 AutoML模型壓縮技術,利用強化學習將壓縮流程自動化
AutoML模型壓縮技術,利用強化學習將壓縮流程自動化
MIT韓松團隊和Google Cloud的研究人員提出AutoML模型壓縮技術,利用強化學習將壓縮流程自動化,完全無需人工,而且速度更快,性能更高。
模型壓縮是在計算資源有限、能耗預算緊張的移動設備上有效部署神經網絡模型的關鍵技術。
在許多機器學習應用,例如機器人、自動駕駛和廣告排名等,深度神經網絡經常受到延遲、電力和模型大小預算的限制。已經有許多研究提出通過壓縮模型來提高神經網絡的硬件效率。
模型壓縮技術的核心是確定每個層的壓縮策略,因為它們具有不同的冗余,這通常需要手工試驗和領域專業知識來探索模型大小、速度和準確性之間的大設計空間。這個設計空間非常大,人工探索法通常是次優的,而且手動進行模型壓縮非常耗時。
為此,韓松團隊提出了AutoML模型壓縮(AutoML for Model Compression,簡稱AMC),利用強化學習來提供模型壓縮策略。
論文地址:
https://arxiv.org/pdf/1802.03494.pdf
負責這項研究的MIT助理教授韓松博士表示:
“算力換算法”是當今AutoML系列工作的熱點話題,AMC則屬于“算力換算力”:用training時候的算力換取inference時候的算力。模型在完成一次訓練之后,可能要在云上或移動端部署成千上萬次,所以inference的速度和功耗至關重要。
我們用AutoML做一次性投入來優化模型的硬件效率,然后在inference的時候可以得到事半功倍的效果。比如AMC將MobileNet inference時的計算量從569M MACs降低到285M MACs,在Pixel-1手機上的速度由8.1fps提高到14.6fps,僅有0.1%的top-1準確率損失。AMC采用了合適的搜索空間,對壓縮策略的搜索僅需要4個GPU hours。
總結來講,AMC用“Training算力”換取“Inference算力”的同時減少的對“人力“的依賴。最后,感謝Google Cloud AI對本項目的支持。
Google Cloud 研發總監李佳也表示:“AMC是我們在模型壓縮方面的一點嘗試,希望有了這類的技術,讓更多的mobile和計算資源有限的應用變得可能。”
“Cloud AutoML 產品設計讓機器學習的過程變得更簡單,讓即便沒有機器學習經驗的人也可以享受機器學習帶來的益處。盡管AutoML有很大的進步,這仍是一項相對初期的技術,還有很多方面需要提高和創新。”李佳說。
用AI做模型壓縮,完全不需要人工
研究人員的目標是自動查找任意網絡的壓縮策略,以實現比人為設計的基于規則的模型壓縮方法更好的性能。
這項工作的創新性體現在:
1、AMC提出的learning-based model compression優于傳統的rule-based model compression
2、資源有限的搜索
3、用于細粒度操作的連續行動空間
4、使用很少的GPU進行快速搜索(ImageNet上1個GPU,花費4小時)
目標:自動化壓縮流程,完全無需人工。利用AI進行模型壓縮,自動化,速度更快,而且性能更高。
這種基于學習的壓縮策略優于傳統的基于規則的壓縮策略,具有更高的壓縮比,在更好地保持準確性的同時節省了人力。
在4×FLOP降低的情況下,我們在ImageNet上對VGG-16模型進行壓縮,實現了比手工模型壓縮策略高2.7%的精度。
我們將這種自動化壓縮pipeline應用于MobileNet,在Android手機上測到1.81倍的推斷延遲加速,在Titan XP GPU上實現了1.43倍的加速,ImageNet Top-1精度僅下降了0.1%。
AutoML模型壓縮:基于學習而非規則
圖1:AutoML模型壓縮(AMC)引擎的概覽。左邊:AMC取代人工,將模型壓縮過程完全自動化,同時比人類表現更好。右邊:將AMC視為一個強化學習為題。
以前的研究提出了許多基于規則的模型壓縮啟發式方法。但是,由于深層神經網絡中的層不是獨立的,這些基于規則的剪枝策略并非是最優的,而且不能從一個模型轉移到另一個模型。隨著神經網絡結構的快速發展,我們需要一種自動化的方法來壓縮它們,以提高工程師的效率。
AutoML for Model Compression(AMC)利用強化學習來自動對設計空間進行采樣,提高模型壓縮質量。圖1展示了AMC引擎的概覽。在壓縮網絡是,ACM引擎通過基于學習的策略來自動執行這個過程,而不是依賴于基于規則的策略和工程師。
我們觀察到壓縮模型的精度對每層的稀疏性非常敏感,需要細粒度的動作空間。因此,我們不是在一個離散的空間上搜索,而是通過DDPG agent提出連續壓縮比控制策略,通過反復試驗來學習:在精度損失時懲罰,在模型縮小和加速時鼓勵。actor-critic的結構也有助于減少差異,促進更穩定的訓練。
針對不同的場景,我們提出了兩種壓縮策略搜索協議:
對于latency-critical的AI應用(例如,手機APP,自動駕駛汽車和廣告排名),我們建議采用資源受限的壓縮(resource-constrained compression),在最大硬件資源(例如,FLOP,延遲和模型大小)下實現最佳精度);
對于quality-critical的AI應用(例如Google Photos),我們提出精度保證的壓縮(accuracy-guaranteed compression),在實現最小尺寸模型的同時不損失精度。
DDPG Agent
DDPG Agent用于連續動作空間(0-1)
輸入每層的狀態嵌入,輸出稀疏比
壓縮方法研究
用于模型大小壓縮的細粒度剪枝(Fine-grained Pruning)
粗粒度/通道剪枝,以加快推理速度
搜索協議
資源受限壓縮,以達到理想的壓縮比,同時獲得盡可能高的性能。
精度保證壓縮,在保持最小模型尺寸的同時,完全保持原始精度。
為了保證壓縮的準確性,我們定義了一個精度和硬件資源的獎勵函數。有了這個獎勵函數,就能在不損害模型精度的情況下探索壓縮的極限。
對于資源受限的壓縮,只需使用Rerr = -Error
對于精度保證的壓縮,要考慮精度和資源(如FLOPs):RFLOPs = -Error?log(FLOPs)

實驗和結果:全面超越手工調參
為了證明其廣泛性和普遍適用性,我們在多個神經網絡上評估AMC引擎,包括VGG,ResNet和MobileNet,我們還測試了壓縮模型從分類到目標檢測的泛化能力。
強化學習agent對ResNet-50的剪枝策略
ACM將模型壓縮到更低密度而不損失精度(人類專家:ResNet50壓縮3.4倍;AMC:ResNet50壓縮5倍)
大量實驗表明,AMC提供的性能優于手工調優的啟發式策略。對于ResNet-50,我們將專家調優的壓縮比從3.4倍提高到5倍,而沒有降低精度。
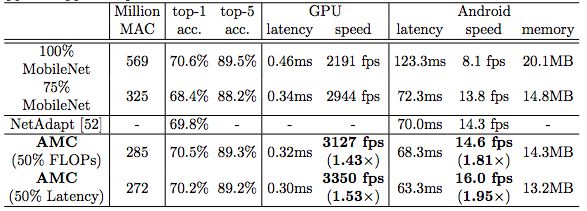
AMC對MobileNet的加速
此外,我們將MobileNet的FLOP降低了2倍,達到了70.2%的Top-1最高精度,這比0.75 MobileNet的Pareto曲線要好,并且在Titan XP實現了1.53倍的加速,在一部Android手機實現1.95的加速。
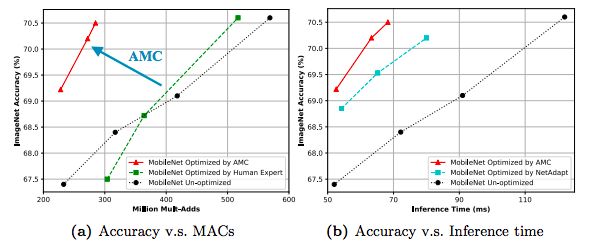
AMC和人類專家對MobileNet進行壓縮的精度比較和推理時間比較
結論
傳統的模型壓縮技術使用手工的特征,需要領域專家來探索一個大的設計空間,并在模型的大小、速度和精度之間進行權衡,但結果通常不是最優的,而且很耗費人力。
本文提出AutoML模型壓縮(AMC),利用增強學習自動搜索設計空間,大大提高了模型壓縮質量。我們還設計了兩種新的獎勵方案來執行資源受限壓縮和精度保證壓縮。
在Cifar和ImageNet上采用AMC方法對MobileNet、MobileNet- v2、ResNet和VGG等模型進行壓縮,取得了令人信服的結果。壓縮模型可以很好滴從分類任務推廣到檢測任務。在谷歌Pixel 1手機上,我們將MobileNet的推理速度從8.1 fps提升到16.0 fps。AMC促進了移動設備上的高效深度神經網絡設計。
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100872 -
機器學習
+關注
關注
66文章
8423瀏覽量
132750 -
強化學習
+關注
關注
4文章
267瀏覽量
11266
原文標題:AutoML自動模型壓縮再升級,MIT韓松團隊利用強化學習全面超越手工調參
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
騰訊 AI Lab 開源世界首款自動化模型壓縮框架PocketFlow
基于ARM嵌入式系統的自動化配送系統
深度強化學習實戰
啃論文俱樂部 | 壓縮算法團隊:我們是如何開展對壓縮算法的學習
壓縮模型會加速推理嗎?
將深度學習和強化學習相結合的深度強化學習DRL
首款自動化深度學習模型壓縮框架——PocketFlow
Waymo用AutoML自動生成機器學習模型
機器學習中的無模型強化學習算法及研究綜述


預先設置NAS算法能否實現AutoML自動機器學習革命

《自動化學報》—多Agent深度強化學習綜述

VEGA:諾亞AutoML高性能開源算法集簡介

ICLR 2023 Spotlight|節省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2






 工商網監
工商網監
評論