 基于強化學習的MADDPG算法原理及實現
基于強化學習的MADDPG算法原理及實現
之前接觸的強化學習算法都是單個智能體的強化學習算法,但是也有很多重要的應用場景牽涉到多個智能體之間的交互,比如說,多個機器人的控制,語言的交流,多玩家的游戲等等。本文,就帶你簡單了解一下Open-AI的MADDPG(Multi-Agent Deep Deterministic Policy Gradient)算法,來共同體驗一下多智能體強化學習的魅力。
1、引言
強化學習中很多場景涉及多個智能體的交互,比如多個機器人的控制,語言的交流,多玩家的游戲等等。不過傳統的RL方法,比如Q-Learning或者policy gradient都不適用于多智能體環境。主要的問題是,在訓練過程中,每個智能體的策略都在變化,因此從每個智能體的角度來看,環境變得十分不穩定(其他智能體的行動帶來環境變化)。對DQN來說,經驗重放的方法變的不再適用(如果不知道其他智能體的狀態,那么不同情況下自身的狀態轉移會不同),而對PG的方法來說,環境的不斷變化導致了學習的方差進一步增大。
因此,本文提出了MADDPG(Multi-Agent Deep Deterministic Policy Gradient)方法。為什么要使用DDPG方法作為基準模型呢?主要是集中訓練和分散執行的策略。
本文提出的方法框架是集中訓練,分散執行的。我們先回顧一下DDPG的方式,DDPG本質上是一個AC方法。訓練時,Actor根據當前的state選擇一個action,然后Critic可以根據state-action計算一個Q值,作為對Actor動作的反饋。Critic根據估計的Q值和實際的Q值來進行訓練,Actor根據Critic的反饋來更新策略。測試時,我們只需要Actor就可以完成,此時不需要Critic的反饋。因此,在訓練時,我們可以在Critic階段加上一些額外的信息來得到更準確的Q值,比如其他智能體的狀態和動作等,這也就是集中訓練的意思,即每個智能體不僅僅根據自身的情況,還根據其他智能體的行為來評估當前動作的價值。分散執行指的是,當每個Agent都訓練充分之后,每個Actor就可以自己根據狀態采取合適的動作,此時是不需要其他智能體的狀態或者動作的。DQN不適合這么做,因為DQN訓練和預測是同一個網絡,二者的輸入信息必須保持一致,我們不能只在訓練階段加入其他智能體的信息。
2、DDPG算法的簡單回顧
什么是DDPG什么是DDPG呢?一句話描述,它是Actor-Critic 和 DQN 算法的結合體。
DDPG的全稱是Deep Deterministic Policy Gradient。
我們首先來看Deep,正如Q-learning加上一個Deep就變成了DQN一樣,這里的Deep即同樣使用DQN中的經驗池和雙網絡結構來促進神經網絡能夠有效學習。
再來看Deterministic,即我們的Actor不再輸出每個動作的概率,而是一個具體的動作,這更有助于我們連續動作空間中進行學習。
DDPG的網絡結構盜用莫煩老師的一張圖片來形象的表示DDPG的網絡結構,同圖片里一樣,我們稱Actor里面的兩個網絡分別是動作估計網絡和動作現實網絡,我們稱Critic中的兩個網絡分別是狀態現實網絡和狀態估計網絡:
我們采用了類似DQN的雙網絡結構,而且Actor和Critic都有target-net和eval-net。我們需要強調一點的事,我們只需要訓練動作估計網絡和狀態估計網絡的參數,而動作現實網絡和狀態現實網絡的參數是由前面兩個網絡每隔一定的時間復制過去的。
我們先來說說Critic這邊,Critic這邊的學習過程跟DQN類似,我們都知道DQN根據下面的損失函數來進行網絡學習,即現實的Q值和估計的Q值的平方損失:
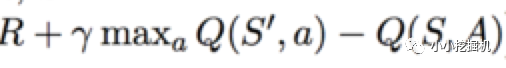
上面式子中Q(S,A)是根據狀態估計網絡得到的,A是動作估計網絡傳過來的動作。而前面部分R + gamma * maxQ(S',A')是現實的Q值,這里不一樣的是,我們計算現實的Q值,不在使用貪心算法,來選擇動作A',而是動作現實網絡得到這里的A'。總的來說,Critic的狀態估計網絡的訓練還是基于現實的Q值和估計的Q值的平方損失,估計的Q值根據當前的狀態S和動作估計網絡輸出的動作A輸入狀態估計網絡得到,而現實的Q值根據現實的獎勵R,以及將下一時刻的狀態S'和動作現實網絡得到的動作A' 輸入到狀態現實網絡 而得到的Q值的折現值加和得到(這里運用的是貝爾曼方程)。
我們再來說一下Actor這邊,論文中,我們基于下面的式子進行動作估計網絡的參數:
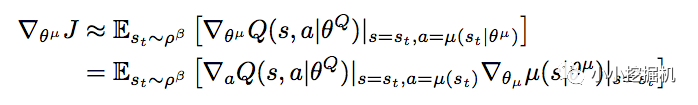
這個式子看上去很嚇人,但是其實理解起來很簡單。假如對同一個狀態,我們輸出了兩個不同的動作a1和a2,從狀態估計網絡得到了兩個反饋的Q值,分別是Q1和Q2,假設Q1>Q2,即采取動作1可以得到更多的獎勵,那么Policy gradient的思想是什么呢,就是增加a1的概率,降低a2的概率,也就是說,Actor想要盡可能的得到更大的Q值。所以我們的Actor的損失可以簡單的理解為得到的反饋Q值越大損失越小,得到的反饋Q值越小損失越大,因此只要對狀態估計網絡返回的Q值取個負號就好啦。是不是很簡單。
DDPG學習中的小trick
與傳統的DQN不同的是,傳統的DQN采用的是一種被稱為'hard'模式的target-net網絡參數更新,即每隔一定的步數就將eval-net中的網絡參數賦值過去,而在DDPG中,采用的是一種'soft'模式的target-net網絡參數更新,即每一步都對target-net網絡中的參數更新一點點,這種參數更新方式經過試驗表明可以大大的提高學習的穩定性。'soft'模式到底是如何更新網絡的?我們可以通過代碼更好的理解。
論文中提到的另一個小trick是對采取的動作增加一定的噪聲:

DDPG的完整流程
介紹了這么多,我們也就能順利理解原文中的DDPG算法的流程:
3、MADDPG算法簡介
算法流程
理解了DDPG的算法過程,那么MADDPG的過程也是不難理解的,我們一起來看一下吧。
每個Agent的訓練同單個DDPG算法的訓練過程類似,不同的地方主要體現在Critic的輸入上:在單個Agent的DDPG算法中,Critic的輸入是一個state-action對信息,但是在MADDPG中,每個Agent的Critic輸入除自身的state-action信息外,還可以有額外的信息,比如其他Agent的動作。
多Agent之間的關系形式
不同的Agent之間的關系大體可以分為三種,合作型,對抗性,半合作半對抗型。我們可以根據不同的合作關系來設計我們的獎勵函數。
4、模型實驗
文章中設置了多組實驗環境,有合作型的,有對抗型的也有半合作半對抗型的。如下圖所示:
這里只重點講我們后面代碼中實現的實驗。
實驗的名稱為Predator-prey。其英文解釋為Good agents (green) are faster and want to avoid being hit by adversaries (red). Adversaries are slower and want to hit good agents. Obstacles (large black circles) block the way.
不過我們在代碼中只實現了三個Adversaries,而Good agents處于隨機游走狀態。
在合作交流的環境下,論文中將MADDPG與傳統的算法進行了對比,得到的結果如下:
可以看到,MADDPG與傳統的RL算法相比,在多智能體的環境下,能夠取得更加突出的效果。
5、MADDPG算法的簡單實現
本文實踐了Predator-prey這一環境,如下圖所示:
綠色的球為目標,在二維空間中隨機游走,躲避紅色的球的攻擊。三個紅色的球是我們定義的Agent,它們處在互相對抗的環境中,想要擊中綠色的球,從而獲得獎勵。黑色的地方時障礙。
本文的github地址為:https://github.com/princewen/tensorflow_practice/tree/master/RL/Basic-MADDPG-Demo
實驗環境安裝
下載https://github.com/openai/multiagent-particle-envs中的代碼。
進入到代碼主路徑中,執行命令安裝所需的環境
pip install -e .
代碼結構本項目的代碼結構如下:
model_agent_maddpg.py:該文件定義了單個Agent的DDPG結構,及一些函數replay_buffer.py:定義了兩種不同的經驗池,一種是普通的經驗池,一種是優先采樣經驗池segment_tree.py:只有在使用優先采樣經驗池的時候才用到。定義一種樹結構根據經驗的優先級進行采樣test_three_agent_maddpg.py:對訓練好的模型進行測試three_agent_maddpg.py:模型訓練的主代碼
DDPG-Actor實現我們首先來實現單個的DDPG結構Actor的輸入是一個具體的狀態,經過兩層的全鏈接網絡輸出選擇的Action。
def actor_network(name): with tf.variable_scope(name) as scope: x = state_input x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, self.nb_actions, kernel_initializer=tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)) x = tf.nn.tanh(x) return x
DDPG-Critic實現
Critic的輸入是state,以及所有Agent當前的action信息:
def critic_network(name, action_input, reuse=False): with tf.variable_scope(name) as scope: if reuse: scope.reuse_variables() x = state_input x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.concat([x, action_input], axis=-1) x = tf.layers.dense(x, 64) if self.layer_norm: x = tc.layers.layer_norm(x, center=True, scale=True) x = tf.nn.relu(x) x = tf.layers.dense(x, 1, kernel_initializer=tf.random_uniform_initializer(minval=-3e-3, maxval=3e-3)) return x
訓練Actor和Critic
Actor的訓練目標是Q值的最大化,而Critic的訓練目標是最小化Q估計值和Q實際值之間的差距:
self.actor_optimizer = tf.train.AdamOptimizer(1e-4)self.critic_optimizer = tf.train.AdamOptimizer(1e-3)# 最大化Q值self.actor_loss = -tf.reduce_mean( critic_network(name + '_critic', action_input=tf.concat([self.action_output, other_action_input], axis=1), reuse=True))self.actor_train = self.actor_optimizer.minimize(self.actor_loss)self.target_Q = tf.placeholder(shape=[None, 1], dtype=tf.float32)self.critic_loss = tf.reduce_mean(tf.square(self.target_Q - self.critic_output))self.critic_train = self.critic_optimizer.minimize(self.critic_loss)
定義三個Agent
隨后,我們分別建立三個Agent,每個Agent對應兩個DDPG結構,一個是eval-net,一個是target-net:
agent1_ddpg = MADDPG('agent1')agent1_ddpg_target = MADDPG('agent1_target')agent2_ddpg = MADDPG('agent2')agent2_ddpg_target = MADDPG('agent2_target')agent3_ddpg = MADDPG('agent3')agent3_ddpg_target = MADDPG('agent3_target')
模型訓練
在訓練過程中,假設當前的狀態是o_n,我們首先通過Actor得到每個Agent的動作,這里我們將動作定義為一個二維的向量,不過根據OpenAi的環境設置,我們需要將動作展開成一個五維的向量,同時綠色的球也需要定義動作,因此一共將四組動作輸入到我們的環境中,可以得到獎勵及下一個時刻的狀態o_n_next以及當前的獎勵r_n:
agent1_action, agent2_action, agent3_action = get_agents_action(o_n, sess, noise_rate=0.2)#三個agent的行動a = [[0, i[0][0], 0, i[0][1], 0] for i in [agent1_action, agent2_action, agent3_action]]#綠球的行動a.append([0, np.random.rand() * 2 - 1, 0, np.random.rand() * 2 - 1, 0])o_n_next, r_n, d_n, i_n = env.step(a)
隨后,我們需要將經驗存放到經驗池中,供Critic反饋和訓練:
agent1_memory.add(np.vstack([o_n[0], o_n[1], o_n[2]]), np.vstack([agent1_action[0], agent2_action[0], agent3_action[0]]), r_n[0], np.vstack([o_n_next[0], o_n_next[1], o_n_next[2]]), False)agent2_memory.add(np.vstack([o_n[1], o_n[2], o_n[0]]), np.vstack([agent2_action[0], agent3_action[0], agent1_action[0]]), r_n[1], np.vstack([o_n_next[1], o_n_next[2], o_n_next[0]]), False)agent3_memory.add(np.vstack([o_n[2], o_n[0], o_n[1]]), np.vstack([agent3_action[0], agent1_action[0], agent2_action[0]]), r_n[2], np.vstack([o_n_next[2], o_n_next[0], o_n_next[1]]), False)
當經驗池中存儲了一定的經驗之后,我們就可以根據前文介紹過的雙網絡結構和損失函數來訓練每個Agent的Actor和Critic:
train_agent(agent1_ddpg, agent1_ddpg_target, agent1_memory, agent1_actor_target_update, agent1_critic_target_update, sess, [agent2_ddpg_target, agent3_ddpg_target])train_agent(agent2_ddpg, agent2_ddpg_target, agent2_memory, agent2_actor_target_update, agent2_critic_target_update, sess, [agent3_ddpg_target, agent1_ddpg_target])train_agent(agent3_ddpg, agent3_ddpg_target, agent3_memory, agent3_actor_target_update, agent3_critic_target_update, sess, [agent1_ddpg_target, agent2_ddpg_target])
-
算法
+關注
關注
23文章
4612瀏覽量
92891 -
強化學習
+關注
關注
4文章
266瀏覽量
11254
原文標題:探秘多智能體強化學習-MADDPG算法原理及簡單實現
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
基于PPO強化學習算法的AI應用案例
機器學習中的無模型強化學習算法及研究綜述

強化學習的基礎知識和6種基本算法解釋
7個流行的強化學習算法及代碼實現
徹底改變算法交易:強化學習的力量
強化學習的基礎知識和6種基本算法解釋

7個流行的強化學習算法及代碼實現





 工商網監
工商網監
評論