 淺析Uber的一鍵式聊天架構
淺析Uber的一鍵式聊天架構
通過機器學習和自然語言理解結束,Uber實現了一套智能的聊天系統,從而有效的提升司機和乘客之間的溝通效率,減少對司機的打擾。
想象一下站在路邊等待你的優步車過來接你時,在你的應用程序上,你會看到車子幾乎沒有移動。于是你向司機發送消息了解發生了什么事。
你不知道的是,你的司機在前往接你的途中遇到了交通堵塞。他們會收到你的消息并希望回復。這種情況是優步的司機伙伴們告訴我們的一個痛點。所以我們開始思考,如果有可能的話,司機可以通過一個簡單的點擊就可以與乘客進行溝通。
我們提出了一種新的智能回復功能,稱為一鍵式聊天(OCC)。借助OCC,在開始行程前乘客和司機之間的協調更快、更無縫。利用機器學習和自然語言處理(NLP)技術來預測對一般乘客信息的響應,優步開發了OCC讓司機更容易回復app內的消息。
OCC 是UberChat最新的關鍵的增強功能之一,旨在通過提供最相關的回復,為優步的司機伙伴提供一鍵式聊天體驗。
圖1:通過一鍵式聊天,司機可以更輕松地回復乘客的消息。
一鍵式聊天架構
一鍵式聊天(OCC)利用Uber的機器學習平臺Michelangelo在乘客聊天消息上執行NLP,并生成適當的回復。如下面的圖2所示,該體系結構遵循五個步驟:
1.發送方(乘客app)發送消息。
2.一旦我們的后端服務收到消息,后端就會將消息發送給Michelangelo的機器學習服務。
3.機器學習模型對消息進行預處理和編碼,為每個可能的意圖生成預測分數,并將它們發送回后端服務。
4.一旦后端服務收到預測,它將遵循回復檢索策略以找到最佳回復(在這種情況下,生成前四個最佳回復)。
5.接收方(司機應用程序)接收建議并將其呈現在應用程序上供司機點擊。
圖2:優步智能回復系統OCC的架構由五步工作流程組成。
為了找到對每個接收消息的最佳回復,我們將任務制定為具有兩個主要組件的機器學習解決方案:1)意圖檢測和2)回復檢索。
如下面的圖3所示,思考這個例子,以更好地理解機器學習如何實現OCC體驗:
圖3:機器學習算法賦予OCC體驗流程。涉及兩個關鍵步驟:1)意圖檢測和2)回復檢索。
司機收到一條乘客的信息:“你現在在哪里?”,這在司機前往接乘客的途中非常常見的。OCC系統首先將消息的意圖檢測為“你在哪里?”這一步稱為意圖檢測。然后,系統會向司機發出前四個最相關的回復,分別是“ 是的,我在路上 ”,“ 抱歉,堵車了 ”,“ 我在您的上車地點 ”,以及“ 請給我打電話“。這是回復檢索步驟。現在,司機可以選擇這四個回復中的一個,并通過一次點擊將其發送給乘客。
在UberChat中實現OCC
我們的UberChat系統允許Uber平臺上的司機,乘客,消費者和派送員在app內進行通信。當前流程遵循標準消息傳遞系統:我們希望發送者輸入他們的消息,然后將消息發送給接收者。下面的圖4顯示了具有典型消息流的UberChat系統的概述:
圖4:UberChat后端服務管理發送者和接收者之間的消息流。
對于用戶發送的每條消息,Uber的消息傳遞平臺(UMP)執行以下操作(如上圖4所示):
1.將Sender的消息發送到Uber的Edge Gateway
2.將消息路由到Uber的Messaging Platform
3.將消息添加到推送通知服務
4.向Uber的Cassandra數據庫存放持久化消息
5.推送遠程和本地的表層消息給Receiver
6.收到消息后,從Messaging Platform獲取消息正文
為了支持智能回復,我們要能夠使用機器學習模型以足夠低的延遲實時評估回復。為了滿足這一需求,我們利用Uber的內部機器學習平臺Michelangelo的機器學習的訓練和服務流水線。
在UberChat中通過機器學習提供智能回復
根據設計,OCC旨在為司機伙伴們在前往接乘客期間(即Uber特定的場景和主題領域)提供簡單的聊天體驗。然而,它與所有其他試圖理解普通文本信息的嘗試一樣都有一個技術挑戰:它們不僅簡短,而且還包含縮寫、拼寫錯誤和口語。我們在設計機器學習系統時考慮到了這一挑戰。
從外部看,OCC接收到最新傳入的消息并返回可能的回復,但在后臺還有更多事情要做。有兩個主要的工作流為OCC ML系統、離線訓練和在線服務提供服務,如圖5所示:
圖5:OCC的背后,我們的機器學習系統依賴于兩個工作流程,離線訓練和在線服務。
離線訓練
在離線訓練期間,我們使用以下基于嵌入的ML和NLP流水線來處理這些文本消息:
預處理器
為了準備文本嵌入模型的訓練數據,我們利用了匿名的UberChat消息。我們首先按語言(語言檢測)對聊天消息進行劃分,然后進行長度截斷(長度<= 2)。最后,我們對每條消息進行標記。
文本和消息的嵌入
在預處理之后,我們使用Doc2vec模型進行消息嵌入,它從可變長度的文本片段(例如句子,段落和文檔)中學習固定長度的特征表示。我們在數百萬個匿名的、聚集的UberChat消息中訓練Doc2vec模型,并使用該訓練將每個消息映射到一個密集的向量嵌入空間。滿足我們需求的Doc2vec的兩個主要優點是它可以捕獲單詞的順序和語義。下面的圖6使用t-SNE圖在二維投影中可視化單詞向量。由于它捕獲了單詞的語義,因此模型可以將相似的單詞聚集在一起。例如,“Toyota”接近““Prius”和“Camry”,但與“chihuahua”相距很遠。
圖6:Doc2vec單詞嵌入的這種二維t-SNE投影顯示了模型自動組織概念和隱式地學習單詞之間的關系的能力,并基于語義對它們進行聚類。
意圖檢測
為了理解用戶的意圖,我們在嵌入過程之后訓練了我們的意圖檢測模型。與Gmail的智能回復功能類似,我們將意圖檢測任務定義為分類問題。
為什么我們需要意圖檢測?因為人類語言豐富。有很多方式會提出同樣的問題,比如“你要去什么地方?”,“你倆要去哪里?”,“你的目的地是什么?”拼寫錯誤和縮寫會增加更多排列,所以聊天消息增加了一定程度的復雜性。
創建一個需要對數百萬個問題進行回復的系統將無法擴展,因此我們需要一個系統來識別每個問題背后的意圖或主題,從而對有限的意圖進行回復。下面的圖7說明了不同的消息如何根據檢測到的意圖聚集在一起:
圖7:在這種二維t-SNE的句子嵌入的投影中,模型圍繞意圖聚類消息。
意圖-回復映射
我們利用匿名和聚集的歷史對話來查找每個意圖的最常見的回復。之后,我們的通信內容策劃師和法律團隊進行一輪又一輪擴充,使回復盡可能的容易理解和準確。然后,我們為回復檢索創建意圖 - 回復映射。
在線服務
一旦我們完成模型的離線訓練,在線服務就相對簡單了。我們獲取最新的輸入消息并通過與離線相同的預處理器發送它們。預處理的消息將通過預先訓練的Doc2vec模型編碼為固定長度的向量表示,之后我們使用向量和意圖檢測分類器來預測消息的可能意圖。
最后,通過利用我們的意圖 - 回復映射,我們根據檢測到的意圖檢索最相關的回復,并將它們顯示給接收消息的司機伙伴。此外,一些極端情況將由規則而不是算法所掩蓋,包括非常短的消息(預處理階段中被截斷的消息),表情符號和低置信度預測(多意圖用例)。
下一步
我們計劃繼續在全球市場中將一鍵式聊天功能擴展到其他語言。我們還在研究更多特定于Uber的上下文功能,如地圖和交通信息,并計劃將它們合并到我們現有的模型中。這些更新將增加我們更準確地識別用戶意圖和展示定制回復的可能性,從而更好地協助司機伙伴們:簡而言之,讓優步體驗變得更加神奇。
此外,雖然當前系統使用靜態意圖 – 回復映射來檢索回復,但我們計劃構建一個回復檢索模型以進一步提高OCC系統的精度。
在高層次上,OCC是一個多回合對話系統的自然應用,因為司機伙伴們和乘客們可以在他們找到對方之前進行多次對話。利用OCC和其他功能,構建一個對話系統改善化成功接到乘客和聊天體驗的這個長期過程,最終在我們的平臺上帶來更好的用戶體驗。
OCC只是Uber中眾多不同的NLP / Conversational AI計劃中的一個。例如,NL也被用于提高Uber[1,2]的客戶服務,同時也處于免提乘車的核心位置,這一塊我們將很快開始測試聲控命令。
-
機器學習
+關注
關注
66文章
8434瀏覽量
132871 -
Uber
+關注
關注
0文章
411瀏覽量
36291 -
自然語言
+關注
關注
1文章
289瀏覽量
13374
原文標題:Uber的一鍵式聊天智能回復系統
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
優可測一鍵尺寸測量儀:實現MLCC尺寸快速精準檢測 | 行業應用

在中壓開關柜上使用微機五防鎖是否可以實現一鍵順控
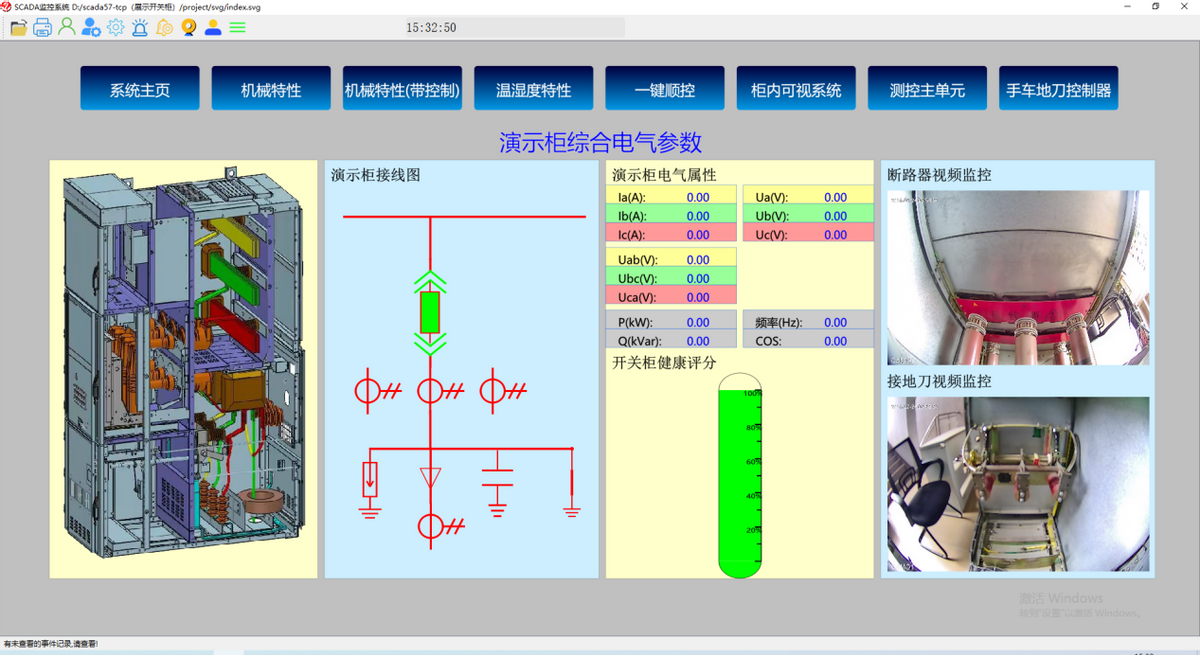
人機界面在開關柜一鍵順控中起到什么作用?
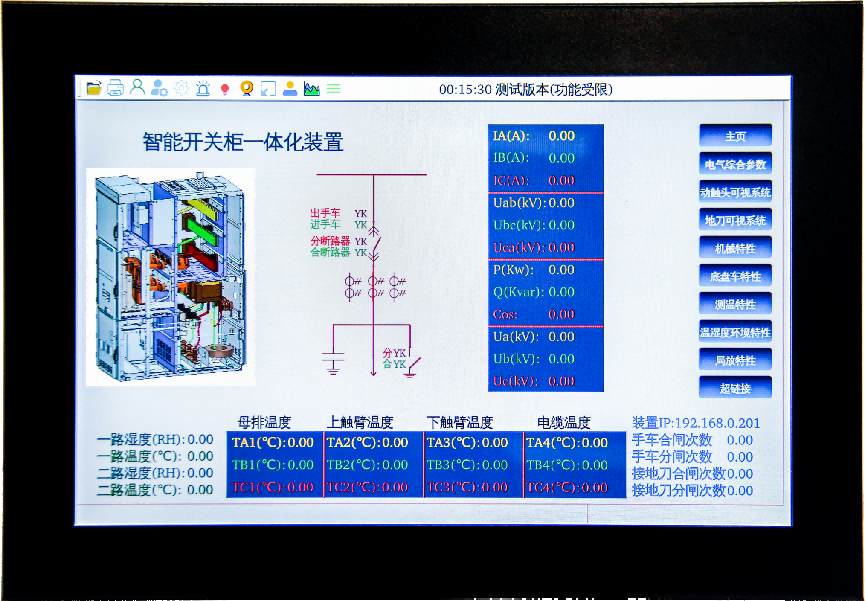
10KV開關柜一鍵順控和110KV變電站一鍵順控哪些地方不同

LoRa無線一鍵報警安防建設系統
一鍵斷電開關的種類有哪些
一鍵斷電開關的安裝方法是什么
一鍵斷電開關的控制原理是什么
變電站一鍵順控系統和開關柜一鍵順控有區別嗎?
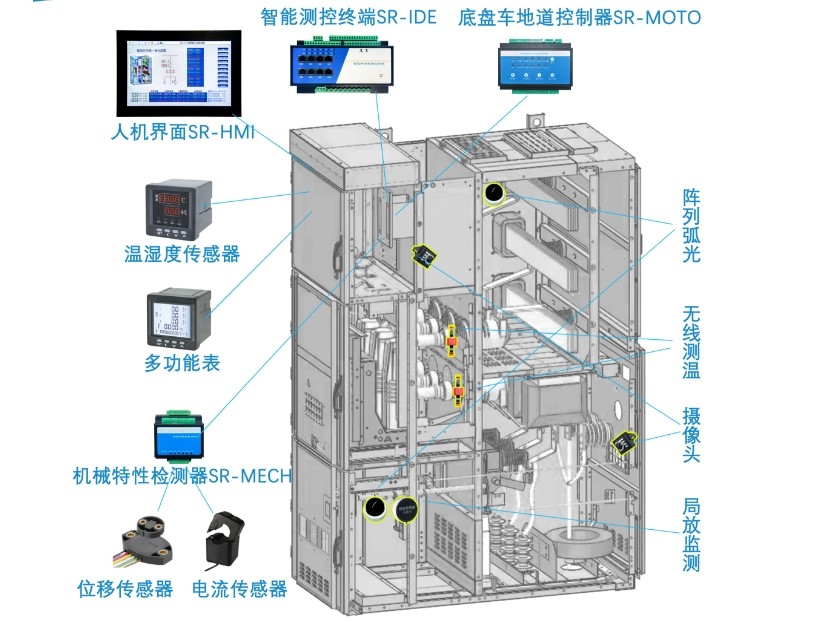
開關柜一鍵順控的技術難點和優勢、發展趨勢?
智能開關柜能如何實現“可視化一鍵順控”?
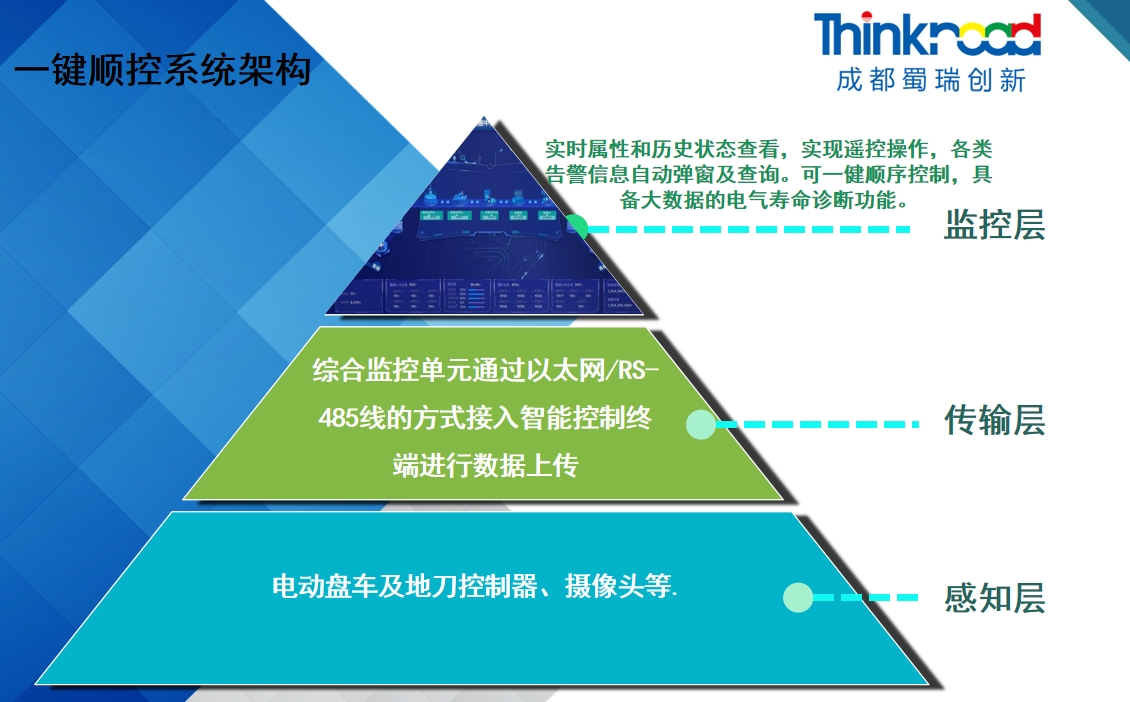
寶塔面板一鍵免費部署LobeChat聊天機器人開發自己私有的ChatGPT
簡析智慧燈桿一鍵告警功能的實用場景

智慧桿一鍵報警連入網關后無法對講是什么原因?






 工商網監
工商網監
評論