

目錄
前言... 1
1、DDR4介紹... 2
1.1、DDR4與DDR3不同之處... 2
1.2、POD 和SSTL的比較... 2
1.3、ODT控制... 4
1.4、DDR4高速訊號(hào)傳輸技術(shù)... 5
2、DDR4 Simulation Challenges. 7
2.1、使用IBIS 5.0 power aware nodel7
2.2、使用Statistical-based analysis. 8
2.3、Random bit pattern with DBI coding. 8
2.4、Unit Interval(UI)單位時(shí)間間隔... 9
3、DDR4 3200 Simulation. 9
3.1、no on-die de-cap. 12
3.2、on-die de-cap at TX. 13
3.3、on-die de-cap at TX and Rx. 17
3.4、TransientEYE vs. QuickEYE. 18
3.5、PRBS vs. DBI patterns. 19
4、Compliance Test21
4.1、[Circuit] [Tool Kits] [Virtual Compliance for DDR4]21
4.2、Presetting dialog for assigning net mapping. 21
4.3、Net Classification for net type, group and IO power22
4.4、DDR settings. 22
4.5、Report Options. 24
4.6、Self-Delay. 24
4.7、Switch to different tabs and press [Run][Run All tables] to get other reported parameters.26
4.8、Sing-off report28
5、問(wèn)題與討論Q&A.. 29
參考... 33
前言
DDR4作為目前最新一代的量產(chǎn)SDRAM記憶體,其高速低功耗特性滿足了眾多消費(fèi)者的需求。但是另一方面,對(duì)于硬件設(shè)計(jì)人員來(lái)講,DDR4的高速率非常容易引起SI問(wèn)題,一旦出現(xiàn)DDR4 Margin測(cè)試Fail之類的問(wèn)題,會(huì)讓很多設(shè)計(jì)者感到頭疼,Debug過(guò)程非常困難。
本文介紹了DDR4技術(shù)的特點(diǎn),并簡(jiǎn)單介紹了ANSYS工具用來(lái)仿真DDR4的過(guò)程。文章中主要介紹的對(duì)象為DDR4 3200MHz內(nèi)存,因?yàn)橛布O客對(duì)DDR4性能的不斷深挖,目前已經(jīng)有接近5000MHz的量產(chǎn)內(nèi)存,比如芝奇推出的TridentZ系列速度最快可達(dá)到4700MHz,并且還在不斷提高。
本文參考***一個(gè)論壇,筆者在學(xué)習(xí)的過(guò)程中,在原作的基礎(chǔ)上進(jìn)行整理,并且參考鎂光和DesignCon論壇諸多經(jīng)典文章,總結(jié)出了個(gè)隨筆,后來(lái)發(fā)現(xiàn)文章過(guò)于冗長(zhǎng),故又刪減了一半多帶給大家。因筆者水平有限,錯(cuò)誤之處在所難免,希望各位讀者批評(píng)指正!
1、DDR4介紹
1.1、DDR4與DDR3不同之處
相對(duì)于DDR3, DDR4首先在外表上就有一些變化,比如DDR4將內(nèi)存下部設(shè)計(jì)為中間稍微突出,邊緣變矮的形狀,在中央的高點(diǎn)和兩端的低點(diǎn)以平滑曲線過(guò)渡,這樣的設(shè)計(jì)可以保證金手指和內(nèi)存插槽有足夠的接觸面從而確保內(nèi)存穩(wěn)定,另外,DDR4內(nèi)存的金手指設(shè)計(jì)也有明顯變化,金手指中間的防呆缺口也比DDR3更加靠近中央。當(dāng)然,DDR4最重要的使命還是提高頻率和帶寬,總體來(lái)說(shuō),DDR4具有更高的性能,更好的穩(wěn)定性和更低的功耗,那么從SI的角度出發(fā),主要有下面幾點(diǎn), 下面章節(jié)對(duì)主要的幾個(gè)不同點(diǎn)進(jìn)行說(shuō)明。
| Items spec | DDR3 | DDR4 |
| Voltage(VDD/VDDQ/VDP) | 1.5 | 1.2 |
| Rate(Mbps) Data | 1600 | 3200 |
| Vref | External(VDD/2) | Internal(Training) |
| Data IO | SSTL | POD |
| Bus Inversion(DBI) Data | No | Supported |
表1DDR3和DDR4差異
1.2、POD 和SSTL的比較
POD作為DDR4新的驅(qū)動(dòng)標(biāo)準(zhǔn),最大的區(qū)別在于接收端的終端電壓等于VDDQ,而DDR3所采用的SSTL接收端的終端電壓為VDDQ/2。這樣做可以降低寄生引腳電容和I/O終端功耗,并且即使在VDD電壓降低的情況下也能穩(wěn)定工作。其等效電路如圖1(DDR4), 圖2(DDR3)。
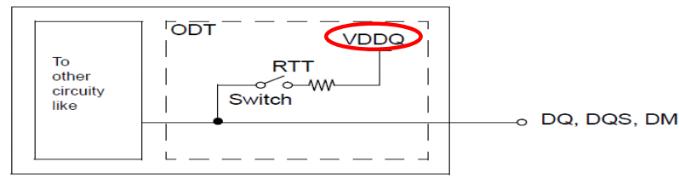
圖1 POD ((Pseudo Open Drain)
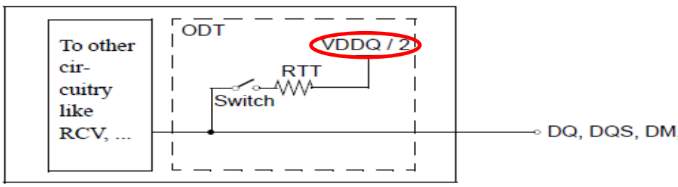
圖2 SSTL(Stub SeriesTerminatedLogic)
可以看出,當(dāng)DRAM在低電平的狀態(tài)時(shí),SSTL和POD都有電流流動(dòng)
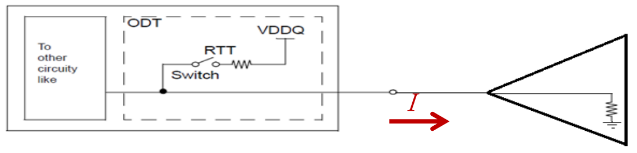
圖3 DDR4
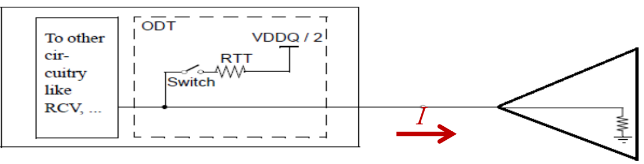
圖4 DDR3
而當(dāng)DRAM為高電平的狀態(tài)時(shí),SSTL繼續(xù)有電流流動(dòng),而POD由于兩端電壓相等,所以沒(méi)有電流流動(dòng)。這也是DDR4更省電的原因。
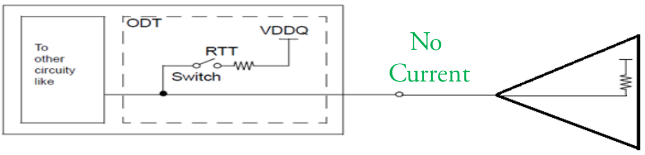
圖5 DDR4
圖6 DDR3
對(duì)于DDR4的IO來(lái)說(shuō),drive high時(shí)幾乎不耗電(下圖右的紅色虛線是電流路徑),這就是為何采用DBI+POD機(jī)制具有優(yōu)勢(shì)的原因[3]p.15,[9]p.80。
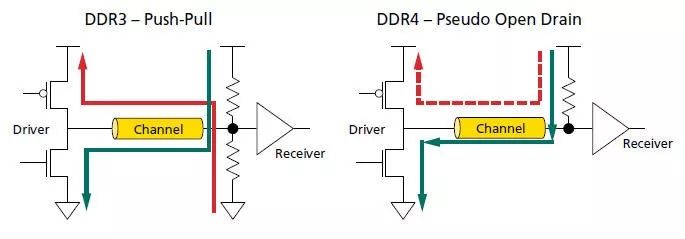
圖7 DDR3和DDR4驅(qū)動(dòng)機(jī)制
DDR4雖然drive high時(shí)候不耗電,但是在drive low的時(shí)候會(huì)消耗相比于SSTL兩倍的電。所以,勝點(diǎn)的關(guān)鍵在于較少輸出0的數(shù)量。如果將要輸出的數(shù)據(jù)bus上0比1多,DDR4會(huì)將數(shù)據(jù)翻轉(zhuǎn)以達(dá)到降低功耗的目的。
1.3、ODT控制
為了提升信號(hào)質(zhì)量, 從DDR2開(kāi)始將DQ, DM, DQS/DQS#的Termination電阻內(nèi)置到Controller和DRAM中, 稱之為ODT (OnDieTermination)。Clock和ADD/CMD/CTRL信號(hào)仍需要使用外接的Termination電阻。
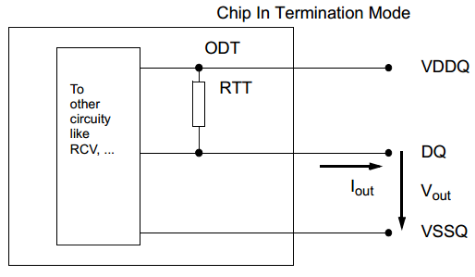
圖8On Die Termination
在DRAM中,On-Die Termination的等效電阻值通過(guò)Mode Register (MR)來(lái)設(shè)置,ODT的精度通過(guò)參考電阻RZQ來(lái)控制,DDR4的ODT支持240, 120, 80, 60, 48, 40, 34 歐姆。
和DDR3不同的是,DDR4的ODT有四種模式:Data termination disable, RTT_NOM,RTT_WR, 和RTT_PARK。Controller可以通過(guò)讀寫(xiě)命令以及ODTPin來(lái)控制RTT狀態(tài),RTT_PARK是DDR4新加入的選項(xiàng),它一般用在多Rank的DDR配置中,比如一個(gè)系統(tǒng)中有Rank0,Rank1以及Rank2, 當(dāng)控制器向Rank0寫(xiě)數(shù)據(jù)時(shí),Rank1和Rank2在同一時(shí)間內(nèi)可以為高阻抗(Hi-Z)或比較弱的終端(240,120,80,etc.), RTT_Park就提供了一種更加靈活的終端方式,讓Rank1和Rank2不用一直是高阻模式,從而可以讓DRAM工作在更高的頻率上。
一般來(lái)說(shuō),在Controller中可以通過(guò)BIOS調(diào)整寄存器來(lái)調(diào)節(jié)ODT的值,但是部分Controller廠商并不推薦這樣做,以Intel為例,Intel給出的MRCCode中已經(jīng)給出了最優(yōu)化的ODT的值,理論上用戶可以通過(guò)仿真等方法來(lái)得到其他ODT值并在BIOS中修改,但是由此帶來(lái)的所有問(wèn)題將有設(shè)計(jì)廠商來(lái)承擔(dān)。下面表格是Intel提供的優(yōu)化方案。
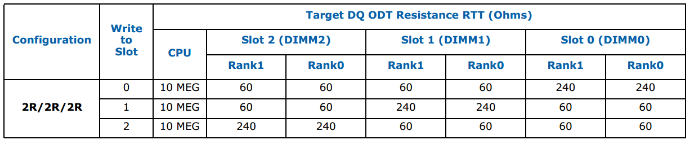
表2DQ Write ODT Table for 3DPC
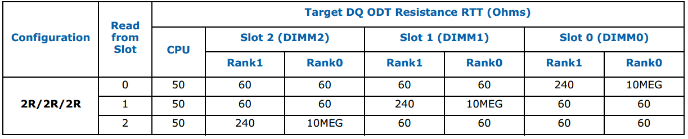
表3DQ Read ODT Table for 3DPC
1.4、DDR4高速訊號(hào)傳輸技術(shù)
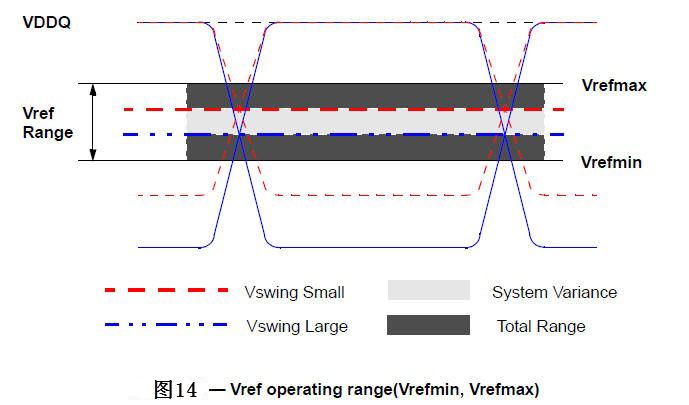
眾所周知,DDR信號(hào)一般通過(guò)比較輸入信號(hào)和另外一個(gè)參考信號(hào)(Vref)來(lái)決定信號(hào)為高或者低,然而在DDR4中,一個(gè)Vref卻不見(jiàn)了,先來(lái)看看下面兩種設(shè)計(jì),可以看出來(lái),在DDR4的設(shè)計(jì)中,VREFCA和DDR3相同,使用外置的分壓電阻或者電源控制芯片來(lái)產(chǎn)生,然而VREFDQ在設(shè)計(jì)中卻沒(méi)有了,改為由芯片內(nèi)部產(chǎn)生,這樣既節(jié)省了設(shè)計(jì)費(fèi)用,也增加了Routing空間。
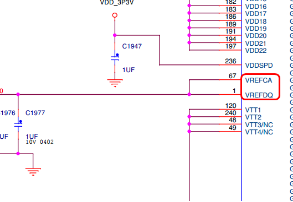
圖9DDR3設(shè)計(jì)
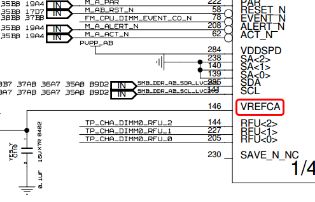
圖10 DDR4設(shè)計(jì)
DDR3采用SSTL,Vref=VDDQ/2;DDR4采用PODL,Vref是不固定的,會(huì)隨VDDQ的AC變動(dòng)而變動(dòng)Vref=((2Rs+Rt)/(Rs+Rt))*VDDQ/2 [9]p.18/25/27。
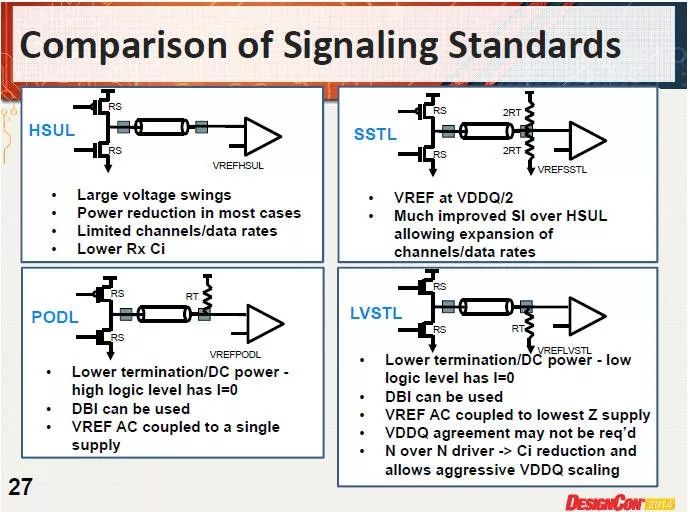
圖11SSTL和PODL技術(shù)區(qū)別
因?yàn)閂ref的不同,Vih/Vil都會(huì)有差異,可以通過(guò)調(diào)整ODT來(lái)看Vref的區(qū)別,用一個(gè)仿真的例子來(lái)說(shuō)明。對(duì)于DDR3,調(diào)整ODT波形會(huì)上下同步浮動(dòng),而調(diào)整DDR4 OOT的時(shí)候,波形只有一邊移動(dòng)。
圖12DDR3仿真結(jié)果
圖13DDR4仿真結(jié)果
DDR4增加了DBI(Data BusInversion)、CRC(Cyclic Redundancy Check)、CA parity等功能,讓DDR4記憶體在更快速更省電的同時(shí)亦能改善資料傳輸及儲(chǔ)存的可靠性。[2],[9]p.20,[14]p.6
2、DDR4Simulation Challenges
2.1、使用IBIS5.0 power aware nodel
鎂光的文件【23】說(shuō)明提供IBIS 5.0 power aware model,供做DDR4 PI以及SS0模擬,這些模型內(nèi)含【Composite Current】Data,可以讓模擬更準(zhǔn)確。鎂光是業(yè)界做IBIS model做的非常好的典范,也感謝其在官網(wǎng)大方分享DDR4 IBISSPICE model。
注意不要抓到?jīng)]有【CompositeCurrent】Data的舊model,那就不是IBIS 5.0 power aware model
鎂光還提供on-die die-capmodel.ckt(VDDQ-VSSQ),供IBIS模擬時(shí)外掛,并且在文件中強(qiáng)調(diào)模擬必須考慮這些部分才能跟HSPICE model一樣準(zhǔn)確。而這one-die de-cap從文件的示意圖來(lái)看【23】p.6,只掛在TX端。
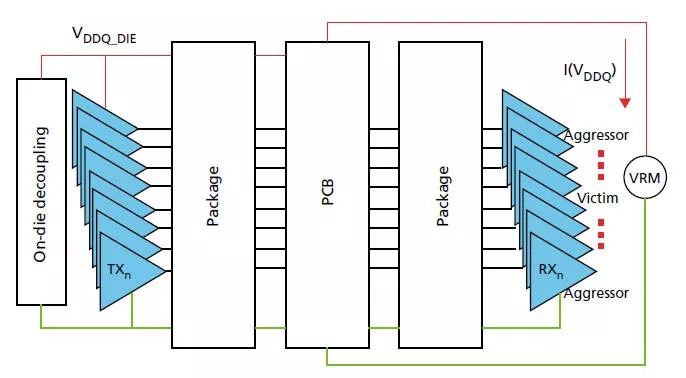
圖15DDR4拓?fù)?/p>
2.2、使用Statistical-basedanalysis【13】【18】
DDR4要求BER=1e-16下的規(guī)格,通過(guò)使用IBIS power aware model與Statistical-basedanalysis,可以有效的評(píng)估DDR4設(shè)計(jì)優(yōu)劣。
2.3、Random bit pattern with DBI coding【3】p.6
DBI是DDR4一個(gè)非常關(guān)鍵的省電技術(shù),直接會(huì)影響暫態(tài)電流與眼圖的模擬結(jié)果,這需要整個(gè)byte(8 bits)一起考慮。目前的方法先把整組random bit pattern整理過(guò),再喂給circuit simulation。
圖16DBI技術(shù)
注意:要模擬DDR4通道內(nèi),所有的DQ/DQS/Addr/Cmd同時(shí)動(dòng)作時(shí)的SI與PI(SSO/SSN),最好的做法是用IBIS 5.0 power aware model與Transientanalysis。QuickEYE雖然可以看眼圖,并且得到與Transientanalysis極為相似的結(jié)果,但無(wú)法做SI+PI分析,原因是QuickEYE是單獨(dú)激發(fā)每個(gè)EYESource得到step response,不是同時(shí)激發(fā),也就是無(wú)法考慮SSN效應(yīng)。
2.4、Unit Interval(UI)單位時(shí)間間隔
UI是做眼圖分析十分重要的一個(gè)參數(shù),在理解單位時(shí)間間隔的基礎(chǔ)后,方可以容易的定義與眼圖的時(shí)間軸上的失真相關(guān)的術(shù)語(yǔ)。例如:在描述規(guī)范標(biāo)準(zhǔn)和數(shù)據(jù)表中的抖動(dòng)特性時(shí),通常使用術(shù)語(yǔ)“UI”。
如圖所示,不論數(shù)據(jù)速率如何,“單位時(shí)間間隔”被定義為歸一化的數(shù)據(jù)位寬度。由于單位時(shí)間間隔基本上與比特?cái)?shù)相同,1個(gè)數(shù)據(jù)位的寬度為1個(gè)單位時(shí)間間隔。水平時(shí)間軸可以以1秒或單位時(shí)間間隔為單位來(lái)表示。例如:我們需要仿真的對(duì)象為DDR4 3200Mbps,在3200Mbps的數(shù)據(jù)流中,1個(gè)單位時(shí)間間隔為1/3.2e9=312.5ps。
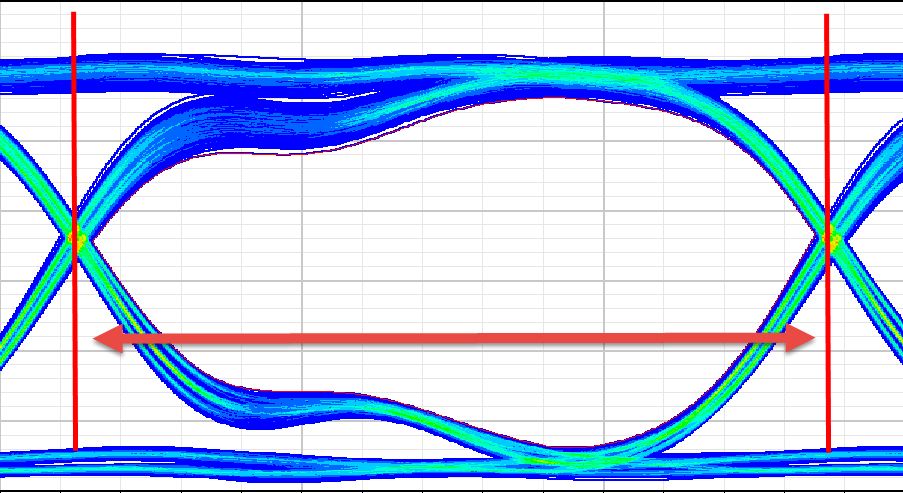
圖17 仿真單位時(shí)間間隔
3、DDR43200 Simulation
使用鎂光DDR4 MT40A512M16JY-075E(IBIS 5.0 power aware model),配合Siwave 2017.2內(nèi)的Siwizard功能自動(dòng)在Designer內(nèi)產(chǎn)生電路,自動(dòng)連接Siwave內(nèi)的DDR4真是DIMMmodel,做DDR4 3200的模擬分析。
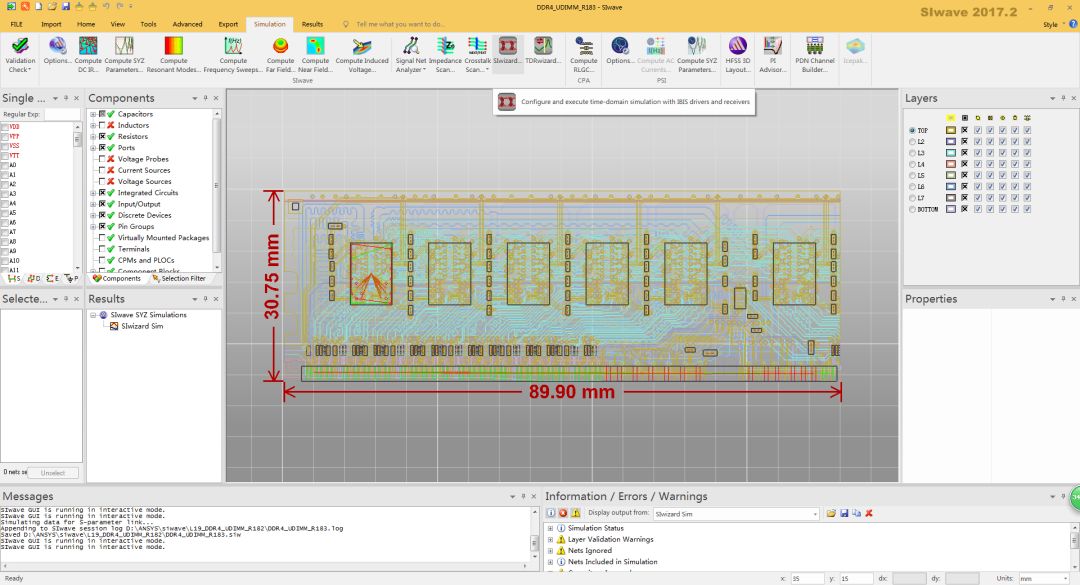
圖18PCB導(dǎo)入siwave
在導(dǎo)入DDR4的PCB文件后,按照Siwave Workflow Wizard完成PCB文件的設(shè)置,然后選擇Simulation菜單下的Siwizard,添加需要仿真的DQ/RDQ單端走線和DQS/RDQS差分走線,這幾組走線共同組成了內(nèi)存U1的數(shù)據(jù)DQ/DQS信號(hào)線。
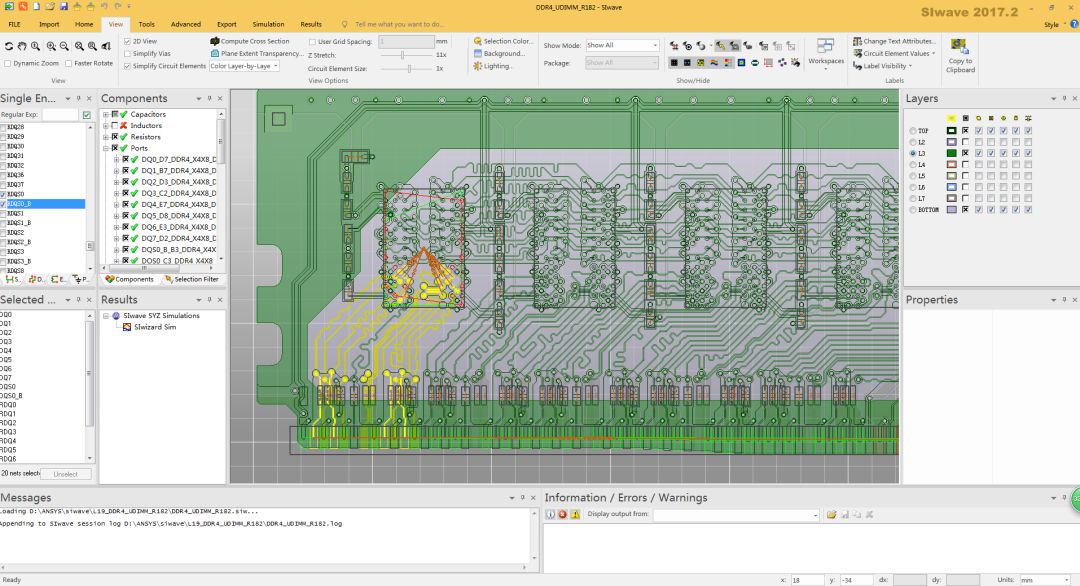
圖19 左側(cè)內(nèi)存顆粒的DQ/DQS走線示意
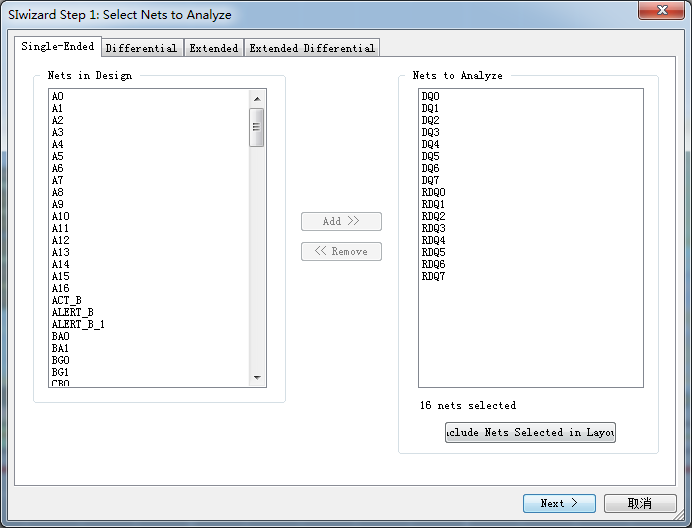
圖20 Siwizard設(shè)置向?qū)?/p>
將J1設(shè)置為Driver,U1設(shè)置為Receiver,IBIS component選擇我們需要仿真的MT40A512M16JY,IBIS Model選擇對(duì)應(yīng)的DQ/DQS,使仿真電路工作在3200Mhz頻率下。
VRM參數(shù)中設(shè)置驅(qū)動(dòng)電壓為1.2V,寄生電感67.5nH,并聯(lián)阻抗30mΩ,輸出電感4nH,輸出電阻1mΩ。
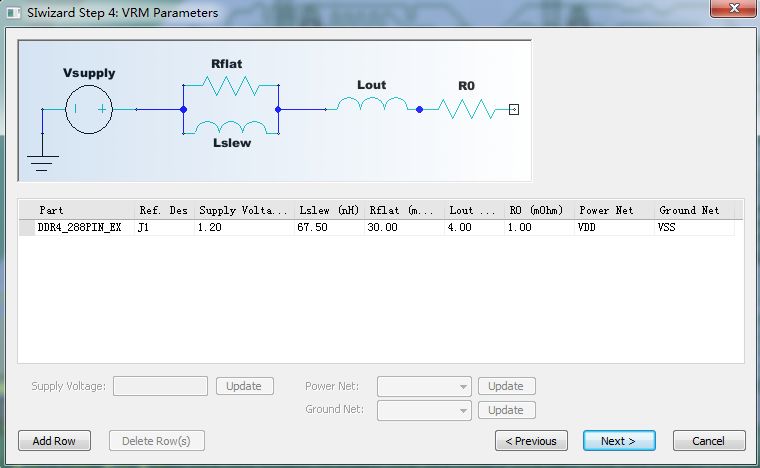
圖21 Siwizard設(shè)置向?qū)?/p>
下圖所有的電路連接(DQsingle-end, DQS differential pair),以及上圖在Siwave中做pin group與下方的port,不管是signal nets for SI或P/G nets for PI,所有連接與設(shè)定工作都是自動(dòng)完成。PCB與電路范例
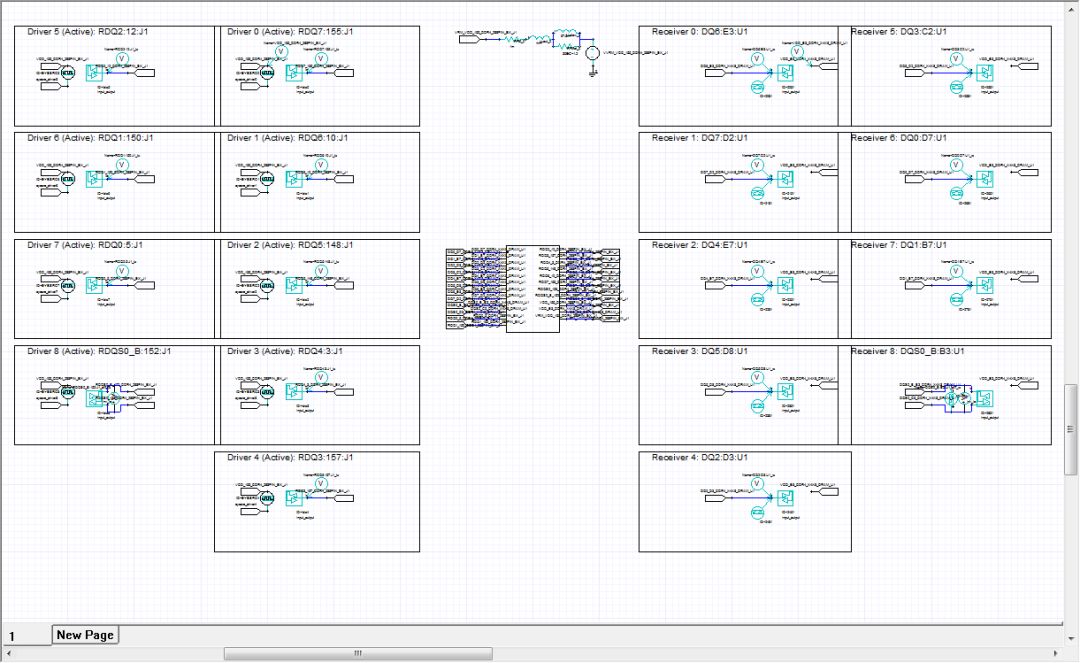
圖22circuit中生成的電路拓?fù)?/p>
整個(gè)過(guò)程從Siwave窗口開(kāi)始全部自動(dòng)完成,因?yàn)槲覀冃枰榭碫RM電流紋波情況,所以需要手動(dòng)終止,在VRM網(wǎng)絡(luò)上手動(dòng)添加Current probe,設(shè)置完成后再Circuit工程樹(shù)中,手動(dòng)開(kāi)始analyze。
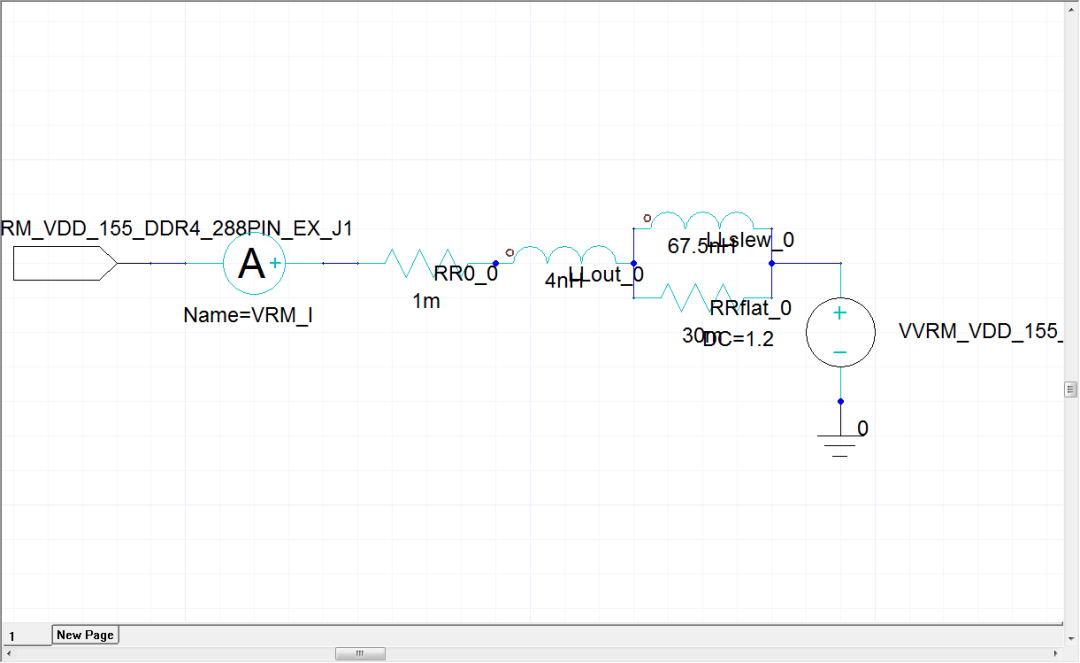
圖23VRM上添加電流probe
3.1、no on-die de-cap
下圖是DDR4 3200MHz DQ【0:7】and DQS pair(allwith DOT48),可以清楚的看到有開(kāi)啟ODT時(shí),DQ眼圖中間交叉點(diǎn)位置上移,但訊號(hào)高準(zhǔn)位維持在1.2V,DQS差分信號(hào)的眼圖交叉點(diǎn)則是維持在0V。DQS的jitter比DQ小是因?yàn)楣郼lock pattern,其它DQ則灌PRBS patter。
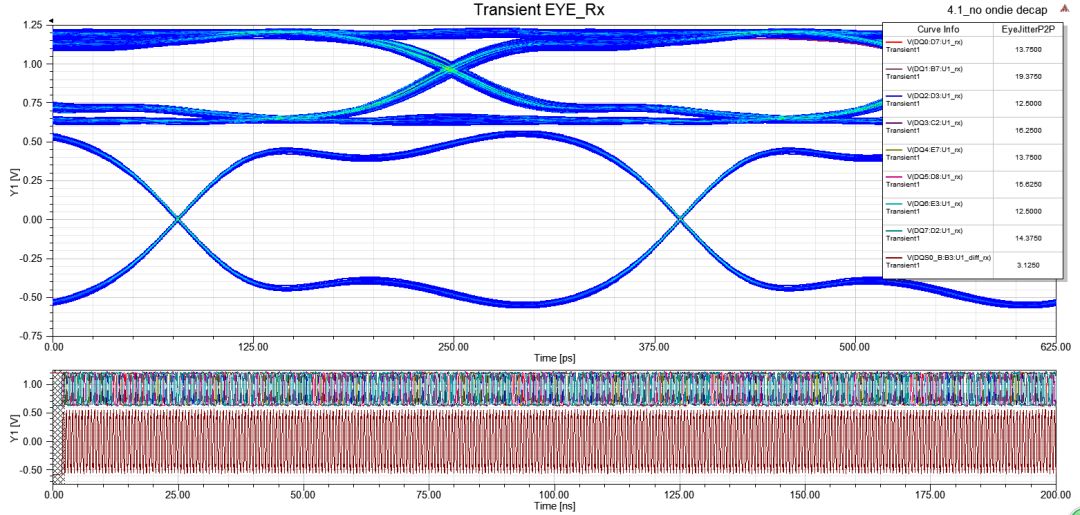
圖24 noon-die de-cap下的DQ/DQS眼圖和VRM電壓紋波(SSN)
3.2、on-die de-cap at TX
如果在Tx端VRM加on-die de-cap 10nF,會(huì)看到Tx端SS0 of P/G明顯變好,而這10nF是參考鎂光的IBIS/SPICE quality report的說(shuō)明(484pF DO pin)。為了對(duì)比,這里先將on-die de-cap設(shè)置為開(kāi)路,手動(dòng)添加10nF替代導(dǎo)入的模型。

圖25 鎂光datasheet中關(guān)于VDDQ/VSSQ Decoupling Capacitance取值的描述
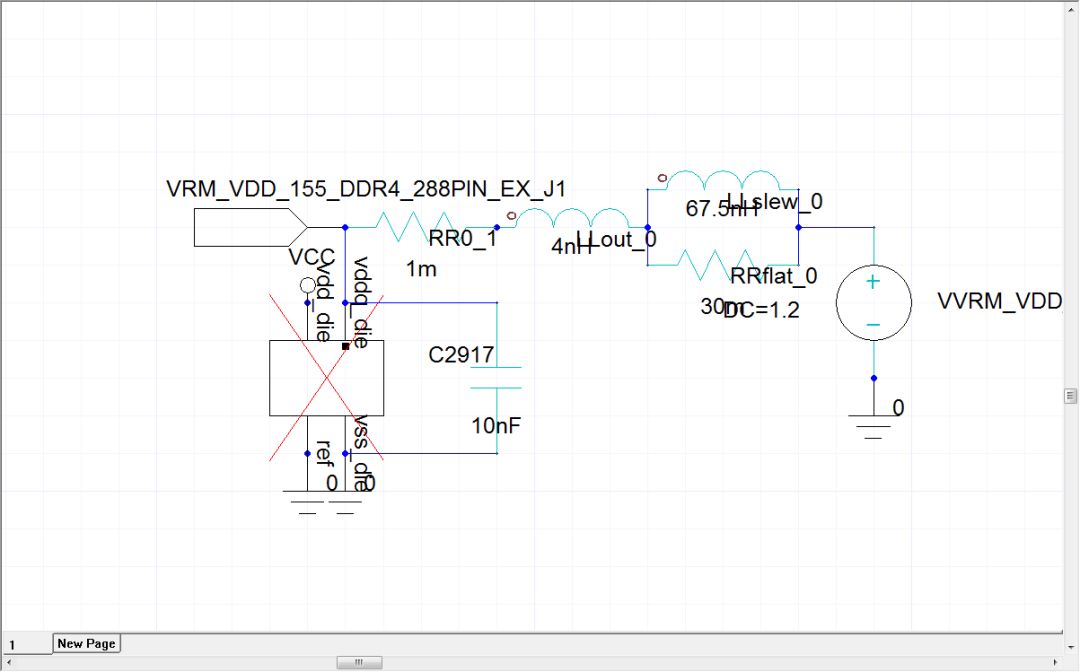
圖26 采用10nF取代on-die de-cap模型
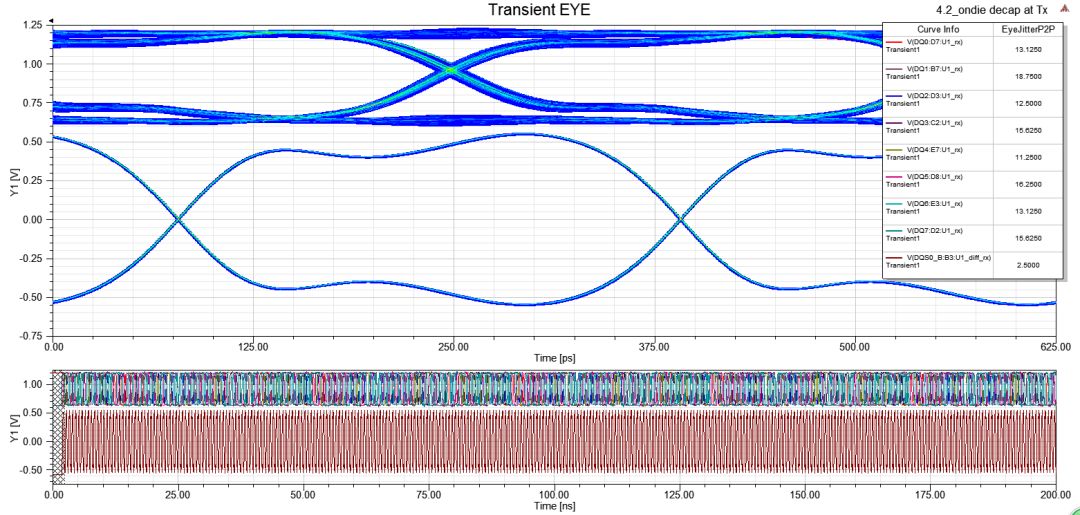
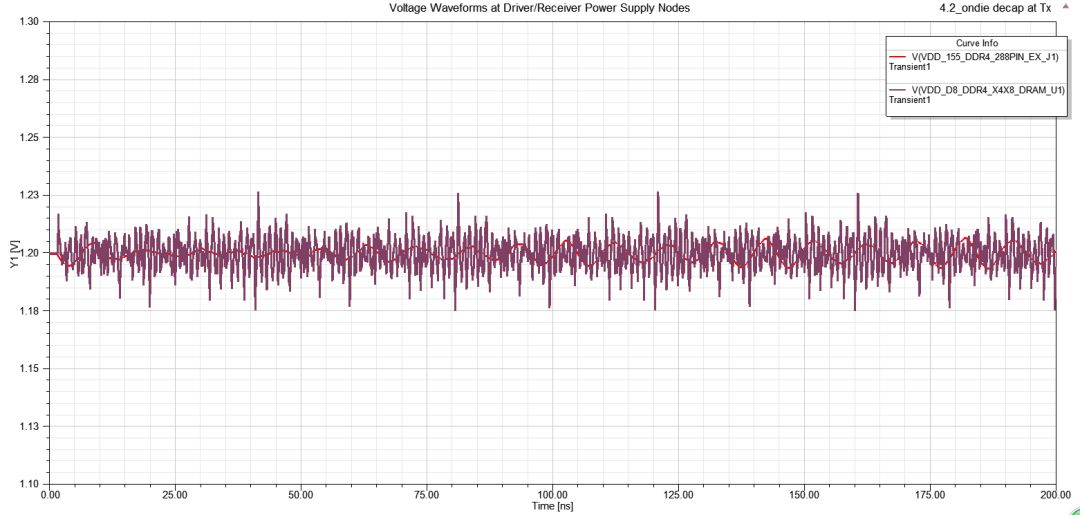
圖27VRM接10nF電容后的DQ/DQS眼圖和電壓紋波
作為對(duì)比,取消添加的10nF電容,將on-die de-cap模型設(shè)置為工作模式。可以看到結(jié)果與手動(dòng)采用10nF電容時(shí)相同。
原文作者在其帖子中提到,掛鎂光提供的de-capmodel時(shí)并沒(méi)有效果。個(gè)人猜測(cè)可能是其在導(dǎo)入或者仿真過(guò)程中出現(xiàn)錯(cuò)誤造成的。
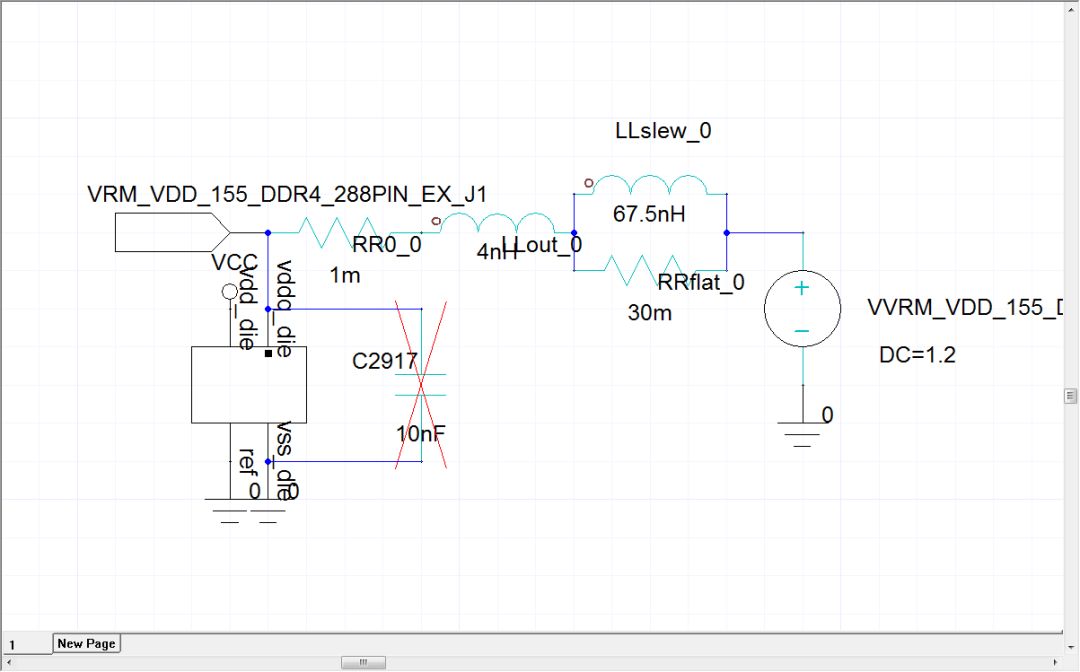
圖28 采用on-die de-cap取代10nF模型
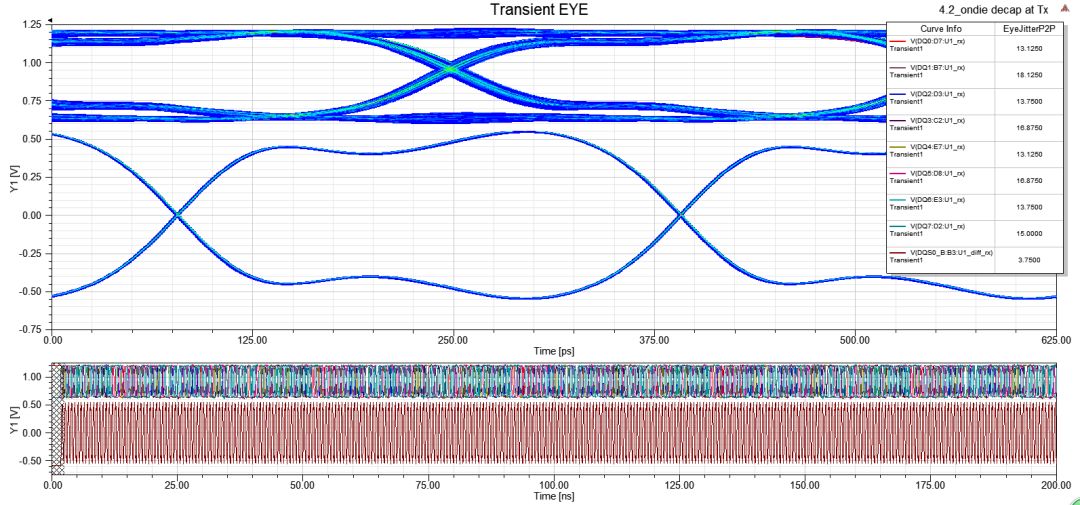
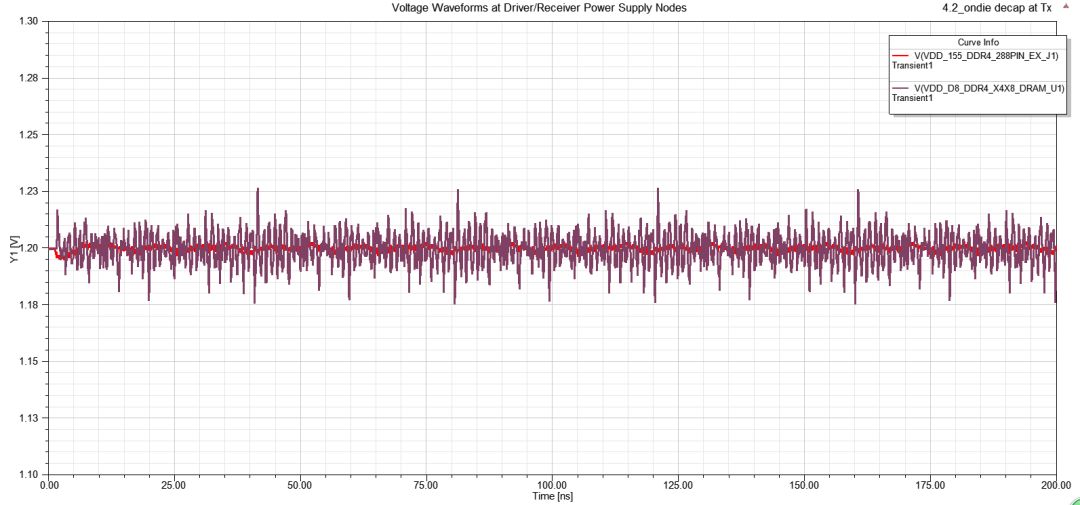
圖29 VRM外接on-die de-cap下的DQ/DQS眼圖和電壓紋波
3.3、on-die de-cap at TX and Rx
此例就算Tx與Rx端都掛on-die de-cap,P/G上的SSN確實(shí)有明顯改善,但眼圖的p-p jitter卻沒(méi)有太大差異,主因是此處的jitter是ISI與DDI引起,與bit pattern和crosstalk比較有關(guān),PI的影響是其次。
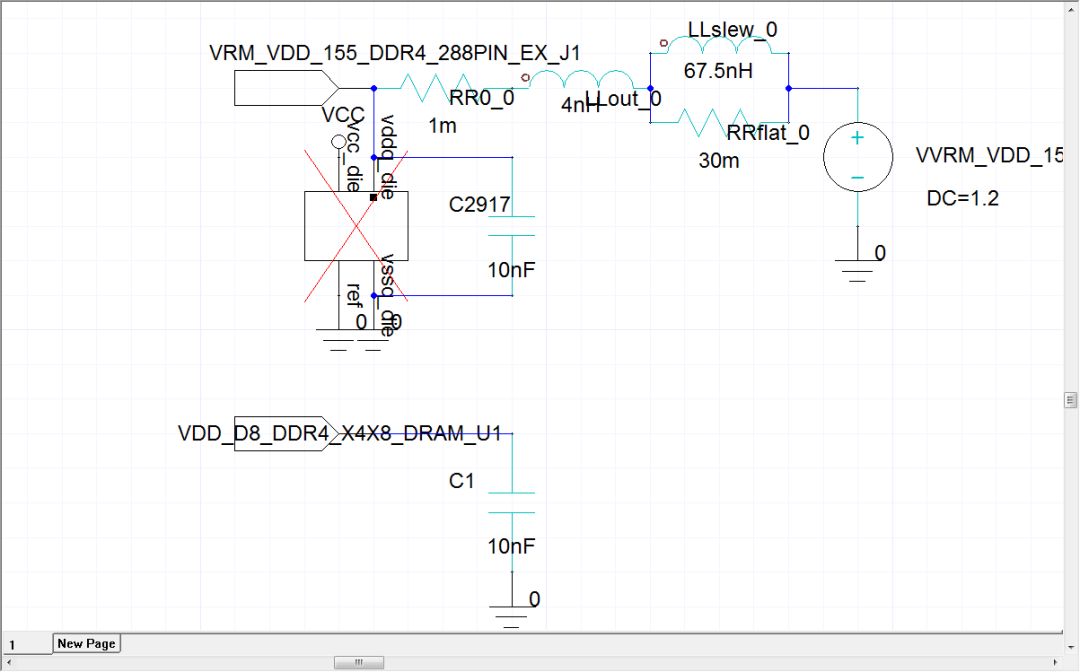
圖30 Tx與Rx端都掛10nF電容
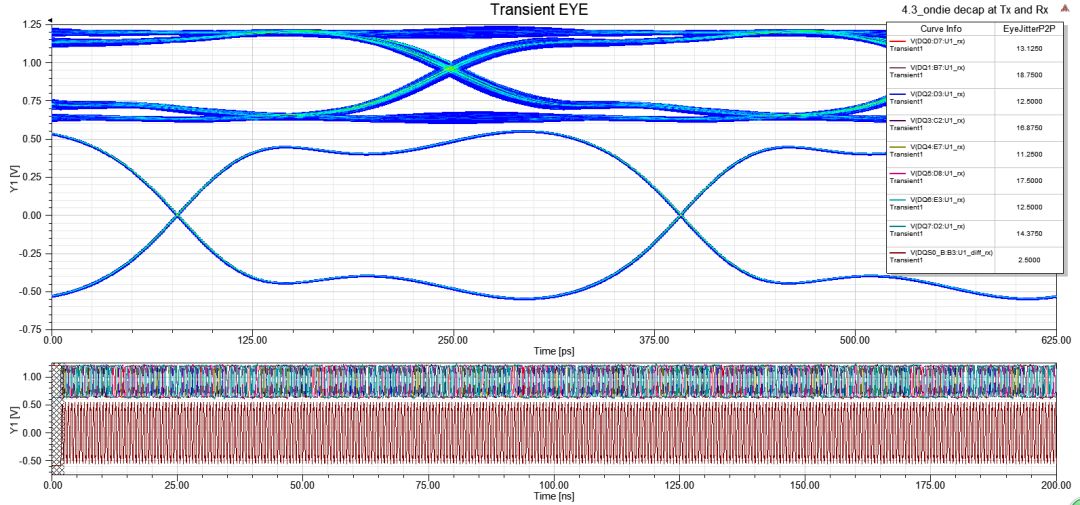
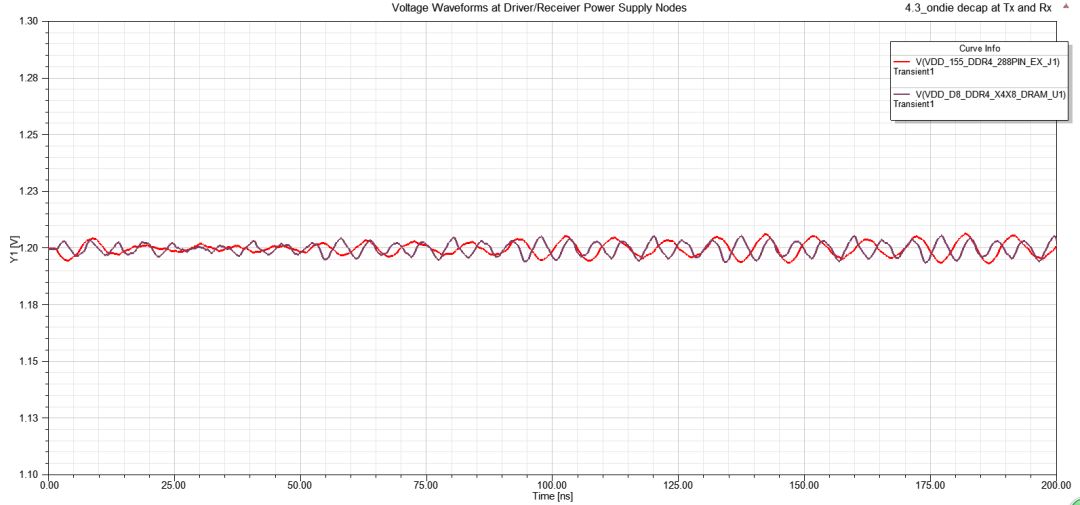
圖31 Tx與Rx端都掛10nF電容下的DQ/DQS眼圖和電壓紋波
3.4、TransientEYE vs. QuickEYE
從下圖可以看出TransientEYE比起QuickEYE眼圖,在high level的軌跡略粗一些,這就是SSN貢獻(xiàn)的效應(yīng),QuickEYE是看不出來(lái)的。
注:QuickEYE結(jié)果來(lái)自eyeprobe
3.4.1、no on-die de-cap
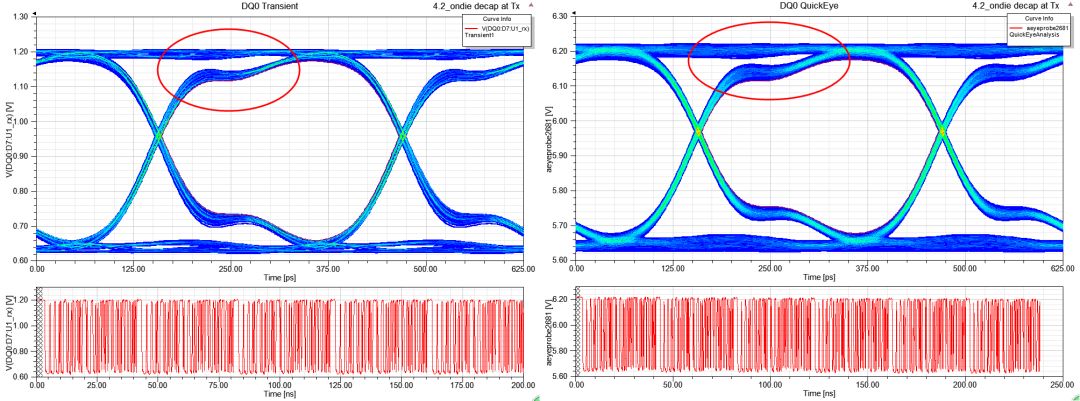
圖32 TransientEYEvs. QuickEYE
3.4.2、on-die de-cap atTx and Rx
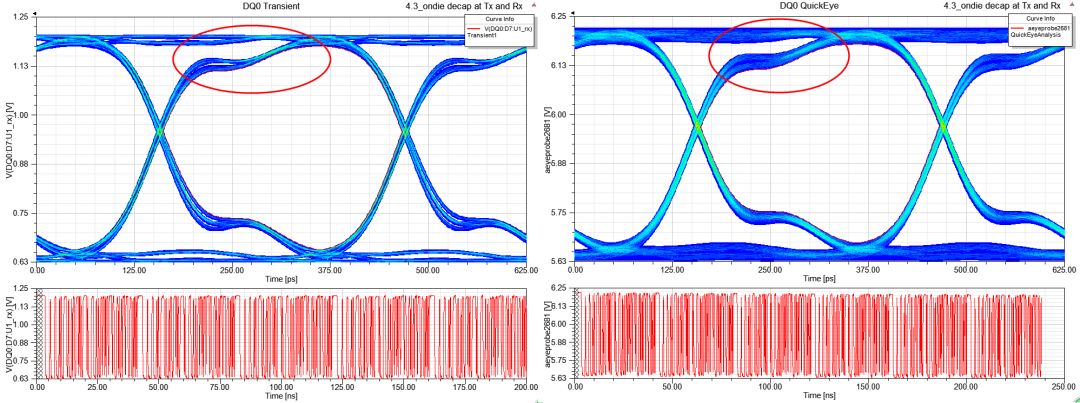
圖33 TransientEYEvs. QuickEYE
3.5、PRBS vs. DBI patterns
3.5.1、Compare SSN:Rx端的SSN明顯變小
前面介紹了DBI技術(shù),DBI技術(shù)的核心在于讓DDR4的高電平盡可能多,當(dāng)8組DQ信號(hào)中低電平占據(jù)多數(shù)時(shí),DBI將會(huì)對(duì)所有信號(hào)進(jìn)行翻轉(zhuǎn)。Circuit中無(wú)法自動(dòng)識(shí)別DDR4中的信號(hào)邏輯,所以需要手動(dòng)進(jìn)行仿真設(shè)置,將Driver端的Eyesource刪除,將IBIS模型中的Bitpattern改寫(xiě)為手動(dòng)調(diào)用外部數(shù)據(jù)。下表為所有傳輸數(shù)據(jù),可以看到DBI_0~DBI_7共8組DQ信號(hào)的高電平數(shù)量始終≥4,包含了所有可能的組合模式。
| DBI_0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| DBI_1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| DBI_2 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
| DBI_3 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| DBI_4 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| DBI_5 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| DBI_6 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| DBI_7 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
表4DBI信號(hào)bit數(shù)值
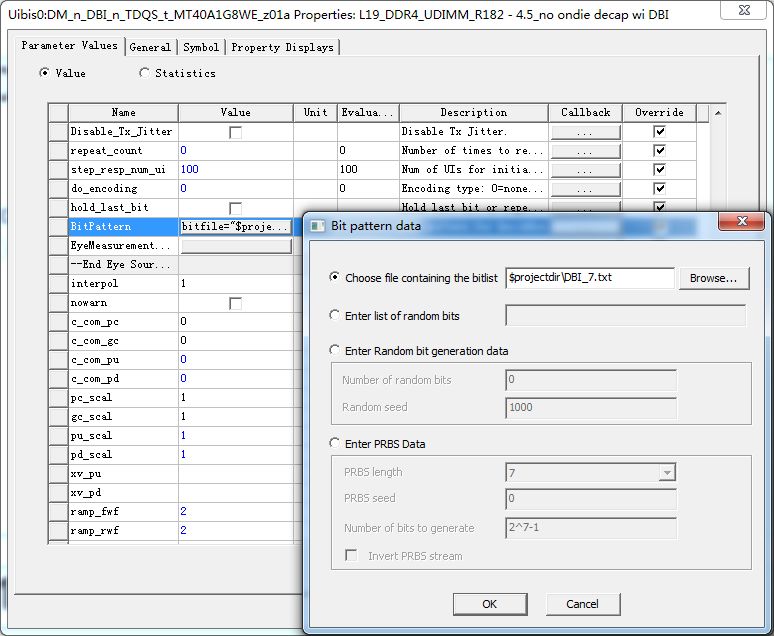
圖34 手動(dòng)模式下調(diào)用表4數(shù)值
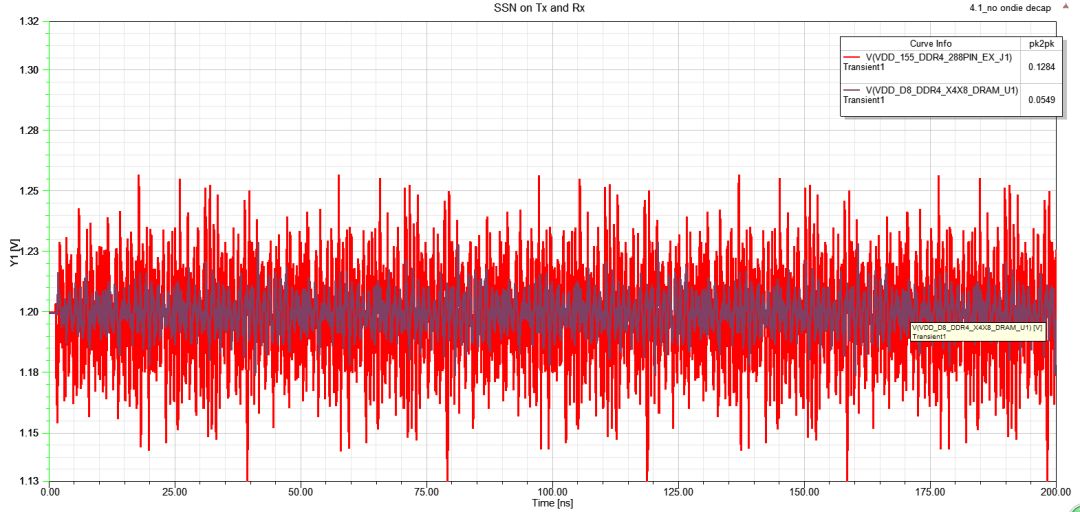
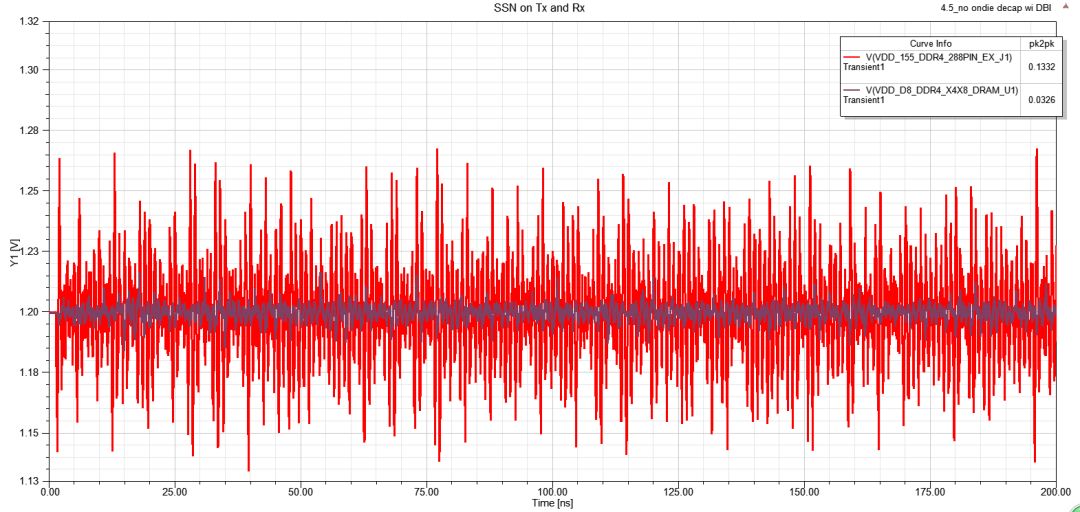
圖35DBI技術(shù)前后電壓紋波對(duì)比(后面為DBI開(kāi)啟)
3.5.2、Compare currentconsumption:current reduction 50%,amazing!!
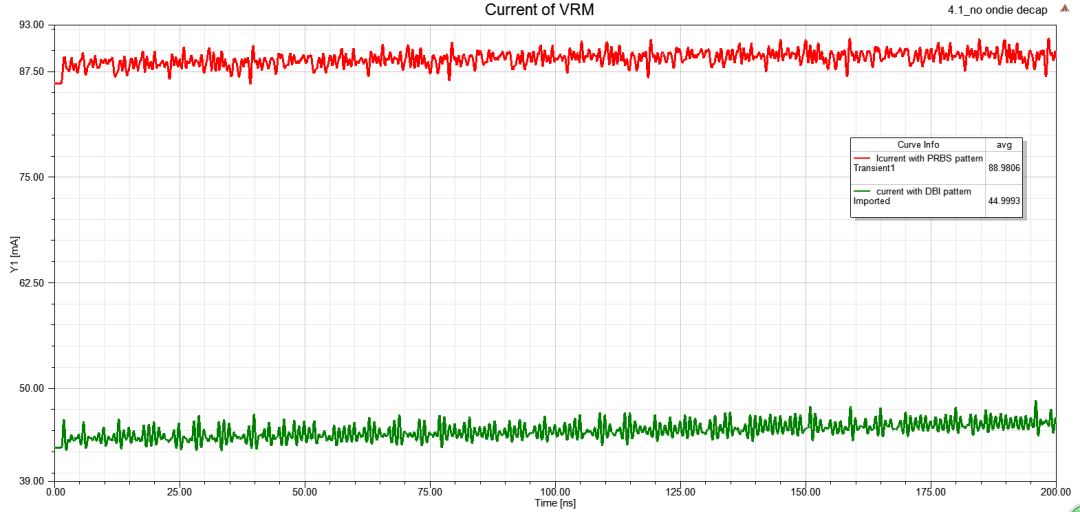
圖36DBI技術(shù)下VRM電流值對(duì)比
4、Compliance Test
4.1、[Circuit] [Tool Kits] [Virtual Compliance for DDR4]
Virtual Compliance for DDR4是新的功能項(xiàng)目,DDR4Compliance Test是舊的,建議轉(zhuǎn)到新的toolkit使用。下面在Tx和Rx加電容的前提下進(jìn)行VirtualCompliance for DDR4的仿真。
圖37 Virtual Compliancefor DDR4
4.2、Presetting dialog forassigning net mapping
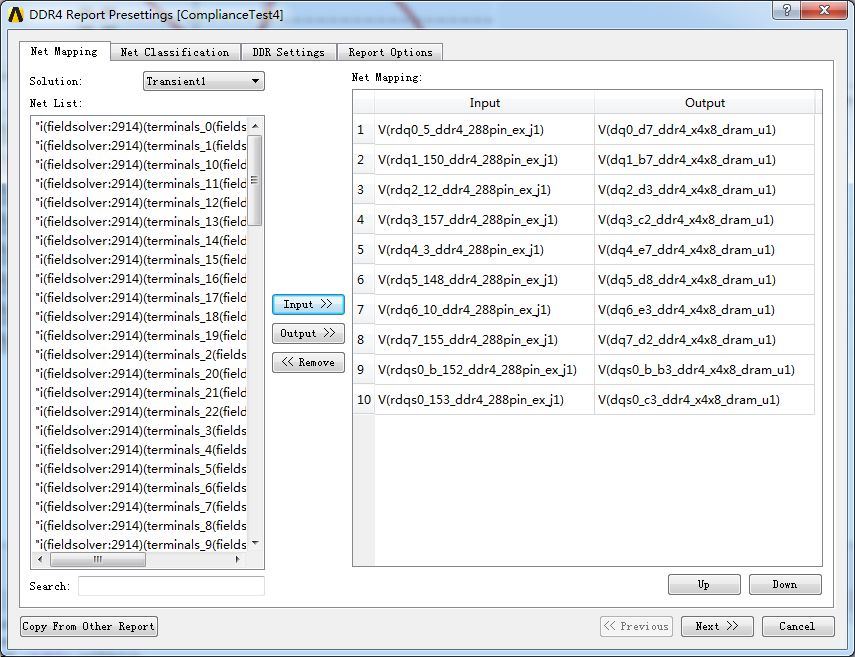
圖38 VirtualCompliance for DDR4設(shè)置向?qū)?/p>
注意:Net的In-Out的對(duì)應(yīng)連接要正確,軟件會(huì)計(jì)算self-delay(timing delay)。如果您不需要report self-delay,可以只指定output nets。
4.3、Net Classification for nettype, group and IO power
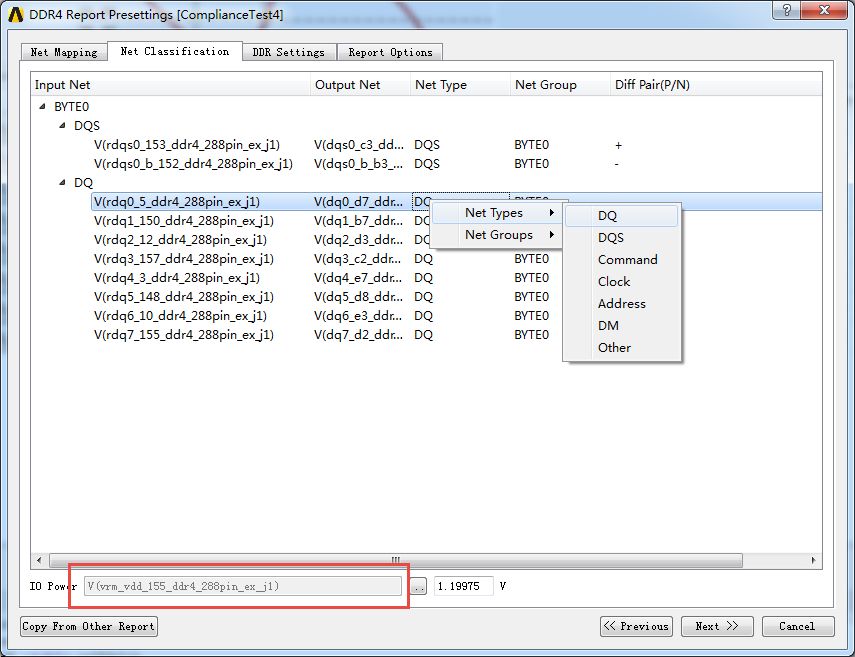
圖39 VirtualCompliance for DDR4設(shè)置向?qū)?/p>
注意:For GDDR5, it supports to use samestrobe pair in different Byte-lane group.
IO power、Net Types與NetGroups都要設(shè)定,step5.5中的【Generate】才能跑下去。當(dāng)在設(shè)置DQS差分信號(hào)時(shí),一定要按照circuit原理圖中的N/P分配原則,否則后續(xù)將無(wú)法進(jìn)行。
4.4、DDR settings
這里速率選擇3200MHz,紅線中參數(shù)為JESD79-4 內(nèi)存標(biāo)準(zhǔn)中的規(guī)定。
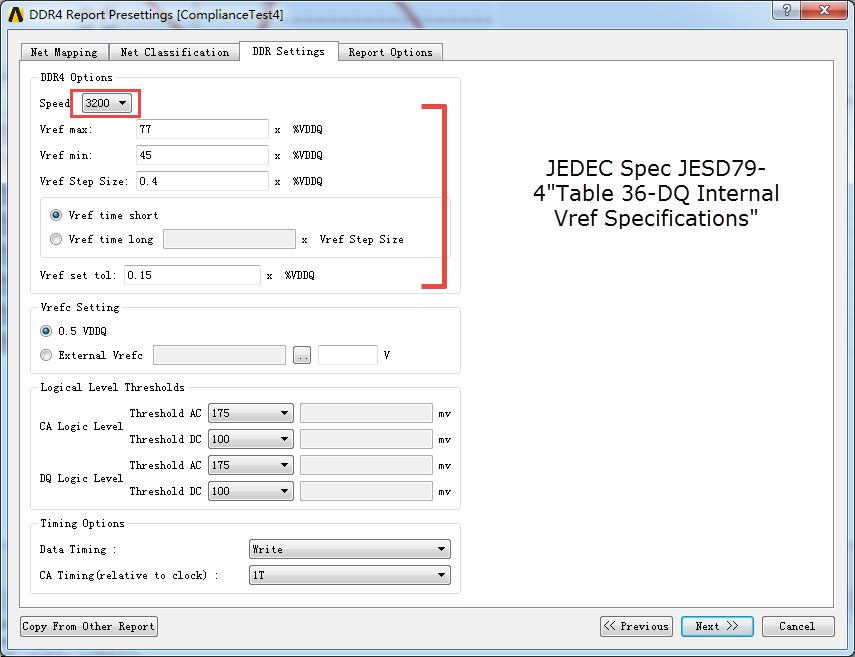
圖40 VirtualCompliance for DDR4設(shè)置向?qū)?/p>
注意:本文3.1顯示DQ與DQS差0.5UI,所以上圖【TimingOPtion】/【Data Timing】必須選擇【W(wǎng)rite】mode,這樣4.7內(nèi)【Eyediagram Timing】才可以正確的顯示pass/fail
4.5、Report Options
圖41 VirtualCompliance for DDR4設(shè)置向?qū)?/p>
4.6、Self-Delay
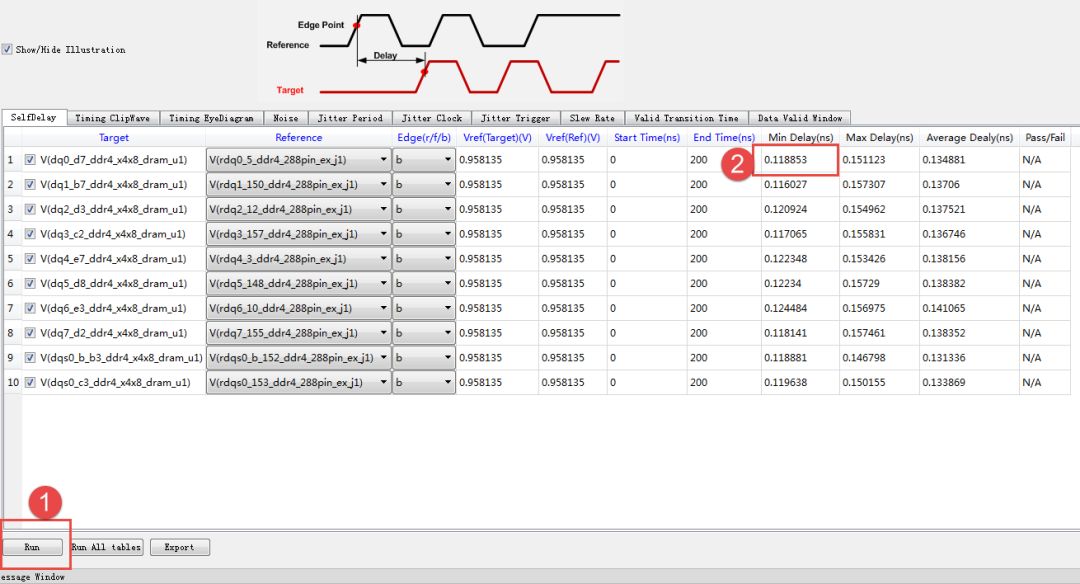
圖42 Self-Delayresult
1. Press [Run] to get the reportedparameters
2. Double-click the reported parameters[Min Delay] of DQ0 to open [Waveform Viewer]
圖43Waveform Viewer
3. Measuring function
圖44 Measuringfunction
4.7、Switch to different tabs and press [Run][Run All tables] to getother reported parameters.
在【Timing EyeDiagram】頁(yè)面下,使用者通過(guò)輸入【VdiVW Total】與【TdiVW Total】來(lái)決定Eye Mask的高與寬,軟件會(huì)幫你算出眼圖的參數(shù)與是否有碰到Eye Mask(Rx Mask Check)。
目前只支持方形的Eye mask forchecking passfail, it is defined in JEDEC DDR4.
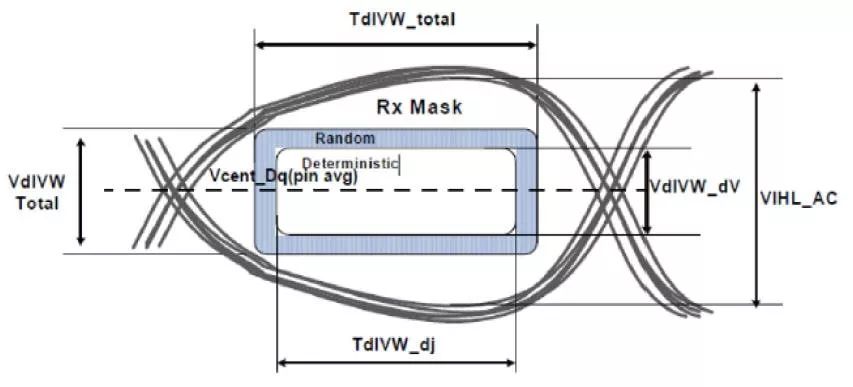
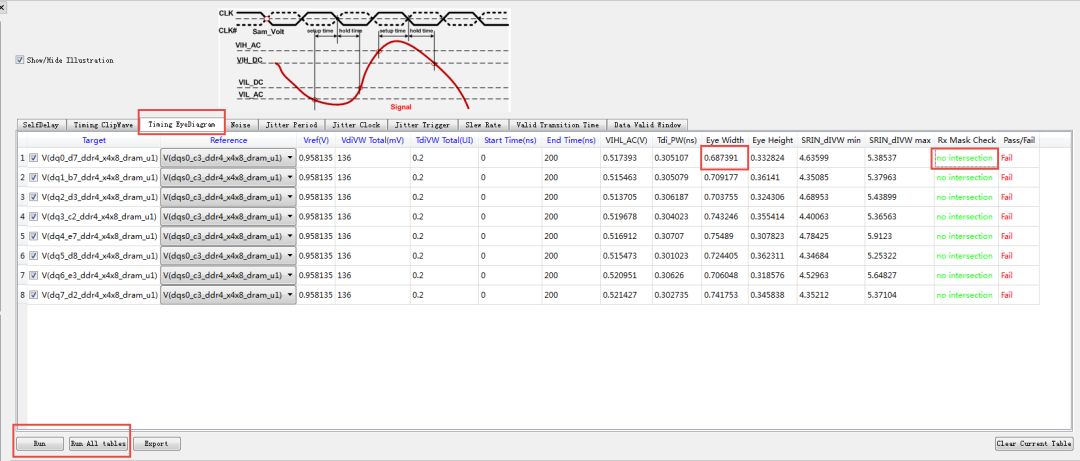
圖45 TimingEyeDiagram
For DDR4 compliance,這里算出的眼高(Eye High)與眼寬(Eye Width),是在BER=1e-16下得到的值
圖46 眼高和眼寬參數(shù)
4.8、Sing-off report
ANSYS可以自動(dòng)生成仿真報(bào)告,通過(guò)Sign-offReport選項(xiàng)可以獲得。
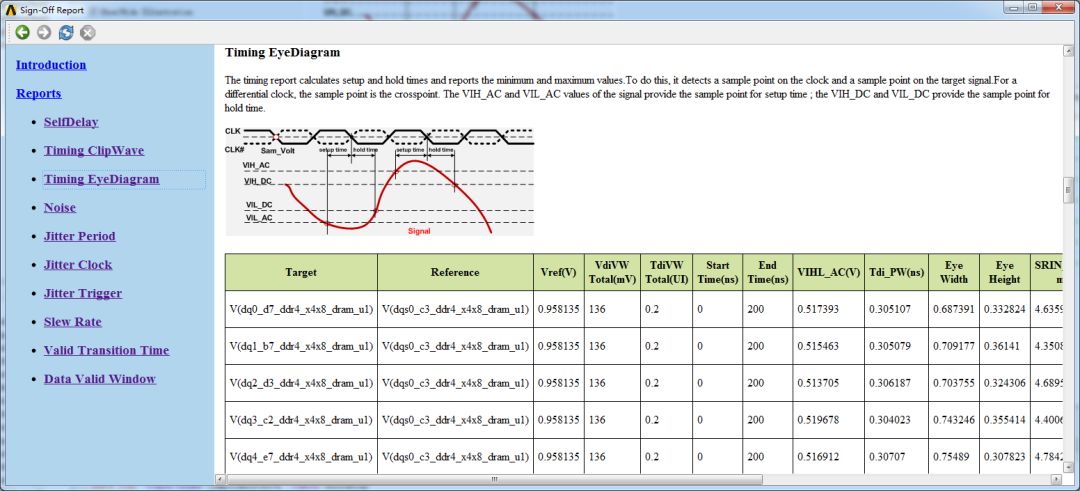
圖47 Sing-offreport
5、問(wèn)題與討論Q&A
5.1、單端或差分高速信號(hào)設(shè)計(jì),其優(yōu)劣分別為何?
Ans:[9]p.24中對(duì)其中的差異進(jìn)行了解釋,分別對(duì)信號(hào)的抖動(dòng),串?dāng)_噪聲等進(jìn)行對(duì)比。
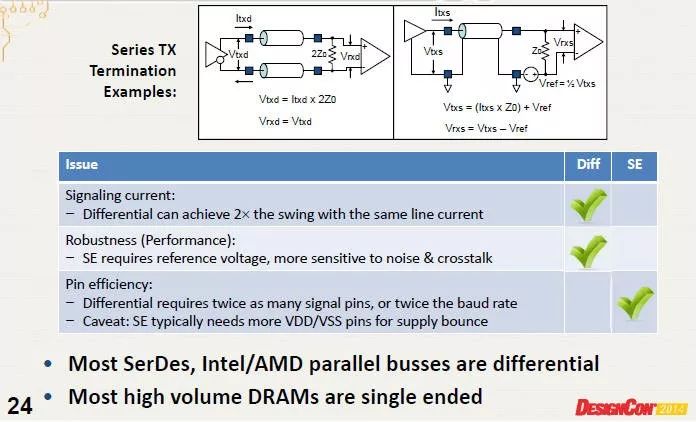
圖48single and differential difference
5.2、為何市面上目前看不到采用點(diǎn)對(duì)點(diǎn)傳輸架構(gòu)的DDR4
Ans:我想所需的PCB繞線空間太多,可支持的總DIMM插槽較少,應(yīng)該是目前較少人在DDR4使用點(diǎn)對(duì)點(diǎn)傳輸架構(gòu)的主因吧!比方一顆有6個(gè)DDR4 channel的CPU,如果使用點(diǎn)對(duì)點(diǎn)架構(gòu)的DDR接法,最多就是接6排DDR4插槽,但如果采用2spc架構(gòu),則最多可接12排DDR4插槽。
5.3、QuickEYE與VerifyEYE真的比Transient EYE快么?
Ans:這個(gè)答案很直覺(jué)的一位是“yes”,但實(shí)際上與模擬條件有關(guān)。
如果只跑一個(gè)net(e.g.DQ0),且跑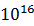 bit time,那肯定QuickEYE與VerifyEYE比TransientEYE快許多
bit time,那肯定QuickEYE與VerifyEYE比TransientEYE快許多
如果跑八個(gè)net(e.g.DQ0~7),且只跑PRBS13bit time,那TransientEYE比Quick EYE與Verify EYE快。關(guān)鍵在于Quick EYE與Verify EYE是by net trigger,模擬的net數(shù)越多,模擬時(shí)間乘倍數(shù)增加。
5.4、DDR4 Virtual compliance test是如何以transientanalysis結(jié)果得到BER=1e-16下的眼高與眼寬?
Ans:是透過(guò)transient analysis數(shù)據(jù)統(tǒng)計(jì)推估出來(lái),并不是真的跑Verify EYE。所以transient analysis模擬時(shí)間長(zhǎng)度會(huì)影響step 4.7的眼高與眼寬。
5.4.1、測(cè)試Transient EYE跑
圖49 三個(gè)不同數(shù)據(jù)量下的眼圖結(jié)果
為何alwaysMinEyeHeight>EyeHeight,MinEyeWidth>EyeWidth?
這是使用者最長(zhǎng)問(wèn)的問(wèn)題,答案在help文檔里,EyeHeight與EyeWidth是以分布中心點(diǎn)考慮三倍標(biāo)準(zhǔn)差(3),是含有統(tǒng)計(jì)概念在里面的。
EyeHeight = [(EyeLevelOne - 3s1) - (EyeLevelZero + 3s0 )] where s1and s0 are the standard deviations of the vertical histograms used to determineEyeLevelZero and EyeLevelOne.
EyeWidth = [( t2 - 3s) - (t1 + 3s)] where s is the standarddeviation of the horizontal histograms used to determine eye-crossing points.
MinEyeWidth is the minimum horizontal opening at the eye-crossingamplitude, typically at the center of the eye. Unlike statistical eye width, ifdifferent traces exist for different unit intervals, then MinEyeWidthrepresents the minimum width of all the traces.
MinEyeHeight is the minimum vertical opening at the eye-measurementpoint, typically at the center of the eye. Unlike statistical eye height, ifdifferent traces exist for different unit intervals, then MinEyeHeightrepresents the minimum height of all the traces.
圖50 mineye width的描述
5.4.2、當(dāng)暫態(tài)分析的時(shí)間太短,可能會(huì)得到BER=1e-16下交叉的眼圖參數(shù)(眼寬較小、眼高較低)。
這背后的物理意義是:暫態(tài)分析時(shí)間長(zhǎng)度較少時(shí)(模擬的Bit pattern數(shù)目較少時(shí)),眼圖偏離中間分布較遠(yuǎn)的少數(shù)幾次bit pattern在統(tǒng)計(jì)上的占比會(huì)升高,導(dǎo)致推估至BER=1e-16下的眼高與眼寬較差。
下圖分別演示不同的暫態(tài)分析時(shí)間40ns/160ns/640ns下,從DDR4 Virtual compliancetest得到BER=1e-16下的Eye Width。
暫態(tài)分析時(shí)間40ns,BER=1e16下的Rx端眼寬UI*0.703443=312.5ps*0.703443=219.8ps
圖5140ns下的Rx端眼寬
暫態(tài)分析時(shí)間160ns,BER=1e-16下的Rx端眼寬UI*0.724729=312.5ps*0.724729=226.48ps
圖52160ns下的Rx端眼寬
暫態(tài)分析時(shí)間640ns,BER=1e-16下的Rx端眼寬UI*0.756475=312.5ps*0.756475=236.40ps
圖53640ns下的Rx端眼寬
從以上測(cè)試數(shù)據(jù)可以看出,這種透過(guò)暫態(tài)分析結(jié)果,經(jīng)統(tǒng)計(jì)推算出在BER=1e-16下EYE parameter的技術(shù)是非常有效的,然而其參數(shù)值會(huì)略受暫態(tài)分析時(shí)間長(zhǎng)度的影響。跑bit(312.5ps*=640ns)時(shí)間長(zhǎng)度,比跑bit(312.5ps*=160ns)時(shí)間長(zhǎng)度的結(jié)果好。
-
SDRAM
+關(guān)注
關(guān)注
7文章
438瀏覽量
55888 -
DDR4
+關(guān)注
關(guān)注
12文章
325瀏覽量
41399 -
ANSYS
+關(guān)注
關(guān)注
10文章
240瀏覽量
36932
原文標(biāo)題:20181011---采用ANSYS進(jìn)行DDR4仿真
文章出處:【微信號(hào):EMC_EMI,微信公眾號(hào):電磁兼容EMC】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
DDR4與DDR3的不同之處 DDR4設(shè)計(jì)與仿真案例

佛山回收DDR4 高價(jià)回收DDR4
佛山回收DDR4 高價(jià)回收DDR4
DDR4,什么是DDR4
ddr4和ddr3內(nèi)存的區(qū)別,可以通用嗎
DDR4設(shè)計(jì)規(guī)則及DDR4的PCB布線指南
DDR4原理及硬件設(shè)計(jì)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論