 淺析生成式對抗網絡發展的內在邏輯
淺析生成式對抗網絡發展的內在邏輯
生成式對抗網絡(Generative adversarial networks, GAN)是當前人工智能學界最為重要的研究熱點之一。其突出的生成能力不僅可用于生成各類圖像和自然語言數據,還啟發和推動了各類半監督學習和無監督學習任務的發展。
本文概括了GAN的基本思想,并對近年來相關的理論與應用研究進行了梳理,總結了GAN常見的網絡結構與訓練方法,博弈形式,集成方法,并對一些應用場景進行了介紹。在此基礎上,本文對GAN發展的內在邏輯進行了歸納總結。
近年來,人工智能領域,特別是機器學習方面的研究取得了長足的進步。得益于計算能力的提高,信息化工具的普及以及數據量的積累,人工智能研究的迫切性和可行性都大為提高。以Google等為代表的IT企業,利用其掌握的海量數據資源,結合新的硬件結構和人工智能算法,實現了一系列新突破和新應用,并獲得了可觀的收益。這些企業獲得的成功進一步帶動了機器學習的研究熱度,使得人工智能的研究進入了一個新的高潮時期。
在此次的人工智能浪潮中,以統計機器學習,深度學習為代表的機器學習方法是主要的研究方向之一。相比符號主義的研究方法,基于機器學習的人工智能系統降低了對人類知識的依賴,轉而使用統計的方法從數據中直接習得知識。機器學習理論是一次重要的范式革命,使人工智能領域的研究重點從算法設計轉向了特征工程與優化方法。
一般而言,依據數據集是否有標記,機器學習任務可被分為有監督學習(又稱預測性學習,數據集有標記)與無監督學習(又稱描述性學習,數據集無標記)[1]。隨著數據收集手段,算力與算法的不斷發展,在諸多監督學習任務中,如圖像識別[2-3],語音識別[4-5],機器翻譯[6-7]等,機器學習方法,特別是深度學習方法都取得了目前最好的成績。
然而,有監督學習需要人為給數據加入標簽。這帶來了兩個問題:一是數據集采集后需要大量人力物力進行標注,大規模數據集的構建十分困難;二是對于許多學習任務,如數據生成,策略學習等,人為標注的方法較為困難甚至不可行。研究者普遍認為,如何讓機器從未經處理的,無標簽類別的數據中直接進行無監督學習,將是AI領域下一步要著重解決的問題。
在無監督學習的任務中,生成模型是最為關鍵的技術之一。生成模型是指一個可以通過觀察已有的樣本,學習其分布并生成類似樣本的模型。深度學習的研究者在領域發展的早期就極為關注無監督學習的問題,基于神經網絡的生成模型在神經網絡的再次復興中起到了極大的作用。在計算資源還未足夠豐富前,研究者提出了深度信念網絡(Deep belief network, DBN)[8],深度玻爾茲曼機(Deep Boltzmann machines, DBM)[9]等網絡結構,這些網絡將受限玻爾茲曼機(Restricted Boltzmann machine, RBM)[10],自編碼機(Autoencoder, AE)[11]等生成模型作為一種特征學習器,通過逐層預訓練的方式加速經網絡的訓練[12]。
然而,早期的生成模型往往不能很好地泛化生成結果。隨著深度學習的進一步發展,研究者提出了一系列新的模型。生成式對抗網絡(Generative adversarial networks, GAN)是生成式模型最新,也是目前最為成功的一項技術,由Goodfellow等在2014年第一次提出[13]。
GAN的主要思想是設置一個零和博弈,通過兩個玩家的對抗實現學習。博弈中的一名玩家稱為生成器,它的主要工作是生成樣本,并盡量使得其看上去與訓練樣本一致。另外一名玩家稱為判別器,它的目的是準確判斷輸入樣本是否屬于真實的訓練樣本。一個常見的比喻是將這兩個網絡想象成偽鈔制造者與警察。GAN的訓練過程類似于偽鈔制造者盡可能提高偽鈔制作水平以騙過警察,而警察則不斷提高鑒別能力以識別偽鈔。隨著GAN的不斷訓練,偽鈔制造者與警察的能力都會不斷提高[14]。
GAN在生成逼真圖像上的性能超過了其他的方法,一經提出便引起了極大的關注。尤為重要的是,GAN不僅可作為一種性能極佳的生成模型,其所啟發的對抗學習思想更滲透進深度學習領域的方方面面,催生了一系列新的研究方向與應用[15]。
本文梳理了生成式對抗網絡的最新研究進展,并對其發展趨勢進行展望。第1節介紹了GAN的提出背景、基本思想與原始GAN存在的缺陷;第2節介紹了GAN在生成機制方面的改進;第3節介紹了GAN在判別機制方面的改進;第4節對GAN的應用發展進行了介紹;最后總結了GAN領域研究的內在邏輯與存在的問題,并對其下一步發展做出展望。
1. GAN的背景與提出
GAN是在深度生成模型的基礎上發展而來,但又與以往的模型有顯著區別。本節首先簡要介紹深度學習與深度生成模型的基本思想與發展歷史,然后介紹原始GAN的模型結構與訓練方法,最后討論原始GAN中存在的不足。
1.1 深度學習
深度學習是機器學習的一種實現方法。相比一般的機器學習方法,深度學習最主要的區別是不依賴人工進行特征工程。研究者認為,手工設計的特征描述子往往過早地丟失掉有用信息,直接從數據中學習到與任務相關的特征表示,比手工設計特征更加有效[16]。
深度學習使用多層神經網絡(Multilayer neural network)[17]對數據進行表征學習。相比傳統的神經網絡方法,深度學習主要在四方面進行了突破:1)使用了卷積神經網絡(Convolutional neural network, CNN)[18-19],遞歸神經網絡(Recurrent/recursive neural network, RNN)[20-22]等特殊設計的網絡結構,這些新的網絡結構大大加強了神經網絡的建模能力;2)使用了整流線性單元(Rectified linear unit, ReLU)[23]、Dropout[24]、Adam[25]等新的激活函數、正則方法與優化算法,這些新的訓練技術有效提高了神經網絡的收斂速度,使得大規模的神經網絡訓練成為可能;3)使用了圖形處理器(Graphics processing unit, GPU)[2,26]、現場可編程邏輯門陣列(Field-programmable gate array, FPGA)[27]、應用定制電路(Application-specific integrated circuit, ASIC)[28]以及分布式系統[29]等新的計算設備與計算系統,這些設備使得神經網絡的訓練時間大大縮短,從而具有被實際部署的可能性;4)形成了較為完善的開源社區,出現了Theano[30],Torch[31-32],Tensorflow[33]等被廣泛使用的算法庫,開源社區的發展降低了深度學習的應用門檻,提高了該領域新發現的可重復性,吸引了越來越多的研究者加入研究行列。
深度學習在模型、算法、硬件設施與開發社區四方面的突破改變了過往神經網絡優化困難,應用受限,計算緩慢,認可度不高的問題,使得該技術的影響力不斷擴大。目前,深度學習已成為人工智能研究中的一種主流方法。深度學習在監督學習任務,尤其是在圖像識別[34]任務上的突破尤為令人矚目。
1.2 深度生成模型
無監督學習具有重要的研究與應用價值。其一是有標記的數據較為稀缺,或是數據的標注與所希望研究的問題不直接相關,此時必須使用無監督或半監督學習的方法[35];其二是高層次的表征學習有助于其他任務的學習,可以幫助模型避免陷入局部最優點,或是添加一定的限制使得模型泛化能力提高[36];其三是在一些強化學習的場景下,我們無法得知未來任務的具體形式,而僅知道這些任務與環境有較為確定性的關系。無監督學習可提高代理(Agent)對環境的預測能力,從而有效提高代理的表現水平[37];最后,對于一些問題我們希望有多樣化的回答而不僅僅是返回一個確定性的答案,有監督學習到的模型無法實現這一要求[14;36]。
生成模型是無監督學習的核心任務之一。雖然深度學習在早期研究中使用了自編碼機,受限玻爾茲曼機等一系列生成模型,但這些模型往往會出現過擬合現象,不能很好地泛化以生成多樣性樣本。
為了解決這一問題,研究者提出了一種名為隨機反向傳播(Stochastic back-propagation)[38]的方法。通過加入額外的獨立于模型的隨機輸入z,我們可以將確定性的神經網絡f(x)轉化為具有隨機性的f(x;z),并使用反向傳播的方法進行訓練。這一方法可以提高生成模型輸出樣本的多樣性。
以變分自編碼機(Variational auto-encoder, VAE)[39]為例。如圖1所示,VAE的一種簡單實現是假設生成樣本x為高斯分布,即

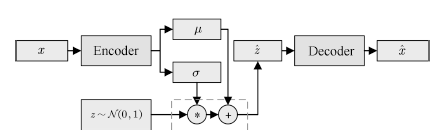
圖1 變分自編碼機
Fig.1 Variational auto-encoder
若將某一隨機變量直接輸入網絡中,由于此時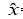 與輸入x的關系不唯一,網絡可能出現優化困難的問題。我們可以通過設置隨機變量z?~?N (0,?1),并構建編碼器網絡μ?=?g1?(x),?σ?=?g2?(x),?原網絡轉化為
與輸入x的關系不唯一,網絡可能出現優化困難的問題。我們可以通過設置隨機變量z?~?N (0,?1),并構建編碼器網絡μ?=?g1?(x),?σ?=?g2?(x),?原網絡轉化為
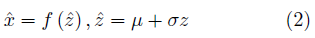
通過反向傳播算法,網絡可以獲得更好的均值與標準差估計,不斷提高生成模型的生成效果。在VAE的工作中,這一方法被稱為重參數化技巧(Reparameterization trick)。
深度學習與隨機反向傳播方法的出現使得使用神經網絡生成復雜隨機樣本成為可能,如何使得生成樣本在具備多樣性的同時保持原樣本的模式特征成為了主要的研究問題。
1.3 生成式對抗網絡
Goodfellow等提出了生成式對抗網絡模型。GAN由一組對抗性的神經網絡構成(分別稱為生成器和判別器),生成器試圖生成可被判別器誤認為真實樣本的生成樣本。與其他生成模型相比,GAN的顯著不同在于,該方法不直接以數據分布和模型分布的差異為目標函數,轉而采用了對抗的方式,先通過判別器學習差異,再引導生成器去縮小這種差異。生成器G接受隱變量z作為輸入,參數為θ。判別器D的輸入為樣本數據x或是生成樣本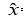 =?G(z),參數為Φ。GAN的網絡結構如圖2所示:
=?G(z),參數為Φ。GAN的網絡結構如圖2所示:
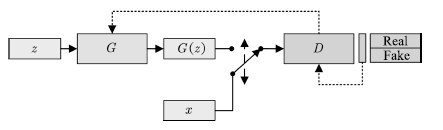
圖2 生成式對抗網絡
Fig.2 Generative adversarial networks
GAN中的生成器與判別器可被視作博弈中的兩個玩家。兩個玩家有各自的損失函數J(G)(θ, φ)與J(D)(θ, φ),訓練過程中生成器和判別器會更新各自的參數以極小化損失。GAN的訓練實質是尋找零和博弈的一個納什均衡解,即一對參數(θ, φ)使得θ是J(G)的一個極小值點,同時φ是J(D的一個極小值點.兩個玩家的損失函數都依賴于對方的參數,但是卻不能更新對方的參數,這與一般的優化問題有很大的不同.
在GAN的原始論文中, Goodfellow將判別器的損失函數定義為一個標準二分類問題的交叉熵.真實樣本對應的標簽為1,生成樣本對應的標簽則為0.J(D的形式為
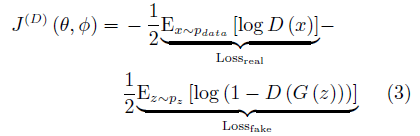
對于生成器的損失函數,根據博弈形式的不同有所區別。對于最簡單的零和博弈,生成器的損失即為判別器所得:

在這一設定下,我們可以認為,GAN的關鍵在于優化一個關于判別器的值函數:
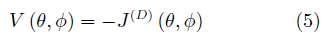
此時,GAN的訓練可以看作一個min-max優化過程:
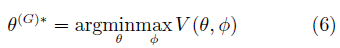
相比以往的生成模型,GAN模型具有以下幾點明顯的優勢:一是數據生成的復雜度與維度線性相關,對于較大維度的樣本生成,僅需增加神經網絡的輸出維度,不會像傳統模型一樣面臨指數上升的計算量;二是對數據的分布不做顯性的限制,從而避免了人工設計模型分布的需要;三是GAN生成的手寫數字、人臉、CIFAR-10等樣本較VAE、PixelCNN等生成模型更為清晰[14]。然而,原始GAN模型也存在許多問題。
1.4 GAN存在的問題
阻礙原始GAN發展的首要問題是不收斂問題。對于有明確目標函數的深度學習問題,一般可以使用基于梯度下降的優化算法加以訓練。GAN的訓練與這類問題不同,其目的是要找到一個納什均衡點。由于一個玩家沿梯度下降的更新過程可能導致另一個玩家的誤差上升,在二者行為可能彼此抵消的情況下,目前沒有理論分析證明GAN總可以達到一個納什均衡點。在實踐中,生成式對抗網絡通常會產生振蕩,這意味著網絡在生成各種模式的樣本之間徘徊,從而無法達到某種均衡。一種常見的問題是GAN將若干不同的輸入映射到相同的輸出點,如生成器輸出了包含相同顏色與紋理的多幅圖片,這種非收斂情形被稱為模式坍塌(Model collapse,又稱the Helvetica scenario)。
其次,原始GAN只能用于生成連續數據,無法生成離散數據(如自然語言)。從直觀上理解,由于生成器每次更新后的輸出是之前的輸出加判別器回傳的梯度,其輸出必須是連續可微的。更進一步地,有研究者指出,是由于原始GAN論文中使用了Jensen-Shannon(JS)散度JSD(Pr||Pg)作為衡量生成樣本的度量標準[40],即使使用詞的分布或embedding等連續的表示方法也無法實現很好的離散數據生成。
最后,相比其他的生成模型,GAN的評價問題更加困難。與VAE不同,GAN的輸入僅有隨機數據,無法使用MAE等重構指標進行衡量。一般而言,除了通過人類測試員對生成樣本進行評價外,研究者還使用Inception score(IS)[41],Frechet inception distance(FID)[42-43]等方法評價生成圖像,使用BLEU分數評判機器翻譯質量[44]。由于這種方式可以自動進行大規模的評估與展示,研究者往往將在這些自動化評價指標上的提升作為主要的貢獻。
然而,有研究指出,在評價分數上的提升更可能來自計算資源與調參技巧上的改進,而非算法上的突破[45]。此外,對于圖像生成任務而言,基于概率估計的評價方法與視覺評價方法相互獨立,一個具有更高評價分數的模型并不能必然地產出更高質量的樣本[46]。在實際中,研究者需要根據具體目的去選擇合適的評價指標。
2. GAN生成機制的發展
面對原始GAN的種種不足,研究者從多個方面嘗試加以解決。在生成機制方面,研究者主要利用了深度學習在有監督學習任務上取得的成果對GAN加以改進。主要包括了使用新的網絡結構、添加正則約束、集成多種模型、改變優化算法等改進。需要說明的是,這四類方法往往會同時出現在一個工作中,本文根據它們的主要貢獻作為分類依據。
2.1 網絡結構
DCGAN[47]是GAN發展早期比較典型的一類改進。卷積神經網絡(Convolutional neural network, CNN)是圖像處理任務中常用的一種網絡結構,被認為可以自動提取圖像的特征[36]。DCGAN將生成器中的全連接層用反卷積(Deconvolution)層[48]代替,在圖像生成的任務中取得了很好的效果,其參數設置如圖3所示。此后,使用GAN進行圖像生成任務時,默認的網絡結構一般都與DCGAN類似的設置。目前,GAN在網絡結構方面的改進主要通過添加額外信息或是對隱變量進行特殊處理來實現。研究人員發現使用半監督的方式,如添加圖像分類標簽的方法會極大地提高GAN生成樣本的質量[41]。這可能是由于添加了圖像標簽等信息后,GAN會更關注對于闡釋樣本相關的統計特征,并忽略不太相關的局部特征。

圖3 DCGAN的拓撲結構[47]
Fig.3 Schematic of DCGAN architecture[47]
基于這種猜想,條件生成式對抗網絡(Conditional GAN,CGAN)[49]提出了一種帶條件約束的GAN,在生成模型G和判別模型D的建模中均引入條件變量c,使用額外信息對模型增加條件,以指導數據的生成過程。CGAN結構如圖4所示。
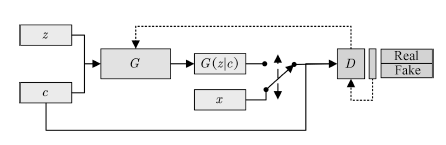
圖4 CGAN的拓撲結構
Fig.4 Schematic of CGAN architecture
CGAN中的條件變量c一般為含有特定語義信息的已知條件,如樣本的標簽。生成器接受噪聲z與條件變量c,生成樣本G(z|c)與相同條件變量c控制下的真實樣本一起用于訓練判別器。相應的,CGAN的目標函數為:
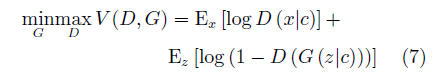
ACGAN[50]是CGAN作者的后續工作。它在判別器D的真實數據x也加入了類別c的信息,進一步告訴G網絡該類的樣本結構如何,從而生成更好的類別模擬。
InfoGAN[51]發展了這種思想。通過引入互信息量,InfoGAN不僅免去了使用標注數據的必要性,還使得GAN的行為具有了一定的可解釋性。InfoGAN的結構如圖5所示。
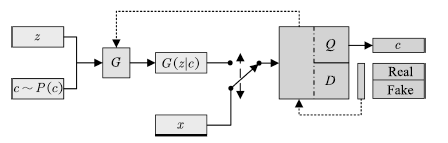
圖5 InfoGAN的拓撲結構
Fig.5 Schematic of InfoGAN architecture
InfoGAN的生成器與CGAN類似,同時接受噪聲z與服從特定分布的隱變量c作為輸入。與CGAN不同的是,InfoGAN接受的隱變量并非已知信息,其含義需要在訓練過程中去發現。判別器會輸出與原始GAN類似的判斷,同時InfoGAN還有一個額外的解碼器Q,用于輸出解碼后的條件變量Q(c|x)。InfoGAN的目標函數為原始GAN的目標函數加上條件變量與生成樣本間的互信息,即:
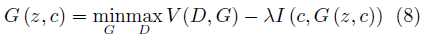
其中第二項為互信息量約束:
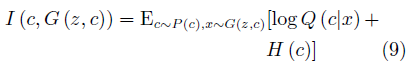
λ是該約束項的超參數。互信息量約束使得輸入的隱變量c對生成數據的解釋性越來越強。
除了有助于提高GAN的生成質量,該類網絡還可實現生成指定類隨機樣本的功能。CGAN通過直接在網絡輸入中加入條件信息c以達到輸出特定類別樣本的目的。InfoGAN可以通過調整隱變量實現改變生成數字的傾斜角度,對人臉的三維模型進行旋轉等操作。
除了在目標函數中對隱變量添加約束外,部分工作利用自編碼機可學習隱變量表示的性質對GAN進行了改進。以VAE-GAN[52]為例,該模型將變分自編碼機與GAN結合,其結構如圖6所示。
該類模型同時訓練GAN與VAE模型,其目標函數由三部分組成:
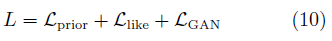

圖6 VAE/GAN的拓撲結構
Fig.6 Schematic of VAE/GAN architecture
其中, 為GAN模型的目標函數,
為GAN模型的目標函數,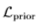 為VAE的先驗約束?
為VAE的先驗約束?
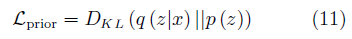
p(z)為隱變量z的先驗分布,q(z|x)為編碼器Encoder(x)的輸出分布。
 為VAE的重構損失函數,根據具體的目的往往有不同形式。通過AE+GAN的設計模式,該類方法可以提供具有更豐富信息的隱變量以提高生成質量。通過設計不同的自編碼機目標函數,研究者還提出了Denoise-GAN[53]、Plug&Play GAN[54]、α-GAN[55]等模型變體。該類模型可以獲得較高清晰度的生成圖像,并在3D模型的生成工作中得到較好應用[56]。
為VAE的重構損失函數,根據具體的目的往往有不同形式。通過AE+GAN的設計模式,該類方法可以提供具有更豐富信息的隱變量以提高生成質量。通過設計不同的自編碼機目標函數,研究者還提出了Denoise-GAN[53]、Plug&Play GAN[54]、α-GAN[55]等模型變體。該類模型可以獲得較高清晰度的生成圖像,并在3D模型的生成工作中得到較好應用[56]。
2.2 正則方法
對原始GAN的另一項重要改進是使用新提出的一系列正則方法。批量規范化(Batch normalization, BN)[57]是深度學習中常用的一種正則方法。其基本思想是每次更新權值時對相應的輸入做規范化操作,使得mini-batch輸出結果的均值為0,方差為1。具體而言,給定一批某中間層網絡的輸入U= {u1,· · ·, um},在使用激活函數對其進行非線性轉換前,首先做如下轉換:
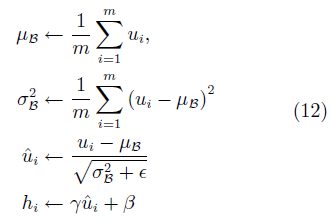
其中,γ、β為待學習的參數,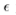 為一極小常數。正則化后,網絡使用轉換過的hi進行下一步操作。BN可以極大地提高神經網絡有監督學習的速度。DCGAN首先將這一技術引入GAN的訓練中,并取得了很好的效果。
為一極小常數。正則化后,網絡使用轉換過的hi進行下一步操作。BN可以極大地提高神經網絡有監督學習的速度。DCGAN首先將這一技術引入GAN的訓練中,并取得了很好的效果。
權值規范化(Weight normalization, WN)[58]是在有監督學習中常用的另一種正則化技術。與BN不同的是,WN主要針對神經網絡的權值進行歸一化,常用的方法是將網絡權值除以其范數。在GAN中,常見的形式是
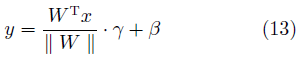
其中,W是網絡的權值,γ、β為待學習的參數。實驗表明,在GAN網絡中使用WN可以取得比BN更好的效果[59]。
除了在有監督學習中常用的BN、WN等方法,有研究者還針對GAN提出了譜規范化(Spectral normalization,SN)[43]。該方法對判別器的各層施加操作
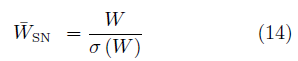
其中,σ(W)是權值的譜范數,其值等于矩陣的最大奇異值。SN可以極大地提高GAN的生成效果,SN-GANs是少數幾種可以使用單一網絡生成ImageNet全部1000類物體的GAN結構。
除此以外,研究者還使用了Minibatch discrimination[41]的方法,通過對批量生成樣本(區別于原始GAN對單個生成樣本)施加多樣性約束以克服模式崩潰問題。
2.3 集成學習
集成學習(Ensemble learning)是通過構建并結合多個學習器來完成學習任務的一種方法[60-61],一般分為兩類。一類是提升(Boosting)方法,通過調整樣本權重,級聯網絡等方法將弱學習器提升為強學習器,另一類則是使用多個同類學習器對數據的不同子集進行學習后,再將學習結果通過某種方式整合(Bagging)起來。
基于Boosting思想的集成方法可以大致分為兩類。一類工作為同構網絡合并。此類的典型工作是AdaGAN[62]。該方法通過與AdaBoost類似的算法依次訓練T個生成器模型。在第t步訓練過程中,前一次未能成功生成的模式會被加大權重。每次訓練后輸出的模型為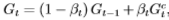 ,為一給定的超參數。?訓練結束后得到一系列生成模型?G1, G2, · · · ,? GT及其相應權重?α1?,? α2, · · · , aT?,?
,為一給定的超參數。?訓練結束后得到一系列生成模型?G1, G2, · · · ,? GT及其相應權重?α1?,? α2, · · · , aT?,? 。?最終的生成模型為?
。?最終的生成模型為?
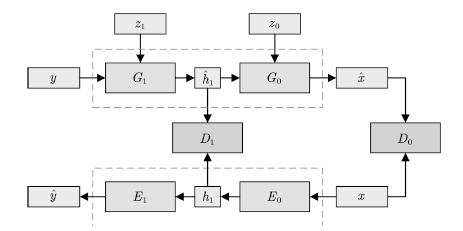
圖7 StackGAN的拓撲結構
Fig.7 Schematic of stackGAN architecture
另一類工作的主要方法為網絡疊加。該類方法的主要模式是串聯多個GAN,將上層生成器的輸出作為隱變量輸入下層生成器。Stack GAN[63]是其中較為典型的工作。如圖7所示,該模型的生成器由多個子模型串聯構成,每級生成器Gi接受上一級生成器的輸出h?i+1及一個隨機變量zi作為輸入.在訓練時,該方法同步訓練一個編碼器Ei,并使用其中間層的輸出hi和生成器的中間輸出一起訓練.
該類工作的另一種常見方式則通過疊加不同分辨率的生成器網絡來實現。以LAP-GAN[64]為例。
如圖8所示,該模型中上一層生成器的輸出Ii+1在放大后(記為li)與隨機變量zi一同輸入下一層網絡,下一層的輸出h?i與li合并為I?i,I?i經過放大后作為再下一層的輸入。
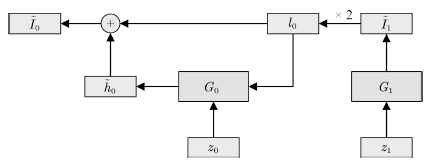
圖8 LAP-GAN的拓撲結構
Fig.8 Schematic of LAP-GAN architecture
后繼的PG-GAN(Progress growing of GANs)[65]通過不斷加深網絡層數的方法改進了這一模式。在訓練過程中首先訓練可輸出低分辨率圖像的淺層網絡,再在淺層網絡上增加層數。該方法可生成目前最高清晰度的圖像。
基于Bagging思想的集成方法主要針對模式坍塌(Mode collapse)這一GAN訓練中最常見的不收斂情況,通過使用多個網絡,每個網絡針對不同的模式進行訓練,之后再將這些網絡的輸出進行整合。
這類模型中較為典型的是CoGAN[66]與MAD-GAN[67]。兩者均通過集成多個共享部分權值的生成器以實現生成多樣性樣本的目的。兩者的區別主要在于,CoGAN使用了與生成器同樣數量的判別器,而MAD-GAN使用了多輸出的單判別器,通過判別目標函數和基于相似性的競爭性目標函數來引導生成器。
相較于基于Boosting的集成方法,基于Bagging的GAN集成方法并沒有在一般性的任務中取得顯著效果。但由于Bagging方法較為直接,在個性化任務中能以較小的代價獲得較大的提升。
2.4 優化算法
GAN的優化算法是另一個重要的改進方向. GAN使用同步梯度下降(Simultaneous gradient ascent)的方法優化網絡,一般可以定義兩個效用函數f(φ,θ)與g(φ,θ),其中(φ,θ)∈?1× ?2.玩家1的目標是最大化效用函數f,玩家2的目標則是最大化效用函數g. ?i(i= 1,2)為對應玩家的可能行動空間,在GAN中,它們對應著生成器與判別器的參數取值空間。GAN博弈的相關梯度向量場(Associated gradient vector field)為
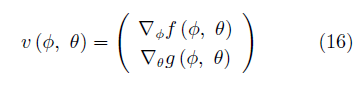
對于零和博弈,有f(φ,θ) = ?g(θ,φ).在一些情況下,如v(φ,θ) =φ·θ時,使用同步梯度下降方法的參數軌跡為
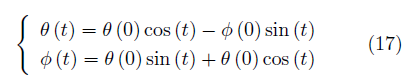
該式對應一個圓軌跡,具有無窮小學習速率的梯度下降將在恒定半徑處環繞軌道運行,使用更大的學習率則軌跡有可能沿螺旋線發散。在這種情況下,同步梯度下降無法接近均衡點θ=Φ=0。
解決這一問題可以使用共識優化(Consensus optimization)[68]的方法。定義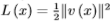 ,有修正的效用函數?
,有修正的效用函數?
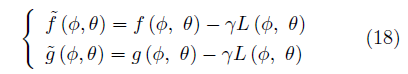
正則化因子L(Φ,θ)鼓勵玩家間達成“共識”,這種方法較同步梯度下降方法具有更好的收斂性。
除了從優化方法的角度,研究者還通過改變優化的形式對GAN加以改進。最為常見的方法是使用強化學習中的策略梯度方法[69-70]以實現生成離散變量的目的。
GAN與強化學習領域的Actor-critic模型[70]的關系引起了許多研究者的注意[71]。強化學習(Reinforcement learning)[72]研究的問題是如何將狀態映射為行動,以最大化執行者的長期回報。Actor-critic模型是強化學習中常用的建模方法,在這一模型中,存在行動者(Actor)與批評家(Critic)兩個子模型,其中,行動者根據系統狀態做出決策,評價者對行動者做出的行為給出估計。如圖9所示。
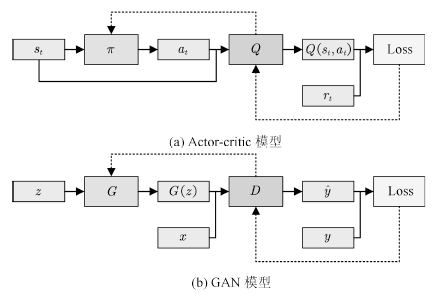
圖9 GAN與Actor-critic模型
Fig.9 GAN and actor-critic models
可以看出,GAN模型與Actor-critic具有結構上的相似性,兩者均包含了一個由隨機變量到另一空間的映射,以及一個可學習的評價模型。兩者均通過迭代尋求均衡點的方式求解。Goodfellow甚至認為GAN實質是一種使用RL技巧解決生成模型問題的方法,兩者的區別主要在于GAN中回報是策略的已知函數且可對行動求導[73]。
Actor-critic的優化方法主要是基于REIN-FORCE算法[74]改進的策略梯度方法。該方法的主要思想是:行動者為一參數化的函數π(s;θ),每次行動的動作為at=π(st|θ).若一個動作可以獲得較大的長期回報Q(st, at)則提高該行動的出現幾率,否則降低該行動的出現幾率.長期回報一般由批評家給出.每次行動后更新策略函數的參數:
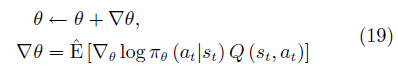
其中,?θ被稱為策略梯度。
在原始GAN中,生成器的學習依賴判別器回傳的梯度。由于離散取值的操作不可微,原始GAN無法解決離散數據的生成問題。通過借鑒Actor-critic模型的思想,研究者提出了一系列基于策略梯度優化的GAN變體以解決這一問題。
SeqGAN[75]是這一系列工作中較早出現的模型之一。它的生成器結構及更新方式與用于圖像生成的GAN類似。其模型結構如圖10所示:
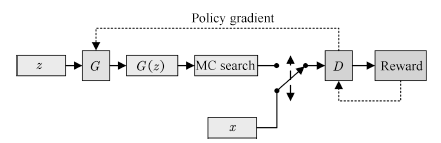
圖10 SeqGAN的拓撲結構
Fig.10 Schematic of SeqGAN architecture
SeqGAN將序列生成問題視為序列決策問題進行處理,使用RNN作為生成網絡。以已生成的語素(Tokens)Y1:t?1作為當前狀態,生成器輸出的下一個詞匯yt為行為,生成器網絡為策略π,行為的回報rt為判別器D對生成Tokens的置信概率。為了提高對整句輸出的判別準確度,SeqGAN在每次生成一個Token后,使用蒙特卡洛搜索(Monte Carlo search, MC search)的方法對句子進行補齊,再將補齊后的句子輸入判別器D. SeqGAN的值函數見式(20),每次更新的策略梯度見式(21):

通過這一方式,SeqGAN克服了原始GAN無法生成離散數據序列的問題。
后續工作通過改進網絡結構,結合更豐富的數據類型等方法進一步強化了GAN的離散數據生成能力。如MaskGAN[76]使用Seq2Seq[7]作為生成網絡,使得GAN具備了填詞能力。SPIRAL[77]使用藝術生成的序列數據作為樣本,可控制機械臂生成藝術圖像。
3. GAN判別機制的發展
如何合理選擇目標函數是深度學習中至關重要的一個問題。一個好的目標函數需要在刻畫任務本質的同時,提供良好的數值優化特性。在GAN的訓練過程中,目標函數設計的主要目標是有效地定義可區分性,并使得博弈過程可解[78-79]。
原始GAN使用分類誤差作為真實分布與生成分布相近度的度量。當判別器為最優判別器時,生成器的損失函數等價于真實分布與生成分布之間的JS散度。然而,已被證明,當真實分布與生成分布的重疊區域可忽略時,JS散度為一常數,此時生成器的獲得梯度為0,無法進一步學習[40]。
有研究者認為,這一問題的根源在于原始GAN假設了判別網絡具有無限建模能力,可以對于任意的樣本分布進行判別。然而對于一般的分布而言,真實分布與生成分布不重疊的概率無限趨于1[80]。為了克服這一問題,研究者提出對樣本分布進行限制的方法,通過假設樣本服從某類特殊的函數族以避免梯度消失的問題。
3.1 Lipschitz密度
一類較有代表性的限制是假設樣本分布服從Lipschitz連續,即其概率密度分布f(x)服從

使不等式成立的最小K值被稱為Lipschitz常數。
這類方法的典型代表是Wasserstein GAN(WGAN)[81]。WGAN使用Wasserstein-1距離(又稱Earth-Mover(EM)距離)作為真實分布與生成分布相近度的度量。定義如下:
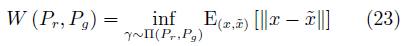
其中,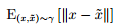 ?相當于在真實與生成樣本?的聯合分布?γ?的條件下,?將真實分布變換為生成分布所需要?“消耗”?的步驟. W (Pr?, Pg?)?是這一?“消?耗”?的最小值.
?相當于在真實與生成樣本?的聯合分布?γ?的條件下,?將真實分布變換為生成分布所需要?“消耗”?的步驟. W (Pr?, Pg?)?是這一?“消?耗”?的最小值.
由于取下界的操作無法直接求解,根據Kantorovich-Rubinstein對偶性[82],EM距離被轉化為如下的形式:
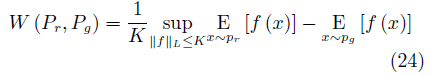
其中, f (·)是一個滿足Lipschitz連續條件的函數.我們可以使用神經網絡對f (·)進行擬合,因此WGAN的目標函數為:

其中評價函數C需要滿足Lipschitz連續條件,一般采用權值裁剪或軟約束的方式保證。在WGAN中,判別器(稱為評價網絡C)的目的是逼近Pr與Pg的EM距離,生成器的目的則是最小化兩者的EM距離。WGAN的網絡結構如圖11所示。
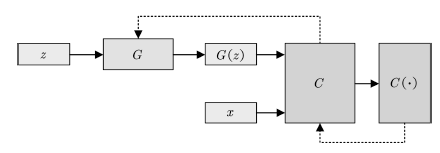
圖11 WGAN的拓撲結構
Fig.11 Schematic of WGAN architecture
WGAN的可收斂性遠強于原始GAN,一經提出就引起了極大的關注。后繼的改進版本WGAN-GP通過添加梯度懲罰的方式[83],進一步提高了網絡的穩定性,在多種網絡結構上都可實現收斂,是目前性能最佳,使用最廣泛的GAN變種之一。
3.2 能量函數
除了使用Lipschitz連續假設對樣本分布進行約束,還可以使用非概率形式作為度量的GAN結構,較為典型的是基于能量的GAN(Energy-based GAN,EBGAN)[84]。EBGAN將判別器D視為一個能量函數,該函數得賦予真實樣本較低的能量,而賦予生成樣本較高的能量。其網絡結構如圖12所示。
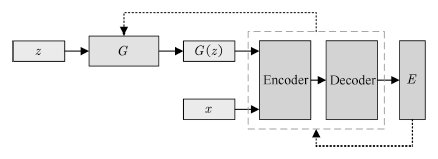
圖12 EBGAN的拓撲結
Fig.12 Schematic of EBGAN architecture
在論文中,EBGAN使用了一個自動編碼機作為判別網絡,并將自動編碼機的重構誤差作為樣本的能量,即:
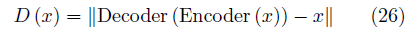
相應的損失函數為

其中[·]+= max (0,·), m是一個預定義的邊界(Margin),主要作用在于避免判別器過強導致生成器無法獲得有用的信息,該參數也可以通過自適應的方式學習[85]。
為了使得生成的樣本具有更好的多樣性,EBGAN還提出了一種約束方法,稱為Pullingaway term(PT),其形式為
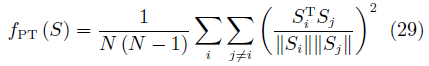
其中,S為判別器中編碼層的輸出。通過增大PT值,EBGAN可以有效地提升生成樣本的多樣性。EBGAN為理解GAN提供了一種全新的視角。
4. GAN的應用
GAN在生成逼真圖像上的性能遠超以往,一經提出便引起了極大的關注。隨著研究的深入,研究者逐漸認識到其作為一種表征學習方式的潛力,并進一步地發展了其對抗的思想,將GAN的結構設計用于模仿學習與圖像翻譯等新興領域。
一般而言,GAN的應用遵循這樣的設計模式:首先定義一個模型用于將某一空間中的數據映射至另一空間,再定義一個模型用于評估這一映射的質量。通過迭代訓練兩模型得到理想的映射模型或評價模型。本文將GAN的應用依據其映射的性質分為三類:數據生成與增強,廣義翻譯模型,以及廣義生成模型。
4.1 數據生成與增強
作為生成模型,GAN最為直接的作用是對訓練數據進行增強。根據增強后的數據性質,這一類應用可以分為數據集內增強與數據集外增強兩類。前者是對訓練集內數據進行填補,清晰化,變換等操作,主要目的是增強數據集質量。后者則主要是結合外部知識或無標簽數據對數據集進行調整和猜測,使其具備原數據集不具備的信息。
在有監督的深度學習訓練中,研究者常常要對原始數據進行平移、縮放、旋轉等操作。這些數據增強操作一方面擴大了數據集的樣本量,另一方面也有助于神經網絡學到輪廓,紋理等特征,以收斂到更好的(局部)最優解[2]。
數據集內提升是對這一工作的擴展。典型的應用包括缺失數據填補[86-87]、超分辨率圖像生成[88]、視頻預測[89-90]、圖像清晰化[91]等。該類工作的主要模式是將有缺陷的數據或歷史數據輸入生成器,通過使用GAN的訓練方式替代均方根誤差(Mean square error,MSE)等人工設計的損失函數,從而實現更好的修復或預測效果。
以缺失數據填補為例。給定一個信息有缺失的數據,如部分像素丟失的圖像,我們希望根據同類別的其他圖像訓練一個模型,該模型可將丟失的信息補全。如圖13所示,相比傳統方法(Image melding)[92],基于GAN的數據填補可以更好地考慮圖像的語義信息,并填充符合當前場景的內容。
圖13 GAN[86]與傳統方法[92]的數據填補效果
Fig.13 Image completion by GAN[86] and traditional method[92]
許多計算機視覺任務都可以通過GAN增強圖像以提高性能。除了圖像分類,目標檢測等常用任務,GAN也被用于對抗樣本[93-94]的生成[95]與抵抗任務,如APE-GAN[96]通過將對抗樣本轉化為可被目標模型正確識別的樣本,Generative adversarial trainer[97]使用GAN生成對抗性擾動(Adversarial perturbation)后將經過污染的樣本與標記樣本一起學習,等等。
GAN在數據集外擴展方面的工作,主要集中在使用仿真數據擴大真實數據相關的工作。在許多問題中,真實數據的收集十分困難或緩慢,但在仿真數據上訓練的模型又無法很好地泛化以用于現實任務[98]。研究者提出了PixelDA[99]、SimGAN[100]、GraspGAN[101]等模型以解決該問題。該類模型的基本想法是通過使用GAN中的生成器作為精煉器(Refiner),對仿真數據進行修飾后,使其與真實數據相接近。該類方法使得以往需要大量樣本的任務,如人眼識別、自動駕駛、機械臂控制等,現在通過少量真實樣本與仿真環境即可完成訓練[102-104]。
GAN還可以用于提升開放集分類(Opencategory classification,OCC,即將與訓練集內數據類型不一致的樣本區分為單獨一類)問題的性能[105]。通過生成接近集內數據但被判別器認為是集外數據的樣本,GAN可以較大地提升分類器在開放集分類問題上的性能。
數據生成與增強的工作往往與半監督學習相聯系,其目的在于提高后續的監督學習或強化學習性能。一部分半監督學習方面工作還使用了GAN本身的結構特性。如后文IRGAN對判別式信息檢索(Information retrieval,IR)模型的提升,使用CGAN模型中的判別器作為圖像分類器[106],Professor forcing[107]方法中使用GAN提高RNN的訓練質量,等等。由于這部分研究尚不豐富,限于篇幅本文不做詳細介紹。
4.2 廣義數據翻譯
不同領域的數據往往具有各自不同的特征和作用。如自然語言數據具有易獲取,具有較為明確的意義,但缺乏細節信息的特點。圖像數據具有細節豐富,但難以分析語義的特點。同類數據間如何翻譯,不同類型的數據間如何轉化,不僅具有相當的實用價值,而且對于提高神經網絡的可解釋性具有重要的意義。GAN已被用于一些常見的數據翻譯工作中,如從語義圖生成圖像[108]、圖文翻譯[109]等。本節主要介紹一些GAN所特有或表現顯著優于傳統方法的應用。
根據用戶修改自動對照片進行編輯和生成是一個極具挑戰的任務。研究人員提出了iGAN模型,通過類似InfoGAN等模型調整隱變量改變輸出樣本的方法,將用戶輸入作為隱變量,實現了圖像的自動修改與生成[110-111]。效果如圖14所示。受該工作啟發,研究者提出了“圖對圖翻譯”的新問題[112]。
圖14 iGAN的生成樣例[110]
Fig.14 Images generated by iGAN[110]
如圖15所示,許多常見的圖像處理任務都可以看作是將一張圖片“翻譯”為另一張圖片,如將衛星圖像轉換為對應的路網圖,將手繪稿轉換為照片,將黑白圖像轉換為彩色圖片等。Isola等提出了一種名為Pix2Pix[112]的方法,利用GAN實現了這種翻譯,模型結構如圖16所示。
圖15圖對圖翻譯舉例[112]
Fig.15 Examples of image to image translation[112]
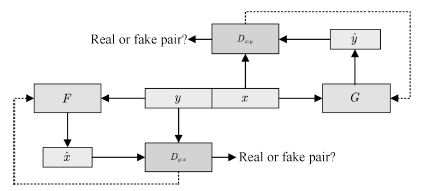
圖16 Pix2Pix的拓撲結構
Fig.16 Chematic of Pix2Pix architecture
圖16中F與G均為翻譯器. Pix2Pix需要成對的數據集(x,y),例如在衛星圖像轉換的任務中,x是衛星圖像,y是對應的路網圖像.在x向y轉換的過程中,翻譯器接受x的樣本,生成對應的樣本y?,判別器Dx:y判別x與y?是否配對,并將梯度回傳給翻譯器.y向x的轉換也照此進行。
Pix2Pix取得了非常驚艷的效果,后續的Pix2PixHD[113]等工作進一步提高了其生成樣本的分辨率和清晰度。不過,該模型的訓練必須有標注好的成對數據,這限制了它的應用場景。為了解決這一問題,結合對偶學習[114],研究者提出了CycleGAN[115],使得無須建立訓練數據間一對一的映射,也可以在源域和目標域之間實現轉換。CycleGAN的結構如圖17所示。
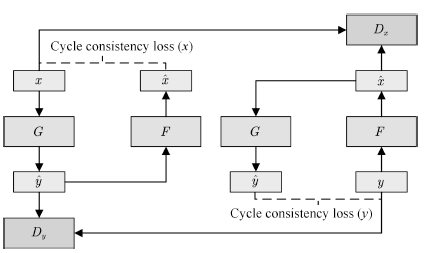
圖17 CycleGAN的拓撲結構
Fig.17 Schematic of CycleGAN architecture
為了使用非配對數據進行訓練,CycleGAN會首先將源域樣本映射到目標域,然后再映射回源域得到二次生成圖像,從而消除了在目標域中圖像配對的要求。為了保證經過“翻譯”的圖像是我們所期望的內容,CycleGAN還引入了循環一致性的約束條件。
以x向y的轉換為例,翻譯器G接受x的樣本,生成對應的樣本y?,翻譯器F再將y?翻譯為x?.判別器Dy接受樣本y與y?,并試圖判別其中的生成樣本。x?應與x相似,以保證中間映射有意義。為此,文中將循環一致性約束定義為
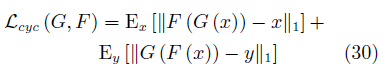
在訓練GAN的同時保證循環一致性約束最小化,CycleGAN就可以通過非配對數據實現較好的映射效果。該方法生成的圖像與Pix2Pix十分接近。除了用于數據增強任務外,該模型也被廣泛用于神經風格轉換(Neural style transfer)[116]等藝術性工作中。
4.3 廣義生成模型
以上討論的工作主要關于圖像,自然語言等具體數據。實際上,我們可以考慮更為廣義的數據,如狀態、行動、圖網絡等。
該類研究的典型工作之一為生成式模仿學習(Generative adversarial imitation learning, GAIL)[117]。模仿學習(Imitation learning)是強化學習中的一個重要課題,其目的是解決如何從示教數據中學習專家策略的問題。由于狀態對行動的映射具有不確定性,直接使用示教數據進行監督訓練得到的策略模型往往不能很好地泛化。研究者一般使用反向強化學習(Inverse reinforcement learning, IRL)[118]來解決這一問題。通過學習一個代理回報函數(Surrogate reward function)R?(s),并期望該函數能最好地解釋觀察到的行為,再由此從數據中習得類似的策略。IRL成功解決了一系列的問題,如預測出租車司機行為[119],規劃四足機器人的足跡[120]等。
然而,IRL算法的運算代價高昂,且方法過于間接。對于模仿學習而言,真正的目的是使得Agent可以習得專家的策略,內在的代價函數并非必要。研究者從GAN的思想中得到啟發,提出了生成式模仿學習(Generative adversarial imitation learning, GAIL)[117]的方法。GAIL的一般結構如圖18所示。
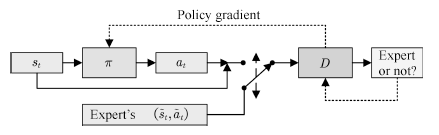
圖18 生成式模仿學習
Fig.18 Generative adversarial imitation learnin
與GAN類似,GAIL的目的是訓練一個策略網絡πθ,其輸出的狀態–行為對Xθ={(s1, a1),· · ·,(sT, aT)}可以欺騙判別器Dφ,使其無法區分Xθ與由專家策略πE輸出的XE.GAIL的目標函數為
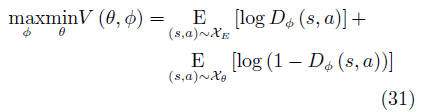
策略的代理回報函數為
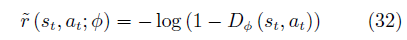
使用策略梯度方法更新行動者π(生成器),最終使得行動者的決策與專家的決策一致。該方法被用于模仿駕駛員[121],機械臂控制[122]等任務中,取得了較好的效果。
與GAIL相類似,IRGAN[123]使用對抗方式提高信息檢索(Information retrieval,IR)模型質量。一般而言,IR模型可分為兩類。一類為生成式模型,其目標是學習一個查詢(Query)到文檔(Document)的關聯度分布,利用該分布對每個查詢返回相關的檢索結果。另一類為判別式模型,該模型可以區分有關聯的查詢對(queryr, docr)與無關聯的查詢對(queryf, docf).對于給定的查詢對對于給定的查詢對,該模型可返回該查詢對內元素的關聯程度[124]。由于這兩類模型的對抗性質,IRGAN將兩個或多個生成式IR模型與判別式IR模型整合為一個GAN模型,再通過策略梯度優化的方式提升兩類模型的檢索質量。
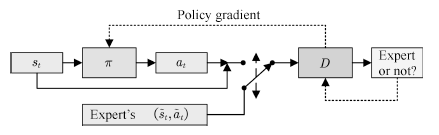
圖18 生成式模仿學習
Fig. 18 Generative adversarial imitation learnin
此外,GAN還被用于專業領域數據的生成任務。如用于生成惡意軟件的MalGAN[125]模型,用于生成DNA序列的FBGAN[126],用于學習圖嵌入表示(Graph embedding)[127]的GraphGAN等。限于篇幅,本文不再詳細介紹。
5. 總結與展望
自2014年提出以來,生成式對抗網絡獲得了極大的關注與發展。GAN的相關工作越來越多地出現在機器學習的各類會議和期刊上,LeCun甚至將其稱為“過去十年間機器學習領域中最讓人激動的點子”。
本文綜述了GAN在理論與應用方面的成果,總體來看可分為兩個大的方向。
第一個研究方向集中在生成機制方面,主要的問題是如何設計一個有效的結構,以學習一個從隱變量到目標空間的映射。在理論上主要包括了如何設計更好的網絡結構和相應的優化方法以提高生成數據質量,如何集成多模型以提高生成效率。在應用上主要是考慮半監督學習問題以及復雜數據間的映射問題。
第二個研究方向集中在判別機制方面,主要的問題是如何更好地將生成問題轉化為一個較易學習的判別問題。在理論上主要包括了如何設計博弈形式以提高學習效率,在應用上主要是如何利用GAN中的判別模型輔助下游任務,以及如何設計整體結構,將其他問題轉化為一個可判別的生成問題。
GAN在數據生成,半監督學習,強化學習等多方面任務中起到了重要作用。但也應看到,該領域的發展仍處于早期階段,許多問題仍在制約GAN的發展。最為突出的是GAN的評價與復現問題,目前尚未有關于如何科學評價GAN的共識。其次,GAN的博弈與收斂機制背后的數學分析仍有待建立,現有的研究主要是利用深度學習在有監督任務中積累的經驗進行擴展。最后,大部分GAN的工作仍然缺乏實用價值,僅可在特定的數據集上使用。如何建立類似ImageNet等標準化任務以評價GAN方法;如何建立和分析GAN的數學機制,并在此基礎上進一步實現GAN特有的,與有監督學習任務不同的深度學習構件;如何拓展GAN的應用范圍;這些問題仍有待研究者進一步探索。
從更高的角度看,GAN的成功實質反映了人工智能的研究進入深水區,研究的重點從視覺、聽覺等感知問題向解決決策、生成等認知問題轉移。與機器感知問題相比,這些新的問題往往人類也無法很好解決,對這類問題的解決必須依賴新的研究方法。
這兩類問題的區別可以使用強化學習中的“探索與利用兩難(Explore and exploit dilemma)”問題進行類比,如圖19所示。對于感知問題,我們有一個足夠明確的目標以及目標臨近域的數據,所需要的是足夠高效的利用方法。然而,對于認知問題,我們只能通過比較局部目標的方法來定義問題,且數據往往過于稀疏或處于局部最優點附近。如在圍棋AI的研究中發現,使用人類數據訓練的智能體會收斂到局部最優值,反而無法勝過不學習人類經驗的智能體[128]。此時,需要尋找一種方法充分探索可能性空間,以更好地確定實際需要學習的目標。
圖19 探索與利用
Fig.19 Explore and exploit
實現這種探索的一個方式是將真實世界的互動機制引入模型。GAN可以看作是這樣的一個系統,通過在生成模型上添加判別模型,GAN模仿了現實世界中人類判斷圖片的機制,進而將難以定義的樣本差異轉化為一個博弈問題。與之類似的是AlphaZero,通過自我對弈的形式積累大量數據,再從中探索出一個更優的策略。在這一新的研究范式中,模型從分析的工具變為了數據的“工廠”[129]。
這類方法的思路與國內學者提出的平行思想有很多相似之處。平行思想是指,通過將真實系統與人工系統融合,在兩個平行的系統中迭代實現對另一系統的描述、預測與引導[129]。有研究者結合平行思想與機器學習提出了平行學習的概念[130]。通過在平行系統中綜合描述學習、預測學習與引導學習,可以更好地提高機器學習方法的樣本效率,擴大學習的探索空間,實現一條從小數據產生大數據,再由大數據煉成“小定律”的精準知識之路,從而更好地分析和解決決策、生成等難以明確定義優化目標的問題。目前,平行學習己在自動駕駛中得到了成功的應用[131-132]。
GAN可被視為一個最簡單且無引導學習功能的平行學習系統,它用判別器逼近真實系統,利用生成器逼近人工系統,為虛實一體的智能“平行機”構造提供了一個例子[133]。GAN為平行學習中的博弈提供了一個初步示例,更為人工智能的下一步發展提供了一種全新的思路。
-
人工智能
+關注
關注
1792文章
47495瀏覽量
239180 -
GaN
+關注
關注
19文章
1950瀏覽量
73776
原文標題:人工智能研究的新前線:生成式對抗網絡
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Imagination 系列研討會 |中國生成式 AI 的發展

特種電源發展走向淺析
IDC生成式AI白皮書亮點速遞
生成式AI工具作用
基于神經網絡的全息圖生成算法
生成對抗網絡(GANs)的原理與應用案例
如何利用生成式人工智能進行精確編碼
生成式AI與神經網絡模型的區別和聯系
原來這才是【生成式AI】!!

【就在本周日】開源商業內在邏輯及運作模式

深度學習生成對抗網絡(GAN)全解析





 工商網監
工商網監
評論