 如何利用Tensorflow搭建神經網絡?
如何利用Tensorflow搭建神經網絡?
在筆記7中,筆者和大家一起入門了 Tensorflow的基本語法,并舉了一些實際的例子進行了說明,終于告別了使用numpy手動搭建的日子。所以我們將繼續往下走,看看如何利用 Tensorflow搭建神經網絡模型。
盡管對于初學者而言使用Tensorflow看起來并不那么習慣,需要各種步驟,但簡單來說,Tensorflow搭建模型實際就是兩個過程:創建計算圖和執行計算圖。在 deeplearningai 課程中,NG和他的課程組給我們提供了Signs Dataset(手勢)數據集,其中訓練集包括1080張64x64像素的手勢圖片,并給定了 6 種標注,測試集包括120張64x64的手勢圖片,我們需要對訓練集構建神經網絡模型然后對測試集給出預測。
先來簡單看一下數據集:
# Loading the datasetX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()# Flatten the training and test imagesX_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T X_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T# Normalize image vectorsX_train = X_train_flatten/255.X_test = X_test_flatten/255.# Convert training and test labels to one hot matricesY_train = convert_to_one_hot(Y_train_orig, 6) Y_test = convert_to_one_hot(Y_test_orig, 6)print ("number of training examples = " + str(X_train.shape[1]))print ("number of test examples = " + str(X_test.shape[1]))print ("X_train shape: " + str(X_train.shape))print ("Y_train shape: " + str(Y_train.shape))print ("X_test shape: " + str(X_test.shape))print ("Y_test shape: " + str(Y_test.shape))
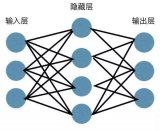
下面就根據 NG 給定的找個數據集利用Tensorflow搭建神經網絡模型。我們選擇構建一個包含 2 個隱層的神經網絡,網絡結構大致如下:LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX正如我們之前利用numpy手動搭建一樣,搭建一個神經網絡的主要步驟如下:-定義網絡結構-初始化模型參數-執行前向計算/計算當前損失/執行反向傳播/權值更新
創建 placeholder
根據Tensorflow的語法,我們首先創建輸入X和輸出Y的占位符變量,這里需要注意shape參數的設置。
def create_placeholders(n_x, n_y): X = tf.placeholder(tf.float32, shape=(n_x, None), name='X') Y = tf.placeholder(tf.float32, shape=(n_y, None), name='Y') return X, Y
初始化模型參數
其次就是初始化神經網絡的模型參數,三層網絡包括六個參數,這里我們采用Xavier初始化方法:
def initialize_parameters(): tf.set_random_seed(1) W1 = tf.get_variable("W1", [25, 12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1)) b1 = tf.get_variable("b1", [25, 1], initializer = tf.zeros_initializer()) W2 = tf.get_variable("W2", [12, 25], initializer = tf.contrib.layers.xavier_initializer(seed = 1)) b2 = tf.get_variable("b2", [12, 1], initializer = tf.zeros_initializer()) W3 = tf.get_variable("W3", [6, 12], initializer = tf.contrib.layers.xavier_initializer(seed = 1)) b3 = tf.get_variable("b3", [6,1], initializer = tf.zeros_initializer()) parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2, "W3": W3, "b3": b3} return parameters
執行前向傳播
def forward_propagation(X, parameters): """ Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX """ W1 = parameters['W1'] b1 = parameters['b1'] W2 = parameters['W2'] b2 = parameters['b2'] W3 = parameters['W3'] b3 = parameters['b3'] Z1 = tf.add(tf.matmul(W1, X), b1) A1 = tf.nn.relu(Z1) Z2 = tf.add(tf.matmul(W2, A1), b2) A2 = tf.nn.relu(Z2) Z3 = tf.add(tf.matmul(W3, A2), b3) return Z3
計算損失函數
在Tensorflow中損失函數的計算要比手動搭建時方便很多,一行代碼即可搞定:
def compute_cost(Z3, Y): logits = tf.transpose(Z3) labels = tf.transpose(Y) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels)) return cost
代碼整合:執行反向傳播和權值更新
跟計算損失函數類似,Tensorflow中執行反向傳播的梯度優化非常簡便,兩行代碼即可搞定,定義完整的神經網絡模型如下:
def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001, num_epochs = 1500, minibatch_size = 32, print_cost = True): ops.reset_default_graph() tf.set_random_seed(1) seed = 3 (n_x, m) = X_train.shape n_y = Y_train.shape[0] costs = [] # Create Placeholders of shape (n_x, n_y) X, Y = create_placeholders(n_x, n_y) # Initialize parameters parameters = initialize_parameters() # Forward propagation: Build the forward propagation in the tensorflow graph Z3 = forward_propagation(X, parameters) # Cost function: Add cost function to tensorflow graph cost = compute_cost(Z3, Y) # Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer. optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost) # Initialize all the variables init = tf.global_variables_initializer() # Start the session to compute the tensorflow graph with tf.Session() as sess: # Run the initialization sess.run(init) # Do the training loop for epoch in range(num_epochs): epoch_cost = 0. num_minibatches = int(m / minibatch_size) seed = seed + 1 minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed) for minibatch in minibatches: # Select a minibatch (minibatch_X, minibatch_Y) = minibatch _ , minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y}) epoch_cost += minibatch_cost / num_minibatches # Print the cost every epoch if print_cost == True and epoch % 100 == 0: print ("Cost after epoch %i: %f" % (epoch, epoch_cost)) if print_cost == True and epoch % 5 == 0: costs.append(epoch_cost) # plot the cost plt.plot(np.squeeze(costs)) plt.ylabel('cost') plt.xlabel('iterations (per tens)') plt.title("Learning rate =" + str(learning_rate)) plt.show() # lets save the parameters in a variable parameters = sess.run(parameters) print ("Parameters have been trained!") # Calculate the correct predictions correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y)) # Calculate accuracy on the test set accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print ("Train Accuracy:", accuracy.eval({X: X_train, Y: Y_train})) print ("Test Accuracy:", accuracy.eval({X: X_test, Y: Y_test})) return parameters
執行模型:
parameters = model(X_train, Y_train, X_test, Y_test)
根據模型的訓練誤差和測試誤差可以看到:模型整體效果雖然沒有達到最佳,但基本也能達到預測效果。
總結
Tensorflow語法中兩個基本的對象類是 Tensor 和 Operator.
Tensorflow執行計算的基本步驟為
創建計算圖(張量、變量和占位符變量等)
創建會話
初始化會話
在計算圖中執行會話
可以看到的是,在 Tensorflow 中編寫神經網絡要比我們手動搭建要方便的多,這也正是深度學習框架存在的意義之一。功能強大的深度學習框架能夠幫助我們快速的搭建起復雜的神經網絡模型,在經歷了手動搭建神經網絡的思維訓練過程之后,這對于我們來說就不再困難了。
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100952 -
tensorflow
+關注
關注
13文章
329瀏覽量
60563
原文標題:深度學習筆記8:利用Tensorflow搭建神經網絡
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TensorFlow是什么
【AI學習】第3篇--人工神經網絡
如何構建神經網絡?
基于BP神經網絡的PID控制
如何使用TensorFlow將神經網絡模型部署到移動或嵌入式設備上
用TensorFlow寫個簡單的神經網絡

深度學習筆記8:利用Tensorflow搭建神經網絡
如何使用numpy搭建一個卷積神經網絡詳細方法和程序概述
基于TensorFlow框架搭建卷積神經網絡的電池片缺陷識別研究





 工商網監
工商網監
評論