 如何使用EAST文本檢測器在自然場景下檢測文本
如何使用EAST文本檢測器在自然場景下檢測文本
眾所周知,自然場景下的文本檢測是極具挑戰性的。本文便使用OpenCV和EAST文本檢測器在自然場景下對文本進行了檢測,包括圖像中的文本檢測,以及視頻中的文本檢測,并對其原理與實現過程做了詳盡的描述。
在本教程中,您將學習如何使用EAST文本檢測器在自然場景下檢測文本。
本教程的主要目的是教讀者利用OpenCV和EAST文本檢測器來檢測文本。
運行環境:
EAST文本檢測器需要OpenCV3.4.2或更高版本,有需要的讀者可以先安裝OpenCV。
主要內容:
教程第一部分分析為何在自然場景下進行文本檢測的挑戰性是如此之高。
接下來簡要探討EAST文本檢測器,為何使用,算法新在何處,并附上相關論文供讀者參考。
最后提供 Python + OpenCV文本檢測實現方式,供讀者在自己的應用中使用。
為何在自然場景下進行文本檢測的挑戰性是如此之高
由于光照條件、圖片質量以及目標非線性排列等因素的限制,自然場景下的文本檢測任務難度較大
受約束的受控環境中的文本檢測任務通常可以使用基于啟發式的方法來完成,比如利用梯度信息或文本通常被分成段落呈現,并且字符一般都是成直線排列等信息。
但自然場景下文本檢測則不同,而且更具挑戰性。
由于廉價數碼相機和智能手機的普及,我們需要高度關注圖像拍攝時的條件。Celine Mancas-Thillou和Bernard Gosselin在其2017年發表的優秀論文《自然場景文本理解》中描述了的自然場景文本檢測面對的主要挑戰:
圖像/傳感器噪音:手持式相機的傳感器噪音通常要高于傳統掃描儀。此外,廉價相機通常會介入原始傳感器的像素以產生真實的顏色。
視角:自然場景中的文本存在不平行的觀測角度問題,使文本更難以識別。
模糊:不受控制的環境下,文本往往會變模糊,尤其是如果最終用戶使用的智能手機的拍攝穩定性不足時,問題就更明顯。
照明條件:我們無法對自然場景圖像中的照明條件做出任何假設。可能在接近黑暗的條件下,相機上的閃光燈可能會亮起,也可能在艷陽高照的條件下,使整個圖像趨于飽和。
分辨率:每臺圖像捕捉設備都是不同的,可能存在分辨率過低的攝像機拍出的圖像。
非紙質對象:大多數(但不是全部)紙張是不反光的。而自然場景中的文字可能是反光的,比如徽標,標志等。
非平面目標:想象文字印在瓶子上的情況,瓶子表面上的文本會扭曲和變形。雖然我們自己仍可以輕松地“檢測”并閱讀文本,但算法做起來就會很困難。我們需要能夠處理這種情況的用例。
處理條件未知:我們不能使用任何先驗信息來為算法提供關于文本所在位置的“線索”。
OpenCV’sEAST文本檢測器甚至可以識別模糊圖片中的文字
EAST深度學習文本檢測器
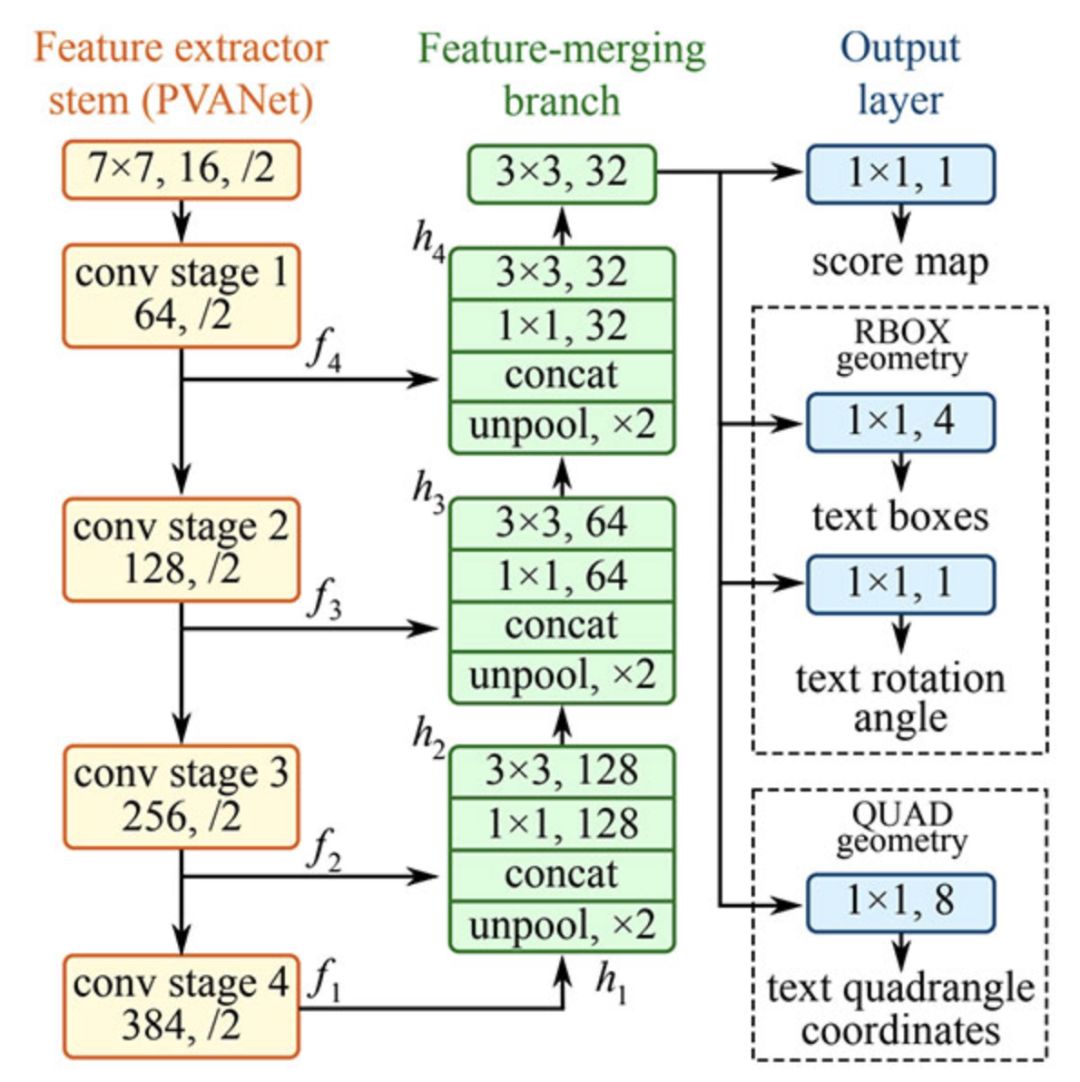
EAST文本檢測器全卷積網絡結構
EAST是一種基于深度學習的文本探測器,即高效、準確的場景文本檢測(Efficient andAccurateSceneText detectionpipeline)。更重要的是,深度學習模型是端對端的,因此可能繞開一般文本識別器用的計算成本高昂的子算法,比如候選對象聚合和詞匯分割等。
項目結構
首先使用Tree終端命令來瀏覽項目結構:
1$tree--dirsfirst 2. 3├──images 4│├──car_wash.png 5│├──lebron_james.jpg 6│└──sign.jpg 7├──frozen_east_text_detection.pb 8├──text_detection.py 9└──text_detection_video.py10111directory,6files
在images/目錄下已有三張樣圖,讀者可以自己添加更多圖片。
我們使用兩個.py文件:
text_detection.py: 檢測靜態圖像中的文本
text_detection_video.py: 檢測網絡攝像頭或輸入圖像文件中的文本
兩個腳本都使用EAST模型 (frozen_east_text_detection.pb)
注意事項
本文中介紹的實例基于OpenCV的官方C++實例,在轉換為Python的過程中可能會遇見一些問題。
比如,Python中沒有Point2f和RotatedRect函數,所以不能完全再現C++環境下的實現。
其次,NMSBoxes函數不返回Python綁定的任何值,最終導致OpenCV報錯。 NMSBoxes函數可以在OpenCV3.4.2中使用,但我無法對其進行詳盡的測試。
使用OpenCV實現文本檢測器的構建
在開始之前,我想再次指出,您至少需要在系統上安裝OpenCV 3.4.2(或OpenCV 4)才能使用OpenCV的EAST文本檢測器,因此如果您還沒有安裝OpenCV 3.4.2或更高版本,請參閱后文的OpenCV安裝指南。
接下來,安裝或升級你的系統中的imutils。
1$pipinstall--upgradeimutils
此時,系統設置已經完成,打開text_detection.py,輸入以下代碼:
1#importthenecessarypackages 2fromimutils.object_detectionimportnon_max_suppression 3importnumpyasnp 4importargparse 5importtime 6importcv2 7 8#constructtheargumentparserandparsethearguments 9ap=argparse.ArgumentParser()10ap.add_argument("-i","--image",type=str,11help="pathtoinputimage")12ap.add_argument("-east","--east",type=str,13help="pathtoinputEASTtextdetector")14ap.add_argument("-c","--min-confidence",type=float,default=0.5,15help="minimumprobabilityrequiredtoinspectaregion")16ap.add_argument("-w","--width",type=int,default=320,17help="resizedimagewidth(shouldbemultipleof32)")18ap.add_argument("-e","--height",type=int,default=320,19help="resizedimageheight(shouldbemultipleof32)")20args=vars(ap.parse_args())
首先,我們在第2-6行導入所需的包和模塊。注意,我們從imutils.object_detection導入NumPy,OpenCV和non_max_suppression實現。
然后我們繼續解析第9-20行的五個命令行參數:
--image:輸入圖像的路徑。
--east:EAST場景文本檢測器模型文件路徑。
--min-confidence:確定文本的概率閾值。可選,默認值= 0.5。
--width:調整后的圖像寬度 - 必須是32的倍數。可選,默認值= 320。
--height:調整后的圖像高度 - 必須是32的倍數。可選,默認值= 320。
重要提示:EAST文本要求輸入圖像尺寸為32的倍數,因此如果您選擇調整圖像的寬度和高度值,請確保這兩個值是32的倍數!
然后加載圖像并調整大小:
22#loadtheinputimageandgrabtheimagedimensions23image=cv2.imread(args["image"])24orig=image.copy()25(H,W)=image.shape[:2]2627#setthenewwidthandheightandthendeterminetheratioinchange28#forboththewidthandheight29(newW,newH)=(args["width"],args["height"])30rW=W/float(newW)31rH=H/float(newH)3233#resizetheimageandgrabthenewimagedimensions34image=cv2.resize(image,(newW,newH))35(H,W)=image.shape[:2]
第23和24行加載并復制輸入圖像。
第30行和第31行確定原始圖像尺寸與新圖像尺寸的比率(基于為--width和--height提供的命令行參數)。
然后我們調整圖像大小,忽略縱橫比(第34行)。
為了使用OpenCV和EAST深度學習模型執行文本檢測,我們需要提取兩層的輸出特征映射:
37#definethetwooutputlayernamesfortheEASTdetectormodelthat38#weareinterested--thefirstistheoutputprobabilitiesandthe39#secondcanbeusedtoderivetheboundingboxcoordinatesoftext40layerNames=[41"feature_fusion/Conv_7/Sigmoid",42"feature_fusion/concat_3"]
我們在40-42行構建了layerNames的表:
第一層是我們的輸出sigmoid激活,它給出了包含文本或不包含文本的區域的概率。
第二層是表示圖像“幾何”的輸出要素圖。我們使用它來導出輸入圖像中文本的邊界框坐標。
加載OpenCV的EAST文本檢測器:
44#loadthepre-trainedEASTtextdetector45print("[INFO]loadingEASTtextdetector...")46net=cv2.dnn.readNet(args["east"])4748#constructablobfromtheimageandthenperformaforwardpassof49#themodeltoobtainthetwooutputlayersets50blob=cv2.dnn.blobFromImage(image,1.0,(W,H),51(123.68,116.78,103.94),swapRB=True,crop=False)52start=time.time()53net.setInput(blob)54(scores,geometry)=net.forward(layerNames)55end=time.time()5657#showtiminginformationontextprediction58print("[INFO]textdetectiontook{:.6f}seconds".format(end-start))
我們使用cv2.dnn.readNet將神經網絡加載到內存中,方法是將路徑傳遞給EAST檢測器作為第46行的參數。
然后我們通過將其轉換為第50行和第51行的blob來準備我們的圖像。要了解有關此步驟的更多信息,請參閱深度學習:OpenCV的blobFromImage如何工作。
要預測文本,我們可以簡單地將blob設置為輸入并調用net.forward(第53和54行)。這些行被抓取時間戳包圍,以便我們可以在第58行打印經過的時間。
通過將layerNames作為參數提供給net.forward,我們指示OpenCV返回我們感興趣的兩個特征映射:
輸出幾何圖用于導出輸入圖像中文本的邊界框坐標
類似地,分數圖包含文本的給定區域的概率:
我們需要逐一循環這些值:
60#grabthenumberofrowsandcolumnsfromthescoresvolume,then61#initializeoursetofboundingboxrectanglesandcorresponding62#confidencescores63(numRows,numCols)=scores.shape[2:4]64rects=[]65confidences=[]6667#loopoverthenumberofrows68foryinrange(0,numRows):69#extractthescores(probabilities),followedbythegeometrical70#datausedtoderivepotentialboundingboxcoordinatesthat71#surroundtext72scoresData=scores[0,0,y]73xData0=geometry[0,0,y]74xData1=geometry[0,1,y]75xData2=geometry[0,2,y]76xData3=geometry[0,3,y]77anglesData=geometry[0,4,y]
我們首先抓取score的維度(第63行),然后初始化兩個列表:
rects:存儲文本區域的邊界框(x,y)坐標
置信度:存儲與每個邊界框相關的概率
我們稍后將對這些區域使用non-maximasuppression。
在第68行開始循環。
第72-77行提取當前行的分數和幾何數據y。
接下來,我們遍歷當前所選行的每個列索引:
79#loopoverthenumberofcolumns 80forxinrange(0,numCols): 81#ifourscoredoesnothavesufficientprobability,ignoreit 82ifscoresData[x]
對于每一行,我們開始循環第80行的列。
我們需要通過忽略概率不高的區域來過濾弱文本檢測(第82行和第83行)。
當圖像通過網絡時,EAST文本檢測器自然地減少了體積大小——我們的體積實際上比輸入圖像小4倍,所以我們乘以4,使坐標回到原始圖像。
我已經包含了如何在第91-93行提取角度數據;然而,正如我在前一節中提到的,不能像在C++中那樣構造一個旋轉的邊界框——如果你想要處理這個任務,那么從第91行角度開始將是你的第一步。
第97-105行派生出文本區域的邊框坐標。
然后我們分別更新rects和confi數據庫列表(第109行和第110行)。
最后一步是將非最大值抑制應用于我們的邊界框以抑制弱重疊邊界框,然后顯示結果文本預測:
112#applynon-maximasuppressiontosuppressweak,overlappingbounding113#boxes114boxes=non_max_suppression(np.array(rects),probs=confidences)115116#loopovertheboundingboxes117for(startX,startY,endX,endY)inboxes:118#scaletheboundingboxcoordinatesbasedontherespective119#ratios120startX=int(startX*rW)121startY=int(startY*rH)122endX=int(endX*rW)123endY=int(endY*rH)124125#drawtheboundingboxontheimage126cv2.rectangle(orig,(startX,startY),(endX,endY),(0,255,0),2)127128#showtheoutputimage129cv2.imshow("TextDetection",orig)130cv2.waitKey(0)
正如我在上一節中提到的,我無法在我的OpenCV 4安裝(cv2.dnn.NMSBoxes)中使用非最大值抑制,因為Python綁定沒有返回值,最終導致OpenCV出錯。我無法完全在OpenCV 3.4.2中進行測試,因此它可以在v3.4.2中運行。
相反,我使用了imutils包中提供的非最大值抑制實現(第114行)。結果仍然很好;但是,我無法將我的輸出與NMSBoxes函數進行比較,看它們是否相同。
第117-126行循環遍歷邊界框,將坐標縮放到原始圖像尺寸,并將輸出繪制到orig圖像。直到按下一個按鍵為止,原始圖像將一直顯示(129-130行)。
最后一個實驗需要注意的是,我們的兩個嵌套for循環用于循環第68-110行上的分數和幾何體(geometry volume),這是一個很好的例子,說明你可以利用Cython極大地加快pipeline的速度。我已經用OpenCV和Python演示了Cython在快速優化“for”像素循環中的強大功能。
OpenCV文本檢測器結果
在終端可以執行一下命令(注意兩個命令行參數):
1$pythontext_detection.py--imageimages/lebron_james.jpg2--eastfrozen_east_text_detection.pb3[INFO]loadingEASTtextdetector...4[INFO]textdetectiontook0.142082seconds
結果應該如下圖所示:
文本檢測器成功識別出籃球巨星勒布朗·詹姆斯球衣上的文字
詹姆斯身上有三個文本區域。
現在讓我們嘗試檢測業務標志的文本:
1$pythontext_detection.py--imageimages/car_wash.png2--eastfrozen_east_text_detection.pb3[INFO]loadingEASTtextdetector...4[INFO]textdetectiontook0.142295seconds
使用EAST文本檢測器很容易識別出路邊洗車店的招牌文字
最后,我們將嘗試一個路標:
1$pythontext_detection.py--imageimages/sign.jpg2--eastfrozen_east_text_detection.pb3[INFO]loadingEASTtextdetector...4[INFO]textdetectiontook0.141675seconds
基于Python和OpenCV的場景文本檢測器和EAST文本檢測器成功檢測出西班牙語的停車指示路牌
該場景中包含一個西班牙的停車標志。“ALTO”可以準確的被OpenCV和EAST識別出來。
如你所知,EAST非常精確,且相對較快,平均每張圖片耗時約0.14秒。
OpenCV在視頻中進行文本檢測
我們可以基于上述工作,進一步使用OpenCV在視頻中進行文本檢測。
開啟text_detection_video.py,然后插入如下代碼:
1#importthenecessarypackages2fromimutils.videoimportVideoStream3fromimutils.videoimportFPS4fromimutils.object_detectionimportnon_max_suppression5importnumpyasnp6importargparse7importimutils8importtime9importcv2
首先,我們導入一些包。我們將使用VideoStream訪問網絡攝像頭并用FPS來為這個腳本測試每秒幀數。其他內容與前一節相同。
為方便起見,定義一個新函數來為我們的預測函數進行解碼 - 它將被重用于每個幀并使循環更清晰:
11defdecode_predictions(scores,geometry):12#grabthenumberofrowsandcolumnsfromthescoresvolume,then13#initializeoursetofboundingboxrectanglesandcorresponding14#confidencescores15(numRows,numCols)=scores.shape[2:4]16rects=[]17confidences=[]1819#loopoverthenumberofrows20foryinrange(0,numRows):21#extractthescores(probabilities),followedbythe22#geometricaldatausedtoderivepotentialboundingbox23#coordinatesthatsurroundtext24scoresData=scores[0,0,y]25xData0=geometry[0,0,y]26xData1=geometry[0,1,y]27xData2=geometry[0,2,y]28xData3=geometry[0,3,y]29anglesData=geometry[0,4,y]3031#loopoverthenumberofcolumns32forxinrange(0,numCols):33#ifourscoredoesnothavesufficientprobability,34#ignoreit35ifscoresData[x]
在第11行,我們定義decode_prediction函數。該函數用于提取:
文本區域的邊界框坐標;
文本區域檢測的概率。
這個專用函數將使代碼更易于閱讀和管理。
讓我們來解析命令行參數:
68#constructtheargumentparserandparsethearguments69ap=argparse.ArgumentParser()70ap.add_argument("-east","--east",type=str,required=True,71help="pathtoinputEASTtextdetector")72ap.add_argument("-v","--video",type=str,73help="pathtooptinalinputvideofile")74ap.add_argument("-c","--min-confidence",type=float,default=0.5,75help="minimumprobabilityrequiredtoinspectaregion")76ap.add_argument("-w","--width",type=int,default=320,77help="resizedimagewidth(shouldbemultipleof32)")78ap.add_argument("-e","--height",type=int,default=320,79help="resizedimageheight(shouldbemultipleof32)")80args=vars(ap.parse_args())
69-80行代碼中命令行參數解析:
--east:EAST場景文本檢測器模型文件路徑。
--video:輸入視頻的路徑(可選)。如果提供了視頻路徑,那么網絡攝像頭將不會被使用。
--Min-confidence:確定文本的概率閾值(可選)。default=0.5。
--width:調整圖像寬度(必須是32的倍數,可選)。default=320。
--Height:調整圖像高度(必須是32的倍數,可選)。default=320。
與上一節中僅使用圖像的腳本(就命令行參數而言)的不同之處在于,用視頻替換了圖像參數。
接下里,我們將進行重要的初始化工作:
82#initializetheoriginalframedimensions,newframedimensions,83#andratiobetweenthedimensions84(W,H)=(None,None)85(newW,newH)=(args["width"],args["height"])86(rW,rH)=(None,None)8788#definethetwooutputlayernamesfortheEASTdetectormodelthat89#weareinterested--thefirstistheoutputprobabilitiesandthe90#secondcanbeusedtoderivetheboundingboxcoordinatesoftext91layerNames=[92"feature_fusion/Conv_7/Sigmoid",93"feature_fusion/concat_3"]9495#loadthepre-trainedEASTtextdetector96print("[INFO]loadingEASTtextdetector...")97net=cv2.dnn.readNet(args["east"])
第84-86行上的高度、寬度和比率初始化將允許我們稍后適當地縮放邊界框。
我們定義了輸出層的名稱,并在第91-97行加載了預先訓練好的EAST文本檢測器。
下面的代碼設置了我們的視頻流和每秒幀數計數器:
99#ifavideopathwasnotsupplied,grabthereferencetothewebcam100ifnotargs.get("video",False):101print("[INFO]startingvideostream...")102vs=VideoStream(src=0).start()103time.sleep(1.0)104105#otherwise,grabareferencetothevideofile106else:107vs=cv2.VideoCapture(args["video"])108109#starttheFPSthroughputestimator110fps=FPS().start()
我們的視頻流設置為:
一個攝像頭(100-103行)
或一個視頻文件(106-107行)
我們在第110行初始化每秒幀計數器,并開始循環傳入幀:
112#loopoverframesfromthevideostream113whileTrue:114#grabthecurrentframe,thenhandleifweareusinga115#VideoStreamorVideoCaptureobject116frame=vs.read()117frame=frame[1]ifargs.get("video",False)elseframe118119#checktoseeifwehavereachedtheendofthestream120ifframeisNone:121break122123#resizetheframe,maintainingtheaspectratio124frame=imutils.resize(frame,width=1000)125orig=frame.copy()126127#ifourframedimensionsareNone,westillneedtocomputethe128#ratioofoldframedimensionstonewframedimensions129ifWisNoneorHisNone:130(H,W)=frame.shape[:2]131rW=W/float(newW)132rH=H/float(newH)133134#resizetheframe,thistimeignoringaspectratio135frame=cv2.resize(frame,(newW,newH))
我們從113行開始在視頻/攝像頭框架上進行循環。
我們的框架調整了大小,保持了縱橫比(第124行)。從129-132行中獲取維度并計算比例。然后我們再次調整幀的大小(必須是32的倍數),這一次忽略了長寬比,因為我們已經存儲了用于安全維護(safe keeping)的比率(第135行)。
推理和繪制文本區域邊框發生在以下幾行:
137#constructablobfromtheframeandthenperformaforwardpass138#ofthemodeltoobtainthetwooutputlayersets139blob=cv2.dnn.blobFromImage(frame,1.0,(newW,newH),140(123.68,116.78,103.94),swapRB=True,crop=False)141net.setInput(blob)142(scores,geometry)=net.forward(layerNames)143144#decodethepredictions,thenapplynon-maximasuppressionto145#suppressweak,overlappingboundingboxes146(rects,confidences)=decode_predictions(scores,geometry)147boxes=non_max_suppression(np.array(rects),probs=confidences)148149#loopovertheboundingboxes150for(startX,startY,endX,endY)inboxes:151#scaletheboundingboxcoordinatesbasedontherespective152#ratios153startX=int(startX*rW)154startY=int(startY*rH)155endX=int(endX*rW)156endY=int(endY*rH)157158#drawtheboundingboxontheframe159cv2.rectangle(orig,(startX,startY),(endX,endY),(0,255,0),2)
在這一代碼塊中:
創建一個blob并通過網絡傳遞文本區域(第139-142行);
解碼預測并應用NMS(第146行和第147行)。使用之前在這個腳本中定義的decode_forecasts函數和imutils non_max_suppression函數。
循環包圍框并在框架上繪制它們(150-159行)。這涉及到按前面收集的比率縮放方框。
而后我們將關閉框架處理循環以及腳本本身:
161#updatetheFPScounter162fps.update()163164#showtheoutputframe165cv2.imshow("TextDetection",orig)166key=cv2.waitKey(1)&0xFF167168#ifthe`q`keywaspressed,breakfromtheloop169ifkey==ord("q"):170break171172#stopthetimeranddisplayFPSinformation173fps.stop()174print("[INFO]elaspedtime:{:.2f}".format(fps.elapsed()))175print("[INFO]approx.FPS:{:.2f}".format(fps.fps()))176177#ifweareusingawebcam,releasethepointer178ifnotargs.get("video",False):179vs.stop()180181#otherwise,releasethefilepointer182else:183vs.release()184185#closeallwindows186cv2.destroyAllWindows()
我們在循環的每次迭代中更新fps計數器(第162行),以便當我們跳出循環時可以計算和顯示計時(第173-175行)。
我們在第165行顯示了EAST文本檢測的輸出,并處理按鍵(第166-170行)。如果“q”鍵代表“退出”,并被按下,我們將跳出循環,繼續清理和釋放指針。
視頻文本檢測結果
要使用OpenCV對視頻進行文本檢測,請務必點擊本文底部“下載內容”鏈接獲取相應資源。
而后,打開終端并執行以下命令(將會開啟攝像頭,因為通過命令行參數不提供- -video):
1$pythontext_detection_video.py--eastfrozen_east_text_detection.pb2[INFO]loadingEASTtextdetector...3[INFO]startingvideostream...4[INFO]elaspedtime:59.765[INFO]approx.FPS:8.85
-
檢測器
+關注
關注
1文章
864瀏覽量
47687 -
EAST
+關注
關注
0文章
21瀏覽量
9507 -
深度學習
+關注
關注
73文章
5503瀏覽量
121157
原文標題:10分鐘上手,OpenCV自然場景文本檢測(Python代碼+實現)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ECD檢測器的原理是什么?
【KV260視覺入門套件試用體驗】七、VITis AI字符和文本檢測(OCR&Textmountain)
基于詞組學習的視頻文本檢測方法
電子俘獲檢測器及檢測方法
電荷注入檢測器(CID),電荷注入檢測器原理
文本數據分析:文本挖掘還是自然語言處理?
一篇包羅萬象的場景文本檢測算法綜述
一篇包羅萬象的場景文本檢測算法綜述





 工商網監
工商網監
評論