") 如何提高生成器G樣本質(zhì)量的新方法
如何提高生成器G樣本質(zhì)量的新方法
最近,生成模型的快速發(fā)展引起了廣泛的關(guān)注,尤其是由Goodfellow等人發(fā)明的生成對(duì)抗網(wǎng)絡(luò)(GANs),其所建立的學(xué)習(xí)框架就像老頑童的“左右互搏術(shù)”,由生成器G和判別器D組成,兩者在博弈過(guò)程中扮演著不同角色。
對(duì)于給定訓(xùn)練數(shù)據(jù)Dt,生成器G的目的就是創(chuàng)建與訓(xùn)練數(shù)據(jù)Dt具有相同概率分布的樣本。判別器D屬于常見(jiàn)的二分類器,主要負(fù)責(zé)兩個(gè)工作。 首先,它要判別輸入究竟是來(lái)自真實(shí)的數(shù)據(jù)分布(Dt)還是生成器;此外,判別器通過(guò)反傳梯度指導(dǎo)生成器G創(chuàng)造更逼真的樣本,這也是生成器G優(yōu)化其模型參數(shù)的唯一途徑。在博弈過(guò)程中,生成器G將隨機(jī)噪聲作為輸入并生成樣本圖像Gsample,要使判別器D以為這是來(lái)自真實(shí)訓(xùn)練集Dt的判斷概率最大化。
訓(xùn)練期間,判別器D的一半時(shí)間將訓(xùn)練集Dt的圖像作為輸入,另一半時(shí)間將生成器得到的圖像Gsample作為輸入。訓(xùn)練判別器D要能最大化分類正確的概率,能夠區(qū)分來(lái)自訓(xùn)練集的真實(shí)圖像和來(lái)自生成器的假樣本。最后,希望博弈最終能達(dá)到平衡——納什均衡。
所以,生成器G要能使得生成的概率分布和真實(shí)數(shù)據(jù)分布盡量接近,這樣判別器D就無(wú)法區(qū)分真實(shí)或假冒的樣本。
在過(guò)去的幾年中,GANs已經(jīng)被用于許多不同的應(yīng)用,包括:生成合成數(shù)據(jù),圖像素描,半監(jiān)督學(xué)習(xí),超分辨率和文本到圖像生成。然而,大部分關(guān)于GANs的工作都集中在開(kāi)發(fā)穩(wěn)定的訓(xùn)練技術(shù)上。的確,我們都知道GANs在訓(xùn)練期間是不穩(wěn)定的,并且對(duì)超參數(shù)的選擇十分敏感。本文將簡(jiǎn)要介紹目前GANs前沿技術(shù),關(guān)于如何提高生成器G樣本質(zhì)量的新方法。
卷積生成對(duì)抗網(wǎng)絡(luò)
深度卷積生成對(duì)抗網(wǎng)絡(luò)(DCGAN)為GANs能夠成功用于圖像生成邁進(jìn)了一大步。它屬于ConvNets家族的一員,利用一些結(jié)構(gòu)約束使得GANs的訓(xùn)練更穩(wěn)定。在DCGAN中,生成器G由一系列轉(zhuǎn)置卷積算子組成,對(duì)于輸入的隨機(jī)噪聲向量z,通過(guò)逐漸增加和減少特征的空間維度,對(duì)其進(jìn)行變換。
使用DCNNs進(jìn)行無(wú)監(jiān)督表示學(xué)習(xí)的網(wǎng)絡(luò)結(jié)構(gòu)示意圖
DCGAN引入了一系列網(wǎng)絡(luò)結(jié)構(gòu)來(lái)幫助GAN訓(xùn)練更穩(wěn)定,它使用帶步幅的卷積而不是池化層。此外,它對(duì)生成器和判別器都使用BatchNorm,生成器中使用的是ReLU和Tanh激活函數(shù),而判別器中使用Leaky ReLU激活函數(shù)。下面,我們來(lái)具體看一下:
BatchNorm是為了將層輸入的特征進(jìn)行規(guī)范化,使其具備零均值和單位方差的特性。BatchNorm對(duì)于網(wǎng)絡(luò)訓(xùn)練是至關(guān)重要的,它可以讓層數(shù)更深的模型工作正常而不會(huì)發(fā)生模式崩塌。模式崩塌是指生成器G創(chuàng)建的樣本具有非常低的多樣性,換句話說(shuō)就是生成器G對(duì)于不同的輸入信號(hào)都返回相同的樣本。此外,BatchNorm有助于處理由于參數(shù)初始化不良引起的問(wèn)題。
此外,DCGAN在判別器網(wǎng)絡(luò)中使用Leaky ReLU激活函數(shù)。與常規(guī)ReLU函數(shù)不同,Leaky ReLU不會(huì)把所有的負(fù)值都置零,而是除以一個(gè)比例,這樣就能傳遞一些很小的負(fù)的梯度信號(hào),從而使判別器中更多的非零梯度進(jìn)入生成器。
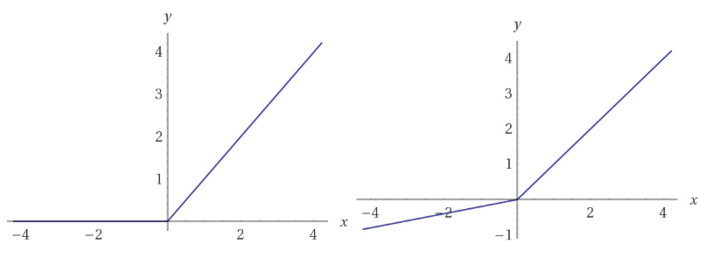
ReLU函數(shù)(左),Leaky ReLU(右),與ReLU不同,Leaky ReLU函數(shù)對(duì)于x軸左側(cè)的負(fù)值導(dǎo)數(shù)不為零。
DCGAN這樣的網(wǎng)絡(luò)結(jié)構(gòu)目前仍被廣泛應(yīng)用,但大部分的工作都集中在如何使GAN訓(xùn)練更加穩(wěn)定。
1.基于自注意力的生成對(duì)抗網(wǎng)絡(luò)
自注意力生成對(duì)抗網(wǎng)絡(luò)(Self-Attention for Generative Adversarial Networks,SAGAN)是這種類型的網(wǎng)絡(luò)之一。近來(lái),基于注意力的方法已經(jīng)被成功用于機(jī)器翻譯等問(wèn)題上。 自注意力GANs具有特殊的網(wǎng)絡(luò)結(jié)構(gòu),使得生成器G能夠建模長(zhǎng)程依賴關(guān)系,核心思想是使生成器G能夠生成具有全局細(xì)節(jié)信息的樣本。
如果我們看一下DCGAN模型會(huì)發(fā)現(xiàn)常規(guī)的GANs模型主要基于卷積,使用局部感受野(卷積核)來(lái)學(xué)習(xí)表征。 卷積具有很多非常好的屬性,比如參數(shù)共享和平移不變性。
典型的深度卷積網(wǎng)絡(luò)(Deep ConvNets)通過(guò)層級(jí)遞進(jìn)的方式來(lái)學(xué)習(xí)表征。 用于圖像分類的常規(guī)ConvNets前幾層中只會(huì)學(xué)到邊緣和角點(diǎn)等簡(jiǎn)單的特征。然而ConvNets卻能夠使用這些簡(jiǎn)單的表征來(lái)學(xué)習(xí)到更為復(fù)雜的表征。 簡(jiǎn)而言之,ConvNets的表征學(xué)習(xí)是基于簡(jiǎn)單的特征表示,很難學(xué)習(xí)到長(zhǎng)程依賴關(guān)系。
實(shí)際上,它可能只適用于低分辨率特征向量。問(wèn)題在于,在這種粒度下,信號(hào)的損失量難以對(duì)長(zhǎng)程細(xì)節(jié)進(jìn)行建模。下面我們看一些樣本圖像:
使用DCNNs進(jìn)行無(wú)監(jiān)督表示學(xué)習(xí)的生成樣本示意圖
這些圖像是使用DCGAN模型基于ImageNet數(shù)據(jù)集訓(xùn)練而生成得到的。正如自注意力GANs文章中所指出的,對(duì)于含有較少結(jié)構(gòu)約束的類別,比如海洋、天空等,得到結(jié)果較好;而對(duì)于含有較多幾何或結(jié)構(gòu)約束的類別則容易失敗,比如合成圖像中狗(四足動(dòng)物)的毛看起來(lái)很真實(shí)但手腳很難辨認(rèn)。這是因?yàn)閺?fù)雜的幾何輪廓需要長(zhǎng)程細(xì)節(jié),卷積本身不具備這種能力,這也是注意力能發(fā)揮很好作用的地方。
所以解決這一問(wèn)題的核心想法在于不局限于卷積核,要為生成器提供來(lái)自更廣泛的特征空間中的信息,這樣生成器G就可以生成具有可靠細(xì)節(jié)的樣本。
實(shí)現(xiàn)
給定卷積層L一個(gè)特征輸入,首先用三種不同的表示來(lái)對(duì)L進(jìn)行變換。這里使用了1x1卷積對(duì)L進(jìn)行卷積以獲得三個(gè)特征空間:f,g和h。這一方法使用矩陣乘法來(lái)線性組合f和g計(jì)算得到注意力,并將其送入softmax層。
自注意力GANS網(wǎng)絡(luò)示意圖
最后得到的張量o是與h的線性組合,由尺度因子gamma控制縮放。 要注意,gamma從0開(kāi)始,因此在訓(xùn)練剛開(kāi)始時(shí),gamma為零相當(dāng)于把注意力層去掉了,此時(shí)網(wǎng)絡(luò)僅依賴于常規(guī)卷積層的局部表示。然而,隨著gamma接收梯度下降的更新,網(wǎng)絡(luò)逐漸允許來(lái)自非局部域的信號(hào)通過(guò)。此外要注意的是特征向量f和g具有與h不同的維度。事實(shí)上f和g使用的卷積濾波器大小要比h小8倍。
2.譜范數(shù)(L2范數(shù))歸一化
此前,Miyato等人提出了一種稱為譜范數(shù)歸一化(spectral normalization ,簡(jiǎn)稱SN)的方法。 簡(jiǎn)而言之,SN可約束卷積濾波器的Lipschitz常數(shù),作者使用它來(lái)穩(wěn)定判別器D網(wǎng)絡(luò)訓(xùn)練。實(shí)踐證明的確很有效。
然而,在訓(xùn)練歸一化判別器D的時(shí)候存在一個(gè)基本問(wèn)題。先前的工作表明,正則化判別器D會(huì)使得GAN的訓(xùn)練變慢。一些已有變通方法往往通過(guò)調(diào)整生成器G和判別器D之間的更新速率,使得在更新生成器G之前多更新判別器D幾次。這樣在更新生成器G之前,正則化判別器D可能需要五次或更多次更新。
有一種簡(jiǎn)單而有效的方法可以解決學(xué)習(xí)緩慢和更新率不平衡的問(wèn)題。我們知道在GAN框架中,生成器G和判別器D是一起訓(xùn)練的。 基于這點(diǎn),Heusel等人在GAN訓(xùn)練中引入了兩個(gè)時(shí)間尺度的更新規(guī)則(two-timescale update rule,簡(jiǎn)稱TTUR),對(duì)生成器G和判別器D使用不同的學(xué)習(xí)率。在這里,設(shè)置判別器D訓(xùn)練的學(xué)習(xí)率是生成器G 的四倍,分別為0.004和0.001。 較大的學(xué)習(xí)率意味著判別器D將吸收梯度信號(hào)的較大部分。較高的學(xué)習(xí)速度可以減輕正則化判別器D學(xué)習(xí)速度慢的問(wèn)題。此外,這種方法也可以使得生成器G和判別器D能以相同的速率更新。事實(shí)上,我們?cè)谏善鱃和判別器D之間使用的是1:1的更新間隔。
此外,文章還表明,生成器狀態(tài)的好壞與GAN性能有著因果關(guān)系。鑒于此,自注意力GAN使用SN來(lái)穩(wěn)定生成器網(wǎng)絡(luò)的訓(xùn)練必然有助于提高GAN網(wǎng)絡(luò)的整體性能。對(duì)于生成器G而言,譜范數(shù)歸一化既可防止參數(shù)變得非常大,也可以避免多余的梯度。
實(shí)現(xiàn)
值得注意的是,Miyato等人引入的SN算法是迭代近似。 它定義了對(duì)于每個(gè)層W,用W的最大奇異值來(lái)對(duì)每個(gè)卷積層W正則化。但是,在每一步都用奇異值分解那就計(jì)算量太大了。所以Miyato等人使用一種被稱作power iteration的方法來(lái)獲得近似的最大奇異值的解。

要注意的是在訓(xùn)練期間,在power iteration中計(jì)算得到的?值會(huì)在下一次迭代中被用作u的初始值。這種策略允許算法僅經(jīng)過(guò)一輪power iteration就獲得非常好的估計(jì)。此外,為了歸一化核權(quán)重,將它們除以當(dāng)前的SN估計(jì)。
訓(xùn)練細(xì)節(jié)
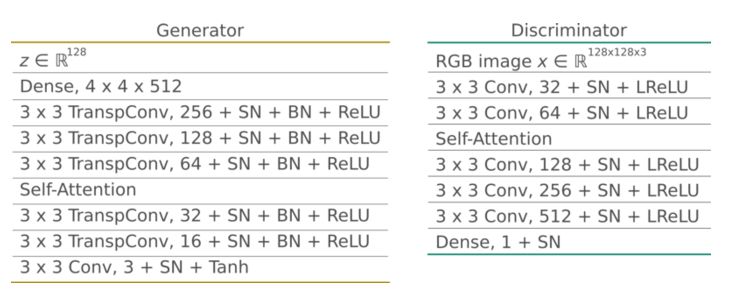
在實(shí)驗(yàn)中生成器G輸入隨機(jī)向量z并生成128x128大小的RGB圖像。所有層(包括全連接層)都使用了SN。生成器G使用Batchnorm和ReLU激活函數(shù),在中層到高層的特征圖中使用了自注意力模型。與原作者實(shí)現(xiàn)方法一樣,我們將注意力層放置在32x32大小的特征圖上。
判別器D還使用譜范數(shù)歸一化(所有層)。它將大小為128x128的RGB圖像樣本作為輸入,并輸出無(wú)標(biāo)度的概率。它使用leaky ReLU激活函數(shù),alpha參數(shù)設(shè)置為0.02。與生成器G一樣,它在32x32大小的特征圖上上也有一個(gè)自注意力層。
最終的結(jié)果如下圖所示:
通過(guò)自注意力和譜歸一化的方式可以實(shí)現(xiàn)更好的生成效果,如果你想了解更多,下面的兩篇論文是不錯(cuò)的選擇:
SAGAN: https://arxiv.org/abs/1805.08318
Spectral Normalization: https://arxiv.org/pdf/1802.05957.pdf https://openreview.net/pdf?id=B1QRgziT-
-
濾波器
+關(guān)注
關(guān)注
161文章
7817瀏覽量
178126 -
GaN
+關(guān)注
關(guān)注
19文章
1935瀏覽量
73425 -
生成器
+關(guān)注
關(guān)注
7文章
315瀏覽量
21011
原文標(biāo)題:GAN提高生成器G樣本質(zhì)量新玩法:自注意力和譜范數(shù)
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
python生成器
STM32庫(kù)函數(shù)代碼自動(dòng)生成器正式版
基于生成器的圖像分類對(duì)抗樣本生成模型


python生成器是什么
TSMaster報(bào)文發(fā)送的信號(hào)生成器操作說(shuō)明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論