

伯克利的研究人員提出了一種簡單的“動作遷移法”,可以將源視頻中一個人的動作和姿態,遷移到新的視頻對象上,讓后者也具有同樣流暢優美的動作,整個過程只需要幾分鐘就成完成。
說起去年讓“馬變斑馬”的CycleGAN,大家應該還記憶猶新。
CycleGAN利用pixel2pixel技術,能自動將某一類圖片轉換成另外一類圖片,過度真實自然,可以說是2017年最受關注的模型之一。CycleGAN論文的第一作者、加州大學伯克利分校的朱俊彥(現已在MIT CSAIL擔任博士后),也由此獲得了SIGGRAPH 2018的杰出博士論文獎。
現在,同樣是伯克利的Caroline Chan、ShiryH Ginosar、Tinghui Zhou、Alexel A. Efros提出了或許更有意思的一篇論文,不僅是圖像,而是實現不同視頻之間的人物動作姿態轉換,而且面部也能逼真合成效果,整個過程只需要幾分鐘就能完成。
將專業舞者的動作遷移到其他人身上,讓每個人都能成為頂級舞者
作者在論文摘要中這樣介紹:
本文提出一種簡單的 “跟我做”(do as I do)的動作遷移方法:給定一個人跳舞的源視頻,我們可以在目標人物表演標準動作幾分鐘后將該表演遷移到一個新的目標身上(業余舞者)。
我們將這個問題視為一個具有時空平滑的每幀 image-to-image 轉換問題。利用姿勢檢測作為原和目標之間的中間表示,我們學習了從姿勢圖像到目標對象外觀的映射。
我們利用這樣的設置實現了連貫時間的視頻生成,并且包括逼真的面部合成。
基于人體姿態關鍵點,實現視頻間不同主體的復雜動作
伯克利研究者提出了一種在不同視頻中轉移人體動作的方法。
他們要實現的目的很簡單——給定兩個視頻:一個是目標人物,我們想合成他的表演;另一個是源視頻,我們想將他的動作轉移到目標人物身上。
這與過去使用最近鄰搜索或 3D 重定向運動的方法不同。在伯克利研究人員提出的框架下,他們制作了各種各樣的視頻,讓業余舞蹈愛好者能夠像芭蕾舞演員一樣旋轉、跳躍,表演武術,跳舞。
最初,為了逐幀地在兩個視頻的主體之間遷移運動,研究人員認為他們必須學習兩個人的圖像之間的映射。因此,目標是在源集和目標集之間發現圖像到圖像的翻譯(image-to-image translation)。
但是,他們并沒有用兩個實驗對象對應的相同動作來直接監督學習這種翻譯。即使兩個實驗對象都做同樣的動作,由于每個實驗對象的體型和風格差異,仍然不太可能有幀到幀的 body-pose 對應的精確框架。
于是,他們觀察了基于人體姿態關鍵點(keypoint),關鍵點本質上是編碼身體的位置而不是外觀,可以作為任何兩個主體之間的中間表示。而姿勢可以隨著時間的推移保持動作特征,同時盡可能地抽象出對象身份標識。因此,我們將中間的表示設計為火柴人自試圖,如下圖所示。
將源視頻中人物(左上)動態的姿態關鍵點(左下)作為轉化,遷移到目標視頻人物(右)。
從目標視頻中,我們得到每一幀的姿勢檢測,得到一組(姿勢火柴人,目標人物形象)的對應數據。有了這些對齊的數據,我們就可以在有監督的情況下,學習一種在火柴人和目標人物圖像之間的 image-to-image 的轉換模型。
因此,的模型經過訓練,可以生成特定目標對象的個性化視頻。然后,將動作從源遷移到目標,將姿勢火柴人圖形輸入到訓練模型中,得到與源姿勢相同的目標對象的圖像。
為了提高結果的質量,研究人員還添加了兩個組件:
為了提高生成的視頻的時間平滑度,我們在每一幀都將預測設置在前一幀的時間步長上。
為了在結果中增加人臉的真實感,我們加入了一個專門訓練來生成目標人物面部的 GAN。
這種方法生成的視頻,可以在各種視頻主體之間遷移運動,而無需昂貴的 3D 或動作捕捉數據。
作者在論文中寫道:“我們的主要貢獻是一個基于學習的視頻之間人體運動遷移的 pineline,所得結果的質量展示了現實的詳細視頻中的復雜運動遷移。”
選一個你喜歡的舞蹈視頻,以及你自己動幾下的視頻,一鍵轉換!
首先,我們需要準備兩種視頻素材:
一個是你理想舞者表演的視頻:
一個是你自己隨性 “凹” 出的動作視頻:
最終的目標,就是讓你能夠跳出夢寐以求的曼妙舞姿:
為了實現這一目標,可以將 pipeline 分為三個階段:
1、姿勢檢測:根據源視頻中給定的幀,使用預訓練好的姿勢檢測器來制作姿勢線條圖;
2、全局姿勢歸一化:該階段考慮了源視頻與目標視頻中人物身形的不同,以及在各自視頻中位置的差異;
3、將歸一化的姿勢線條圖與目標人物進行映射:該階段通過對抗性學習設計了一個系統,來將歸一化的姿勢線條圖與目標人物進行映射。
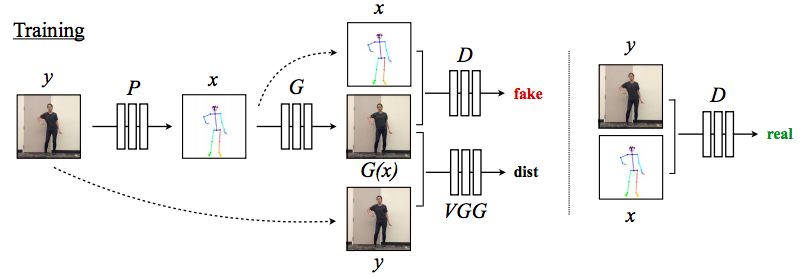
完整的訓練過程
模型根據源視頻中給定的幀,使用預訓練好的姿勢檢測器 P 來制作姿勢線條圖。在訓練期間,學習了一種映射 G 和一個對抗性鑒別器 D,來試圖區分哪些匹配是真,哪些是假。

完整的轉換過程
模型使用一個姿勢檢測器 P : Y′ → X′來獲取源視頻中人物的姿勢關節,這些關節通過歸一化,轉換為姿勢條形圖中目標人物的關節。而后,我們使用訓練好的映射 G。
增加人臉真實感:圖像到圖像轉換的對抗訓練
好了,現在“炫酷舞姿”的問題解決了,剩下的就是將目標視頻中因為動作改變而隨之模糊的臉部變得更加逼真而清晰。
為了實現這一點,研究人員將 pix2pixHD 的對抗性訓練設置修改為:
(1) 產生時間相干視頻幀;
(2) 合成逼真的人臉圖像。
接下來將詳細描述原始目標和對它的修改。
pix2pixHD 框架
方法是基于 pix2pixHD 中的目標提出來的。在初始條件 GAN 設置中,生成器網絡 G 對多尺度鑒別器 D = (D1,D2,D3) 進行極大極小博弈。
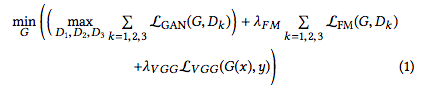
其中,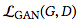 是對抗性損失:
是對抗性損失:

讓動作更加連貫
時間平滑(Temporal Smoothing)設置
Face GAN
我們添加了一個專門的 GAN 設置,用于為面部區域添加更多細節和真實感,如下圖所示。
Face GAN 設置
在 Face GAN 中,通過生成器預測殘差,并將其添加到來自主生成器的原始面部預測中。
更進一步:從pix2pix到pix2pixHD
我們探討了對 pix2pixHD baseline 的修改效果,并根據收集的數據集評估結果的質量。
遷移的結果。每個部分顯示 5 個連續的幀。上面一行顯示 source subject,中間一行顯示規范化的 pose stick figures,下面一行顯示目標人物的模型輸出。
不同模型合成結果的比較
人人都能在幾分鐘之內,成為世界頂級舞者
總的來說,新的這個動作遷移模型能夠創建合理的、將任意長度的目標人物跳舞的視頻,其中他們的舞姿跟隨另一個跳舞者的輸入視頻。雖然我們的設置在很多情況下都可以產生可信的結果,但偶爾會遇到幾個問題。
從根本上說,作為輸入的 pose stick figures 依賴于噪聲姿態估計,這些估計不會逐幀攜帶時間信息。在姿勢檢測中丟失關鍵點,關鍵點位置不正確,會將錯誤引入到輸入中,并且這些失敗通常會延續到結果中,雖然我們嘗試了通過時間平滑設置來減輕這些限制。但即使我們試圖在設置中注入時間連貫性(temporal coherence),以及預平滑關鍵點,結果經常仍然會受到抖動的影響。
雖然我們的全局姿勢歸一化方法合理地調整了任何源對象的運動,使其與訓練中看到的目標人物的體型和位置相匹配,但這種簡單縮放和平移解決方案并未考慮不同的肢長和攝像機位置或角度。這些差異也會導致在訓練和測試時看到的運動之間存在更大的差距。
另外,2D 坐標和缺失檢測限制了在對象之間重新定位運動的方式,這些方法通常在 3D 中工作,需要有完美的關節位置和時間連貫運動。
為了解決這些問題,需要在時間上連貫的視頻生成和人體運動表示方面做更多的工作。雖然整體上 pose stick figures 產生了令人信服的結果,但我們希望在未來的工作中,通過使用為運動遷移特別優化的時間連貫輸入和表示來避免它所帶來的限制。
盡管存在這些挑戰,但我們的方法能夠在給出各種輸入的情況下制作吸引人的視頻。
難度被譽為最高的芭蕾舞黑天鵝48圈轉,可以換上自己的臉,想想還是有些小激動呢。
-
圖像
+關注
關注
2文章
1091瀏覽量
40891 -
遷移
+關注
關注
0文章
34瀏覽量
8021
原文標題:【超越CycleGAN】這個人體動態遷移技術讓白癡變舞王(視頻)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種在線式熒光法溶解氧傳感器原理
HarmonyOS Next 應用元服務開發-應用接續動態配置遷移保持遷移連續性
一種使用LDO簡單電源電路解決方案
一種簡單高效配置FPGA的方法
華納云:企業遷移到云端的主要原因是什么?
數學建模(2)--TOPSIS法
電磁線圈雙線繞法最簡單三個步驟
回路電流法和支路電流法的實質是什么
支路電流法和網孔電流法的區別是什么
電源紋波平行線法與靠測法的區別
rup是一種什么模型
plc是一種什么的電子裝置
一種簡單的降壓開關穩壓器TL2575HV-33-Q1and TL2575HV-05-Q1數據表






 工商網監
工商網監

評論