 使用VHDL語言和FPGA技術實現高效微控制器內核的設計
使用VHDL語言和FPGA技術實現高效微控制器內核的設計
與傳統投片實現ASIC相比,FPGA具有實現速度快、風險小、可編程、可隨時更改升級等一系列優點,因而得到了越米越廣泛的應用。MCS-51應用時間長、范圍廣,相關的軟硬件資源豐富,因而往往在FPGA應用中嵌人MCS-51內核作為微控制器。但是傳統MCS-51的指令效率太低,每個機器周期高達12時鐘周期,因此必須對內核加以改進,提高指令執行速度和效率,才能更好地滿足FPGA的應用。
通過對傳統MCS-51單片機指令時序和體系結構的分析,使用VHDL語言采用自頂向下的設計方法重新設計了一個高效的微控制器內核。改進了的體系結構,可以兼容MCS-51所有指令,每個機器周期只需1個時鐘周期,同時增加了硬件看門狗和軟件復位功能,提高了指令執行效率和抗干擾能力。
1 系統設計
1.1 模塊劃分
本內核在劃分和設計模塊時,基于以下幾條原則:
(1)同步設計,提高系統穩定性和可移植性;(2)功能明確,功能接近的放在同一個模塊內以減少模塊的數量和模塊之間的互連線,同時利于綜合時的優化;(3)模塊之間的接口時序預先定義好,并嚴格按定義的時序要求編寫每個模塊;(4)模塊信號的輸出采用寄存器輸出的方式。這樣可以提高系統的可靠性,一旦出錯也容易確定問題所在。
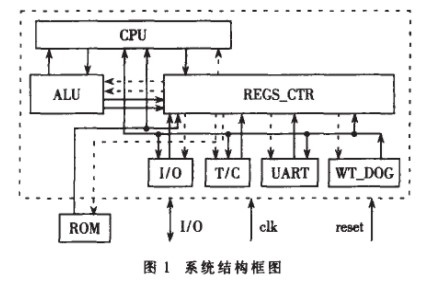
本內核由以下幾個部分組成:中央控制單元(CPU),算術邏輯運算單元(ALU),寄存器組控制器(REGS_CTR),定時器/計數器(T/C),通用串行接口(UART),看門狗(WT_DOG),如圖1所示。
1.2 提高速度的方法
本內核采用以下幾種辦法來提高速度。
(1) 采用多數據通道:本內核取消了傳統MCS-51系列單片機的單一總線,采用直連結構,各模塊的數據傳輸使用單向專用數據線,尤其在數據交換頻繁的ALU與REGS_CTR之間采用四條單向數據線相互連接,提高了數據傳輸的并行度,從而加快了數據的傳輸。
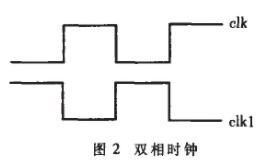
(2) 采用雙相時鐘:如圖2所示。CLK時鐘上升沿CPU發出控制信號,I/O端口采樣外部信號即圖1中流入REGS_CTR的數據或控制信號;CLK1時鐘上升沿把數據寫入寄存器中并把刷新后的數據或控制信號發出,即圖1中虛箭頭表示的數據流向。這樣REGS_CTR的讀寫分別在兩個時鐘的上升沿,減少了一個時鐘周期的等待,時鐘頻率提高了一倍。
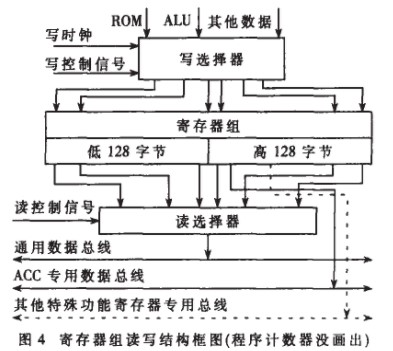
(3) 采用寄存器組:FPGA內部有極為豐富的寄存器資源,本內核取消了傳統的同一時間只能讀或者寫的RAM塊,代之以可同時進行不同地址讀寫操作的寄存器組。一些特殊功能寄存器有專用總線輸出,如圖3所示。
(4) 提高時鐘頻率:對電路的關鍵路徑進行了改造,以減少邏輯電路級數從而提高時鐘頻率。通過這些設計,保證了每個機器周期只需一個時鐘周期,提高了指令執行效率,同時也提高系統的時鐘頻率。
1.3 兼容性方面的考慮
MCS-51系列單片機有豐富的軟硬件資源,為充分利用這些資源,在本內核設計時盡量考慮增強其兼容性。除機器周期變為原來的1/12以及新增加一個特殊功能寄存器(地址F8H)用于控制看門狗和軟件復位外,其他沒有變化。因而單個內核應用時,以前的程序可完全移植;在與外界通信時因機器周期與MCS-51單片機有差別可能需對一些程序作相應改動。這樣可以使系統在提高性能的同時無需其他開銷,便于推廣使用。
2 功能模塊的設計
2.1 中央控制器(CPU)的設計
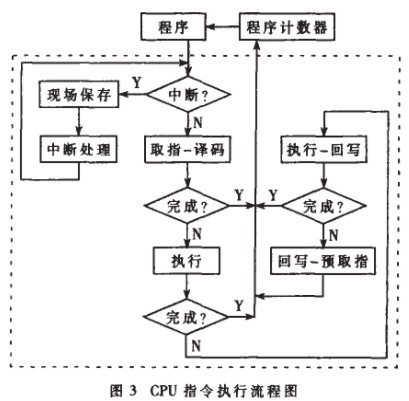
這是微控制器的核心,負責中斷處理及指令執行。中斷處理分為中斷取樣、中斷高低優先級的判斷及執行相應的處理過程。CPU對指令的執行分為四個階段:取指-譯碼、執行、執行-回寫、回寫-預取指。指令執行流程如圖4所示。
在編碼實現方式上,本模塊是一個大的父子兩級狀態機,父狀態機為指令的類型,子狀態機為每種指令的執行步驟。這樣結構清晰,利于編程、查錯及仿真。
2.2 寄存器組(REGS_CTR)的設計
本模塊在CPU的控制下完成:程序地址的產生、高低128個寄存器的讀寫。程序計數器根據控制信號與來自寄存器組的數據產生相應的指令地址并送往ROM。在寄存器組的讀寫中,用讀譯碼電路選擇輸出操作數據,寫譯碼電路寫入結果數據。這種結構可以在對一個寄存器寫的同時讀另一個寄存器。如圖3所示,通用的數據總線可以取得任何一個寄存器的數據,各個專用寄存器也有各自的專用數據線輸出。例如執行指令ADDA,DIRECT時,由于累加器ACC有專門的總線,只要給出相應的讀控制信號就可以從通用數據總線上得到來自寄存器組的DIRECT數據,這樣ALU在同一周期內就可以得到所需的兩個操作數。
2.3 看門狗(WT_DOG)的設計
傳統的MCS-51系列單片機為提高抗干擾能力通常使用外置看門狗或者采用軟件陷阱的方式使系統復位。本內核增加了硬件看門狗及軟件復位功能,通過新增加一個特殊功能寄存器(地址F8H)來控制是否啟用看門狗或軟件復位以及設置看門狗的喂狗時間。除非掉電或用程序重新設置,F8H寄存器的數值一直保存,這樣避免了看門狗復位后其自身失效的問題。
2.4 算術邏輯運算單元(ALU)的設計
累加器在CPU發出的指令控制下,對來自ROM與REGS_CTR的數據完成相應的操作,包括算術運算(加減乘除)與邏輯運算(與或非)及BCD碼調整。所有操作的結果在一個時鐘周期內得出,在clkl上升沿到來后寫入REGS_CTR。
2.5 串行模塊及定時/計數器的設計
串行模塊和定時/計數器的工作模式與傳統的MCS-51系列單片機相同。定時/計數器一個時鐘周期計數一次,與傳統MCS-51單片機一個機器周期計數一次效果等同。在與外界用串行端口通信時機器周期有差別。
3 仿真、綜合優化及實現
3.1 仿真
為了保證內核正確地工作,必須對電路做充分的仿真以保證設計的正確性。系統設計完成后用ModelSim Se PLUS 6.0D對電路進行了功能仿真,對組合邏輯模塊(如ALU)采用了窮舉測試向量的方法予以功能仿真,對于時序模塊如CPU,先測試能否正確執行中斷及每一條指令,再測試隨機指令及隨機中斷。仿真結果表明,內核能滿足設計的要求。ALU的仿真結果如同5所示。
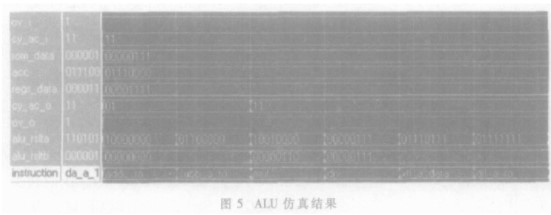
其中rom_data、acc、regs_data為ALU的操作數,in-struction為指令的類別,alu_rslta、alu_rsltb為ALU的操作結果的高、低字節。由圖5可見,在輸入操作數和進位溢位標志位不變的情況下,不同的指令都能輸出相對應的正確結果。ALU操作結果的數據予以鎖存,直到下一個指令或數據到來時才改變。在保持指令不變的情況下改變輸入數據和進位溢位標志位也能得到正確的結果。
3.2 綜合優化
為了盡可能提高時鐘頻率,必須降低關鍵路徑的延時。由于ALU所有的操作都要在一個周期內完成,因而操作所需的最長時間也是時鐘周期的最小值。綜合分析后發現操作時間最長的是除法運算,采用通移位相減除法器所需時間為39ns,如果采用并行除法器后則只需23ns,從而顯著提高了時鐘頻率。內核綜合后消耗的LUT為4500個。
3.3 實現
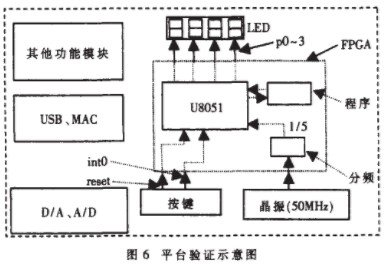
本內核的全部工作都在ISE7.1開發環境下完成。其中,仿真用的是ModelSim Se PLUS 6.0D,綜合用的軟件是Synplify Pro 8.0。驗證采用的平臺足CREAT-SOPC1000X試驗箱,它的核心芯片即FPGA使用的是Xilinx公司的Virtex-Ⅱxc2v1000-6 fg456,等效為100萬門電路,如圖6所示。平臺上集成了一些常用的功能模塊,其中的晶振為50MHz,超過了本內核綜合后的最高頻率,因而設計了一個5分頻模塊使時鐘為10MHz。內核運行的測試程序和數據以事先機器代碼的形式“固化”在一個程序模塊內替代ROM,系統可以像ROM一樣對其讀取數據和程序。P0-3輸出觀察數據,檢驗程序是否正確執行。驗證結果表明,內核能正確執行加載的程序并穩定運行在10MHz的頻率上。
為克服傳統MCS-51單片機執行效率偏低的缺點,滿足現在的FPGA對嵌入式軟核速度較高的要求,重新設計了一個兼容MCS-51指令的嵌入式軟核。該軟核指令效率提高了12倍,同時增加了實用的功能:硬件看門狗和軟件復位。內核通過FPGA驗證具有一定的應用價值。
-
微控制器
+關注
關注
48文章
7646瀏覽量
151949 -
FPGA
+關注
關注
1630文章
21796瀏覽量
605445 -
vhdl
+關注
關注
30文章
817瀏覽量
128286
發布評論請先 登錄
相關推薦
怎么通過FPGA實現微控制器?
怎么使用VHDL語言設計一個高效的微控制器內核?
基于VHDL的DRAM控制器設計
基于VHDL語言和FPGA開發板實現數字秒表的設計
基于VHDL語言和可編程邏輯器件實現Petri網邏輯控制器的設計
基于FPGA的DSP技術實現伺服控制器的應用方案與設計






 工商網監
工商網監
評論