 深度文本匹配的簡介,深度文本匹配在智能客服中的應用
深度文本匹配的簡介,深度文本匹配在智能客服中的應用
▌一、深度文本匹配的簡介
1. 文本匹配的價值
文本匹配是自然語言理解中的一個核心問題,它可以應用于大量的自然語言處理任務中,例如信息檢索、問答系統、復述問題、對話系統、機器翻譯等等。這些自然語言處理任務在很大程度上都可以抽象成文本匹配問題,比如信息檢索可以歸結為搜索詞和文檔資源的匹配,問答系統可以歸結為問題和候選答案的匹配,復述問題可以歸結為兩個同義句的匹配,對話系統可以歸結為前一句對話和回復的匹配,機器翻譯則可以歸結為兩種語言的匹配。
2. 深度文本匹配的優勢
傳統的文本匹配技術如圖1中的 BoW、TFIDF、VSM等算法,主要解決詞匯層面的匹配問題,而實際上基于詞匯重合度的匹配算法存在著詞義局限、結構局限和知識局限等問題。
詞義局限:的士和出租車雖然字面上不相似,但實為同一種交通工具;而蘋果在不同的語境下表示的東西不同,或為水果或為公司;
結構局限:機器學習和學習機器雖詞匯完全重合,但表達的意思不同;
知識局限:秦始皇打 Dota,這句話雖從詞法和句法上看均沒問題,但結合知識看這句話是不對的。
傳統的文本匹配模型需要基于大量的人工定義和抽取的特征,而這些特征總是根據特定的任務(信息檢索或者自動問答)人工設計的,因此傳統模型在一個任務上表現很好的特征很難用到其他文本匹配任務上。而深度學習方法可以自動從原始數據中抽取特征,省去了大量人工設計特征的開銷。首先特征的抽取過程是模型的一部分,根據訓練數據的不同,可以方便適配到各種文本匹配的任務當中;其次,深度文本匹配模型結合上詞向量的技術,更好地解決了詞義局限問題;最后得益于神經網絡的層次化特性,深度文本匹配模型也能較好地建模短語匹配的結構性和文本匹配的層次性[1]。
3. 深度文本匹配的發展路線
圖 1 深度文本匹配的發展路線
隨著深度學習在計算機視覺、語音識別和推薦系統領域中的成功運用,近年來有很多研究致力于將深度神經網絡模型應用于自然語言處理任務,以降低特征工程的成本。最早將深度學習應用于文本匹配的是微軟 Redmond 研究院。2013年微軟 Redmond 研究院發表了 DSSM [2],當時 DSSM 在真實數據集上的效果超過了SOTA(State of the Art);為了彌補 DSSM 會丟失上下文的問題,2014年微軟又設計了CDSSM [3];2016年又相繼發表了 DSSM-LSTM, MV-DSSM。微軟的 DSSM 及相關系列模型是深度文本匹配模型中比較有影響力的,據了解百度、微信和阿里的搜索場景中都有使用。
其他比較有影響的模型有:2014年華為諾亞方舟實驗室提出的 ARC-I和ARC-II [4],2015年斯坦福的 Tree-LSTM [5],2016年 IBM 的 ABCNN [6],中科院的 MatchPyramid [7],2017年朱曉丹的 ESIM[8],2018 年騰訊 MIG 的多信道信息交叉模型 MIX [9]。
一般來說,深度文本匹配模型分為兩種類型,表示型和交互型。表示型模型更側重對表示層的構建,它會在表示層將文本轉換成唯一的一個整體表示向量。典型的網絡結構有 DSSM、CDSMM 和 ARC-I。這種模型的核心問題是得到的句子表示失去語義焦點,容易發生語義偏移,詞的上下文重要性難以衡量。交互型模型摒棄后匹配的思路,假設全局的匹配度依賴于局部的匹配度,在輸入層就進行詞語間的先匹配,并將匹配的結果作為灰度圖進行后續的建模。典型的網絡結構有 ARC-II、DeepMatch 和 MatchPyramid。它的優勢是可以很好的把握語義焦點,對上下文重要性合理建模。由于模型效果顯著,業界都在逐漸嘗試交互型的方法。
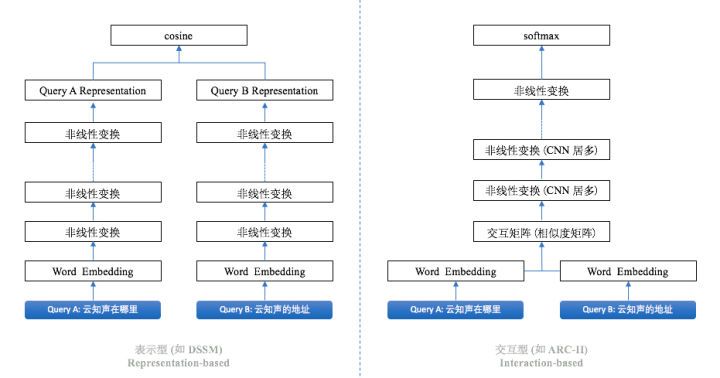
圖 2 深度文本匹配模型的類型
▌二、智能客服的簡介
1. 智能客服的應用背景
由于人工客服在響應時間、服務時間和業務知識等方面的局限性,有必要研發智能客服系統,使其通過智能化的手段來輔助人工客服為用戶服務。智能客服與人工客服的優劣勢對比如圖 4 所示。
圖 3 智能客服與人工客服的優劣勢對比
2. 智能客服的核心模塊
智能客服的一般框架如圖 5 所示:當有 Query 請求時,首先對 Query 進行補全、解析和需求理解;其次,問題召回模塊通過精準召回、核心召回和語義召回從 FAQ 庫召回與 Query 相關的問題;接著,問題排序模塊通過 CTR 模型和相似度模型對召回的問題進行排序,選出 Top k 返回給用戶;最后,反饋系統記錄用戶的點擊行為等,對模型進行更新。具體哪些模型會被更新,與語義召回和相似度模型階段使用的算法有關。
圖 4 智能客服的一般框架
在智能客服的框架中,最重要的模塊是 FAQ 庫的構建、語義召回、相似度模型和模型更新,它們性能的好壞對用戶的使用體驗有很大影響。
FAQ 庫的構建
對于重視用戶體驗的客服系統來說,FAQ 庫的構建是非常嚴格的,它的內容需要非常完整和標準,不能像聊天機器人那樣可以插科打諢。一般的做法是將積累的 FAQ ,或是將場景相關的設計文檔、PRD文檔中的相應內容整理成 FAQ,添加到 FAQ 庫中。日常的維護就是運營人員根據線上用戶的提問做總結,把相應的問題和答案加入 FAQ 庫。不難想像,隨著用戶量的增加,用戶的問題種類五花八門,問法多種多樣,這種維護方式肯定會給運營帶來很大的壓力,也會給用戶帶來糟糕的體驗。那么,有沒有什么自動或是半自動的方法可以解決新問題的挖掘和 FAQ 庫的更新?
一種理想的 FAQ 庫構建的流程應該是:從客服的直接對話出發,提取出與產品相關的問題,計算問題之間的距離,通過增量聚類的方法把用戶相似的問題聚到一起,最后由運營人員判斷新增的問題能否進入 FAQ 庫,同時將他們的反饋更新給文本匹配模型。
圖 5 理想的FAQ 庫構建的流程
語義召回
當 FAQ 庫達到一定規模時,再讓用戶請求的 Query 與 FAQ 庫中的問題一一計算相似度是非常耗時的,而問題召回模塊可以通過某些算法只召回與請求 Query 相關的問題,減少問題相似度模型階段的復雜度。精準召回和核心召回是基于詞匯重合度的檢索方法,它們的局限是不能召回那些 FAQ 庫中與請求 Query 無詞匯重合,但語義表達是一樣的問題,而語義召回可以解決此類問題。
相似度模型
相似度模型分別計算召回的相關問題與請求 Query 之間的相似度,作為排序模型的特征之一。需要注意,此處的相似度模型不同于語義召回中的相似度計算,前者更靠近輸出端,對準確率要求高;后者對召回率要求高。因此,這兩個模塊在實現時使用的模型往往不同,在我們的文本匹配引擎中,語義召回使用的是基于表示型的深度文本匹配模型,相似度模型使用的是基于交互型的深度文本匹配模型和其他傳統文本匹配模型的混合模型。
模型更新
智能客服投入線上使用后,用戶 query 可能與某些模型的訓練數據分布不一致,導致智能客服的響應不理想。因此,十分有必要從收集到的用戶行為數據中挖掘相關知識,并更新相關模型。
▌三、深度文本匹配在智能客服中的應用
1. 為什么使用深度文本匹配
問題聚類、語義召回和相似度模型都可以歸結為文本匹配問題。傳統智能客服在這些模塊中使用的是傳統文本匹配方法,不可避免地會遇到詞義局限、結構局限和知識局限等問題;加上傳統文本匹配方法多是無監督的學習方法,那么由這些方法訓練的模型就無法利用運營人員的反饋和用戶的點擊行為等知識。然而,使用深度文本匹配的方法則可以有效地解決這些弊端。具體改進方面如圖 6 所示。

圖 6 深度文本匹配對傳統智能客服的改進
2. 怎么樣使用深度文本匹配
我們曾在智能客服的不同領域中嘗試過多種深度文本匹配方法,通過業務場景推動技術演進的方式,逐淅形成了一套成熟的文本匹配引擎。我們的文本匹配引擎除了使用傳統的機器學習模型(如話題匹配模型、詞匹配模型、VSM等)外,還使用了基于表示型和基于交互型的深度文本匹配模型。
深度文本匹配模型
Representation-based Model
表示型的深度文本匹配模型能抽出句子主成分,將文本序列轉換為向量,因此,在問題聚類模塊,我們使用表示型的深度文本匹配模型對挖掘的問題和 FAQ 庫的問題做預處理,方便后續增量聚類模塊的計算;在語義召回模塊,我們使用表示型的深度文本匹配模型對 FAQ 庫的問題做向量化處理,并建立索引,方便問題召回模塊增加對用戶 query 的召回。另外,我們使用基于 Bi-LSTM 的表示型模型以捕獲句子內的長依賴關系。模型結構如圖 7 所示。
圖 7 基于 Bi-LSTM 的表示型模型
我們在相似度模型模塊使用了基于交互型的深度文本匹配模型 MatchPyramid,其原因有三點:
第一點,表示型的深度文本匹配模型對句子表示時容易失去語義焦點和發生語義偏移,而交互型的深度文本匹配模型不存在這種問題,它能很好地把握語義焦點,對上下文重要性進行合理建模。
第二點,在語義召回階段,用戶 query 與召回問題間的語義相似度會作為排序模型的特征之一,同樣地,相似度模型階段,用戶 query 與召回問題間的另一種語義相似度也會作為排序模型的特征之一。
第三點,相似度模型需要實時計算,用戶每請求一次,相似度模型就需要計算 n 個句對的相似度,n 是問題召回的個數。而序列型的神經網絡不能并行計算,因此我們選擇了網絡結構是 CNN 的 MatchPyramid 模型。模型結構如圖 8 所示。
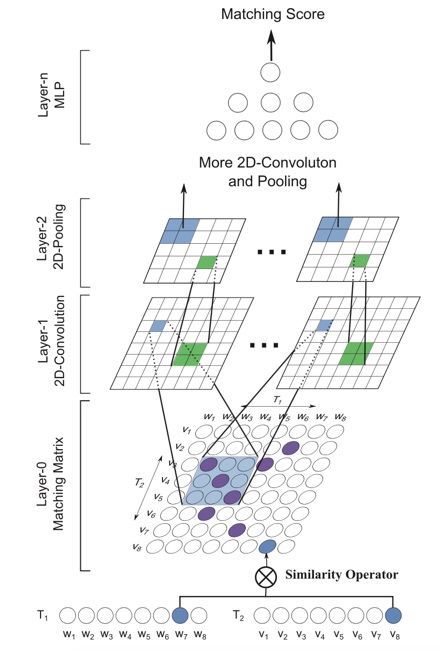
圖 8 An overview of MatchPyramid on Text Matching
文本匹配引擎
由于自然語言的多樣性,文本匹配問題不是某個單一模型就能解決的,它涉及到的是算法框架的問題。每個模型都有獨到之處,如何利用不同模型的優點去做集成,是任何文本匹配引擎都需要解決的問題。我們的文本匹配引擎融合了傳統文本匹配模型和深度文本匹配模型,具體的框架如圖 9 所示。
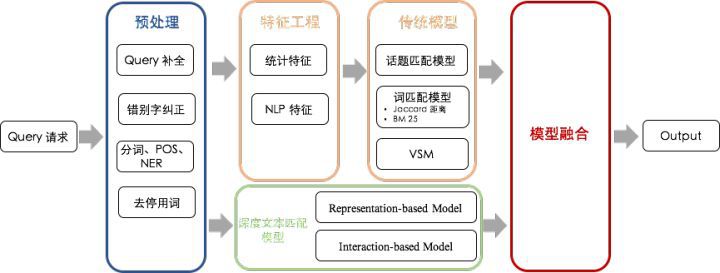
圖 9 文本匹配引擎的框架
3. 深度智能客服的效果評測
應用上述的文本匹配引擎后,我們為某汽車公司開發的智能客服系統,在測試集上的 precision 達到了 97%;與某壽險公司合作完成的智能客服,其 precision 比 baseline 高出 10 個點。除此之外,在對話系統的音樂領域中,使用深度文本匹配引擎替代模糊匹配后,整體 precision 提高了 10 個點;在通用領域的測試集上,我們的文本匹配引擎也與百度的 SimNet 表現不相上下。
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
46032 -
機器學習
+關注
關注
66文章
8425瀏覽量
132772 -
深度學習
+關注
關注
73文章
5507瀏覽量
121293
原文標題:深度文本匹配在智能客服中的應用
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問DAC5682z內部FIFO深度為多少,8SAMPLE具體怎么理解?
如何使用自然語言處理分析文本數據
NPU在深度學習中的應用
圖紙模板中的文本變量
如何在文本字段中使用上標、下標及變量

手寫圖像模板匹配算法在OpenCV中的實現

使用語義線索增強局部特征匹配

【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
如何學習智能家居?8:Text文本實體使用方法

利用TensorFlow實現基于深度神經網絡的文本分類模型
卷積神經網絡在文本分類領域的應用
電路的阻抗如何匹配







 工商網監
工商網監
評論