") Facebook研究人員提出了一個(gè)大規(guī)模圖像文本提取和識(shí)別系統(tǒng)——Rosetta
Facebook研究人員提出了一個(gè)大規(guī)模圖像文本提取和識(shí)別系統(tǒng)——Rosetta
【導(dǎo)讀】OCR(Optical Character Recognition),也稱光學(xué)字符識(shí)別,是通過掃描等光學(xué)輸入方式將各種票據(jù)、報(bào)刊、書籍、文稿及其它印刷品的文字轉(zhuǎn)化為圖像信息,再利用文字識(shí)別技術(shù)將圖像信息轉(zhuǎn)化為可以使用的計(jì)算機(jī)輸入的一種技術(shù)。其實(shí)大家都在應(yīng)用這項(xiàng)技術(shù)——快遞單號(hào)的掃描識(shí)別、火車票的驗(yàn)證等等。最近,F(xiàn)acebook 研究人員提出了一個(gè)大規(guī)模圖像文本提取和識(shí)別系統(tǒng)——Rosetta。接下來 AI科技大本營(yíng)就為大家解讀一下這個(gè) OCR 界的最新神器。
摘要
在本文中,我們提出了一個(gè)可部署、可擴(kuò)展的光學(xué)字符識(shí)別 (OCR) 系統(tǒng),稱之為 Rosetta,用于處理 Facebook 上每天上傳的圖片。對(duì)于 Facebook 這樣社交網(wǎng)絡(luò)中的互聯(lián)網(wǎng)用戶而言,通過圖像內(nèi)容共享實(shí)現(xiàn)對(duì)圖像及其包含文字的理解,已經(jīng)成為信息溝通的一種主要方式,這對(duì)促進(jìn)搜索和推薦應(yīng)用來說也是至關(guān)重要的。這里, 我們提出 Rosetta 系統(tǒng)結(jié)構(gòu),這是一種有效的建模技術(shù)用于檢測(cè)和識(shí)別圖像中的文本。通過進(jìn)行大量的評(píng)估實(shí)驗(yàn),我們解釋了這種實(shí)用系統(tǒng)是如何用于構(gòu)建 OCR 系統(tǒng),以及如何在系統(tǒng)的開發(fā)期間部署特定的組分。
簡(jiǎn)介
人們?cè)?Facebook 等社交網(wǎng)絡(luò)中的信息共享主要是通過一些視覺媒體,如圖片和視頻等。在過去的幾年里,每天上傳到社交媒體平臺(tái)上的照片數(shù)量成倍增長(zhǎng),這對(duì)大量視覺信息的處理技術(shù)提出了挑戰(zhàn)。圖像理解的主要挑戰(zhàn)之一是將有關(guān)圖像中的文本信息檢索出來,這也稱為光學(xué)字符識(shí)別 (OCR),這是一個(gè)將電子圖像中的字體,繪圖或場(chǎng)景文本轉(zhuǎn)化為機(jī)器編碼文本的過程。從圖像中獲取這樣的文本信息是非常重要的,這也能促進(jìn)許多不同的現(xiàn)實(shí)應(yīng)用,如圖像搜索和推薦等。
在光學(xué)字符識(shí)別任務(wù)中,給定一張圖像,我們的 OCR 系統(tǒng)能夠正確地提取所覆蓋或嵌入的文本圖片。這種任務(wù)所面臨的挑戰(zhàn)主要是來自一些潛在的字體、語(yǔ)言、詞典和其他語(yǔ)言變體,包括特殊的符號(hào),非字典單詞或圖像中的 URL,email ID 等特定信息。此外,圖像的質(zhì)量往往也會(huì)隨著自然場(chǎng)景圖像中文字的出現(xiàn)而變化不同的背景。另一方面,社交網(wǎng)絡(luò)上每天上傳的圖像數(shù)量都是龐大的,對(duì)于如此大量的圖片進(jìn)行處理也是目前這項(xiàng)任務(wù)所要面臨的一大挑戰(zhàn)。我們想要在圖像上傳的同時(shí),實(shí)時(shí)地進(jìn)行 OCR 處理,這需要我們花費(fèi)大量的時(shí)間對(duì)系統(tǒng)的組件進(jìn)行優(yōu)化。
總的說來,我們希望建立一個(gè)強(qiáng)大而準(zhǔn)確的 OCR 系統(tǒng),來實(shí)時(shí)處理每天上傳的數(shù)億張圖像。本文,我們提出一種可擴(kuò)展的 OCR 系統(tǒng) Rosetta,為 Facebook 日常網(wǎng)絡(luò)社交提供支持。我們的 OCR 系統(tǒng)分為文本檢測(cè)和文本識(shí)別兩個(gè)階段:基于 Faster-RCNN 模型,在文本檢測(cè)階段我們的系統(tǒng)能夠檢測(cè)出圖像內(nèi)包含文本的區(qū)域;采用基于全卷積網(wǎng)絡(luò)的字符識(shí)別模型,在文本識(shí)別階段我們的系統(tǒng)能夠處理檢測(cè)到的位置并識(shí)別出文本的內(nèi)容。下圖1展示了 Rosetta 系統(tǒng)的檢測(cè)識(shí)別效果。
圖1 使用 Rosetta 系統(tǒng)進(jìn)行 OCR 文本識(shí)別。首先,基于 Faster-RCNN 模型檢測(cè)出單詞的位置,并采用全卷積模型生成每個(gè)單詞的轉(zhuǎn)路信息。
方法
我們的 OCR 系統(tǒng) Rosetta 主要包含兩個(gè)階段:檢測(cè)和識(shí)別階段。在檢測(cè)階段,我們的系統(tǒng)能夠檢測(cè)出圖像中可能包含文字的矩形區(qū)域。在識(shí)別階段,我們對(duì)每個(gè)檢測(cè)到的區(qū)域,使用全卷積神經(jīng)網(wǎng)絡(luò)模型,識(shí)別并轉(zhuǎn)錄該區(qū)域的單詞,實(shí)現(xiàn)文本識(shí)別。兩階段的處理過程有幾大好處,包括解耦訓(xùn)練處理、部署并更新檢測(cè)和識(shí)別模型的能力,并行地運(yùn)行文本識(shí)別,獨(dú)立地支持不同語(yǔ)言的文本識(shí)別等。下圖2詳細(xì)說明我們系統(tǒng)的流程。
圖2 兩階段模型的結(jié)構(gòu)。第一階段是基于 Faster-RCNN 模型進(jìn)行單詞檢測(cè)。第二階段使用具有 CTC 損失的全卷積模型進(jìn)行單詞識(shí)別。這兩個(gè)模型是獨(dú)立訓(xùn)練的。
▌文本檢測(cè)模型
文本檢測(cè)階段,我們采用最先進(jìn)的 Faster-RCNN 目標(biāo)檢測(cè)網(wǎng)絡(luò)。簡(jiǎn)而言之,F(xiàn)aster-RCNN 通過一個(gè)全卷積神經(jīng)網(wǎng)絡(luò)和區(qū)域建議網(wǎng)絡(luò) (RPN) 同時(shí)實(shí)現(xiàn)目標(biāo)的檢測(cè)和識(shí)別:學(xué)習(xí)表征一張圖像的卷積特征映射并生成 k 個(gè)高可能性的文本建議區(qū)域候選框及其置信度得分,隨后按置信度分?jǐn)?shù)排序這些候選框并利用非極大值抑制 (NMS) 算法得到最有希望的檢測(cè)區(qū)域,再?gòu)暮蜻x框中提取相關(guān)的特征映射并學(xué)習(xí)一個(gè)分類器來識(shí)別它們。此外,邊界框回歸 (bounding-box regression) 通常用于提高邊界框生成的準(zhǔn)確性。
考慮到模型效率的問題,我們的文本檢測(cè)模型采用基于 ShuffleNet 結(jié)構(gòu)的 Faster-RCNN 模型,而 ShuffleNet 卷積結(jié)構(gòu)是在 ImageNet 數(shù)據(jù)集上經(jīng)過預(yù)訓(xùn)練得到的。整個(gè)文本檢測(cè)系統(tǒng)是以監(jiān)督式的,端到端的方式進(jìn)行訓(xùn)練的。訓(xùn)練過程中,該檢測(cè)系統(tǒng)采用內(nèi)部合成的數(shù)據(jù)進(jìn)行訓(xùn)練,并在 COCO-Text 數(shù)據(jù)集上進(jìn)行微調(diào)后應(yīng)用于學(xué)習(xí)真實(shí)世界數(shù)據(jù)集特征。了,
▌文本識(shí)別模型
文本識(shí)別階段,我們嘗試了以下兩種不同的模型結(jié)構(gòu),并采用了不同的文本損失函數(shù)。
基于字符序列的編碼模型 (CHAR)。該模型假設(shè)所有圖像都具有相同的大小并且存在最大可識(shí)別字符數(shù)量 k。對(duì)于較長(zhǎng)的單詞,單詞中只有 k 個(gè)字符能夠被識(shí)別出。該 CHAR 模型的主體由一系列卷積結(jié)構(gòu)組成,后接上 k 個(gè)獨(dú)立的多類分類器,用于預(yù)測(cè)在每個(gè)位置上出現(xiàn)的字符。在訓(xùn)練期間,共同學(xué)習(xí)卷積體和 k 個(gè)不同的分類器。使用 k 個(gè)并行損失 (softmax + negative cross-entropy) 并提供合理的基線就能很容易地訓(xùn)練 CHAR 模型,但這有兩個(gè)重大缺點(diǎn):它無(wú)法正確識(shí)別長(zhǎng)的單詞串 (如 URL 地址),分類器中大量的參數(shù)容易導(dǎo)致模型出現(xiàn)過擬合現(xiàn)象。
基于全卷積模型。我們將此模型稱為 CTC,因?yàn)樗褂?seq2seq 的CTC損失函數(shù)用于模型的訓(xùn)練,并輸出一系列字符。CTC 模型的結(jié)構(gòu)示意圖如下圖3所示,基于 ResNet-18 結(jié)構(gòu),在最后一層的卷積中預(yù)測(cè)輸入字符在每個(gè)圖像中最可能的位置。與其他工作不同的是,我們?cè)诖瞬皇褂蔑@式循環(huán)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu) (如 LSTM 或 GRU) 或任何的注意力機(jī)制,而直接生成每個(gè)字符的概率。訓(xùn)練時(shí),我們采用 CTC 損失函數(shù),通過邊緣化所有可能對(duì)齊的路徑集合來計(jì)算給定標(biāo)簽的條件概率,這就能夠使用動(dòng)態(tài)編程進(jìn)行有效地計(jì)算。 如圖3所示,特征映射的每一列對(duì)應(yīng)于圖像每個(gè)位置所有字符的概率分布,CTC 能夠找到它們之間的對(duì)齊預(yù)測(cè),即可能包含重復(fù)的字符或空白字符 (-)和真實(shí)標(biāo)簽。
圖3 文本識(shí)別模型的結(jié)構(gòu)
▌Rosetta 系統(tǒng)
下圖4展示了 Rosetta 的系統(tǒng)結(jié)構(gòu),其在線圖片處理的流程主要包含以下幾個(gè)步驟:
Rosetta 將客戶端的圖片下載到本地計(jì)算機(jī)集群,并通過預(yù)處理步驟,如調(diào)整大小和規(guī)范化來進(jìn)一步處理。
執(zhí)行文本檢測(cè)模型 (圖4中的步驟4) 獲取圖像中所有單詞的位置信息 (邊界框坐標(biāo)和置信度分?jǐn)?shù))。
將單詞的位置信息傳遞給文本識(shí)別模型 (圖4中的步驟5),用于提取圖像給定裁剪區(qū)域的單詞字符。
所提取的文本信息及圖像中文本的位置信息都被存儲(chǔ)在 TAO 中,這是 Facebook 的一個(gè)分布式圖形數(shù)據(jù)庫(kù) (圖4中的步驟6)。
諸如圖片搜索等下游應(yīng)用程序可以從 TAO 中訪問所提取的圖像文本信息 (圖4中的步驟7)。
圖4 Rosetta 系統(tǒng)結(jié)構(gòu),這是 Facebook 的可擴(kuò)展的文本識(shí)別系統(tǒng)。
實(shí)驗(yàn)
我們對(duì) Rosetta OCR 系統(tǒng)進(jìn)行了大量的評(píng)估實(shí)驗(yàn)。首先,我們定義用于評(píng)估準(zhǔn)確性和系統(tǒng)處理時(shí)間的度量,并描述用于訓(xùn)練和評(píng)估的數(shù)據(jù)集。我們?cè)趩为?dú)的數(shù)據(jù)集上進(jìn)行保準(zhǔn)的模型訓(xùn)練和評(píng)估過程。進(jìn)一步,我們?cè)u(píng)估文本檢測(cè)和文本識(shí)別模型,以及系統(tǒng)準(zhǔn)確性和運(yùn)行時(shí)間之間的權(quán)衡。
▌評(píng)估度量
對(duì)于文本檢測(cè)模型,我們采用 mAP 和 IoU 作為評(píng)估度量。而對(duì)于文本識(shí)別模型,我們使用 accuracy 和 Levenshtein’s edit distance 作為我們的評(píng)估指標(biāo)。
▌數(shù)據(jù)庫(kù)
我們采用 COCO-Text 數(shù)據(jù)集對(duì)我們的模型進(jìn)行訓(xùn)練和測(cè)試。COCO-Text 數(shù)據(jù)集包含大量自然場(chǎng)景下注釋的文字,由超過63000張圖片和145000文本實(shí)例組成。為了解決 COCO-Text 數(shù)據(jù)與 Facebook 上圖片數(shù)據(jù)分布不匹配的問題,我們還通過隨機(jī)重疊 Facebook 中圖像的文本來生成了一個(gè)大規(guī)模的合成數(shù)據(jù)集。
▌模型檢測(cè)性能
下表1,表2,表3分別展示了 Faster-RCNN 檢測(cè)模型在不同數(shù)據(jù)測(cè)試集上的的檢測(cè)性能,不同卷積主體結(jié)構(gòu)的推理時(shí)間,以及 ResNet-18 和 ShuffleNet 為卷積主體的檢測(cè)性能。
表1 在不同數(shù)據(jù)測(cè)試集上 Faster-RCNN 檢測(cè)模型的mAP。準(zhǔn)確性是 mAP 在合成訓(xùn)練數(shù)據(jù)集上的相對(duì)改進(jìn)。→表示微調(diào),即 A→B 表示在 A 上訓(xùn)練并在 B 上微調(diào)。
表2 以各種卷積結(jié)構(gòu)為主體的 Faster-RCNN 模型的推理時(shí)間。表中的數(shù)字為相對(duì)于 ResNet-50 的改進(jìn)。
表3 使用 ResNet-18 和 Shuffle 結(jié)構(gòu)的 Faster R-CNN 在 COCO-Text 數(shù)據(jù)集上評(píng)估結(jié)果。表格中的 mAP 是對(duì) ResNet-18 的 3個(gè)RPN 寬高比的相對(duì)改進(jìn)。
▌模型識(shí)別性能
下表4,表5分別展示了在不同數(shù)據(jù)集上模型的識(shí)別性能以及結(jié)合檢測(cè)和識(shí)別系統(tǒng)檢測(cè)到的詞召回率下降的歸一化幅度。
表4不同數(shù)據(jù)集上模型的識(shí)別性能。越高的 accuracy 和越低的 edit distance 代表越好的結(jié)果。表中的數(shù)字是相對(duì)于在合成數(shù)據(jù)集上訓(xùn)練的 CHAR 模型的改進(jìn)。
表5 檢測(cè)和識(shí)別組合系統(tǒng)檢測(cè)到詞召回率下降的歸一化幅度
結(jié)論
本文,我們提出了魯棒而有效的文本檢測(cè)和識(shí)別模型,并用于構(gòu)建可擴(kuò)展的 OCR 系統(tǒng) Rosetta。我們對(duì) Rosetta 系統(tǒng)進(jìn)行了大量的評(píng)估,結(jié)果展示系統(tǒng)在權(quán)衡模型精度和處理時(shí)間方面都能實(shí)現(xiàn)高效率的性能。進(jìn)一步地,我們的系統(tǒng)將部署到實(shí)際生產(chǎn)中并用于處理 Facebook 用戶每天上傳的圖片。
-
圖像
+關(guān)注
關(guān)注
2文章
1087瀏覽量
40501 -
Facebook
+關(guān)注
關(guān)注
3文章
1429瀏覽量
54814 -
識(shí)別系統(tǒng)
+關(guān)注
關(guān)注
1文章
138瀏覽量
18819
原文標(biāo)題:OCR大突破:Facebook推出大規(guī)模圖像文字檢測(cè)識(shí)別系統(tǒng)——Rosetta
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
車輛牌照識(shí)別系統(tǒng)的原理及算法研究
FPGA和Nios_軟核的語(yǔ)音識(shí)別系統(tǒng)的研究
基于DSP的快速紙幣圖像識(shí)別技術(shù)研究
研究:面部識(shí)別技術(shù)目前并不可靠
微軟語(yǔ)音識(shí)別系統(tǒng)錯(cuò)誤率僅為5.1%,達(dá)成新的精準(zhǔn)里程碑!
大規(guī)模MIMO的性能
分享一款不錯(cuò)的基于DSP的虹膜識(shí)別系統(tǒng)
基于STM32嵌入式的孤立詞語(yǔ)音識(shí)別系統(tǒng)設(shè)計(jì)
一個(gè)大規(guī)模超文本網(wǎng)絡(luò)搜索引擎剖析(英文版)
圖像處理的板形識(shí)別系統(tǒng)設(shè)計(jì)
以色列研究人員開發(fā)出了一種能夠識(shí)別不同刺激的新型傳感系統(tǒng)
JD和OPPO的研究人員們提出了一種姿勢(shì)引導(dǎo)的時(shí)尚圖像生成模型
Facebook的研究人員提出了Mesh R-CNN模型

Facebook向研究人員發(fā)布友誼數(shù)據(jù)
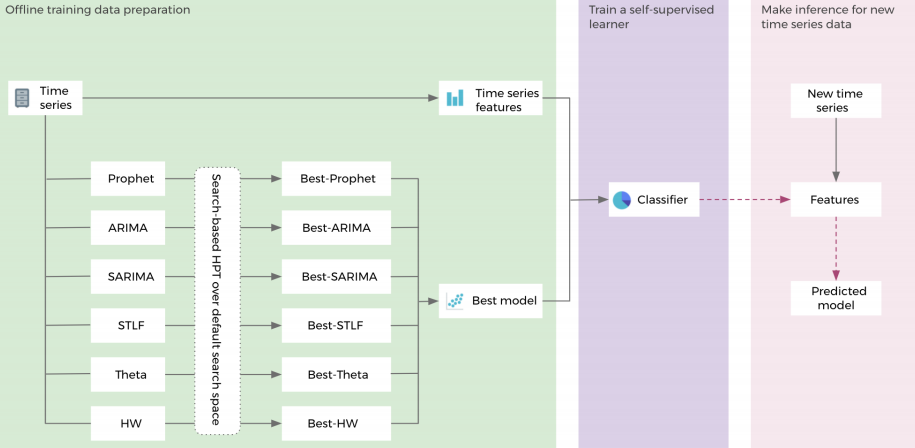
華裔女博士提出:Facebook提出用于超參數(shù)調(diào)整的自我監(jiān)督學(xué)習(xí)框架





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論