 Web使用挖掘中的數據預處理模塊、實現方法及發展前景
Web使用挖掘中的數據預處理模塊、實現方法及發展前景
1 Web挖掘
Web挖掘是指運用數據挖掘技術從Web頁面中發現和抽取信息的過程。Web挖掘又分為3種類型:Web使用挖掘、Web結構挖掘和Web內容挖掘。Web使用挖掘的數據源主要是Web日志文件,通過挖掘Web日志可以了解用戶的訪問模式。基于用戶的訪問模式,可以對網站的鏈接進行相應的修正;了解用戶興趣,為用戶定制個性化的頁面;進行用戶分類,對不同的用戶實行不同的促銷策略,提高投資回報率;向用戶推薦Web頁面等。
2 數據預處理
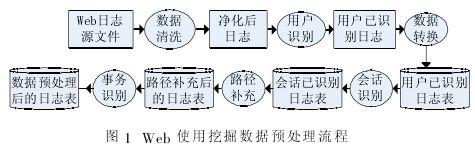
數據預處理是Web使用挖掘的第一個環節。預處理的對象是Web 日志文件。由于Web 日志文件的格式是半結構化的,且日志中的數據不夠完整,因此需要對Web日志文件進行預處理,將其轉化為易于挖掘的、具有良好格式的數據。數據預處理結果的好壞將直接影響后面所進行的事務識別、路徑分析、關聯規則挖掘和序列模式發現等環節的效果。Web使用的挖掘流程如圖1所示,包括預處理、模式挖掘、模式分析和可視化。本文將重點研究其中的數據預處理模塊。
數據預處理主要包括數據清理、用戶識別和會話識別等幾個步驟。
2.1 數據清理
數據清理的任務就是刪除那些和挖掘目的無關的數據,避免無關數據對后續步驟的影響。由于網頁中存在大量的圖片(如GIF、JPEG、JPG等),當用戶訪問網頁時,其中的圖片都會作為單獨的記錄存在于日志文件中。對于大多數挖掘任務來說它們都是可以忽略的(但如果網站是專門提供圖片的則要另外考慮)。刪除這些記錄可以減少后續步驟所要處理的數據量,提高處理速度,同時還可以減少無效數據對挖掘過程的影響。
例如,取自天津大學網站003年3月1日至3月7日一周的日志文件,共105MB,進行數據清理之前共有記錄1 174 093條,按照上述方法清理之后剩余記錄為378 747條,由此可以充分說明數據清理的作用。
2.2 用戶識別
用戶識別就是從日志文件中識別出有哪些用戶訪問了網站,以及每個用戶訪問了哪些網頁。下面給出關于用戶(User)的定義。
定義1 用戶
用戶的定義為User=〈UserID,User_IP,User_Referer_Page,User_Agent〉。UserID是識別出的用戶的標識,User_IP、User_Referer_Page和User_Agent分別代表用戶的IP地址、訪問過的頁面以及用戶所用電腦的操作系統、瀏覽器版本信息。通過以上各項可以惟一確定用戶。
已經注冊的用戶可以很容易被識別出來。而事實上,有許多用戶未經注冊,還有大量用戶使用代理服務器上網,或多個用戶共用一臺電腦。此外防火墻的存在以及一個用戶使用不同的瀏覽器等,都增加了用戶識別難度。當然可以采用Cookies來追蹤用戶的行為,但是考慮到個人隱私問題,許多用戶的瀏覽器是禁用Cookies的,因此有必要考慮其他方法解決該問題。
對于使用同一臺電腦或者使用相同代理上網的多名用戶的區分,可以借助于網站的拓撲圖檢測是否此次訪問的頁面可以從上次訪問的頁面直接到達,如果不能,則很有可能是多名用戶共用一臺電腦或者一個代理。但是該方法主要涉及的是網頁拓撲結構的問題,沒有考慮單個用戶使用多個代理或者多臺電腦的情況。此外,還可以通過基于導航模式(Navigation Patterns)的用戶會話自動生成技術來識別用戶。這種方法所側重的是網頁的分類和彼此之間的鏈接關系。所以上面二種方法在用戶識別的過程中只是考慮了個別的影響因素,只能部分解決用戶不確定的問題,沒有充分考慮所有可能出現的情況。本文給出了一種新的用戶及會話識別算法(User and Session IdentifICation Algorithm,USIA)。該算法綜合考慮用戶IP(User_IP)、網站的拓撲圖、參考網頁(Referer)和Agent來識別出單個用戶。在考慮算法的精度和效率的前提下盡可能用更多的影響因素來識別用戶,具有較好的準確性和可擴展性。
2.3 會話識別
一個會話就是指用戶在一次訪問過程中所訪問的Web頁面序列。下面給出了關于會話的定義。
定義2 會話
會話的定義為Session=〈Si,UserID,Times,Timee,[(url1,time1),(url2,time2)……(urlk,timek)]〉。Si是Session標識,UserID是用戶識別過程所識別出的用戶的標識,Times是會話的初始時間,Timee是會話的結束時間,urlk是此次會話所訪問的頁面urls,timek是頁面urlk被訪問的時間。
一個日志文件的時間跨度是不確定的,一名用戶可能多次訪問同一站點。會話識別的目的就是將用戶每次的訪問頁面劃分到不同的會話當中,這樣以會話為基本單元將有助于模式的挖掘和分析。
區分一個用戶的2個不同會話的最常用的方法是:規定一個超時值(常用的是30分鐘),如果對2個頁面的請求時間間隔超過了這個預先設定的閾值,則可以看作用戶又開始了一次新的會話。由于將超時值預置為30分鐘,并且經過了大量實際應用的檢驗,證明該方法簡單易行,因此本文采用了該方法。
對于識別出的用戶和會話需要存儲起來,以備后續步驟進行挖掘時使用。此處定義了Cube作為用戶和會話的數據存儲格式。
定義3 Cube
Cube是算法USIA識別出的用戶和會話的存儲方式,定義為Cube=〈Si,UserID,User_IP,[(url1,time1), (url2,time2)……(urlk,timek)]〉。其中Si和UserID的含義同定義2,User_IP是用戶的IP地址,urlk是此次會話所訪問的頁面Urls,timek是頁面urlk被訪問的時間。
2.4 USIA算法
2.4.1 USIA算法過程
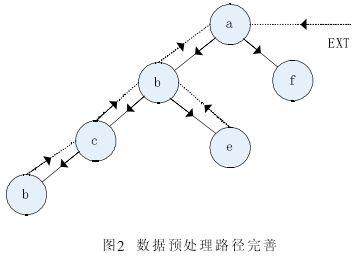
2.4.2 USIA算法的優點如下:
(1)準確度高:克服了傳統方法中只采用IP地址區分訪問者所導致的識別精度不高的缺點。該算法綜合考慮用戶IP、網站的拓撲圖、參考網頁和Agent來識別單個用戶。在考慮算法的精度和效率的前提下盡可能用更多的影響因素來識別用戶,具有較好的準確性和可擴展性。
(2)效率高:在一個算法中實現了用戶識別和會話識別,克服了將用戶識別和會話識別分開單獨進行所引起的效率低的缺點。
(3)良好的數據存儲格式:對于識別出的用戶和會話,算法USIA構造出動態數據立方體存放用戶ID、用戶IP、用戶Url、用戶訪問時間,避免了大量存儲空間的浪費。
用戶和會話的存儲方式示意圖如圖3所示,縱軸表示識別出的用戶和會話,其中n表示總的用戶數,k表示某用戶的第k個會話,不同的用戶會話采用不同的UserID來表示,如1-1,2-1,3-1,……n-k.同一用戶可能有多個不同的會話,如圖中用戶3有2個會話3-1和3-2.
IPn表示第n個用戶的IP地址。橫軸表示在一次單獨的會話中用戶所訪問的頁面Url序列,該序列按時間先后順序排列,如圖中的字母A、B、C、D、E、F等表示頁面的Url.時間軸存放用戶訪問某個頁面時的時間,如用戶1訪問頁面A的時間為2003-03-01 10:21:36.這樣存放對于數據預處理之后的序列模式挖掘很有益。圖中的數字“12”表示用戶1在一次單獨的會話中總共訪問了12個頁面。這樣便于用動態數據立方體存儲用戶識別和會話識別的結果,為下一步提高模式挖掘的效率和準確性奠定了基礎。
USIA算法存在的不足:在判定當前用戶和已經識別出的用戶是否為同一個訪問者的過程中,需要考慮的因素較多,導致算法的運算速度降低。但是考慮到對于Web日志文件的挖掘分析并不是實時的,運算速度并不是首要考慮的因素,因此權衡識別精度和運算速度是值得的。
3 試驗結果
以天津大學網站(http://www.tju.edu.cn/)2003-03-01至2003-03-07一周的Web日志文件作為試驗的對象。該日志文件共105MB,經數據清理后剩余有效記錄為378 747條。
為了對比不同的用戶識別方法對用戶識別精度的影響,針對數據清理后剩余的378 747條有效記錄分別進行了4組試驗,每組試驗采用不同的識別方法。其中方法4為算法USIA.
方法1:只根據IP地址識別用戶,識別出18 706名用戶。
方法2:根據IP地址和參考網頁識別出19 528名用戶。
方法3:根據IP地址、參考網頁和Agent識別用戶,識別出21 655名用戶。
方法4:根據IP地址、參考網頁、Agent和網站拓撲結構識別用戶,識別出22 173名用戶。
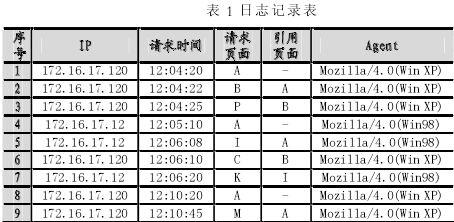
由實驗結果可以看出,采用USIA算法共識別出用戶22 173名,如果僅用IP地址來識別用戶則只能識別出18 706名用戶,而會有22173-18706=3467名用戶被忽略,可見USIA算法擁有更高的用戶識別精度。從營銷以及客戶服務的角度看,如果這3 467名用戶被精確地識別出來,對每個用戶實行個性化定制,有可能使其中相當比例的用戶轉化為網站的忠誠顧客,從而給公司帶來更多收益。
4 總結
本文討論了Web使用挖掘中的數據預處理模塊,側重于預處理的具體實現,提出的USIA算法能夠很好地同步識別出用戶和會話,比一般的識別算法有更好的識別精度。目前國外針對Web使用挖掘的研究有很多,國內也有一些院校及研究機構在進行這方面的研究工作,但是有影響的并不多。考慮到Web使用挖掘所具有的極大的商業價值和廣闊的應用前景以及相關技術還具有很大的提升空間。
Web挖掘是一個有著巨大發展前景的研究領域。Web使用挖掘能夠從Web服務器日志中抽取用戶感興趣的潛在的有用模式和隱藏的信息,優化站點結構,以使得教育資源合理配置,并能根據用戶的個性特征主動推送感興趣內容,提高個性化水平。因此將會有更多的研究力量投入到這個領域,研究的重點將會在繼續關注模式發現的基礎上更多地趨向于模式分析、分析結果的可視化以及人機交互等方面。
-
數據
+關注
關注
8文章
7032瀏覽量
89039 -
Web
+關注
關注
2文章
1263瀏覽量
69483 -
電腦
+關注
關注
15文章
1706瀏覽量
68846
發布評論請先 登錄
相關推薦
嵌入式系統發展前景?
國產FPGA的發展前景是什么?
數據挖掘在電子商務推薦系統中的應用研究
STATCOM發展前景怎么樣啊?
通過使用PL/SQL編程改進Web日志挖掘中的會話識別方法





 工商網監
工商網監
評論