") 什么是PCA?何時(shí)應(yīng)該使用PCA?PCA是如何工作的?
什么是PCA?何時(shí)應(yīng)該使用PCA?PCA是如何工作的?
編者按:General Assembly數(shù)據(jù)科學(xué)主講Matt Brems講解了主成分分析的原理、數(shù)學(xué)和最佳實(shí)踐。
在統(tǒng)計(jì)學(xué)經(jīng)典教材Casella & Berger的前言中,作者以完美的方式解釋了他們選擇編寫這本教材的原因:
當(dāng)有人發(fā)現(xiàn)你在編教材的時(shí)候,會(huì)問(wèn)下面兩個(gè)問(wèn)題。第一個(gè)是“你為什么寫書?”第二個(gè)是“你的書和現(xiàn)有的書有什么不一樣?”第一個(gè)問(wèn)題相當(dāng)容易回答。寫書是因?yàn)槟銓?duì)現(xiàn)有的文本不完全滿意。
在統(tǒng)計(jì)學(xué)和數(shù)據(jù)科學(xué)中,主成分分析(PCA)是非常重要的技術(shù)……但我在備課的時(shí)候,發(fā)現(xiàn)網(wǎng)上的資料過(guò)于技術(shù)性,不能完全滿足我的需要,甚至提供互相沖突的信息。所以我很有把握地說(shuō),我對(duì)“現(xiàn)有的文本不完全滿意”。
因此,我打算講述下PCA的3W1H:什么是PCA(What),何時(shí)應(yīng)用PCA(When),PCA如何工作(How),為什么PCA有效(Why)。另外,我也將提供一些深入解釋這一主題的資源。我特別想要呈現(xiàn)這一方法的原理,其下的數(shù)學(xué),一些最佳實(shí)踐,以及潛在的缺陷。
盡管我想要讓PCA盡可能地平易近人,但我們將要討論的算法是相當(dāng)技術(shù)性的。熟悉以下知識(shí)能夠更容易地理解本文和PCA方法:矩陣運(yùn)算/線性代數(shù)(矩陣乘法,矩陣轉(zhuǎn)置,矩陣取逆,矩陣分解,本征向量/本征值)和統(tǒng)計(jì)/機(jī)器學(xué)習(xí)(標(biāo)準(zhǔn)化、方差、協(xié)方差、獨(dú)立、線性回歸、特征選取)。在文章中,我加上了指向講解這些主題的鏈接,但這些鏈接(我希望)主要起溫習(xí)作用,以備遺忘,并不要求必須閱讀。
什么是PCA?
假設(shè)你想要預(yù)測(cè)美國(guó)本年度的GDP。你具有大量信息:2017年第一季度的美國(guó)GDP數(shù)據(jù),去年的GDP,前年的GDP……你有所有公開的經(jīng)濟(jì)指標(biāo),比如失業(yè)率、通脹率,等等。你有2010年的人口普查數(shù)據(jù),可以估計(jì)每個(gè)行業(yè)中有多少美國(guó)人工作,以及在人口普查間隙更新這些估計(jì)的美國(guó)社區(qū)調(diào)查數(shù)據(jù)。你知道兩黨在參眾兩院各有多少席位。你可以收集股價(jià)、IPO數(shù)量,已經(jīng)有多少CEO看起來(lái)對(duì)參政感興趣。
TL;DR——有大量變量需要考慮。
如果你之前曾經(jīng)處理過(guò)大量變量,你會(huì)知道這會(huì)帶來(lái)問(wèn)題。你了解所有變量之間的相互關(guān)系嗎?你的變量是否多到導(dǎo)致過(guò)擬合風(fēng)險(xiǎn)顯著加大?或者違背了建模策略的假設(shè)?
你也許會(huì)問(wèn):“我怎樣才能僅僅關(guān)注收集變量中的一小部分呢?”用術(shù)語(yǔ)說(shuō),你想要“降低特征空間的維度”。通過(guò)降低特征空間的維度,你需要考慮的變量之間的關(guān)系不那么多了,過(guò)擬合的風(fēng)險(xiǎn)也不那么高了。(注意:這并不意味著再也不需要考慮過(guò)擬合等事項(xiàng)——不過(guò),我們的方向是正確的!)
毫不令人意外,降低特征空間的維度稱為“降維”。有許多降維的方法,但大部分降維技術(shù)屬于:
特征消除
特征提取
顧名思義,特征消除(feature elimination)通過(guò)消除特征降低特征空間的維度。在上面舉的GDP的例子中,我們可以保留三個(gè)我們認(rèn)為最能預(yù)測(cè)美國(guó)的GDP的特征,丟棄所有其他特征,而不是考慮所有特征。特征消除方法的優(yōu)勢(shì)有:簡(jiǎn)單,保持變量的可解釋性。
特征消除方法的缺點(diǎn)是你無(wú)法從丟棄變量中獲得信息。如果我們僅僅使用去年的GDP,制造業(yè)人口比例(根據(jù)最新的美國(guó)社區(qū)調(diào)查數(shù)據(jù)),失業(yè)率來(lái)預(yù)測(cè)今年的GDP,我們將失去所有丟棄變量的信息,這些丟棄變量本可以為模型貢獻(xiàn)力量。消除特征的同時(shí),我們也完全消除了丟棄變量可能帶來(lái)的任何好處。
而特征提取沒(méi)有這個(gè)問(wèn)題。假設(shè)我們有十個(gè)自變量。在特征提取時(shí),我們創(chuàng)建十個(gè)“新”自變量,每個(gè)“新”自變量是“舊”自變量的組合。然而,我們以特定方式創(chuàng)建這些新自變量,并根據(jù)它們對(duì)因變量的預(yù)測(cè)能力排序。
你可能會(huì)說(shuō):“哪里體現(xiàn)了降維?”好吧,我們保留所需的新自變量,丟棄“最不重要的那些”。由于我們根據(jù)新變量預(yù)測(cè)因變量的能力排序,因此我們知道哪個(gè)變量最重要,哪個(gè)變量最不重要。但是——關(guān)鍵部分來(lái)了——由于這些新自變量是舊變量的組合,因此我們?nèi)匀槐A袅伺f變量最有價(jià)值的部分,盡管我們丟棄了一個(gè)或幾個(gè)“新”變量!
主成分分析是一種特征提取技術(shù)——以特定的方式組合輸入變量,接著在保留所有變量最有價(jià)值部分的同時(shí),丟棄“最不重要”的變量!這還帶來(lái)了有益的副作用,PCA得到的所有“新”變量?jī)蓛瑟?dú)立。這是有益的,因?yàn)榫€性模型的假設(shè)要求自變量互相獨(dú)立。如果我們用這些“新”變量擬合一個(gè)線性回歸模型(見后文的“主成分回歸”),這一假設(shè)必定會(huì)滿足。
何時(shí)應(yīng)該使用PCA?
你是否想要降低變量的數(shù)目,但不能夠識(shí)別可以完全移除的變量?
你是否想要確保變量相互獨(dú)立?
你是否可以接受讓自變量變得不那么容易解釋?
如果這三個(gè)問(wèn)題的回答都是“是”,那PCA是一個(gè)很合適的選擇。如果第三問(wèn)的回答是“否”,那么你不應(yīng)該使用PCA。
PCA是如何工作的?
下一節(jié)將討論P(yáng)CA為何有效。讓我們?cè)谥v解算法之前先簡(jiǎn)要概括下整個(gè)過(guò)程:
我們將計(jì)算概括變量互相關(guān)性的矩陣。
接著我們將這一矩陣分為兩部分:方向和大小。之后我們可以了解數(shù)據(jù)的“方向”及其“大小”(也就是每個(gè)方向有多“重要”)。下圖展示了數(shù)據(jù)的兩個(gè)主要方向:“紅向”和“綠向”。在這一情形下,“紅向”更重要。我們將在后文討論這是為什么,不過(guò),看看給定的數(shù)據(jù)點(diǎn)排列的方式,你能看出為什么“紅向”比“綠向”更重要嗎?(提示:能最好地?cái)M合這些數(shù)據(jù)的直線看起來(lái)是什么樣?)
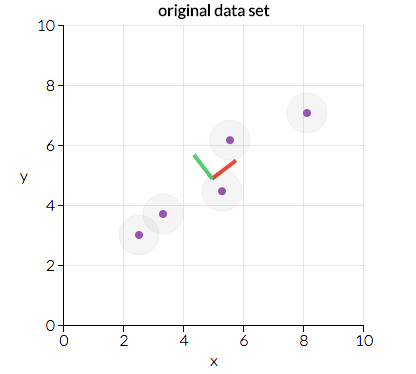
圖片來(lái)源:setosa.io
我們將沿著重要方向(原變量的組合)轉(zhuǎn)換原始數(shù)據(jù)。下圖是經(jīng)過(guò)轉(zhuǎn)換的數(shù)據(jù),x軸和y軸遵循“紅向”和“綠向”。能最好地?cái)M合這些數(shù)據(jù)的直線看起來(lái)會(huì)是什么樣?
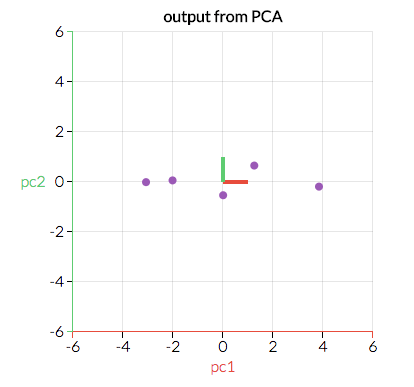
圖片來(lái)源:setosa.io
盡管這里的可視化例子是二維的(因此我們有兩個(gè)“方向”),我們可以設(shè)想數(shù)據(jù)具有更多維度的情形。通過(guò)識(shí)別哪些“方向”最“重要”,我們可以通過(guò)丟棄“最不重要”的“方向”將數(shù)據(jù)壓縮進(jìn)較小的特征空間。通過(guò)將數(shù)據(jù)投射到較小的特征空間,我們降低了特征空間的維度。但因?yàn)閿?shù)據(jù)是根據(jù)這些不同的“方向”轉(zhuǎn)換的,我們確保模型保留了所有原變量。
下面我將具體講解推導(dǎo)PCA的算法。我嘗試避免讓本文過(guò)于技術(shù)性,但這里的細(xì)節(jié)不可能忽略,因此我的目標(biāo)是盡可能明確地講解。下一節(jié)將深入討論為什么這一算法有效的直覺(jué)。
在開始之前,將數(shù)據(jù)整理成表格形式,n行,p+1列,其中一列對(duì)應(yīng)因變量(通常記為Y),p列對(duì)應(yīng)于自變量(這一自變量矩陣通常記為X)。
根據(jù)上一段的定義,將數(shù)據(jù)分成Y和X——我們主要處理X。
在自變量矩陣X的每一列上,從每個(gè)條目中減去該列的均值。(這確保每列的均值為0.)
決定是否標(biāo)準(zhǔn)化。給定X的列,是否高方差的特征比低方差的特征更重要?(這里重要指特征能更好地預(yù)測(cè)Y。)如果特征的重要性獨(dú)立于特征的方差,那么將列中的每項(xiàng)觀測(cè)除以該列的標(biāo)準(zhǔn)差。(結(jié)合第二步、第三步,我們將X的每列標(biāo)準(zhǔn)化了,確保每列的均值為零,標(biāo)準(zhǔn)差為1.)所得矩陣稱為Z。
轉(zhuǎn)置矩陣Z,將轉(zhuǎn)置矩陣和原矩陣相乘。(數(shù)學(xué)上寫為ZTZ.)所得矩陣為Z的協(xié)方差矩陣(無(wú)視常數(shù)差異)。
(這大概是最難的一步——跟緊了。)計(jì)算ZTZ的本征向量和相應(yīng)的本征值。在大多數(shù)計(jì)算軟件包下,這都很容易做到——事實(shí)上,ZTZ的本征分解為將ZTZ分解為PDP-1,其中P為本征向量矩陣,D為對(duì)角線為本征值、其余值均為零的對(duì)角矩陣。D的對(duì)角線上的本征值對(duì)應(yīng)P中相應(yīng)的列——也就是說(shuō),D對(duì)角線上的第一個(gè)元素是λ1,相應(yīng)的本征向量是P的第一列。我們總是能夠計(jì)算出這樣的PDP-1。(獎(jiǎng)勵(lì):致對(duì)此感興趣的讀者,我們之所以總是能夠計(jì)算出這樣的PDP-1是因?yàn)閆TZ是一個(gè)對(duì)稱正定矩陣。)
將本征值λ1,λ2…,λp由大到小排列。并據(jù)此排列P中相應(yīng)的本征向量。(例如,如果λ2是最大的本征值,那么就將P的第二列排到第一。)取決于計(jì)算軟件包,這可能可以自動(dòng)完成。我們將這一經(jīng)過(guò)排序的本征向量矩陣記為P*。(P*的列數(shù)應(yīng)當(dāng)與P相同,只不過(guò)順序可能不同。)注意這些本征向量相互獨(dú)立。
計(jì)算Z*=ZP*。這一新矩陣Z*不僅是X的標(biāo)準(zhǔn)化版本,同時(shí)其中的每個(gè)觀測(cè)是原變量的組合,其中的權(quán)重由本征向量決定。一個(gè)額外的好處是,由于P*中的本征向量是相互獨(dú)立的,Z*的每一列也是相互獨(dú)立的!
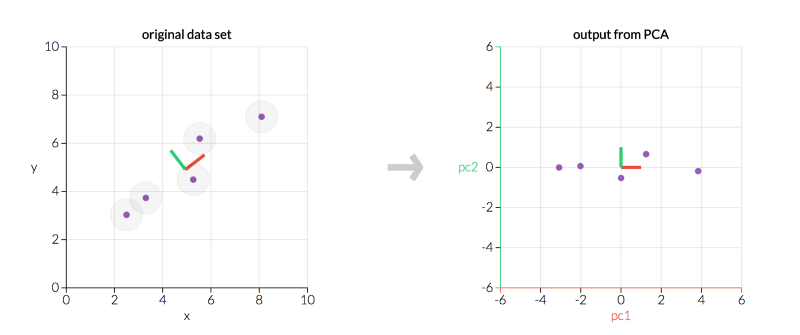
左為原數(shù)據(jù)X,右為經(jīng)PCA轉(zhuǎn)換后的數(shù)據(jù)Z*(圖片來(lái)源:setosa.io)
上圖中,有兩點(diǎn)值得注意:
由于我們的主成分相互之間是正交的,因此它們?cè)诮y(tǒng)計(jì)學(xué)上是相互獨(dú)立的……這就是為什么Z*中的列相互獨(dú)立的原因!
左圖和右圖顯示的是同樣的數(shù)據(jù),但右圖表現(xiàn)的是轉(zhuǎn)換后的數(shù)據(jù),坐標(biāo)軸為主成分。
不管是左圖還是右圖,主成分相互垂直。事實(shí)上,所有主成分總是互相正交(正交是垂直的正式數(shù)學(xué)術(shù)語(yǔ))。
最后,我們需要決定要保留多少特征,丟棄多少特征。決定這一事項(xiàng)有三種常見的方法,我們下面將討論這三種方法并舉例說(shuō)明:
現(xiàn)在我們簡(jiǎn)單解釋下解釋方差比例這個(gè)概念。因?yàn)槊總€(gè)本征值大致等于相應(yīng)本征向量的重要性,所以解釋方差比例等于保留特征的本征值之和除以所有特征的本征值。
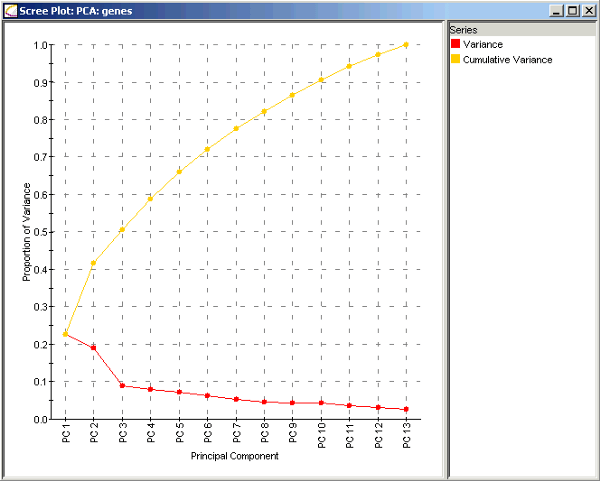
基因數(shù)據(jù)的陡坡圖(來(lái)源:improvedoutcomes.com)
考慮上面的基因數(shù)據(jù)的陡坡圖。紅線表明每個(gè)特征的解釋方差比例,將該主成分的本征值除以所有本征值之和可以得到這一數(shù)值。僅僅包括主成分1的解釋方差比例是λ1/(λ1+ λ2+ … + λp),約為23%. 僅僅包括主成分2的解釋方差比例是λ2/(λ1+ λ2+ … + λp),約為19%.
包括主成分1和主成分2的解釋方差比例是(λ1+ λ2)/(λ1+ λ2+ … + λp),約為42%. 也就是圖中黃線的部分,黃線表明包括到該點(diǎn)為止的所有主成分的解釋方差比例。例如,PC2處的黃點(diǎn)表明包括主成分1和主成分2可以解釋42%的模型總方差。
下面,讓我們看一些例子:
注意:有些陡坡圖的Y軸是本征向量大小而不是方差比例。這樣的陡坡圖得出的結(jié)果是等價(jià)的,不過(guò)需要手工計(jì)算方差比例。
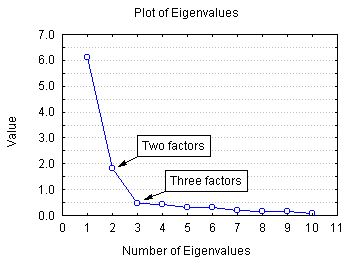
圖片來(lái)源:statsoft.com
法一:假設(shè)我想保留模型中的5個(gè)主成分。在上面的基因數(shù)據(jù)例子中,這5個(gè)主成分可以解釋66%的總方差(包括全部13個(gè)主成分的方差)。
法二:假設(shè)我想包括足夠的主成分,解釋90%的總方差。在上面的基因數(shù)據(jù)例子中,我將包括前10個(gè)主成分,丟棄最后3個(gè)變量。
法三:這次我們想要“找到肘部”。從上圖中,我們看到,在主成分2和主成分3之間有解釋方差比例的較大下降。在這一情形下,我們打算包括前兩個(gè)特征,丟棄其余特征。如你所見,這個(gè)方法有一定的主觀性,因?yàn)椤爸獠俊睕](méi)有一個(gè)數(shù)學(xué)上精確的定義,并且在這個(gè)例子中,包括前兩個(gè)特征的模型只能解釋42%的總方差。
法一:隨意選擇想要保留多少維度。也許我想在二維平面上可視化數(shù)據(jù),所以我可能只保留兩個(gè)特征。這取決于用例,沒(méi)有硬性規(guī)則。
法二:計(jì)算每個(gè)特征的解釋方差比例(下面將簡(jiǎn)要解釋這一概念),選取一個(gè)閾值,不斷加上特征直到達(dá)到閾值。(例如,如果你想要讓模型可以解釋80%的總方差,那就加上解釋方差比例最大的特征,直到可解釋的方差比例達(dá)到或超過(guò)80%.)
法三:這一方法和法二密切相關(guān)。計(jì)算每個(gè)特征的解釋方差比例,根據(jù)解釋方差比例排序特征,并隨著更多特征的保留,標(biāo)繪出解釋方差的累計(jì)比例。(這一圖形稱為陡坡圖,見下。)根據(jù)陡坡圖可以決定包含的特征的數(shù)量,在陡坡圖中找到解釋方差比例明顯小于前一點(diǎn)的點(diǎn),然后選擇到該點(diǎn)為止的特征。(這個(gè)方法叫做“找肘法”,因?yàn)樗ㄟ^(guò)尋找陡坡圖的“彎曲處”或“肘部”以判定解釋方差比例最大下降在何處發(fā)生。)
丟棄了我們想要丟棄的轉(zhuǎn)換后的變量,就可以收工了!這就是PCA.
但是,為什么PCA有效?
盡管PCA是一個(gè)深度依賴線性代數(shù)算法的非常技術(shù)性的方法,仔細(xì)想想,它其實(shí)是一個(gè)相對(duì)直觀的方法。
首先,協(xié)方差矩陣ZTZ包含了Z中每個(gè)變量和其他各個(gè)變量相關(guān)性的估計(jì)。這是一個(gè)了解變量相關(guān)性的強(qiáng)力工具。
其次,本征值和本征向量很重要。本征向量表示方向。設(shè)想下將數(shù)據(jù)繪制在一張多維的散布圖上。每個(gè)本征向量可以想像成數(shù)據(jù)散布圖的一個(gè)“方向”。本征值表示大小,或者重要性。更大的本征值意味著更重要的方向。
最后,我們做了一個(gè)假設(shè),一個(gè)特定方向上的更多差異和解釋因變量行為的能力相關(guān)。大量差異通常意味著信號(hào),而極少差異通常意味著噪音。因此,一個(gè)特定方向上的更多差異,理論上意味著這一方向上有一些我們想要檢測(cè)的重要東西。
所以說(shuō),PCA是一個(gè)結(jié)合了以下概念的方法:
變量之間的相關(guān)性的測(cè)度(協(xié)方差矩陣)。
數(shù)據(jù)散布的方向(本征向量)。
這些不同方向的相對(duì)重要性(本征值)。
PCA組合了預(yù)測(cè)因子,讓我們可以丟棄相對(duì)不那么重要的本征向量。
PCA有擴(kuò)展嗎?
有,不過(guò)限于篇幅,這里不多說(shuō)。最常見到的是主成分回歸,在Z*中未曾丟棄的特征子集上進(jìn)行回歸。這里Z*的相互獨(dú)立發(fā)揮了作用;在Z*上回歸Y,我們知道一定能滿足自變量相互獨(dú)立這一點(diǎn)。不過(guò),我們?nèi)匀恍枰獧z查其他假設(shè)。
另一個(gè)常見的變體是核PCA,即先使用核函數(shù)升維,再使用PCA降維,從而將PCA應(yīng)用于非線性情形。
-
PCA
+關(guān)注
關(guān)注
0文章
89瀏覽量
29609 -
變量
+關(guān)注
關(guān)注
0文章
613瀏覽量
28371
原文標(biāo)題:主成分分析PCA一站式指南
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
PCA9306 I2C緩沖器評(píng)估模塊

PCA8753A 70H地址寫不進(jìn)去數(shù)據(jù),沒(méi)有應(yīng)答信號(hào)是怎么回事?
使用rtthread settings配置完i2c后,與pca9535pw的第一通訊報(bào)錯(cuò),為什么?
PCA9515B雙路雙向I2C總線和SMBus中繼器數(shù)據(jù)表
PCA9518可擴(kuò)展的5通道雙向緩沖器數(shù)據(jù)表
PCA9655E I / O端口擴(kuò)展器 I

PCA9515A雙路雙向I2C總線和SMBus中繼器數(shù)據(jù)表
PCA9548A低電壓8通道I2C開關(guān)數(shù)據(jù)表
PCA9517電平轉(zhuǎn)換I2C總線中繼器數(shù)據(jù)表
簡(jiǎn)單認(rèn)識(shí)變頻器和PLC/PCA系統(tǒng)
具有復(fù)位功能的PCA9546A低壓4通道I2C和SMbus開關(guān)數(shù)據(jù)表
STM32中級(jí)聯(lián)2個(gè)PCA9539,如何對(duì)每個(gè)IO口進(jìn)行操作呢?
普源精電RIGOL示波器電流探頭PCA1150的測(cè)量步驟詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論