 用Keras創造一個卷積神經網絡來識別神奇寶貝妙蛙種子的填充玩具
用Keras創造一個卷積神經網絡來識別神奇寶貝妙蛙種子的填充玩具
用Keras創造一個卷積神經網絡來識別神奇寶貝妙蛙種子的填充玩具
簡 介
本文內容是構建完整端對端圖像分類+深度學習應用系列的第二部分,你將會了解如何在你自己的數據庫中建立、訓練并評估一個卷積神經網絡。
為了讓這個系列輕松、愉快,我決定實現我童年的一個夢想,那就是構造一個神奇寶貝圖鑒。神奇寶貝圖鑒是于神奇寶貝(一部很火的動畫片、電子游戲和集換卡系列)世界中的一個設備(我曾經是以及現在還是神奇寶貝的大粉絲)。
如果你對于神奇寶貝不了解,你可以把神奇寶貝圖鑒想象成一個可以識別神奇寶貝(一個長得像動物、存在于在神奇寶貝世界的生物)的智能手機app。
當然你也可以換成你自己的數據,我只是覺得很有趣并且在做一件很懷舊的事情。
想要知道如何在你自己的數據庫中用Keras和深度學習訓練一個卷積神經網絡,繼續往下讀就行了。
目 錄
1.Keras和卷積神經網絡
我們的深度學習數據庫
卷積神經網絡和Keras項目的結構
Keras和CNN結構
完成我們的CNN+Keras訓練腳本
用Keras訓練CNN
創造CNN和Keras訓練腳本
用CNN和Keras分類圖片
該模型的局限性
我們能否使用這個Keras深度學習模型建一個REST API?
Keras和卷積神經網絡
在上周的博文中,我們學習了如何能快速建立一個深度學習的圖像數據庫——我們使用了博文中的過程和代碼來收集、下載和組織電腦上的圖像。
既然已有下載并組織好的圖像,下一步就是在數據上訓練一個卷積神經網絡(CNN)。
我將會在今天的博文中向你展示如何用Keras和深度學習來訓練你的CNN。下周將要發布這個系列的最后一部分,將會向你展示你如何僅用幾行代碼將你訓練好的Keras模型應用在一個智能手機(特別是iPhone)app上。
這個系列的最終目的是幫助你建立一個能夠運行的深度學習app——用這個系列的文章作為發靈感啟發,并且開始幫助你建立自己的深度學習應用。
現在讓我們開始用Keras和深度學習訓練一個CNN。
我們的深度學習數據庫
圖1:神奇寶貝深度學習數據庫中的樣本示意圖。它展示了神奇寶貝的每個種類。正如我們所見,數據庫的內容范圍很大,包含了插畫、電影/電視節目截圖、模型、玩具等。
我們深度學習的數據庫有1191個神奇寶貝)的圖片。
我們的目標是用Keras和深度學習訓練一個卷積神經網絡來識別和分類這些神奇寶貝。
我們將要識別的神奇寶貝包括這幾種:
妙蛙種子(234張圖片)
小火龍(238張圖片)
杰尼龜(223張圖片)
皮卡丘(234張圖片)
超夢(239張圖片)
每個種類的訓練圖片的示意圖在圖1中可見。
正如你所見,我們的訓練圖片包括:
電視節目和電影中的截圖
集換卡
模型
玩具
粉絲的畫作和藝術表達
我們的CNN將從這些涵蓋范圍很廣的使N一大堆圖片中識別出5種神奇寶貝。——而且我們將會看到,我們可以達到97%的分類準確率!
卷積神經網絡和Keras項目的結構
今天的項目有很多活動部件?。我們現在從回顧項目的目錄結構開始。
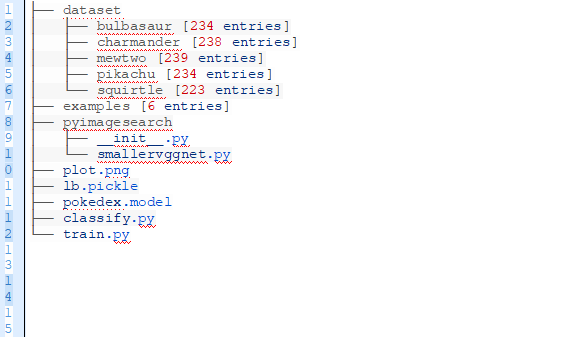
有3個目錄:
dataset:包含了5個種類,每個種類有自己單獨的子目錄,這使得分析種類標簽較為容易。
examples:包含了我們將要用來測試CNN的圖片。
pyimagesearch模塊:包含了SmallerVGGNet模型種類(在這片文章的后面將會用到)。
根目錄下有5個文件:
plot.png:訓練腳本運行之后產生的的訓練/測試準確率和失敗率的圖像
lb.pickle:LabelBinarizer序列化的目標文件——包含個從種類指標到種類名稱的查找機制
pokedex.model:這是我們序列化的Keras卷積神經網絡的模型文件(即權值文件)
train.py:我們將用這個腳本來訓練我們的Keras CNN,劃分準確率/失敗率,然后將CNN和標簽二值序列化于磁盤上。
classify.py:測試腳本
Keras和CNN結構
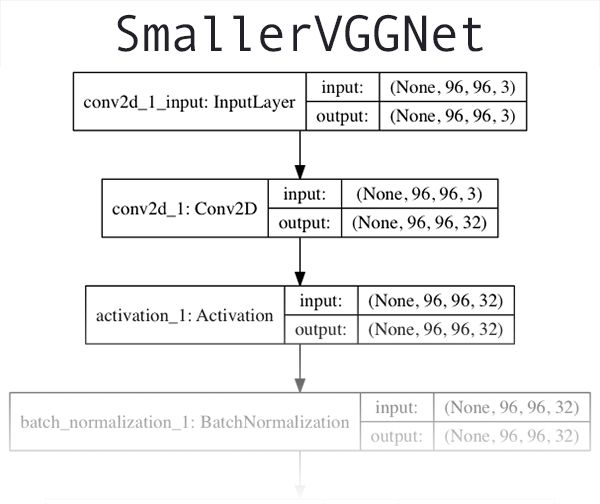
圖2:一個我稱為“SmallerVGGNet”的VGGNet類神經網絡,它將被用于和Keras一起訓練一個深度學習分類器。
我們將要使用的CNN結構是VGGNet網絡的一個小而緊湊的變體。Simonyan和Zisserman在他們2014年的論文Very Deep Convolutional Networks for Large Scale Image Recognition中引入。
VGGNet類結構有這些特點:
在增加深度方面只用3×3個互相交疊的卷積層。
使用最大化池化來減少體積。
相比于softmax分類器,優先網絡最后完全連接的層。
我假設你已經安裝了Keras并且在你的系統上配置好了它。如果沒有,這里有一些關于深度學習構建環境配置指導的鏈接:
使用Python為深度學習配置Ubuntu
使用Python建立Ubuntu 16.04 + CUDA + GPU進行深度學習
配置macOS以便使用Python進行深入學習
如果你想要跳過配置深度學習環境,我推薦你用以下幾個云上預先配置好的實體個:
Amazon AMI用于使用Python進行深度學習
微軟的數據科學虛擬機(DSVM)用于深度學習
現在讓我們開始執行更小版本的BGGNet,即SmallerVGGNet。在pyimagesearch模塊中創建一個命名為smallervggnet.py的新文件,插入以下代碼:
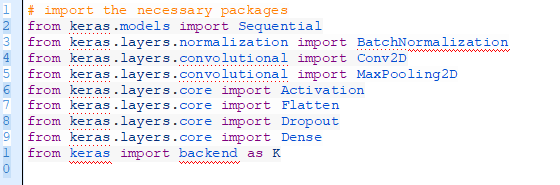
首先我們輸入模塊——注意到它們都來自于Keras,每個都在Deep Learning for Computer Vision with Python課程中有涉及到。
注意:在pyimagesearch中創建__init__.py文件,這樣Python就知道這個文件夾是一個模塊。如果你對__init__.py這個文件或者如何用他們創建模塊不熟悉,不要擔心,用本文最后的“下載”部分來下載我的目錄結構、源代碼和數據庫+圖片樣例。
在此,我們定義SmallerVGGNet類:
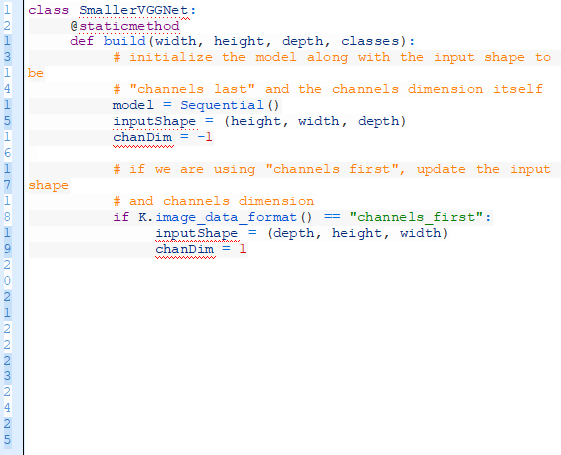
我們構建的方法需要4個參數:
width:圖像的寬度
height:圖像的高度
depth:圖像的深度——也叫做隧道數
classes:數據庫中的種類數(這將會影響模型的最后一層)。
在這篇博文中,我們用到神奇寶貝的5個種類,但是如果你為每個種類下載了足夠多的樣例圖片,你可以使用807個神奇寶貝種類!
注意:我們將會使用96*96、深度為3的輸入圖片。請記住這個,因為我們已經解釋了當它穿過網絡輸入的體積的空間參數。
因為我們使用TensorFlow的編譯器后端,我們用頻道最后的數據順序來安排輸入形狀,但是如果你想使用頻道最先(Theano等),那么它將在23-25行被自動處理。
現在,我們開始在模型中添加層:
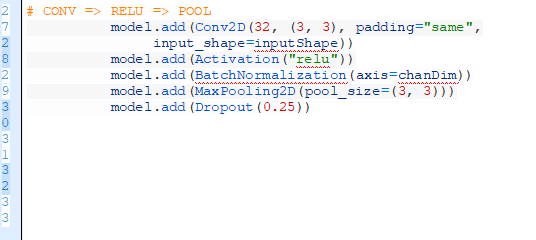
以上是我們第一個CONV=>RELU=>POOL塊。
卷積層有3×3個核的32個過濾器。我們在批規范化后使用激活函數RELU。POOL層有3×3的POOL大小來減少圖片的空間參數,從96×96變成32×32(我們將使用96×96×3的輸入圖片來訓練網絡)。
如你在代碼中所見,我們將網絡中使用丟棄這個功能。丟棄的工作機制是隨機斷開從當前層到下一層之間的節點作。這個在訓練批中隨機斷開的過程能夠在模型中自然引入丟棄——層中沒有一個單獨的節點是用于預測一個確定的類、目標、邊或者角。
從這里在使用另外一個POOL層之前加入(CONV=>RELU)*2層。
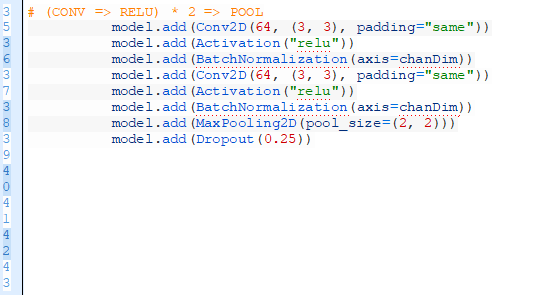
堆疊多個CONV和RELU層在一起(在減少體檢的空間尺寸之前),這樣們能夠獲得更豐富的特征。
注意:
增加過濾器尺寸,從32到64。網絡越深,體積的空間尺寸越小,我們就能學習更多過濾器。
我們減少最大池化尺寸,從3×3變成2×2,以保證我們不會太快地減少空間尺寸。
這一階段再次使用丟棄段。
現添加另外一組(CONV=>RELU)*2=>POOL:
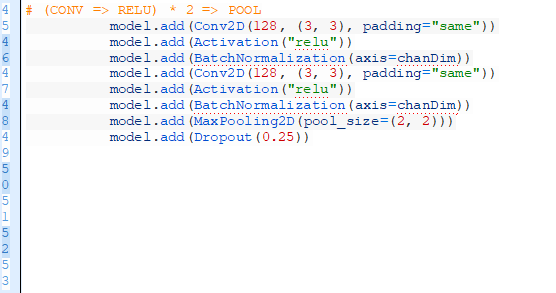
注意到我們已經將的過濾器的尺寸增加到128。節點的25%再次被丟棄以減少過度擬合。
最后,我們有一組FC=>RELU的層和一個softmax分類器:
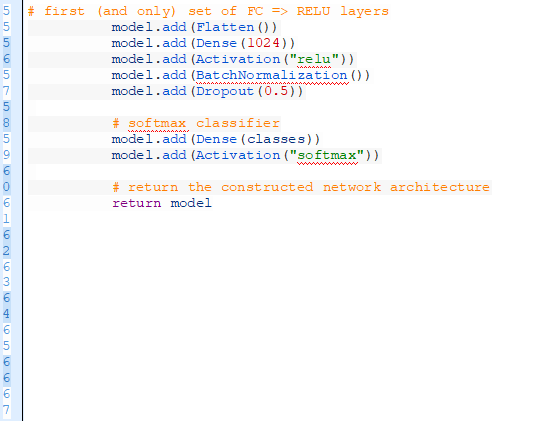
完全連接的層由具備矯正線性單元激活器和批規范化的Dense(1024)來指定。
最后再操作一次丟棄次。這次注意到,在訓練時,我們丟棄了50%的節點。一般情況下,在我們的完全連接層你將使用一個40-50%丟棄率的丟棄和一個低得多的丟棄率,通常是在之前的層10-25%丟層(如果有某個丟棄在所有層都使用)。
我們用softmax分類器來完善這個模型,該分類器可為每個種類反饋預測概率型。
在這個部分的一開始的圖2是一個SmallerVGGNet前幾層的網絡結構的圖片。如果想看完整的SmallerVGGNet的Keras CNN結構,可以進入這個鏈接
https://www.pyimagesearch.com/wp-content/uploads/2018/04/smallervggnet_model.png。
執行我們的CNN+Keras訓練腳本
既然SmallerVGGNet已經完成了,我們可以用Keras來訓練卷積神經網絡了。
打開一個新的文件,命名為train.py,并且加入下面的代碼,我們在此加載需要的包和庫。
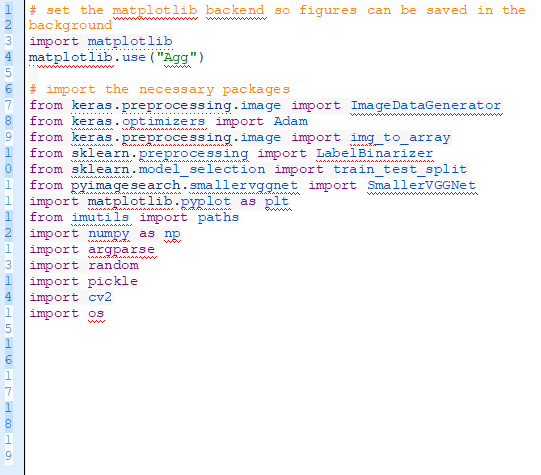
我們將使用“Agg” matplotlib后端將圖片保存在背景中。(第三行)
ImageDataGenerator類將被用于數據增加,這是一個用已經存在于我們數據庫的圖片并且使用隨機變換(旋轉、剪切等)來闡釋新的訓練數據的技巧。數據增加能夠防止過擬合。
第七行載入了Adam優化器,一個用來訓練網絡的優化器。
LabelBinarizer(第九行)是一個重要的類,這個類使得我們能夠:
輸入一系列種類的標簽(如,代表了在數據庫中人類可以閱讀的種類標簽的字符串)
把種類標簽轉化成一個獨熱編碼向量。
讓我們能夠取一個Keras CNN中的整數種類標簽預測,并且把它轉化為一個人類可讀的標簽。
在PyImageSearch博客上我經常被問到如何將一個種類標簽字符串轉換成一個整數及其反向操作。現在你知道方法就是使用LabelBinarizer類。
train_test_split函數(第10行)用于創建訓練和測試劃分。同樣注意到第11行中載入SmallerVGGNet——這是我們上一節中已經完成了的Keras CNN。
這個博客的讀者很熟悉我自己的imutils安裝包。如果你還沒有安裝/升級它,可以這樣安裝它:

如果你正在用一個虛擬的Python環境(正如在PyImageSearchg博客中我們總是做的那樣),確保你在安裝/升級imutils之前使用workon命令來進入虛擬環境級前。
現在,讓我們分析一下命令行的語句:
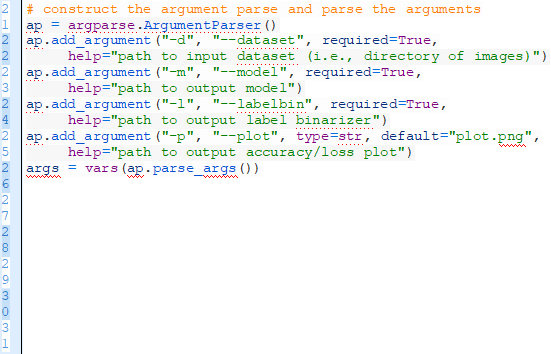
為了我們的訓練腳本,需要使用三個命令行語句:
--dataset:這是輸入數據庫的路徑。數據庫在dataset的目錄中,這個目錄下面有代表每個種類的子目錄。在每個子目錄中,有大約250個神奇寶貝的圖像。請看開頭的目錄結構。
--model:這個是輸出模型的路徑——這個訓練腳本將會訓練模型并且把它輸出到磁盤上。
--labelbin:這是輸出標簽二值器的路徑——正如你將看到,我們從dataset目錄的名字中提取種類標簽并建立標簽二值器。
我們還有一個可選的語句“—plot”。如果你不特別指定一個路徑/文件名,那么plot.png這個文件將被放在目前的工作目錄中。
你不需要修改第22-31行來提供新的文件目錄。命令行語句將在runtime被執行。如果你不明白,那么請回顧我的命令行語句那篇博文。
既然我們已經寫完了命令行語句,現在開始一些重要的變量:
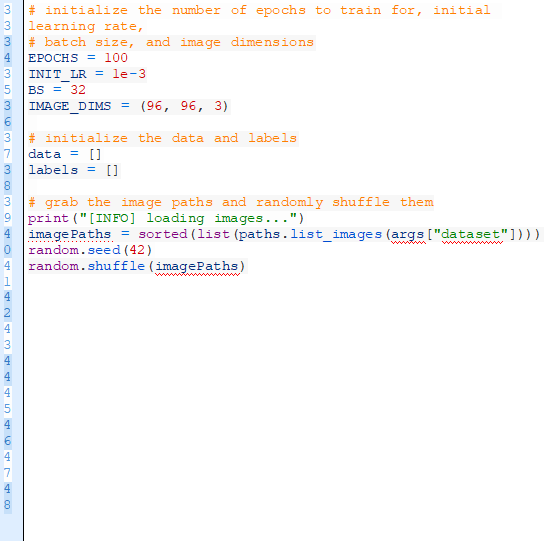
第35-38行初始化用于訓練Keras CNN的重要變量。
EPOCHS:我們將要訓練的網絡總epoch次數。(即,次網絡“看見”訓練例子并從中學習模式的次數)
INIT_LR:開始的學習率——1e-3是我們將用于訓練網絡的Adam優化器的初始值。
BS:我們將輸入很多捆圖片進入網絡進行訓練。在每個epoch有很多捆,BS值控制了捆的大小。
IMAGE_DIMS:我們使用輸入圖片的空間大小。輸入圖片是96×96像素,并有3個通道(紅綠藍)。我也注意到把SmallerVGGNet設計成處理96×96的圖片。
我們初始化兩個列表——data和labels,他們是預先處理過的圖片和標簽。
第46-48行得到所有圖片的路徑并且隨機切換它們。
從這,我們循環一下每個imagePahts:
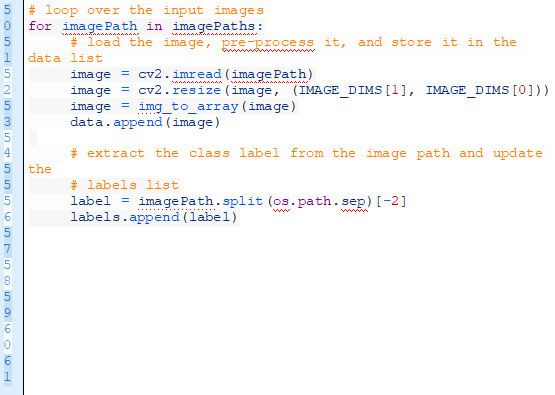
在第51行我們循環imagePaths然后加載圖片(第53行),并且調整它的尺寸使之適應我們的模型(第54行)。
現在更新data和labels列表。
使用Keras img_to_array函數來將圖片轉換成一個兼容Keras的數組(第55行),接著把圖片貼在我們的data列表上(第56行)。
對于labels列表,我們從第60行的文件路徑上提取label并把它加入列表(第61行)。
為什么這個種類標簽分析過程有效?
到我們有意創建了dataset目錄結構來得到下以下格式式

用第60行的路徑分離器,我們可以將分離路徑成一個數組,然后抓取從第二個到最后一項放進列表——種類標簽。
如果這個過程讓你困惑,我建議你打開Python的殼文件,然后通過分離操作系統的路徑分離器的路徑來探索imagePath這個例子。
我們繼續。一些事情在下面的代碼塊中發生了——更多的預處理、二值化的標簽和分割數據。
我們首先把data數據轉化成一個NumPy數組,然后調整像素密度到[0,1]的范圍(第64行)。我們也在第65行把一個列表中的labels轉換到一個NumPy數據。一個表示data矩陣的大小(以MB為單位)的信息出現了。
然后,我們用scikit-learn的LabelBinarizer二值化標簽nr(第70和71行)。
隨著深入學習或任何機器學習,通常的做法是進行訓練和測試的劃分。在第75和76行,我們創建了一個對于數據的80/20的隨機分劃。
接著,我們創建的圖像數據放大器項目:
既然我們在處理受限的數據點(每個種類<250個圖像),我們可以利用訓練過程中的數據給模型帶來更多圖像(基于已經存在的圖像)進行訓練。
數據放大應該是每個深度學習從業者的必備工具。
我們在第79-81行初始化ImageDataGenerator。
從這里開始我們編譯模型并且開始訓練。
在第85和86行,我們初始化96×96×3輸入空間大小的Keras CNN。我將再重申一遍這個問題,因為我很多次被問到這個問題——SmallerVGGNet被設計成接受96×96×3的輸入圖片。如果你想要用不同的空間尺寸,你也許需要:
要么減少較小圖片的網絡深度
要么給較大圖片增加網絡深度
不要瞎改代碼。先考慮較大或較小圖片的含義!
我們用到有學習速度衰變的Adam優化器(第87行),然后用多種的交叉熵編譯我們的模型,因為我們有>2個種類(第88和89行)。
注意:如果只有兩個類別,你應該用二元的交叉熵作為遺失函數。
從這里開始,我們使用Keras fit_generator方法來訓練網絡(第93-97行)。要有耐心——這會花一些時間,這取決于你用CPU還是GPU來訓練。
一旦Keras CNN完成了訓練,我們將會想要保存(1)模型和(2)標簽二值化,因為當我們用網絡測試不在訓練/測試集中的圖片時,我們需要從磁盤上加載它們片。
我們保存模型(第101行)和標簽二值化(第105-107行),這樣我們就能在之后的classify.py腳本中使用它們。
標簽二值化文件包含了種類指數和人類刻度的種類標簽詞典。其目的是讓我們不必把我們使用Keras CNN腳本中的種類標簽用一個固定值代表。
最終,我們可以劃分出訓練和失敗準確率。
我選擇保存我的圖片到磁盤上(第121行)而不是展示它,有兩個原因:
我在使用一個沒有顯示器的云端服務器,
我想要確保我不會忘記保存這些圖片。
用Keras訓練CNN
現在我們準備好訓練神奇寶貝圖鑒CNN。
確保閱讀了這篇博客的“下載”部分以下載代碼+數據。
然后執行下面的語句來訓練模型。確保正確提供命令行語句。
查看訓練腳本的結果,我們發現Keras CNN獲得:
訓練集上的96.84%的分類準確率
測試集上的97.07%的準確率
訓練失敗和準確率如下:
圖3:用Keras訓練的神奇寶貝圖鑒深度學習分類器的訓練和驗證失敗/準確率片s
正如你在圖3中所見,我訓練了這個模型100遍來達到在過擬合限制下的低失敗率。如果有更多的訓練數據,我們就能得到更高的準確率。
創建CNN和Keras訓練腳本
既然我們的CNN已經被訓練了,我們需要完成一個腳本來分類不在我們訓練/測試集中的圖片。打開一個新的文件,命名為classify.py,并加入以下代碼:
首先載入必要的包(第2-9行)。
從這里開始分析命令行語句。
我們有三個必要的命令行語句需要分析:
model:我們剛才訓練的模型的路徑。
labelbin:標簽二值化文件的路徑。
image:我們輸入圖片文件的路徑。
這三個命令在第12-19行。記住,你不需要修改這些命令——我將會在下一節告訴你如何運用runtime提供的命令行語句運行這個程序在的。
接著,我們加載并預處理圖片。
現在我們加載輸入image(第22行),備份命名為做output,以備展示。(第23行)
然后用訓練時一樣的方法預處理image(第26-29行)。
這時,加載模型和標簽二值化,然后分類圖片:
為了分類圖片,我們需要模型和標簽二值化。我們在第34和35行加載這兩者。
接著,我們分類圖片然后創建標簽(第39-41行)。
剩下的代碼塊是為了展示:
在第46和47行,我們從filename中提取神奇寶貝的名字并且把它和label比較。correct變量將會根據結果顯示”correct”或”incorrect”。顯然這兩行包含了這樣的假設,即你輸入的文件有一個文件名是它真正的標簽。
我們進行如下步驟:
附加百分比的概率和”correct”/”incorrect”的文本進了類標簽(第50行)。
調整output圖片的尺寸使得它適合屏幕(第51行)。
在output圖片上畫標簽的文字(第52和53行)。
展示output圖像并且等待按鍵來退出(第57和58行)。
用CNN和Keras分類圖片
現在準備運行classify.py腳本!
確保你已經從“下載”部分(在這篇博文的下面)獲得了代碼+圖片。
一旦你已經下載并且解壓了壓縮文件,就把它放入這個項目的根目錄中,并且跟著我從一個小火龍的圖片開始。注意到我們已經提供了三個命令行語句來執行這個腳本:
圖4:用Keras和CNN正確分類了一個輸入圖片
現在用尊貴和兇猛的布隆巴爾口袋妖怪填充玩具來考驗我們的模型。
圖5:Keras深度學習圖片分類器再次正確分類輸入圖片。
嘗試一個超夢(一個基因改造過的神奇寶貝)的玩具立體模型。
圖6:在CNN中使用Keras、深度學習和Python我們能夠正確分類輸入圖片。
如果一個神奇寶貝圖鑒不能識別出皮卡丘,那它有什么用呢!
圖7:用Keras模型我們可以識別標志性的皮卡丘。
現在嘗試可愛的杰尼龜神奇寶貝。
圖8:用Keras和CNN正確分類圖片。
最后,再次分類有火尾巴的小火龍。這次他很害羞并且有一部分藏在了我的顯示器下面。
圖9:最后一個用Keras和CNN正確分類輸入圖片的例子。
這些神奇寶貝中的每一個都和我的新神奇寶貝不符合。
目前,有大概807種不同種類的神奇寶貝。我們的分類器被訓練用來分類5種不同的神奇寶貝(為了簡單的目的)。
如果你想要訓練一個分類器來識別神奇寶貝圖鑒中的更多神奇寶貝,你將要更多每個種類的更多的訓練圖片。理想的情況下,你的目標應該是在每個你想要識別的種類里有500-1000個圖片。
為了獲得訓練圖片,我建議你使用微軟必應的圖片搜索API,比谷歌的圖片搜索引擎更好用。
這個模型的限制
這個模型的主要限制是很少的訓練數據。我測試過不同的圖片,有時這個分類器是不準確額。這時,我仔細檢查了輸入圖片+網絡然后發現圖片中最顯著的顏色很嚴重地影響了分類器。
比如,一個有很多的紅色或者黃色的圖片很可能讓它被識別成小火龍。類似的,一個有很多黃色的圖片通常被識別成皮卡丘。
這一部分是因為我們的輸入數據。神奇寶貝顯然是虛假的并且沒有它們顯示中的圖片(除了立體模型和毛絨玩具)。
我們的圖片大多數來自于一個粉絲的繪畫,或者電影/電視的截圖。此外,我們每個種類只有很少的數據(225-250個圖片)。
理想的情況下,在訓練一個卷積神經網絡時我們每個種類有至少500-1000個圖片。記住這個當你處理你自己的數據時。
我們能否使用Keras深度學習模型作為一個REST API?
如果你想用這個模型(或其它深度學習模型)作為一個REST API,我寫過三個博文來幫助你開始:
創建一個簡單的Keras+深度學習REST API
一個可拓展的Keras+深度學習REST API
深度學習和Keras、Redis、Flask、Apache一起使用
總 結
在今天的博文中你學習了如何用Keras深度學習庫構建一個卷積神經網絡s。
我們數據集的收集方法在上周的博文中已經講過了。
我們的數據集包含5種神奇寶貝的1191個圖片。
用卷積神經網絡和Keras,我們能獲得97.07%的準確率。這是很厲害的,因為:
我們數據集不大
我們網絡中的參數量少
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100960 -
深度學習
+關注
關注
73文章
5510瀏覽量
121345 -
keras
+關注
關注
2文章
20瀏覽量
6089
原文標題:用Keras和CNN建立模型,識別神奇寶貝(附代碼)
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論