") 深度學(xué)習(xí)顯卡選型指南:關(guān)于GPU選擇的一般建議
深度學(xué)習(xí)顯卡選型指南:關(guān)于GPU選擇的一般建議
深度學(xué)習(xí)是一個(gè)對(duì)算力要求很高的領(lǐng)域,GPU的選擇將從根本上決定你的深度學(xué)習(xí)體驗(yàn)。如果沒有GPU,可能你完成整個(gè)實(shí)驗(yàn)需要幾個(gè)月,甚至當(dāng)你只想看看參數(shù)調(diào)整、模型修改后的效果時(shí),那可能也得耗費(fèi)1天或更久的時(shí)間。
憑借性能良好、穩(wěn)定的GPU,人們可以快速迭代深層神經(jīng)網(wǎng)絡(luò)的架構(gòu)設(shè)計(jì)和參數(shù),把原本完成實(shí)驗(yàn)所需的幾個(gè)月壓縮到幾天,或是把幾天壓縮到幾小時(shí),把幾小時(shí)壓縮到幾分鐘。因此,在選購(gòu)GPU時(shí)做出正確選擇至關(guān)重要。
下面是華盛頓大學(xué)博士Tim Dettmers結(jié)合競(jìng)賽經(jīng)驗(yàn)給出的GPU選擇建議,有需要的讀者可把它可作為參考意見。
當(dāng)一個(gè)人開始涉足深度學(xué)習(xí)時(shí),擁有一塊高速GPU是一件很重要的事,因?yàn)樗軒腿烁咝У胤e累實(shí)踐經(jīng)驗(yàn),而經(jīng)驗(yàn)是掌握專業(yè)知識(shí)的關(guān)鍵,能打開深入學(xué)習(xí)新問(wèn)題的大門。如果沒有這種快速的反饋,我們從錯(cuò)誤中汲取經(jīng)驗(yàn)的時(shí)間成本就太高了,同時(shí),過(guò)長(zhǎng)的時(shí)間也可能會(huì)讓人感到挫敗和沮喪。
以我個(gè)人的經(jīng)驗(yàn)為例。通過(guò)配置合理的GPU,我在短時(shí)間內(nèi)就學(xué)會(huì)把深度學(xué)習(xí)用于一系列Kaggle競(jìng)賽,并在Chaly of Hashtags比賽中取得第二名。當(dāng)時(shí)我構(gòu)建了一個(gè)相當(dāng)大的兩層深層神經(jīng)網(wǎng)絡(luò),里面包含用于整流的線性神經(jīng)元和用于正則化的損失函數(shù)。
像這么深的網(wǎng)絡(luò),我手里的6GB GPU是跑不動(dòng)的。所以之后我入手了一塊GTX Titan GPU,這也是最終獲得佳績(jī)的主要原因。
終極建議
性能最好的GPU:RTX 2080 Ti
性價(jià)比高,但小貴:RTX 2080, GTX 1080
性價(jià)比高,同時(shí)便宜:GTX 1070, GTX 1070 Ti, GTX 1060
使用的數(shù)據(jù)集>250GB:RTX 2080 Ti, RTX 2080
預(yù)算很少:GTX 1060 (6GB)
幾乎沒預(yù)算:GTX 1050 Ti (4GB)/CPU(建模)+ AWS/TPU(訓(xùn)練)
參加Kaggle競(jìng)賽:GTX 1060 (6GB)(建模)+ AWS(最終訓(xùn)練)+ fast ai庫(kù)
有前途的CV研究員:GTX 2080 Ti; 在2019年升級(jí)到RTX Titan
普通研究員:RTX 2080 Ti/GTX 10XX -> RTX Titan,注意內(nèi)存是否合適
有雄心壯志的深度學(xué)習(xí)菜鳥:從GTX 1060 (6GB)、GTX 1070、GTX 1070 Ti開始,慢慢進(jìn)階
隨便玩玩的深度學(xué)習(xí)菜鳥:GTX 1050 Ti (4或2GB)
我應(yīng)該多買幾塊GPU嗎?
那時(shí)候,看到GPU能為深度學(xué)習(xí)提供這么多的可能性,我很興奮,于是鉆進(jìn)了多GPU的“深坑”:我組裝了一個(gè)IB 40Gbit/s的小型GPU陣列,希望它能產(chǎn)出更好的結(jié)果。
但現(xiàn)實(shí)很殘酷,我很快就被“打臉”了,在多個(gè)GPU上并行訓(xùn)練神經(jīng)網(wǎng)絡(luò)不僅非常困難,一些常用的加速技巧也收效甚微。誠(chéng)然,小型神經(jīng)網(wǎng)絡(luò)可以通過(guò)數(shù)據(jù)并行性大大降低訓(xùn)練用時(shí),但由于我構(gòu)建的是個(gè)大型神經(jīng)網(wǎng)絡(luò),它的效率并沒有多大變化。
面對(duì)失敗,我深入研究了深度學(xué)習(xí)中的并行化,并在2016年的ICLR上發(fā)表了一篇論文:8-Bit Approximations for Parallelism in Deep Learning。在論文中,我提出了8位近似算法,它能在包含96個(gè)GPU的系統(tǒng)上獲得50倍以上的加速比。與此同時(shí),我也發(fā)現(xiàn)CNN和RNN非常容易實(shí)現(xiàn)并行化,尤其是在只用一臺(tái)計(jì)算機(jī)或4個(gè)GPU的情況下。
所以,雖然現(xiàn)代GPU并沒有針對(duì)并行訓(xùn)練做過(guò)高度優(yōu)化,但我們?nèi)匀豢梢浴盎ㄊ健碧崴佟?/p>
主機(jī)內(nèi)部構(gòu)造:3個(gè)GPU和一個(gè)IB卡,這適合深度學(xué)習(xí)嗎?
NVIDIA:主導(dǎo)者
在很早的時(shí)候,NVIDIA就已經(jīng)提供了一個(gè)標(biāo)準(zhǔn)庫(kù),這使得在CUDA中建立深度學(xué)習(xí)庫(kù)非常容易。再加上那時(shí)AMD的OpenCL沒有意識(shí)到標(biāo)準(zhǔn)庫(kù)的前景,NVIDIA結(jié)合這個(gè)早期優(yōu)勢(shì)和強(qiáng)大的社區(qū)支持,讓CUDA社區(qū)規(guī)模實(shí)現(xiàn)迅速擴(kuò)張。發(fā)展至今,如果你是NVIDIA的用戶,你就能在各個(gè)地方輕松找到深度學(xué)習(xí)的教程和資源,大多數(shù)庫(kù)也都對(duì)CUDA提供最佳支持。
因此,如果要入手NVIDIA的GPU,強(qiáng)大的社區(qū)、豐富的資源和完善的庫(kù)支持絕對(duì)是最重要的因素。
另一方面,考慮到NVIDIA在去年年底不聲不響地修改了GeForce系列顯卡驅(qū)動(dòng)最終用戶許可協(xié)議,數(shù)據(jù)中心只被允許使用Tesla系列GPU,而不能用GTX或RTX卡。雖然他們到現(xiàn)在都沒有定義“數(shù)據(jù)中心”是什么,但考慮到其中的法律隱患,現(xiàn)在不少機(jī)構(gòu)和大學(xué)開始購(gòu)買更貴但效率低的Tesla GPU——即便價(jià)格上可能相差10倍,Tesla卡與GTX和RTX卡相比并沒有真正優(yōu)勢(shì)。
這意味著作為個(gè)人買家,當(dāng)你接受了N卡的便捷性和優(yōu)勢(shì)時(shí),你也要做好接受“不平等”條款的心理準(zhǔn)備,因?yàn)镹VIDIA在這一領(lǐng)域占據(jù)壟斷地位。
AMD:功能強(qiáng)大但缺乏支持
在2015年的國(guó)際超算會(huì)議上,AMD推出HIP,可以把針對(duì)CUDA開發(fā)的代碼轉(zhuǎn)換成AMD顯卡可以運(yùn)行的代碼。這意味著如果我們?cè)贖IP中擁有所有GPU代碼,這將是個(gè)重要的里程碑。但三年過(guò)去了,我們還是沒能見證A卡在深度學(xué)習(xí)領(lǐng)域的崛起,因?yàn)檫@實(shí)踐起來(lái)太困難,尤其是移植TensorFlow和PyTorch代碼庫(kù)。
確切來(lái)說(shuō),TensorFlow是支持AMD顯卡的,所有常規(guī)網(wǎng)絡(luò)都可以在AMD GPU上運(yùn)行,但如果你想構(gòu)建新網(wǎng)絡(luò),它就會(huì)出現(xiàn)不少bug,讓你怎么都不能如意。此外,ROCm社區(qū)也不是很大,沒法直接解決這個(gè)問(wèn)題,再加上缺乏深度學(xué)習(xí)開發(fā)的資金支持,AMD比肩NVIDIA遙遙無(wú)期。
然而,如果我們對(duì)比兩家的下一代產(chǎn)品,可以發(fā)現(xiàn)AMD的顯卡顯示出了強(qiáng)勁性能,未來(lái),Vega 20可能會(huì)擁有類似Tensor-Core計(jì)算單元的計(jì)算能力。
總的來(lái)說(shuō),對(duì)于只是希望模型能在GPU上穩(wěn)穩(wěn)當(dāng)當(dāng)跑完的普通用戶,目前我還找不到推薦AMD的理由,選N卡是最合適的。但如果你是GPU開發(fā)者或是希望對(duì)GPU計(jì)算做出貢獻(xiàn)的人,你可以支持AMD,打擊NVIDIA的壟斷地位,因?yàn)檫@將使所有人長(zhǎng)期受益。
Intel:努力嘗試
用過(guò)Intel家的Phi后,我簡(jiǎn)直要“一生黑”。我認(rèn)為它們不是NVIDIA或AMD卡的真正競(jìng)爭(zhēng)對(duì)手,所以這里我們長(zhǎng)話短說(shuō)。如果你決定入手Xeon Phi,下面是你可能會(huì)遇到的問(wèn)題:支持很爛、計(jì)算代碼段比CPU慢、編寫優(yōu)化代碼非常困難、不完全支持C++11、編譯器不支持一些重要的GPU設(shè)計(jì)模式、和其他庫(kù)的兼容性差(NumPy和SciPy)等等。
我真的很期待Intel的Nervana神經(jīng)網(wǎng)絡(luò)處理器(NNP),但自提出以來(lái),它就陷入了無(wú)休無(wú)止的跳票。根據(jù)最近的說(shuō)法,NNP會(huì)在2019年第三/第四季度出貨,但參考他們家的Xeon Phi,如果我們想買顆技術(shù)成熟的NNP,估計(jì)至少得等到2020年。
谷歌:按需提供的廉價(jià)服務(wù)?
到現(xiàn)在為止,Google TPU已經(jīng)發(fā)展成為非常成熟的云產(chǎn)品,性價(jià)比超高。要理解TPU,我們可以把它簡(jiǎn)單看做是打包在一起的多個(gè)GPU。如果你曾對(duì)比過(guò)Tensor-Core-enabled V100和TPUv2在ResNet50上的性能差距,如下圖所示,可以發(fā)現(xiàn),兩者的準(zhǔn)確率差不多,但TPU更便宜。
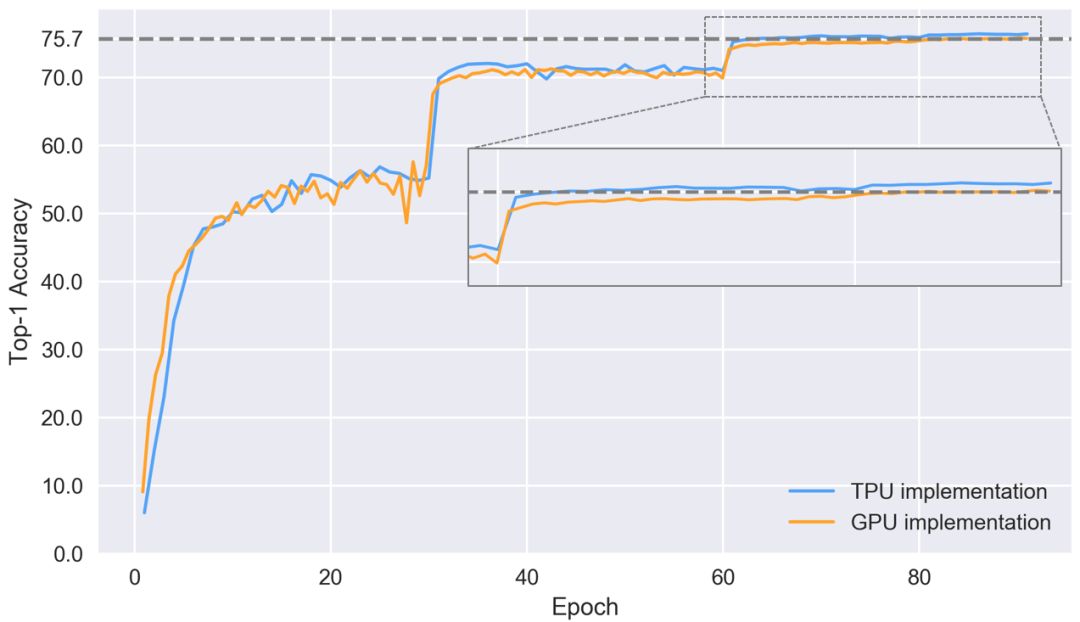
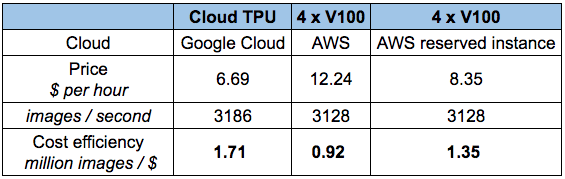
那么如果手頭緊又期望高性能,是不是就選TPU呢?是,也不是。如果你要做論文研究,或是會(huì)頻繁用到它,TPU確實(shí)是個(gè)經(jīng)濟(jì)實(shí)惠的選擇。但是,如果你上過(guò)fast ai的課,用過(guò)fast ai庫(kù),你就會(huì)發(fā)現(xiàn)自己可以用更低的價(jià)格實(shí)現(xiàn)更快的收斂——至少對(duì)于CNN目標(biāo)識(shí)別來(lái)說(shuō)是這樣的。
此外,雖然相比其他同類產(chǎn)品,TPU性價(jià)比更高,但它也存在不少問(wèn)題:(1)TPU不能用于fast ai庫(kù),即PyTorch;(2)TPU算法主要依賴谷歌內(nèi)部團(tuán)隊(duì);(3)沒有統(tǒng)一的高級(jí)庫(kù),無(wú)法為TensorFlow提供良好的標(biāo)準(zhǔn)。
以上三點(diǎn)都是TPU的痛點(diǎn),因?yàn)樗枰獑为?dú)的軟件才能跟上深度學(xué)習(xí)算法的更新迭代。我相信谷歌團(tuán)隊(duì)已經(jīng)完成了一些列工作,但它們對(duì)某些任務(wù)的支持效果還是個(gè)未知數(shù)。因此,目前的TPU更適合計(jì)算機(jī)視覺任務(wù),并作為其他計(jì)算資源的補(bǔ)充,我不建議開發(fā)者把它當(dāng)做自己的主要深度學(xué)習(xí)資源。
亞馬遜:可靠但昂貴
AWS的GPU很豐富,價(jià)格也有點(diǎn)高。如果突然需要額外的計(jì)算,AWS GPU可能是一個(gè)非常有用的解決方案,比如論文deadline快到了。
經(jīng)濟(jì)起見,如果要購(gòu)買亞馬遜服務(wù),你最好只跑一部分網(wǎng)絡(luò),而且確切知道哪些參數(shù)最接近最佳選擇。否則,這些因?yàn)樽约菏д`多出來(lái)的花費(fèi)可能會(huì)讓你的錢包見底。所以,即便亞馬遜的云GPU很快,我們還是自己買一塊專用的實(shí)體顯卡吧,GTX 1070很貴,但它至少也能用個(gè)一兩年啊。
是什么決定了GPU的快慢?
是什么讓這個(gè)GPU比那個(gè)GPU更快?面對(duì)這個(gè)問(wèn)題,可能你最先想到的是看和深度學(xué)習(xí)有關(guān)的顯卡特征:是CUDA核心嗎?主頻多少?RAM多大?
雖然“看內(nèi)存帶寬”是個(gè)“萬(wàn)金油”的說(shuō)法,但我不建議這么做,因?yàn)殡S著GPU硬件和軟件的多年開發(fā),現(xiàn)在帶寬已經(jīng)不再是性能的唯一代名詞。尤其是消費(fèi)級(jí)GPU中Tensor Cores的引入,這個(gè)問(wèn)題就更復(fù)雜了。
現(xiàn)在,如果要判斷顯卡性能好不好,它的指標(biāo)應(yīng)該是帶寬、FLOPS和Tensor Cores三合一。要理解這一點(diǎn),我們可以看看矩陣乘積和卷積這兩個(gè)最重要的張量操作是在哪里被加速的。
提到矩陣乘積,最簡(jiǎn)單有效的一個(gè)理念是它受帶寬限制。如果你想用LSTM和其他需要經(jīng)常進(jìn)行大量矩陣乘積運(yùn)算的RNN,那么內(nèi)存帶寬是GPU最重要的特性。類似地,卷積受計(jì)算速度約束,因此對(duì)于ResNets和其他CNN,GPU上的TFLOP是性能的最佳指標(biāo)。
Tensor Cores的出現(xiàn)稍稍改變了上述平衡。它們是非常簡(jiǎn)單的專用計(jì)算單元,可以加速計(jì)算——但不是內(nèi)存帶寬 ——因此對(duì)CNN來(lái)說(shuō),如果GPU里有Tensor Core,它們帶來(lái)的最大改善就是速度提高約30%到100%。
雖然Tensor Cores只能提高計(jì)算速度,但它們也可以使用16bit數(shù)進(jìn)行計(jì)算。這對(duì)矩陣乘法也是一個(gè)巨大優(yōu)勢(shì),因?yàn)樵诰哂邢嗤鎯?chǔ)器帶寬的矩陣中,16bit數(shù)的信息傳輸量是32bit數(shù)的兩倍。數(shù)字存儲(chǔ)器大小的削減對(duì)于在L1高速緩存中存儲(chǔ)更多數(shù)字特別重要,實(shí)現(xiàn)了這一點(diǎn),矩陣就越大,計(jì)算效率也更高。所以如果用了Tensor Cores,它對(duì)LSTM的提速效果約為20%至60%。
請(qǐng)注意,這種加速不是來(lái)自Tensor Cores本身,而是來(lái)自它們進(jìn)行16bit數(shù)計(jì)算的能力。AMD GPU也支持16bit數(shù)計(jì)算,這意味著在進(jìn)行乘積運(yùn)算時(shí),它們其實(shí)和具有Tensor Cores的NVIDIA顯卡一樣快。
Tensor Cores的一個(gè)大問(wèn)題是它們需要16位浮點(diǎn)輸入數(shù)據(jù),這可能會(huì)引入一些軟件支持問(wèn)題,因?yàn)榫W(wǎng)絡(luò)通常使用32位。如果沒有16位輸入,Tensor Cores將毫無(wú)用處。但是,我認(rèn)為這些問(wèn)題將很快得到解決,因?yàn)門ensor Cores太強(qiáng)大了,現(xiàn)在它們已經(jīng)出現(xiàn)在消費(fèi)級(jí)GPU中,未來(lái),使用它的人只會(huì)越來(lái)越多。請(qǐng)注意,隨著16bit數(shù)被引入深度學(xué)習(xí),GPU內(nèi)存其實(shí)也相當(dāng)于翻倍了,因?yàn)楝F(xiàn)在我們可以在同樣大小的內(nèi)存中存儲(chǔ)比之前多一倍的參數(shù)。
總的來(lái)說(shuō),最好的經(jīng)驗(yàn)法則是:如果用RNN,請(qǐng)看帶寬;如果用卷積,請(qǐng)看FLOPS;如果有錢,上Tensor Cores(除非你必須購(gòu)買Tesla)。
GPU和TPU的標(biāo)準(zhǔn)化原始性能數(shù)據(jù),越高越好
成本效益分析
GPU的成本效益可能是選擇GPU最重要的標(biāo)準(zhǔn)。我圍繞帶寬、TFLOP和Tensor Cores做了一項(xiàng)新的性價(jià)比分析。首先,顯卡的銷售價(jià)格來(lái)自亞馬遜和eBay,兩個(gè)平臺(tái)的權(quán)重是50:50;其次,我查看了有無(wú)Tensor Cores的顯卡在LSTM和CNN上的性能指標(biāo),對(duì)這些指標(biāo)做歸一化處理后進(jìn)行加權(quán),獲得平均性能得分;最后,我計(jì)算得到了下面這個(gè)性能/成本比率:
圍繞帶寬、TFLOP和Tensor Cores的性價(jià)比,越高越好
根據(jù)初步數(shù)據(jù),我們可以發(fā)現(xiàn)RTX 2080比RTX 2080 Ti更實(shí)惠。雖然后者在Tensor Cores和帶寬上提升了40%,在價(jià)格上提高了50%,但這不意味著它能在深度學(xué)習(xí)性能上提升40%。對(duì)于LSTM和其他RNN,GTX 10系列和RTX 20系列帶給它們的性能提升主要來(lái)自支持16bit數(shù)計(jì)算,而不是Tensor Cores;對(duì)于CNN,雖然Tensor Cores帶來(lái)的計(jì)算速度提升效果明顯,但它對(duì)卷積體系結(jié)構(gòu)的其他部分也不存在輔助作用。
因此,相比GTX 10系列,RTX 2080在性能上實(shí)現(xiàn)了巨大提升;相比RTX 2080 Ti,它在價(jià)格上又占盡優(yōu)勢(shì)。所以RTX 2080性價(jià)比最高是可以理解的。
此外,圖中的數(shù)據(jù)不可迷信,這個(gè)分析也存在一些問(wèn)題:
如果你買了性價(jià)比更高但速度很慢的顯卡,那么之后你的計(jì)算機(jī)可能就裝不下更多顯卡了,這是一種資源浪費(fèi)。所以為了抵消這種偏差,上圖會(huì)偏向更貴的GPU。
這個(gè)圖假設(shè)我們用的是帶Tensor Cores和16bit數(shù)計(jì)算的顯卡,這意味著對(duì)于支持32bit數(shù)計(jì)算的RTX卡,它們的性價(jià)比會(huì)被統(tǒng)計(jì)得偏低。
考慮到“礦工”的存在,RTX 20系列開售后,GTX 1080和GTX 1070可能會(huì)迅速降價(jià),這會(huì)影響性價(jià)比排名。
因?yàn)楫a(chǎn)品還未發(fā)布,表中RTX 2080和RTX 2080 Ti的數(shù)字存在水分,不可盡信。
綜上可得,如果只從性價(jià)比角度看,選擇最好的GPU是不容易的。所以如果你想根據(jù)自身?xiàng)l件選一款中庸的GPU,下面的建議是合理的。
關(guān)于GPU選擇的一般建議
目前,我會(huì)推薦兩種主要的選擇方法:(1)購(gòu)買RTX系列,然后用上兩年;(2)等新品發(fā)布后,購(gòu)買降價(jià)的GTX 1080/1070/1060或GTX 1080Ti / GTX 1070Ti。
很長(zhǎng)一段時(shí)間內(nèi),我們一直在等GPU升級(jí),所以對(duì)于很多人來(lái)說(shuō),第一種方法最立竿見影,現(xiàn)在就可以獲得最好的性能。雖然RTX 2080更具成本效益,但RTX 2080 Ti內(nèi)存更大,這對(duì)CV研究人員是個(gè)不小的誘惑。所以如果你是追求一步到位的人,買這兩種顯卡都是明智的選擇,至于選擇哪種,除了預(yù)算,它們的主要區(qū)別就是你究竟要不要RTX 2080 Ti的額外內(nèi)存。
如果你想用16bit計(jì)算,選Ti,因?yàn)閮?nèi)存會(huì)翻倍;如果沒這方面的需要,2080足矣。
至于第二種方法,它對(duì)那些想要追求更大的升級(jí)、想買RTX Titan的人來(lái)說(shuō)是個(gè)不錯(cuò)的選擇,因?yàn)镚TX 10系列顯卡可能會(huì)降價(jià)。請(qǐng)注意,GTX 1060有時(shí)會(huì)缺少某些型號(hào),因此當(dāng)你發(fā)現(xiàn)便宜的GTX 1060時(shí),首先要考慮它的速度和內(nèi)存是否真正滿足自己的需求。否則,便宜的GTX 1070、GTX 1070 Ti、GTX 1080和GTX 1080 Ti也是絕佳的選擇。
對(duì)于創(chuàng)業(yè)公司、Kaggle競(jìng)賽參賽者和想要學(xué)習(xí)深度學(xué)習(xí)的新手,我的推薦是價(jià)格便宜的GTX 10系列顯卡,其中GTX 1060是非常經(jīng)濟(jì)的入門解決方案。
如果是想在深度學(xué)習(xí)上有所建樹的新手,一下子買幾個(gè)GTX 1060組裝成陣列也不錯(cuò),一旦技術(shù)純熟,你可以在2019年把顯卡升級(jí)到RTX Titan。
如果你缺錢,我會(huì)推薦4GB內(nèi)存的GTX 1050 Ti,當(dāng)然如果買得起,還是盡量上1060。請(qǐng)注意,GTX 1050 Ti的優(yōu)勢(shì)在于它不需要連接到PSU的額外PCIe,所以你可以把它直接插進(jìn)現(xiàn)有計(jì)算機(jī),節(jié)省額外資金。
如果缺錢又看重內(nèi)存,eBay的GTX Titan X也值得入手。
我個(gè)人會(huì)買一塊RTX 2080 Ti,因?yàn)槲业腉TX Titan X早該升級(jí)了,而且考慮到研究需要的內(nèi)存比較大,加上我打算自己開發(fā)一個(gè)Tensor Core算法,這是唯一的選擇。
小結(jié)
看到這里,相信現(xiàn)在的你應(yīng)該知道哪種GPU更適合自己。總的來(lái)說(shuō),我提的建議就是兩個(gè):一步到位上RTX 20系列,或是買便宜的GTX 10系列GPU,具體參考文章開頭的“終極建議”。性能和內(nèi)存,只要你真正了解自己要的是什么,你就能挑出屬于自己的最合適的顯卡。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100766 -
顯卡
+關(guān)注
關(guān)注
16文章
2434瀏覽量
67611 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5503瀏覽量
121162
原文標(biāo)題:ICLR老司機(jī)的經(jīng)驗(yàn)和建議:深度學(xué)習(xí)顯卡選型指南
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
相比GPU和GPP,F(xiàn)PGA是深度學(xué)習(xí)的未來(lái)?
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
剛開始進(jìn)行深度學(xué)習(xí)的同學(xué)怎么選擇合適的機(jī)器配置
什么是深度學(xué)習(xí)?使用FPGA進(jìn)行深度學(xué)習(xí)的好處?
深度學(xué)習(xí)之GPU硬件選型
GPU和GPP相比誰(shuí)才是深度學(xué)習(xí)的未來(lái)
深度學(xué)習(xí)如何讓Turing 顯卡如虎添翼
深度學(xué)習(xí)算法的選擇建議
低壓斷路器選型的一般原則
GPU在深度學(xué)習(xí)中的應(yīng)用與優(yōu)勢(shì)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論