 假設不懂數據科學,如何解決問題?
假設不懂數據科學,如何解決問題?
編者按:MIT博士、Salesforce前SVP、數據科學家Rama Ramakrishnan提醒,在從事數據科學項目時,養成首先創建基線的良好習慣,迅速交付價值,避免自我欺騙。
準備解決一個數據科學問題時,你可能很想單刀直入,直接開始創建模型。
別這么做。首先創建一個常識基線。
常識基線是指,假設你不懂數據科學,你會如何解決這個問題。假設你對監督學習、無監督學習、聚類、深度學習之類一無所知。現在問問你自己,如何解決手頭的問題?
對于經驗豐富的從業者而言,首先創建常識基線是常規操作。
他們會首先思考數據和問題,發展某種關于什么能使解決方案更好的直覺,以及考慮一些需要避免的地方。他們會和商業終端用戶討論,這些用戶之前可能通過手工方式解決這個問題。
有經驗的從業者會告訴你,常識基線不僅實現起來很簡單,而且常常難以打敗。即使數據科學模型確實戰勝了這些基線,優勢也可能很小。
直銷郵件
讓我們來看三個例子,從一個直銷的例子開始。
你為一家服裝零售商工作,手頭有一個顧客數據庫,其中包括了去年從你處買過東西的每個顧客的信息。
你希望給一些顧客發郵件,宣傳最新的春裝,預算可以支持給數據庫中的100000名顧客發送郵件。
你應該選擇哪100000個呢?
你大概已經在打算創建一個訓練集和一個測試集,并訓練一些監督學習模型了。也許是隨機森林或梯度提升。甚至是深度學習。
這些都是很強大的模型,你的工具箱也應該常備這些。但是,先問自己一個問題:“如果這些方法都不存在,我必須靠自己的小聰明解決這個問題,那么我該如何挑選出這100000個顧客?”
常識告訴你,應該選擇那些最忠誠的顧客,畢竟,他們是最可能對郵件感興趣的人。(不過,其實這個問題也可以從增量建模(Uplift Modeling)的角度考慮,可能不管你發不發郵件,最忠誠的顧客總是傾向于到你這兒買東西,反而是給不那么忠誠的顧客發郵件,增量更高。)
那么,你將如何衡量忠誠度呢?直觀地說,忠誠顧客傾向于多購買,多花錢。所以你可以計算每位顧客去年在你那里花了多少錢,到你那里買過多少次東西?
如此計算之后,查看下結果,你會發現它很好地描述了忠誠度。但是你也注意到,這樣會選中那些在上半年很忠誠、下半年“失蹤”的客戶。
通過查看顧客在你處的最近購買情況,可以修正這一問題。如果花費和購買頻率相似,那么昨天在你處買東西的顧客,價值比11個月前購買過的顧客要高。
總結一下,你為每位顧客計算:
過去12個月在你處的花銷
過去12個月在你處發生的交易數量
上一次交易到現在有幾周
你可以基于上面的三個測度排序顧客列表:
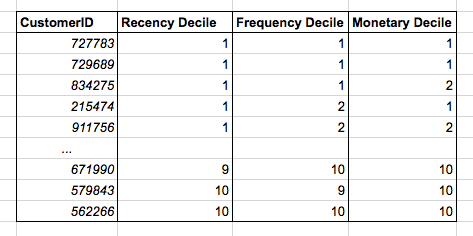
測度轉換為10分制(十分位)
選中其中的前100000名顧客。
恭喜!你剛剛發現的是價值很高的RFM(Recency-Frequency-Monetary)啟發式算法,直銷領域久經考驗的主力算法。
萬一你好奇R、F、M中哪個最重要,據研究R最重要。
RFM方法易于創建,易于解釋,易于使用。最妙的是,它出人意料地有效。有經驗的直銷從業者會告訴你,即使當更復雜的模型戰勝RFM的時候,兩者之間的差距也比你想象的要小得多,讓你懷疑是否有必要構建復雜模型。
推薦系統
接下來,我們來看一個推薦系統的例子。
你工作的服裝零售商有一家電商網站,需要你創建產品推薦區域,該區域將顯示在首頁上。
服裝推薦需要個性化——如果訪問者之前訪問過你的站點,你需要基于歷史數據推薦符合他們口味的商品。
有些書整本都在討論這一主題,而GitHub上也有許多專門為此開發的庫。你是不是應該直接開始應用矩陣分解(點擊閱讀)?
到了一定時候你大概應該嘗試下矩陣分解,但剛開始你不應該直接應用矩陣分解。你首先應該創建一個常識基線。
向訪問者展示相關商品的最簡單的方案是什么?
暢銷商品!
是的,它們并不是個性化的。但是暢銷商品之所以是暢銷商品,正是因為有足夠的訪問者購買了它們。所以從這個意義上說,很大可能至少相當一部分訪問者會對這些商品感興趣,即使這些商品并不是根據訪問者的興趣定制的。
此外,不管怎么說,你都需要準備好顯示暢銷商品,畢竟你需要向沒有數據的初次訪問者展示一些東西。
選中暢銷商品很簡單。確定一個時間窗口(最近24小時、最近7天、……),確定一項測度(利潤、訪問量、……),確定計算周期(每小時、每日、……),編寫查詢請求并加以自動化。
并且你可以調整這一基線,稍稍加上一點個性化。比如說,如果記住了訪問者上次訪問站點瀏覽的商品類別,那么你可以直接從這一具體類別中選出暢銷商品(而不是選出所有類別的暢銷商品),在推薦區域展示。例如,上次訪問時瀏覽過女裝類別的訪問者,可以向她展示暢銷女裝。
需要澄清的是,上面描述的“調整”涉及開發工作,因為你需要“記住”不同訪問會話的信息。但是,如果你計劃創建、交付基于模型的個性化推薦,那么這些收集信息的開發工作是免不了的。
定價優化
最后一個例子是零售定價優化。
作為一個服裝零售商,你販賣季節性商品——例如,毛衣——在季節末,需要清庫存,以便為下一季的商品留出空間。服裝業對此的標準做法是減價促銷。
如果折扣太小,最后時刻你將不得不以廢品回收的價格出清積壓的季節性商品。如果折扣太大,季節性商品會很快售罄,但是你損失了賺取更多金錢的機會。
在服裝行業,平衡這兩者的藝術稱為清倉優化或減價優化。
有大量關于如何使用數據科學技術建模和求解這一問題的文獻(例如,牛津價格管理手冊的第25章,利益申明:這書是我寫的)。但是讓我們首先考慮下如何創建一個常識基線。
想象一下,手頭有100單位的毛衣,這一季還有4周。每周可以調一次價,也就是說你有4次出手調整的機會。
你應該從本周就開始減價嗎?
好吧,首先考慮下,你覺得如果維持價格不變,下面4周可以賣掉多少單位毛衣?
我們如何估計這一數值?最簡單的做法是看看上一周賣了多少。
假定上一周賣了15單位。如果接下來4周和上一周情況差不多,那么我們將賣出60單位,到了季節末會積壓40單位。
不妙。明顯需要減價。
零售商有時使用折扣階梯,八折、七折、六折……最簡單的做法是首先邁上折扣階梯的第一階,也就是下周開始八折促銷。
快進一周。比方說賣掉了20單位,剩下80單位和3周。假設剩下3周維持相同的賣出率(例如,20單位每周),總共將賣出60單位,季節末仍將積壓20單位。所以你需要在折扣階梯上往下走一階,下周開始增加促銷力度,改為七折出售。
以此類推,在每周重復以上策略,直到季節末。
取決于賣出率對折扣的響應程度,不同的商品可能遵循不同的折扣路徑。比如,相比下圖中的商品A,商品B需要更大力度的折扣刺激。
這一常識基線可以通過非常簡單的if-then邏輯實現。和上面的個性化推薦例子一樣,我們也可加以調整(例如,之前我們直接使用上一周的銷售單位數“預測”未來幾周的銷售量,但是我們也可以轉而使用前幾周的平均銷售量)。
搞定了基線之后,你可以勇往直前,釋放數據科學的全部火力。但是不管你做了什么,都需要將所得結果與基線進行比較,從而精確地評估工作的回報。
結語
在很多問題上,古老的二八法則仍然適用。常識基線經常能夠讓你以很快的速度取得80%的價值。
隨著越來越多數據科學技術的應用,你將看到更高的價值,但價值增長的速度越來越慢。取決于具體情況,你當然可以決定使用一個復雜方案榨取最后一點價值。不過你應該在很清楚增加的成本和收益的前提下才這么做。
常識基線能從根本上保護你避免理查德·費曼提到的著名危險:
首要原則是,你千萬不能愚弄自己,最容易被愚弄的人是你自己。
創建數據科學模型可能是一個非常享受的過程,你很容易哄騙自己,你所創建的復雜、傾注了很多心血、精心調整的模型(從成本/收益角度上而言)更好,而實際上并沒有那么好。
常識基線能夠迅速交付價值,也能避免自我欺騙。請養成首先創建基線的好習慣。
-
深度學習
+關注
關注
73文章
5506瀏覽量
121265 -
數據科學
+關注
關注
0文章
165瀏覽量
10078
原文標題:數據科學項目的第一步:創建常識基線
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦









 工商網監
工商網監
評論