 如何提升神經網絡性能
如何提升神經網絡性能
本文簡要介紹了提升神經網絡性能的方法,如檢查過擬合、調參、超參數調節、數據增強。
神經網絡是一種在很多用例中能夠提供最優準確率的機器學習算法。但是,很多時候我們構建的神經網絡的準確率可能無法令人滿意,或者無法讓我們在數據科學競賽中拿到領先名次。所以,我們總是在尋求更好的方式來改善模型的性能。有很多技術可以幫助我們達到這個目標。本文將介紹這些技術,幫助大家構建更準確的神經網絡。
檢查過擬合
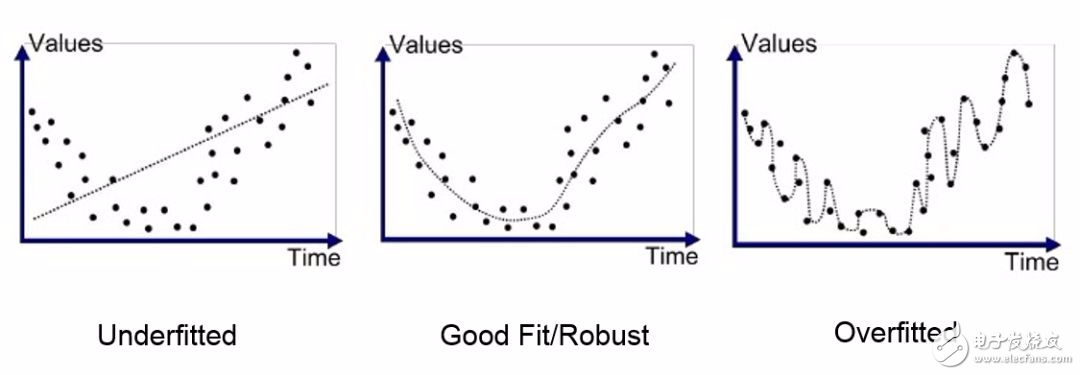
保證神經網絡在測試集上運行良好的第一步就是驗證神經網絡沒有過擬合。什么是過擬合呢?當你的模型開始記錄訓練數據而不是從中學習的時候,就發生了過擬合。然后,當你的模型遇到之前沒有見過的數據時,它就無法很好的運行。為了更好地理解,我們來看一個類比。我們有一個記性特好的同學,假設一次數學考試馬上就要來臨了。你和這位擅長記憶的同學開始學習課本。這名同學記住課本中的每一個公式、問題以及問題的答案,然而你要比他來得聰明一些,所以你決定以直覺為基礎、解決問題、學習這些公式是如何發揮作用的。考試來了,如果試卷中的問題是直接來源于課本的,那么可以想像那名記憶力超群的同學發揮得更好,但是,如果試題是涉及應用直觀知識的全新問題,那么你將會做得更好,而你的朋友會慘敗。
如何鑒別模型是否過擬合呢?你僅僅需要交叉檢查訓練準確率和測試準確率。如果訓練準確率遠遠高出了測試準確率,那么可以斷定你的模型是過擬合了。你也可以在圖中畫出預測點來驗證。下面是一些避免過擬合的技術:
數據正則化(L1 或 L2);
Dropout:隨機丟棄一些神經元之間的連接,強制神經網絡尋找新的路徑并泛化;
早停(Early Stopping):促使神經網絡訓練早點停止,以減少在測試集中的誤差。
超參數調節
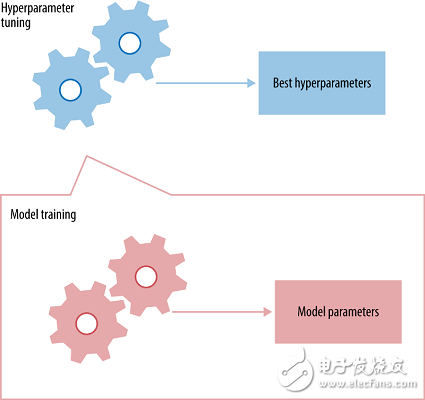
超參數是你必須給網絡初始化的值,這些數值不能在訓練的過程中學到。在卷積神經網絡中,這些超參數包括:核大小、神經網絡層數、激活函數、損失函數、所用的優化器(梯度下降、RMSprop)、批大小、訓練的 epoch 數量等等。
每個神經網絡都會有最佳超參數組合,這組參數能夠得到最大的準確率。你也許會問,「有這么多超參數,我如何選擇每個參數呢?」不幸的是,對每個神經網絡而言,并沒有確定最佳超參數組合的直接方法,所以通常都是通過反復試驗得到的。但是也有一些關于上述超參數的最佳實踐:
學習率:選擇最優學習率是很重要的,因為它決定了神經網絡是否可以收斂到全局最小值。選擇較高的學習率幾乎從來不能到達全局最小值,因為你很可能跳過它。所以,你總是在全局最小值附近,但是從未收斂到全局最小值。選擇較小的學習率有助于神經網絡收斂到全局最小值,但是會花費很多時間。這樣你必須用更多的時間來訓練神經網絡。較小的學習率也更可能使神經網絡困在局部極小值里面,也就是說,神經網絡會收斂到一個局部極小值,而且因為學習率比較小,它無法跳出局部極小值。所以,在設置學習率的時候你必須非常謹慎。
神經網絡架構:并不存在能夠在所有的測試集中帶來高準確率的標準網絡架構。你必須實驗,嘗試不同的架構,從實驗結果進行推斷,然后再嘗試。我建議使用已經得到驗證的架構,而不是構建自己的網絡架構。例如:對于圖像識別任務,有 VGG net、Resnet、谷歌的 Inception 網絡等。這些都是開源的,而且已經被證明具有較高的準確率。所以你可以把這些架構復制過來,然后根據自己的目的做一些調整。
優化器和損失函數:這方面有很多可供選擇。事實上,如果有必要,你可以自定義損失函數。常用的優化器有 RMSprop、隨機梯度下降和 Adam。這些優化器貌似在很多用例中都可以起作用。如果你的任務是分類任務,那么常用的損失函數是類別交叉熵。如果你在執行回歸任務,那么均方差是最常用的損失函數。你可以自由地使用這些優化器超參數進行試驗,也可以使用不同的優化器和損失函數。
批大小和 epoch 次數:同樣,沒有適用于所有用例的批大小和 epoch 次數的標準值。你必須進行試驗,嘗試不同的選擇。在通常的實踐中,批大小被設置為 8、16、32……epoch 次數則取決于開發者的偏好以及他/她所擁有的計算資源。
激活函數:激活函數映射非線性函數輸入和輸出。激活函數是特別重要的,選擇合適的激活函數有助于模型學習得更好。現在,整流線性單元(ReLU)是最廣泛使用的激活函數,因為它解決了梯度消失的問題。更早時候,Sigmoid 和 Tanh 函數都是最常用的激活函數。但是它們都會遇到梯度消失的問題,即在反向傳播中,梯度在到達初始層的過程中,值在變小,趨向于 0。這不利于神經網絡向具有更深層的結構擴展。ReLU 克服了這個問題,因此也就可以允許神經網絡擴展到更深的層。
ReLU 激活函數
算法集成
如果單個神經網絡不像你期待的那樣準確,那么你可以創建一個神經網絡集成,結合多個網絡的預測能力。你可以選擇不同的神經網絡架構,在不同部分的數據集上訓練它們,然后使用它們的集合預測能力在測試集上達到較高的準確率。假設你在構建一個貓狗分類器,0 代表貓,1 代表狗。當組合不同的貓狗分類器時,基于單個分類器之間的皮爾遜相關系數,集成算法的準確率有了提升。讓我們看一個例子,拿 3 個模型來衡量它們各自的準確率:
Ground Truth: 1111111111 Classifier 1: 1111111100 = 80% accuracy Classifier 2: 1111111100 = 80% accuracy Classifier 3: 1011111100 = 70% accuracy
3 個模型的皮爾遜相關系數很高。所以,集成它們并不會提升準確率。如果我們使用多數投票的方式來組合這三個模型,會得到下面的結果:
Ensemble Result: 1111111100 = 80% accuracy
現在,讓我們來看一組輸出具備較低皮爾遜相關系數的模型:
Ground Truth: 1111111111 Classifier 1: 1111111100 = 80% accuracy Classifier 2: 0111011101 = 70% accuracy Classifier 3: 1000101111 = 60% accuracy
當我們組合這三個弱學習器的時候,會得到以下結果:
Ensemble Result: 1111111101 = 90% accuracy
正如你在上面所看到的,具有低皮爾遜相關系數的弱學習器的組合優于具有較高皮爾遜相關系數的學習器的組合。
缺乏數據
在使用了上述所有的技術以后,如果你的模型仍然沒有在測試集上表現得更好一些,這可能是因為缺乏數據。在很多用例中訓練數據的數量是有限的。如果你無法收集更多的數據,那么你可以采取數據增強方法。
數據增強技術
如果你正在使用的是圖像數據集,你可以通過剪切、翻轉、隨機裁剪等方法來增加新的圖像。這可以為你正在訓練的神經網絡提供不同的樣本。
結論
這些技術被認為是最佳實踐經驗,在提升模型學習特征的能力方面通常是有效的。希望對大家有所幫助。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論