") 基于強(qiáng)化學(xué)習(xí)的自動(dòng)駕駛預(yù)測(cè)控制技術(shù)
基于強(qiáng)化學(xué)習(xí)的自動(dòng)駕駛預(yù)測(cè)控制技術(shù)
1介紹
如今,道路上車輛越來越多,道路運(yùn)輸系統(tǒng)變得越來越繁忙。為了使交通和移動(dòng)更加智能化和高效,自動(dòng)駕駛汽車被認(rèn)為是有前途的解決方案。隨著外部傳感、運(yùn)動(dòng)規(guī)劃和車輛控制等方面取得顯著的成果,自動(dòng)駕駛汽車的自主創(chuàng)新能夠很好地幫助車輛在預(yù)先設(shè)定的場(chǎng)景下獨(dú)立運(yùn)行。
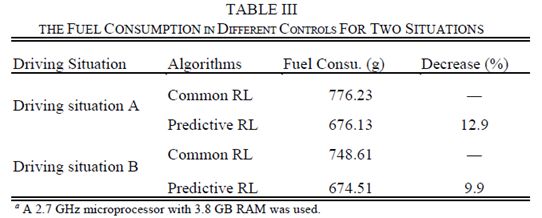
通常,自動(dòng)駕駛車輛中的系統(tǒng)架構(gòu)由三個(gè)主要處理模塊組成,參見圖1作為圖示[2]。傳感器和數(shù)字地圖提供的數(shù)據(jù)在感知和定位模塊中進(jìn)行,以呈現(xiàn)駕駛情況的代表性特征;運(yùn)動(dòng)規(guī)劃模塊旨在根據(jù)給定的傳感器和地圖信息生成適當(dāng)?shù)臎Q策策略并得出最佳軌跡;軌跡控制器模塊的目的是計(jì)算處理加速和轉(zhuǎn)向的具體控制動(dòng)作,以維持現(xiàn)有的軌跡[ 3 ]。
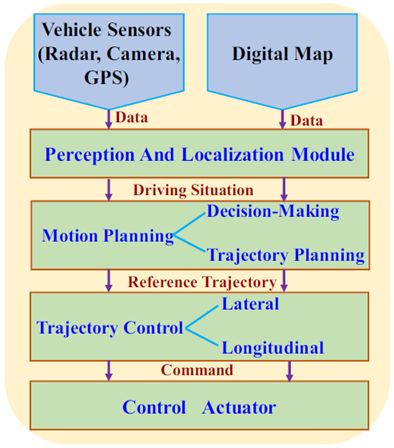
圖1.通用自動(dòng)駕駛汽車的系統(tǒng)架構(gòu)[2]
決策和路徑規(guī)劃是自動(dòng)駕駛汽車的關(guān)鍵技術(shù)。為了討論軌跡生成步驟,目前已經(jīng)提出了幾種技術(shù)。例如,提出了一種名為“逐個(gè)學(xué)習(xí)”的數(shù)據(jù)驅(qū)動(dòng)控制框架,用于從歷史駕駛數(shù)據(jù)中訓(xùn)練控制器以將車輛作為人類駕駛員來操作。具體來說,人工神經(jīng)網(wǎng)絡(luò)( ANN ) [ 4 ]和逆最優(yōu)控制[ 5 ]已經(jīng)被用于再現(xiàn)自動(dòng)駕駛車輛中的人類駕駛行為。然而,當(dāng)歷史數(shù)據(jù)集中沒有當(dāng)前駕駛情況時(shí),車輛無法平穩(wěn)運(yùn)行。作為替代方案,模型預(yù)測(cè)控制(MPC)[6]用于預(yù)測(cè)駕駛員行為并在成本函數(shù)中實(shí)施多個(gè)約束,駕駛狀態(tài)預(yù)測(cè)的精度決定了MPC方法的控制性能[7]。自動(dòng)駕駛和人類駕駛員之間的最大區(qū)別是能否確保乘客的安全和舒適。如何創(chuàng)建可行、安全和舒適的參考軌跡仍然是一個(gè)嚴(yán)峻的挑戰(zhàn)。
在這項(xiàng)工作中,為自動(dòng)駕駛混合動(dòng)力電動(dòng)汽車(HEV)開發(fā)了基于強(qiáng)化學(xué)習(xí)的預(yù)測(cè)控制框架。提出的方法是雙層的,高層是一個(gè)類似人類的駕駛模型,它可以生成約束。底層是基于強(qiáng)化學(xué)習(xí)( RL )的控制器,能夠提高自動(dòng)駕駛混合動(dòng)力汽車的能效。所提出的框架被驗(yàn)證用于汽車跟隨模型中的縱向控制。結(jié)果表明,該方法能夠重現(xiàn)人類駕駛員的駕駛風(fēng)格,提高燃油經(jīng)濟(jì)性。
這項(xiàng)工作的貢獻(xiàn)包含兩個(gè)方面。首先是適應(yīng)訓(xùn)練數(shù)據(jù)集中不存在的當(dāng)前駕駛情況。提出誘導(dǎo)矩陣范數(shù)(IMN)來比較當(dāng)前和歷史駕駛數(shù)據(jù)之間的差異并擴(kuò)展訓(xùn)練數(shù)據(jù)集;其次是將軌跡生成步驟與自動(dòng)駕駛HEV的能量效率改進(jìn)相結(jié)合。基于從高層獲得的參考軌跡,基于RL的控制器在成本函數(shù)中實(shí)施電池和燃料消耗約束以促進(jìn)燃料經(jīng)濟(jì)性。
本文的其余部分組織如下,第Ⅱ節(jié)介紹了更高級(jí)別的驅(qū)動(dòng)程序建模方法,第III節(jié)描述了混合動(dòng)力汽車動(dòng)力總成的低級(jí)RL控制器,第Ⅳ節(jié)給出了模擬結(jié)果,第V節(jié)總結(jié)了論文。
2.高層:駕駛員建模
本節(jié)展示了高層類人駕駛模型。首先,定義汽車跟隨模型中的參數(shù);然后,介紹了駕駛員模型的訓(xùn)練方法;最后,描述了未來加速度的預(yù)測(cè)過程。
A.汽車跟隨模型
在汽車跟隨模型中,自動(dòng)駕駛HEV被命名為目標(biāo)車輛,前方自動(dòng)駕駛HEV被稱為前方車輛。定義δt= [dt,vt]是時(shí)刻t的目標(biāo)車輛的狀態(tài),其中dt和vt分別是縱向位置和速度,類似地,δft= [dft,vft]是在時(shí)刻t的前方車輛的狀態(tài),時(shí)刻t的行駛狀況由特征ωt= [drt,vrt,vt]表示,其中drt= dft-d是相對(duì)距離,vrt= vft-v是相對(duì)速度。
在高層上,駕駛員模型旨在生成一個(gè)加速度序列At= [ At,…,At + N - 1],以指導(dǎo)目標(biāo)車輛的運(yùn)行,N = T /△T表示總時(shí)間步長(zhǎng),T是預(yù)測(cè)的時(shí)間間隔,而△T是駕駛員模型的采樣時(shí)間。基于該加速序列,基于RL的控制器用于導(dǎo)出底層的自動(dòng)駕駛HEV的功率分配控制策略。
B.駕駛員模型訓(xùn)練
基于歷史駕駛數(shù)據(jù)ω1 : t= [ω1,…,ωt),駕駛員模型的目標(biāo)是預(yù)測(cè)接近人類駕駛員實(shí)際操作的加速度序列。對(duì)于真實(shí)的駕駛數(shù)據(jù),人類駕駛員的控制策略被建模為隱馬爾科夫鏈( HMC ),其中mt∈{ 1,…M }是用于復(fù)制人類駕駛員演示的加速度命令。在時(shí)刻t的隱模式,ot= [ωt,at]是時(shí)刻t的觀察向量,包括駕駛情況和加速度。
對(duì)于HMC,隱藏模式通過概率分布與觀測(cè)相關(guān),如下所示
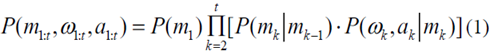
其中假設(shè)轉(zhuǎn)移概率P(ωk,ak| mk)符合高斯分布。特別地,HMC模型的參數(shù)包括初始分布P ( m1)、總隱藏模式M、轉(zhuǎn)移概率πij意味著從第I模式到第j模式的轉(zhuǎn)移,以及高斯分布的協(xié)方差和平均矩陣。期望最大化算法和貝葉斯信息準(zhǔn)則被用來從歷史駕駛數(shù)據(jù)[ 8 ]中學(xué)習(xí)這些參數(shù)。
C.當(dāng)前加速度的計(jì)算
高斯混合回歸用于計(jì)算當(dāng)前加速度,給出行駛情況序列ω1 : t,如下[ 3 ]
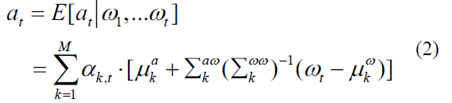
其中
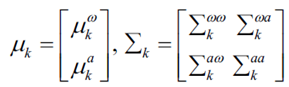
αk,t表示混合系數(shù),并且被計(jì)算為處于模式mt= k的概率[3]
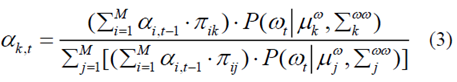
D.預(yù)測(cè)未來加速度
當(dāng)前的行駛狀況ωt= [drt,vrt,vt],當(dāng)前的加速度at和離散時(shí)間△t是先前已知的,可以通過假設(shè)前方車輛的速度恒定來計(jì)算未來的行駛狀況。
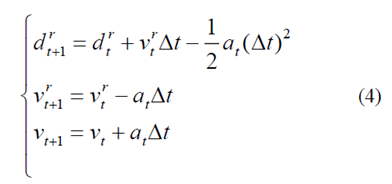
簡(jiǎn)單來說,Eq.(4)可以重新表述為狀態(tài)空間方程
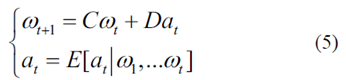
最后,可以通過迭代以下表達(dá)式來導(dǎo)出預(yù)測(cè)范圍T上的未來加速序列
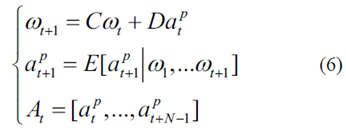
3.底層:RL控制器
本節(jié)介紹了基于RL的節(jié)油控制器。首先,計(jì)算加速度序列的轉(zhuǎn)移概率矩陣(TPM);然后,提出誘導(dǎo)矩陣范數(shù)(IMN)來評(píng)估歷史和當(dāng)前加速度數(shù)據(jù)之間的差異;此外,制定了自主HEV的能效改進(jìn)問題的成本函數(shù);最后,構(gòu)造了RL方法框架,利用Q學(xué)習(xí)算法搜索最優(yōu)控制策略。
A.加速序列的TPM
加速序列被視為有限馬爾可夫鏈(MC),其轉(zhuǎn)移概率通過統(tǒng)計(jì)方法計(jì)算為
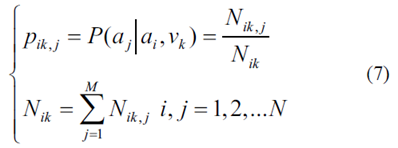
其中Nik,j是從車輛速度vk發(fā)生從ai到aj的轉(zhuǎn)換的次數(shù),Nik是從車速vk的ai開始的總轉(zhuǎn)換計(jì)數(shù),k是離散時(shí)間步長(zhǎng),N是離散加速指數(shù)。加速序列的TPM P填充有元素pik,j。歷史和當(dāng)前加速序列的TPM分別表示為P1和P2。
B.誘導(dǎo)矩陣范數(shù)
當(dāng)歷史駕駛數(shù)據(jù)集不包含當(dāng)前駕駛情況時(shí),高層的駕駛員模型不能生成有效的加速命令來指導(dǎo)自主HEV的操作。因此,引入誘導(dǎo)矩陣范數(shù)(IMN)來量化歷史和當(dāng)前加速度序列的TPM差異
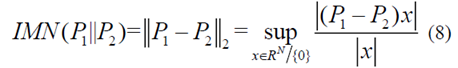
其中sup描繪了標(biāo)量的上確界,x是N×1維非零矢量。方程式中的二階范數(shù)。為了方便計(jì)算,可以將(8)重新表述為以下表達(dá)式
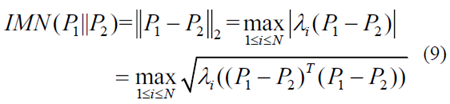
其中PT表示矩陣P的轉(zhuǎn)置,并且λi(P)表示對(duì)于i = 1,...,N的矩陣P的特征值。注意,IMN越接近零,TPM P1與P2越相似。
C.能源效率的成本函數(shù)
自動(dòng)駕駛HEV的能效改進(jìn)的目標(biāo)是在部件的約束下搜索最優(yōu)控制,以提高燃料經(jīng)濟(jì)性,同時(shí)保持有限預(yù)測(cè)范圍內(nèi)的電荷維持約束為
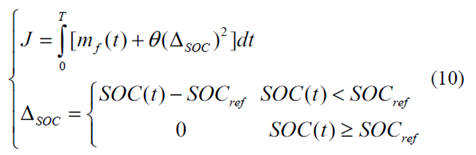
其中mf是燃料消耗率,SOC是電池的充電狀態(tài),θ是限制SOC終端值的大的正加權(quán)因子,而SOCref是滿足電荷維持約束的預(yù)定因子[9]。表1列出了自動(dòng)駕駛HEV的主要部件參數(shù)。
D.RL方法
預(yù)測(cè)加速度序列和車輛參數(shù)的TPM是用于最優(yōu)控制計(jì)算的RL方法的輸入。在RL構(gòu)造中,學(xué)習(xí)代理與隨機(jī)環(huán)境交互。交互被建模為五元組(S,A,P,R,β),其中S和A是狀態(tài)變量和控制動(dòng)作集,P代表功率請(qǐng)求的TPM,R代表獎(jiǎng)勵(lì)集合,β∈(0,1)表示折扣因子。
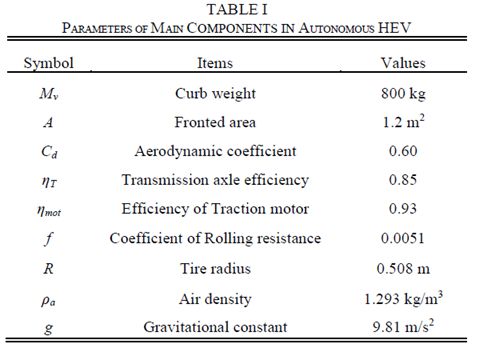
控制策略ψ是控制命令a的分布。有限預(yù)期折現(xiàn)和累積獎(jiǎng)勵(lì)總結(jié)為最優(yōu)值函數(shù)
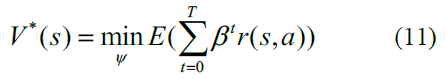
為了在每個(gè)時(shí)刻推導(dǎo)出最佳控制動(dòng)作,Eq.(11)遞歸地重新表述為
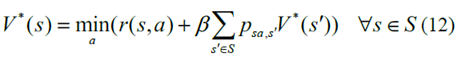
其中psa,s'表示使用動(dòng)作a從狀態(tài)s到狀態(tài)s'的轉(zhuǎn)換概率。基于方程式中的最優(yōu)值函數(shù)確定最優(yōu)控制策略。(12)
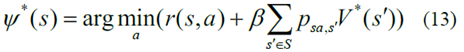
此外,動(dòng)作值函數(shù)及其相應(yīng)的最優(yōu)度量描述如下[10]
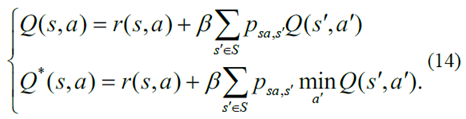
最后,Q學(xué)習(xí)算法中的動(dòng)作值函數(shù)的更新標(biāo)準(zhǔn)由表示
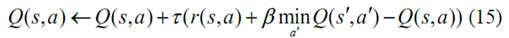

4.模擬結(jié)果與討論
本節(jié)將對(duì)所提出的基于學(xué)習(xí)的預(yù)測(cè)控制框架進(jìn)行評(píng)估。首先,討論了加速序列預(yù)測(cè)的驅(qū)動(dòng)模型的性能。此外,說明了基于RL的燃料節(jié)省策略的控制有效性。
A.驗(yàn)證駕駛員模型
第II節(jié)中描述的駕駛員模型用于預(yù)測(cè)不同駕駛情況下的加速序列。均方誤差(MSE)用于量化預(yù)測(cè)加速序列和實(shí)際加速序列之間的差異。圖2和圖3示出了兩個(gè)實(shí)際加速序列及其對(duì)于兩個(gè)駕駛情況A和B的預(yù)測(cè)值。對(duì)于圖2,假設(shè)自主HEV的當(dāng)前駕駛風(fēng)格存在于歷史駕駛數(shù)據(jù)集中。相反,圖3中的當(dāng)前駕駛風(fēng)格在訓(xùn)練數(shù)據(jù)中不存在。
圖2.情況A的預(yù)測(cè)和實(shí)際加速度序列。
很明顯,加速度序列的預(yù)測(cè)值非常接近圖2中駕駛情況A的實(shí)際值。這表明,當(dāng)歷史駕駛數(shù)據(jù)集預(yù)先遍歷當(dāng)前駕駛情況A時(shí),駕駛員模型可以達(dá)到極好的精度。然而,當(dāng)當(dāng)前駕駛狀況B在訓(xùn)練數(shù)據(jù)中缺失時(shí),駕駛員模型不能為自動(dòng)駕駛HEV操作提供準(zhǔn)確的指導(dǎo),參見圖3作為說明。圖2中的MSE等于1.57,這在預(yù)測(cè)可用性方面優(yōu)于圖3中的MSE = 4.43。
圖3.情況b的預(yù)測(cè)和實(shí)際加速度序列
B.RL控制器的驗(yàn)證
基于歷史和當(dāng)前加速度序列,第III - A節(jié)中描述的TPM的計(jì)算過程被用于計(jì)算駕駛情況A和b中的加速度TPM。IMN被用于量化這兩個(gè)序列之間的差異。因?yàn)镮MN值超過預(yù)定閾值,這意味著當(dāng)前駕駛情況不同于歷史駕駛數(shù)據(jù),因此預(yù)測(cè)加速度不精確。相反,較小的IMN值意味著從歷史數(shù)據(jù)中學(xué)習(xí)的預(yù)測(cè)加速度序列可能是準(zhǔn)確的。
圖4和圖5示出了分別對(duì)應(yīng)于圖2和圖3中的兩種駕駛情況的不同車速水平下的IMN值。這兩個(gè)數(shù)字表明,IMN值超過預(yù)定義閾值的時(shí)間不同。為了處理歷史駕駛數(shù)據(jù)中不存在當(dāng)前駕駛情況B的情況,當(dāng)IMN值超過閾值時(shí),該駕駛數(shù)據(jù)將被添加到訓(xùn)練數(shù)據(jù)集中。通過這樣做,歷史駕駛數(shù)據(jù)集能夠準(zhǔn)確預(yù)測(cè)人類駕駛員在相同駕駛情況下的行為。
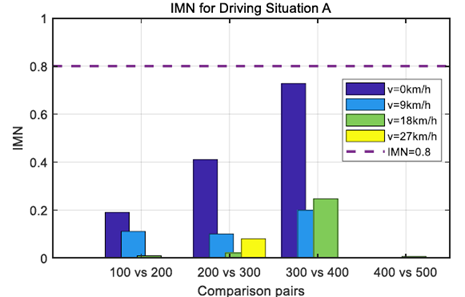
圖4.駕駛情況a的不同速度水平下的IMN值
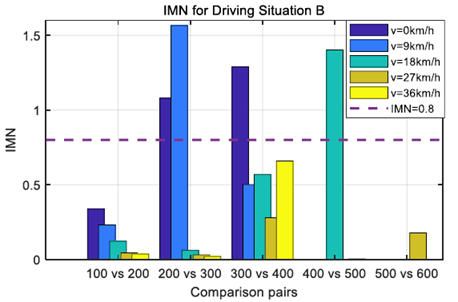
圖5.駕駛情況b的不同速度水平下的IMN值
未來加速序列的精確TPM被進(jìn)一步用于使用RL技術(shù)導(dǎo)出燃料節(jié)省控制。圖6描繪了沒有預(yù)測(cè)加速度信息的公共RL和具有該信息的預(yù)測(cè)RL的SOC軌跡。注意到在這兩種駕駛情況下,SOC軌跡有很大的不同。這是由未來加速序列的TPM決定的自適應(yīng)控制造成的。對(duì)于駕駛情況B,由于基于IMN值的駕駛數(shù)據(jù)的擴(kuò)展過程,預(yù)測(cè)RL也優(yōu)于普通RL。
圖6.兩種情況下的共同SOC和預(yù)測(cè)RL的SOC軌跡
此外,圖7示出了在多個(gè)燃料節(jié)省控制中發(fā)動(dòng)機(jī)的工作區(qū)域。與普通RL控制相比,所提出的預(yù)測(cè)RL控制下的發(fā)動(dòng)機(jī)工作區(qū)域更頻繁地位于較低燃料消耗區(qū)域。這意味著與普通RL技術(shù)相比,預(yù)測(cè)RL方法可以實(shí)現(xiàn)更高的燃料經(jīng)濟(jì)性。
圖7.兩種情況下發(fā)動(dòng)機(jī)工作點(diǎn)的共性和預(yù)測(cè)性RL。
表III描述了在這兩種用于駕駛情況A和b的方法中SOC校正后的燃料消耗。顯然,預(yù)測(cè)RL控制下的燃料消耗低于普通RL控制下的燃料消耗。預(yù)測(cè)的加速序列使得基于RL的控制更加適應(yīng)未來的駕駛情況,這有助于提高燃油經(jīng)濟(jì)性。
5.結(jié)論
在本文中,我們通過提出一個(gè)基于雙層學(xué)習(xí)的預(yù)測(cè)控制框架來尋求自動(dòng)駕駛混合動(dòng)力汽車(HEV)能效的提高。高層通過使用隱馬爾可夫鏈和高斯分布來模擬人類駕駛員的行為;底層是基于強(qiáng)化學(xué)習(xí)的控制器,旨在提高自動(dòng)駕駛混合動(dòng)力汽車的能效,所提出的框架被驗(yàn)證用于汽車跟隨模型中的縱向控制。模擬結(jié)果表明,所提出的駕駛員模型能夠利用誘導(dǎo)矩陣范數(shù)準(zhǔn)確預(yù)測(cè)未來的加速度序列。試驗(yàn)還證明,基于未來加速序列TPM的預(yù)測(cè)RL控制與普通RL控制相比,可以實(shí)現(xiàn)更高的燃油經(jīng)濟(jì)性。未來的工作包括將提議的控制框架應(yīng)用到實(shí)時(shí)應(yīng)用中,并使用RL方法制定駕駛員模型來處理?yè)Q道決策。
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
784文章
13899瀏覽量
166699 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11273
原文標(biāo)題:基于強(qiáng)化學(xué)習(xí)的自動(dòng)駕駛汽車預(yù)測(cè)控制
文章出處:【微信號(hào):IV_Technology,微信公眾號(hào):智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一個(gè)使用傳統(tǒng)DAS和深度強(qiáng)化學(xué)習(xí)融合的自動(dòng)駕駛框架
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
汽車自動(dòng)駕駛技術(shù)
自動(dòng)駕駛真的會(huì)來嗎?
自動(dòng)駕駛的到來
AI/自動(dòng)駕駛領(lǐng)域的巔峰會(huì)議—國(guó)際AI自動(dòng)駕駛高峰論壇
如何讓自動(dòng)駕駛更加安全?
自動(dòng)駕駛汽車的處理能力怎么樣?
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
自動(dòng)駕駛技術(shù)的實(shí)現(xiàn)
深度學(xué)習(xí)技術(shù)的開發(fā)與應(yīng)用
基于強(qiáng)化學(xué)習(xí)的飛行自動(dòng)駕駛儀設(shè)計(jì)
強(qiáng)化學(xué)習(xí)在自動(dòng)駕駛的應(yīng)用
探討深度學(xué)習(xí)在自動(dòng)駕駛中的應(yīng)用
深度學(xué)習(xí)技術(shù)與自動(dòng)駕駛設(shè)計(jì)的結(jié)合





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論