載一個預先訓練好的模型(模型已針對ImageNet任務訓練了數周時間),刪除網絡的最后一層(完全連接層),添加我們選擇的分類器,執行適合我們的任務(如果任務是對貓和狗進行分類,就選擇二元分類器),最后僅對我們的分類層進行訓練。
由于我們使用的數據可能與之前訓練過的模型數據不同,我們也可以對上面的步驟進行微調,以在相當短的時間內對所有的層進行訓練。
除了能夠更快地進行訓練之外,遷移學習也是特別有趣的,僅在最后一層進行訓練,讓我們可以僅僅使用較少的標記數據,而對整個模型進行端對端訓練則需要龐大的數據集。標記數據的成本很高,在無需大型數據集的情況下建立高質量的模型是很可取的方法。
遷移學習NLP的尷尬
目前,深度學習在自然語言處理上的應用并沒有計算機視覺領域那么成熟。在計算機視覺領域中,我們可以想象機器能夠學習識別邊緣、圓形、正方形等,然后利用這些知識去做其他事情,但這個過程對于文本數據而言并不簡單。
最初在NLP任務中嘗試遷移學習的趨勢是由“嵌入模型”一詞帶來的。
實驗證明,事先將預先訓練好的詞向量加入模型,可以在大多數NLP任務中改進結果,因此已經被NLP社區廣泛采用,并由此繼續尋找質量更高的詞/字符/文檔表示。與計算機視覺領域一樣,預訓練的詞向量可以被視為特征化函數,轉換一組特征中的每個單詞。
不過,詞嵌入僅代表大多數NLP模型的第一層。之后,我們仍然需要從頭開始訓練所有RNN / CNN /自定義層。
高階方法:微調語言模型,在上面加一層分類器
今年早些時候,Howard和Ruder提出了ULMFit模型作為在NLP遷移學習中使用的更高級的方法(論文地址:https://arxiv.org/pdf/1801.06146.pdf)。
他們的想法是基于語言模型(Language Model)。語言模型是一種能夠根據已經看到的單詞預測下一個單詞的模型(比如你的智能手機在你發短信時,可以為你猜測下一個單詞)。就像圖像分類器通過對圖像分類來獲得圖像的內在知識一樣,如果NLP模型能夠準確地預測下一個單詞,似乎就可以說它已經學會了很多關于自然語言結構的知識。這些知識可以提供高質量的初始化狀態,然后針對自定義任務進行訓練。
ULMFit模型一般用于非常大的文本語料庫(如維基百科)上訓練語言模型,并將其作為構建任何分類器的基礎架構。由于你的文本數據可能與維基百科的編寫方式不同,因此你可以對語言模型的參數進行微調。然后在此語言模型的頂部添加分類器層,僅僅對此層進行訓練。
Howard和Ruder建議向下逐層“解凍”,逐步對每一層進行訓練。他們還在之前關于學習速度(周期性學習)的研究成果基礎上,提出了他們自己的三角學習速率(triangular learning rates)。
用100個標記數據,達到用20000個標記數據從頭訓練的結果
這篇文章得出的神奇結論是,使用這種預訓練的語言模型,讓我們能夠在使用更少的標記數據的情況下訓練分類器。盡管網絡上未標記的數據幾乎是無窮無盡的,但標記數據的成本很高,而且非常耗時。
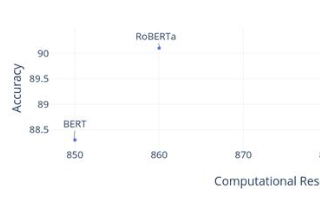
下圖是他們從IMDb情感分析任務中報告的結果:
該模型只用了100個示例進行訓練,錯誤率與20000個示例從頭到尾進行完全訓練的模型相仿。
此外,他們在文中還提供了代碼,讀者可以自選語種,對語言模型進行預訓練。由于維基百科上的語言多種多樣,因此我們可以使用維基百科數據快速完成語種的轉換。眾所周知,公共標簽數據集更難以使用英語以外的語言進行訪問。在這里,你可以對未標記數據上的語言模型進行微調,花幾個小時對幾百個至幾千個數據點進行手動標注,并使分類器頭適應您預先訓練的語言模型,完成自己的定制化任務。
為了加深對這種方法的理解,我們在公共數據集上進行了嘗試。我們在Kaggle上找了一個數據集。它包含400萬條關于亞馬遜產品的評論,并按積極/消極情緒(即好評和差評)加上了標記。我們用ULMfit模型對這些評論按好評/差評進行分類。結果發現,該模型用了1000個示例,其分類準確度已經達到了在完整數據集上從頭開始訓練的FastText模型的水平。甚至在僅僅使用100個標記示例的情況下,該模型仍然能夠獲得良好的性能。
所以,語言模型了解的是語法還是語義?
我們使用ULMFit模型進行了監督式和無監督式學習。訓練無監督的語言模型的成本很低,因為您可以在線訪問幾乎無限數量的文本數據。但是,使用監督模型就很昂貴了,因為需要對數據進行標記。
雖然語言模型能夠從自然語言的結構中捕獲大量相關信息,但尚不清楚它是否能夠捕捉到文本的含義,也就是“發送者打算傳達的信息或概念”或能否實現“與信息接收者的交流”。
我們可以這樣認為,語言模型學到的更多是語法而不是語義。然而,語言模型比僅僅預測語法的模型表現更好。比如,“I eat this computer“(我吃這臺電腦)和“I hate this computer”(我討厭這臺電腦),兩句話在語法上都是正確的,但表現更優秀的語言模型應該能夠明白,第二句話比第一句話更加“正確”。語言模型超越了簡單的語法/結構理解。因此,我們可以將語言模型視為對自然語言句子結構的學習,幫助我們理解句子的意義。
由于篇幅所限,這里就不展開探討語義的概念(盡管這是一個無窮無盡且引人入勝的話題)。如果你有興趣,我們建議你觀看Yejin Choi在ACL 2018上的演講,深入探討這一主題。
微調遷移學習語言模型,大有前景
ULMFit模型取得的進展推動了面向自然語言處理的遷移學習研究。對于NLP任務來說,這是一個激動人心的事情,其他微調語言模型也開始出現,尤其是微調遷移語言模型(FineTuneTransformer LM)。
我們還注意到,隨著更優秀的語言模型的出現,我們甚至可以完善這種知識遷移。高效的NLP框架對于解決遷移學習的問題是非常有前景的,尤其是對一些常見子詞結構的語言,比如德語,經過詞級訓練的語言模型的表現前景非常好。
怎么樣?趕緊試試吧~
-
數據集
+關注
關注
4文章
1208瀏覽量
24703 -
nlp
+關注
關注
1文章
488瀏覽量
22038 -
遷移學習
+關注
關注
0文章
74瀏覽量
5562
原文標題:只有100個標記數據,如何精確分類400萬用戶評論?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
介紹用遷移學習處理NLP任務的大致思路
NLP多任務學習案例分享:一種層次增長的神經網絡結構
一個深度學習模型能完成幾項NLP任務?

8個免費學習NLP的在線資源
NLP遷移學習面臨的問題和解決
如何利用機器學習思想,更好地去解決NLP分類任務

基于遷移學習的駕駛分心行為識別模型






 工商網監
工商網監
評論