 基于K9K1G08U0M閃存芯片和FIFO實現星載大容量存儲器系統方案
基于K9K1G08U0M閃存芯片和FIFO實現星載大容量存儲器系統方案
無效塊空間飛行器的數據記錄設備是衛星上的關鍵設備之一。自20世紀90年代初起,各航天大國開始研制固態記錄器(Solid State Recorder,簡稱SSR)。由于SSR使用半導體存儲芯片作為存儲介質,所以其存儲密度高、無轉動部件、可靠性高、體積小、重量輕,因而逐漸成為空間飛行器的數據記錄器的主流方案。閃速存儲器(簡稱閃存)作為一種新興的半導體存儲器件,以其獨有的特點得到了迅猛的發展,其主要特點有:(1)具有非易失性,掉電時數據不丟失,可靠性高;(2)功耗小,不加電的情況下可長期保持數據信息;(3)壽命長,可以在在線工作情況下進行寫入和擦除,標準擦寫次數可達十萬次;(4)密度大、成本低,存儲單元由一個晶體管構成,具有很高的容量密度,且價格也在不斷降低;(5)適應惡劣的空間環境,具有抗震動、抗沖擊、溫度適應范圍寬等特點。由于閃存的這些特點,使它受到了航天領域研究人員的關注。20世紀90年代中期,Firechild公司就曾為F-16偵察星成功設計了SSR2,使用的主要存儲芯片就是閃存;國內的FY-2衛星也曾采用閃存作為該星的固態存儲器的存儲介質。雖然有這些成功的應用案例,但是閃存也存在一些明顯的缺點,如寫入速度較慢、使用過程中會出現無效塊等。本文將探討如何解決和突破這些缺點,并依此給出一個具體的系統實現方案。
1 閃存構成星載大容量存儲器的關鍵問題
1.1 寫入速度問題
目前閃存有多種技術架構,其中以NOR技術和NAND技術為主流技術3。NOR型閃存是隨機存取的設備,適用于代碼存儲;NAND型閃存是線性存取的設備,適用于大容量數據存儲4。NAND型閃存有一定的工業標準,具有一些統一的特點,現以三星公司的K9K1G08U0M型芯片為例進行介紹。該芯片容量為1Gbit,由8192個塊組成,每塊又由32個頁組成,一頁有(512+16)×8bit,該片的8位I/O總線是命令、地址、數據復用的。讀寫操作均以頁為單位,擦除操作則以塊為單位,寫入每頁的典型時間為200μs4,平均每寫一個字節約需400ns,即約20Mb/s。這樣的寫入(編程)速度對于要求高速的應用場合來講是難以滿足的,因此必須采取一定的技術措施。
1.1.1 并行總線技術
并行總線技術亦稱寬帶總線技術,即通過拓寬數據總線的帶寬實現數據宏觀上的并行操作。比如,由四片K9K1G08U0M型閃存芯片組成一個32位寬的閃存子模塊,它們共用相同的控制信號,包括片選信號、讀寫信號、芯片內部地址等。子模塊總是被看做一個整體而進行相同的操作,只是數據加載的時候是不同的數據。這樣,數據量將是使用單獨一塊芯片時的4倍,所以理論上速度也將是非并行時的4倍。
1.1.2 流水線技術
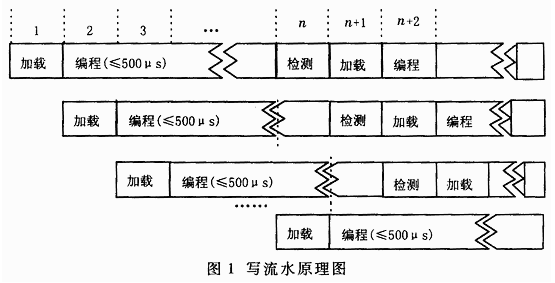
借鑒現今高性能計算機中的流水線操作原理,可在時間片上實現微觀并行。針對閃存的寫入速度慢的問題,可以對其進行流水處理。K9K1G08U0M型閃存的寫入操作可分為三個步驟:(1)加載操作,即完成命令、地址和數據的載入工作;(2)自動編程操作,即由閃存芯片自動完成編程操作,將載入到頁寄存器的數據寫到內部存儲單元的;(3)檢測操作,即在自動編程結束后檢測寫入的數據是否正確。如果不正確,需要重新編程;如果正確,繼續下一步的操作。寫流水原理圖如圖1所示。由圖1可以看到,流水線運行起來后,在任一時間片上總有若干小操作在同時進行,即在時間片上實現了復用,因此從整體上看速度將會提高。
1.2 無效塊的管理
三星閃存芯片在使用過程中會出現無效塊。無效塊是指一個塊中存在一個或多個無效位,其可靠性不能得到保證,必須加以標識和旁路(當然無效塊不會影響到其它塊的有效性)4并進行數據備份。為了對無效塊實現管理,可以建立一張無效塊到冗余區有效塊的映射表。映射表結構如圖2所示。映射原理如下: 開始是一張初始無效塊映射表,這張表可以根據三星公司技術手冊給出的算法建立起來。按照圖示的映射數據結構對整個存儲區進行編號,并根據這個編號對映射表進行排序。進行寫操作時,按照上述的映射結構將寫地址與映射表進行比較,比較到塊級即可。如果是無效塊,將待寫入的數據寫到被映射到的塊;如果不是,則直接寫入該塊。如果在寫某塊的某頁時出現編程錯誤,則將該塊添加進無效塊映射表(當編程出錯時就表明出錯頁對應的塊無效),同時從該出錯頁開始,將該塊后面的頁數據都寫入到對應的映射塊。這樣,在數據讀出時,可將讀地址與映射表比較,并且需要比較到頁級以確定每一頁的確切存放位置。如果該頁編程正確,則直接讀出;如果錯誤,則到被映射的塊的對應頁讀數據,并且該頁之后的頁也從被映射塊中讀數據。根據三星的技術資料,對無效塊進行讀操作是允許的,即對于編程出錯頁前面的那些編程正確的頁是可以正確讀出的,而對無效塊進行編程和擦除的操作是不推薦的,因為有時這些操作會使鄰近的塊也失效4。所以讀操作要查找到每一頁的對應存放位置,而寫操作只要查找到塊就行。查找時采用二分查找算法。擦除完后,將擦除出錯的塊也添加進無效塊映射表。無效塊映射表需要不斷維護和更新。


2.1.1 存儲區模塊
為了實現并行和流水技術,整個存儲區模塊按如下方式構成:由4片K9K1G08U0M型三星閃存芯片組成一個子模塊,8個子模塊組成8級流水的大模塊,而這個大模塊即是整個存儲區,其總容量為32Gbit。無效塊備份的冗余區可以設在每個子模塊內部,即從子模塊的每塊芯片中預留出一部分空間。這種模塊化管理的方式既便于系統擴展,又可以在不影響系統正常工作的情況下旁路已損壞的存儲塊。
2.1.2 接口模塊
系統與外部的接口有兩個。一是與CPU的接口,主要完成系統的初始化、外部命令和地址的輸入以及內部狀態參數的輸出,同時CPU 還要對存儲區完成管理:無效塊的管理、地址的譯碼和映射等;二是與外部高速數據源的接口,主要完成外部高速數據的接收和發送。這里選用了1394高速總線作為數據源總線。
2.1.3 數據緩沖模塊
這一模塊包括數據輸入FIFO、數據輸出FIFO和一個作為數據備份的SRAM。由于閃存的寫入速度比較慢,如果沒有數據緩沖區,外部的高速數據很有可能會丟失,而且數據回放時也需要一個緩沖區使內外的數據率匹配。考慮到編程出錯時需要重新加載數據,按照流水線的工作方式,如果不進行數據備份,可能會出現出錯時的數據丟失,因此選用了一個SRAM進行數據備份。當將輸入FIFO的數據寫入FLASH時,同時也將數據寫入到SRAM進行備份;當需要重新編程時,再從SRAM中將相應的備份數據重新寫入FLASH。
2.1.4 主控模塊
這一模塊完成整個存儲器系統的內部控制,是核心控制機構,連接著存儲區、數據緩沖以及外部接口三個模塊,完成它們之間的數據、命令、地址、狀態的相互傳遞、轉換和處理。主控模塊又分為三個子模塊,即存儲區控制子模塊、存儲區數據子模塊和1394接口控制子模塊,分別由三片FPGA(現場可編程邏輯陣列)完成。
3 系統的基本工作原理下面以閃存的寫(編程)操作為線索,闡述系統的基本工作原理。
3.1 寫操作的準備和啟動
1394高速總線上的串行數據通過一定的接口芯片變換成并行數據。當大容量存儲器接收到外部1394高速總線上的數據存儲握手信號時,1394接口控制子模塊利用握手信號產生一定的時鐘和控制信號,控制高速數據緩存入32位的輸入FIFO。當輸入FIFO的存儲量達到一次8級流水運行的數據量時,就向CPU發出中斷,申請寫操作啟動。
3.2 寫流水操作的加載和自動編程
存儲區的尋址采用內存尋址方式,即為FLASH存儲區分配一段內存空間,CPU象訪問內存一樣對其進行尋址,大小為2M,共21根地址線,其中高3位是子模塊選擇,選擇8級流水中的某一級;低18位是子模塊的每塊芯片的頁(行)地址。對于芯片內的列地址,由于向每一頁寫入數據時,總是從頁的起始處開始寫,即列地址(頁內編程起始地址)是固定的,因此可以直接由FPGA給出。當CPU接收到寫操作啟動的中斷申請時,給出寫操作命令,并進行地址譯碼。存儲區控制子模塊將CPU給出的命令和地址經過一定的邏輯轉換成片選、命令、地址及控制信號,依次對8級存儲子模塊進行片選并完成各級命令和內部地址的加載工作。然后再由存儲區控制子模塊產生一定的控制信號,控制輸入FIFO啟動對8級存儲子模塊的數據加載工作:首先對第一級進行片選,數據流由輸入FIFO經存儲區數據子模塊驅動后輸入第一級存儲子模塊,經過512個寫周期后(頁有效數據),完成對四片并行的FLASH芯片的頁加載,加載完成后由存儲區控制子模塊給出自動編程的起始指令10H,第一級子模塊的四片芯片就開始將加載到頁寄存器的數據寫入到芯片內部,進行自動編程工作。頁編程操作時序圖如圖4所示,這時它們的片選可以無效。然后使第二級片選信號有效,開始對第二級進行數據加載。依次下去,完成8級存儲子模塊的數據加載。

3.3 檢驗寫流水操作是否成功
第一級存儲子模塊在完成了數據加載后開始自動編程,待到8級的數據加載都完成后,其自動編程已接近尾聲。此時不斷檢測該級四片芯片的忙/閑端口,一旦它們都處于“閑”狀態時,說明自動編程都已經結束。這時由存儲區控制子模塊的控制邏輯產生片選信號,選通第一級存儲子模塊并發讀狀態命令70H,通過采樣四片芯片的I/O端口的“0”狀態來檢測編程是否成功,并將檢測結果鎖存進FPGA內部的寄存器;然后按同樣的方式對第二級存儲子模塊進行檢測,依次下去,直到“記錄”下8級存儲子模塊的編程成功與否的狀態信息后,向CPU申請中斷并將這些狀態值返回給CPU。CPU則根據這些狀態值更新無效塊映射表,并將無效塊映射到冗余區,對編程出錯的存儲子模塊重新編程。重新編程與正常編程的工作原理是一致的 只不過數據是由SRAM輸出給FLASH,且不能進行流水操作。
4 采用并行及流水技術后速率的估算根據上述實現方案以及三星閃存芯片的時序和各項性能指標參數,可以對采用四片并行和8級流水技術后的寫速率做一個理論上的大致估算,整個流水操作完成所需的時間應以最后一級流水完成的時間為準。估算方法如下:令FLASH芯片中一頁的數據量為a 并行操作的芯片數為b 流水的總級數為c,命令、地址和數據的加載時間為d 芯片自動編程時間為e,檢測時間為f,需重新編程的級數為g,正常寫速率為S1,重新寫入時的寫速率為S2,則:
S1=(a×b×c)/(d×c e f)
S2=(a×b×c)/[(d×c e f) (d e f)×g]
采用并行和流水技術前后的寫速率比較如表1所示。可以看出,采用該方案后的速率較采用前有了大幅度的提高。即使考慮到硬軟件的延遲及其它一些因素,這個速率的提升仍然是可觀的,說明這個設計方案是可行的。
表1 采用并行和流水技術前后的寫速率比較

隨著空間技術的不斷進步,要求空間飛行器上的大容量存儲器件朝著更大容量、更高速度、更低功耗、更小的重量和體積、更合理有效的存儲區管理以及更高可靠性的方向發展。從商業領域發展而來的閃存,存儲密度大、功耗小、可靠性高、體積小、重量輕且成本也在不斷降低。對于其寫入速度慢及存在無效塊等主要缺點,可以通過其自身工藝技術的不斷發展及融合其它領域的思想和技術,如本文所述的并行技術、流水線技術等得到解決,因而有著良好的應用前景。
責任編輯:gt
-
存儲器
+關注
關注
38文章
7518瀏覽量
164083 -
fifo
+關注
關注
3文章
389瀏覽量
43771 -
閃存芯片
+關注
關注
1文章
126瀏覽量
19636
發布評論請先 登錄
相關推薦
用PDIUSBD12和K9F5608U0A設計USB移動閃存
可兼容K9F1G08U0D型號的AFND1G08U3-CKAI
可兼容K9F2G08U0C的替代物料AFND2G08U3A-CKAI
K9F1G08U0CPCB0芯片相關資料下載
如何使用XCR3032實現大容量FLASH存儲器的接口設計?
閃速存儲器K9F1208U0M在圖像采集系統中的應用
超大容量存儲器K9F2G08U0M及其在管道通徑儀中的應用
K9F1G08X0C_128M x 8 Bit NAND Flash Memory


微雪電子K9F1G08U0E NandFlash存儲模塊簡介






 工商網監
工商網監
評論