沒人否認,維基百科是現代最令人驚嘆的人類發明之一。
幾年前誰能想到,匿名貢獻者們的義務工作竟創造出前所未有的巨大在線知識庫?維基百科不僅是你寫大學論文時最好的信息渠道,也是一個極其豐富的數據源。
從自然語言處理到監督式機器學習,維基百科助力了無數的數據科學項目。
維基百科的規模之大,可稱為世上最大的百科全書,但也因此稍讓數據工程師們感到頭疼。當然,有合適的工具的話,數據量的規模就不是那么大的問題了。
本文將介紹“如何編程下載和解析英文版維基百科”。
在介紹過程中,我們也會提及以下幾個數據科學中重要的問題:
1、從網絡中搜索和編程下載數據
2、運用Python庫解析網絡數據(HTML, XML, MediaWiki格式)
3、多進程處理、并行化處理
這個項目最初是想要收集維基百科上所有的書籍信息,但我之后發現項目中使用的解決方法可以有更廣泛的應用。這里提到的,以及在Jupyter Notebook里展示的技術,能夠高效處理維基百科上的所有文章,同時還能擴展到其它的網絡數據源中。
本文中運用的Python代碼的筆記放在GitHub,靈感來源于Douwe Osinga超棒的《深度學習手冊》。前面提到的Jupyter Notebooks也可以免費獲取。
GitHub鏈接:
https://github.com/WillKoehrsen/wikipedia-data-science/blob/master/notebooks/Downloading%20and%20Parsing%20Wikipedia%20Articles.ipynb
免費獲取地址:
https://github.com/DOsinga/deep_learning_cookbook
編程搜索和下載數據
任何一個數據科學項目第一步都是獲取數據。我們當然可以一個個進入維基百科頁面打包下載搜索結果,但很快就會下載受限,而且還會給維基百科的服務器造成壓力。還有一種辦法,我們通過dumps.wikimedia.org這個網站獲取維基百科所有數據的定期快照結果,又稱dump。
用下面這段代碼,我們可以看到數據庫的可用版本:
import requests# Library for parsing HTMLfrom bs4 import BeautifulSoupbase_url = 'https://dumps.wikimedia.org/enwiki/'index = requests.get(base_url).textsoup_index = BeautifulSoup(index, 'html.parser')# Find the links on the pagedumps = [a['href'] for a in soup_index.find_all('a') if a.has_attr('href')]dumps['../', '20180620/', '20180701/', '20180720/', '20180801/', '20180820/', '20180901/', '20180920/', 'latest/']
這段代碼使用了BeautifulSoup庫來解析HTML。由于HTML是網頁的標準標識語言,因此就處理網絡數據來說,這個庫簡直是無價瑰寶。
本項目使用的是2018年9月1日的dump(有些dump數據不全,請確保選擇一個你所需的數據)。我們使用下列代碼來找到dump里所有的文件。
dump_url = base_url + '20180901/'# Retrieve the htmldump_html = requests.get(dump_url).text# Convert to a soupsoup_dump = BeautifulSoup(dump_html, 'html.parser')# Find list elements with the class filesoup_dump.find_all('li', {'class': 'file'})[:3][
enwiki-20180901-pages-articles-multistream.xml.bz2 15.2 GB,
enwiki-20180901-pages-articles-multistream-index.txt.bz2 195.6 MB,
enwiki-20180901-pages-meta-history1.xml-p10p2101.7z 320.6 MB]
我們再一次使用BeautifulSoup來解析網絡找尋文件。我們可以在https://dumps.wikimedia.org/enwiki/20180901/頁面里手工下載文件,但這就不夠效率了。網絡數據如此龐雜,懂得如何解析HTML和在程序中與網頁交互是非常有用的——學點網站檢索知識,龐大的新數據源便觸手可及。
考慮好下載什么
上述代碼把dump里的所有文件都找出來了,你也就有了一些下載的選擇:文章當前版本,文章頁以及當前討論列表,或者是文章所有歷史修改版本和討論列表。如果你選擇最后一個,那就是萬億字節的數據量了!本項目只選用文章最新版本。
所有文章的當前版本能以單個文檔的形式獲得,但如果我們下載解析這個文檔,就得非常費勁地一篇篇文章翻看,非常低效。更好的辦法是,下載多個分區文檔,每個文檔內容是文章的一個章節。之后,我們可以通過并行化一次解析多個文檔,顯著提高效率。
“當我處理文檔時,我更喜歡多個小文檔而非一個大文檔,這樣我就可以并行化運行多個文檔了。”
分區文檔格式為bz2壓縮的XML(可擴展標識語言),每個分區大小300~400MB,全部的壓縮包大小15.4GB。無需解壓,但如果你想解壓,大小約58GB。這個大小對于人類的全部知識來說似乎并不太大。
維基百科壓縮文件大小
下載文件
Keras 中的get_file語句在實際下載文件中非常好用。下面的代碼可通過鏈接下載文件并保存到磁盤中:
from keras.utils import get_filesaved_file_path = get_file(file, url)
下載的文件保存在~/.keras/datasets/,也是Keras默認保存設置。一次性下載全部文件需2個多小時(你可以試試并行下載,但我試圖同時進行多個下載任務時被限速了)
解析數據
我們首先得解壓文件。但實際我們發現,想獲取全部文章數據根本不需要這樣。我們可以通過一次解壓運行一行內容來迭代文檔。當內存不夠運行大容量數據時,在文件間迭代通常是唯一選擇。我們可以使用bz2庫對bz2壓縮的文件迭代。
不過在測試過程中,我發現了一個更快捷(雙倍快捷)的方法,用的是system utility bzcat以及Python模塊的subprocess。以上揭示了一個重要的觀點:解決問題往往有很多種辦法,而找到最有效辦法的唯一方式就是對我們的方案進行基準測試。這可以很簡單地通過%%timeit Jupyter cell magic來對方案計時評價。
迭代解壓文件的基本格式為:
data_path = '~/.keras/datasets/enwiki-20180901-pages-articles15.xml-p7744803p9244803.bz2# Iterate through compressed file one line at a timefor line in subprocess.Popen(['bzcat'], stdin = open(data_path), stdout = subprocess.PIPE).stdout: # process line
如果簡單地讀取XML數據,并附為一個列表,我們得到看起來像這樣的東西:
維基百科文章的源XML
上面展示了一篇維基百科文章的XML文件。每個文件里面有成千上萬篇文章,因此我們下載的文件里包含百萬行這樣的語句。如果我們真想把事情弄復雜,我們可以用正則表達式和字符串匹配跑一遍文檔來找到每篇文章。這就極其低效了,我們可以采取一個更好的辦法:使用解析XML和維基百科式文章的定制化工具。
解析方法
我們需要在兩個層面上來解析文檔:
1、從XML中提取文章標題和內容
2、從文章內容中提取相關信息
好在,Python對這兩個都有不錯的應對方法。
解析XML
解決第一個問題——定位文章,我們使用SAX(Simple API for XML) 語法解析器。BeautifulSoup語句也可以用來解析XML,但需要內存載入整個文檔并且建立一個文檔對象模型(DOM)。而SAX一次只運行XML里的一行字,完美符合我們的應用場景。
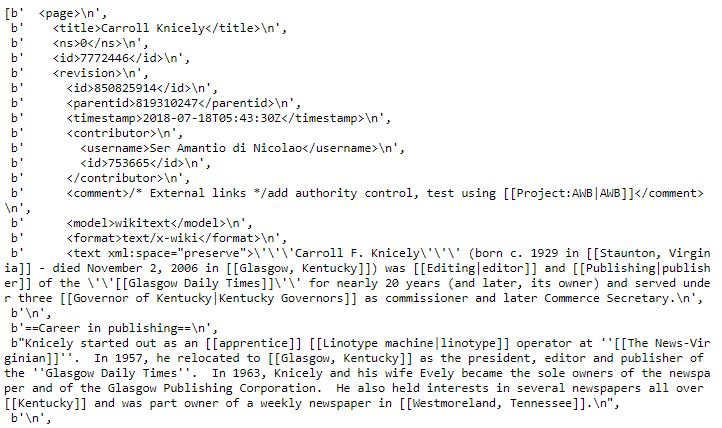
基本思路就是我們對XML文檔進行搜索,在特定標簽間提取相關信息。例如,給出下面這段XML語句:
Carroll F. Knicely'''Carroll F. Knicely''' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] of the ''[[Glasgow Daily Times]]'' for nearly 20 years (and later, its owner) and served under three [[Governor of Kentucky|Kentucky Governors]] as commissioner and later Commerce Secretary.
'
我們想篩出在
和<text>這兩<a target="_blank"><u>標簽</u></a>間的內容(這個title就是維基百科文章標題,text就是文章內容)。SAX能直接讓我們實現這樣的功能——通過parser和ContentHandler這兩個語句來控制信息如何通過解析器然后被處理。每次掃一行XML句子進解析器,Content Handler則幫我們提取相關的信息。</p>
<p style="text-indent: 2em;">
如果你不嘗試做一下,可能理解起來有點難度,但是Content handler的思想是尋找開始標簽和結束標簽之間的內容,將找到的字符添加到緩存中。然后將緩存的內容保存到字典中,其中相應的標簽作為對應的鍵。最后我們得到一個鍵是標簽,值是標簽中的內容的字典。下一步,我們會將這個字典傳遞給另一個函數,它將解析字典中的內容。</p>
<p style="text-indent: 2em;">
我們唯一需要編寫的SAX的部分是Content Handler。全文如下:</p>
<p style="text-indent: 2em;">
在這段代碼中,我們尋找標簽為title和text的標簽。每次解析器遇到其中一個時,它會將字符保存到緩存中,直到遇到對應的結束標簽(</tag>)。然后它會保存緩存內容到字典中-- self._values。文章由<page>標簽區分,如果Content Handler遇到一個代表結束的</page>標簽,它將添加self._values 到文章列表(self._pages)中。如果感到疑惑了,實踐觀摩一下可能會有幫助。</p>
<p style="text-indent: 2em;">
下面的代碼顯示了如何通過XML文件查找文章。現在,我們只是將它們保存到handler._pages中,稍后我們將把文章發送到另一個函數中進行解析。</p>
<p style="text-indent: 2em;">
# Object for handling xmlhandler = WikiXmlHandler()# Parsing objectparser = xml.sax.make_parser()parser.setContentHandler(handler)# Iteratively process filefor line in subprocess.Popen(['bzcat'], stdin = open(data_path), stdout = subprocess.PIPE).stdout: parser.feed(line) # Stop when 3 articles have been found if len(handler._pages) > 2: break</p>
<p style="text-indent: 2em;">
如果我們觀察handler._pages,我們將看到一個列表,其中每個元素都是一個包含一篇文章的標題和內容的元組:</p>
<p style="text-indent: 2em;">
handler._pages[0][('Carroll Knicely', "'''Carroll F. Knicely''' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] ...)]</p>
<p style="text-indent: 2em;">
此時,我們已經編寫的代碼可以成功地識別XML中的文章。現在我們完成了解析文件一半的任務,下一步是處理文章以查找特定頁面和信息。再次,我們使用專為這項工作而創建的一個工具。</p>
<p style="text-indent: 2em;">
解析維基百科文章</p>
<p style="text-indent: 2em;">
維基百科運行在一個叫做MediaWiki的軟件上,該軟件用來構建wiki。這使文章遵循一種標準格式,這種格式可以輕易地用編程方式訪問其中的信息。雖然一篇文章的文本看起來可能只是一個字符串,但由于格式的原因,它實際上編碼了更多的信息。為了有效地獲取這些信息,我們引進了強大的 mwparse<a href="http://www.xsypw.cn/tongxin/rf/" target="_blank"><u>rf</u></a><a href="http://www.xsypw.cn/tags/rom/" target="_blank"><u>rom</u></a>hell, 一個為處理MediaWiki內容而構建的庫。</p>
<p style="text-indent: 2em;">
如果我們將維基百科文章的文本傳遞給mwparserfromhell,我們會得到一個Wikicode對象,它含有許多對數據進行排序的方法。例如,以下代碼從文章創建了一個wikicode對象,并檢索文章中的wikilinks()。這些鏈接指向維基百科的其他文章:</p>
<p style="text-indent: 2em;">
import mwparserfromhell# Create the wiki articlewiki = mwparserfromhell.parse(handler._pages[6][1])# Find the wikilinkswikilinks = [x.title for x in wiki.filter_wikilinks()]wikilinks[:5]['Provo, Utah', 'Wasatch Front', 'Megahertz', 'Contemporary hit radio', 'watt']</p>
<p style="text-indent: 2em;">
有許多有用的方法可以應用于wikicode,例如查找注釋或搜索特定的關鍵字。如果您想獲得文章文本的最終修訂版本,可以調用:</p>
<p style="text-indent: 2em;">
wiki.strip_code().strip()'KENZ (94.9 FM, " Power 94.9 " ) is a top 40/CHR radio station bro<a href="http://www.xsypw.cn/tags/adc/" target="_blank"><u>adc</u></a>asting to Salt Lake City, Utah '</p>
<p style="text-indent: 2em;">
因為我的最終目標是找到所有關于書籍的文章,那么是否有一種方法可以使用解析器來識別某個類別中的文章呢?幸運的是,答案是肯定的——使用MediaWiki templates。</p>
<p style="text-indent: 2em;">
文章模板</p>
<p style="text-indent: 2em;">
模板(templates)是記錄信息的標準方法。維基百科上有無數的模板,但與我們的目的最相關的是信息框(Infoboxes)。有些模板編碼文章的摘要信息。例如,戰爭與和平的信息框是:</p>
<p align="center">
</p>
<p style="text-indent: 2em;">
維基百科上的每一類文章,如電影、書籍或廣播電臺,都有自己的信息框。在書籍的例子中,信息框模板被命名為Infobox book。同樣,wiki對象有一個名為filter_templates()的方法,它允許我們從一篇文章中提取特定的模板。因此,如果我們想知道一篇文章是否是關于一本書的,我們可以通過book信息框去過濾。展示如下:</p>
<p style="text-indent: 2em;">
# Filter article for book templatewiki.filter_templates('Infobox book')</p>
<p style="text-indent: 2em;">
如果匹配成功,那我們就找到一本書了!要查找你感興趣的文章類別的信息框模板,請參閱信息框列表。</p>
<p style="text-indent: 2em;">
如何將用于解析文章的mwparserfromhell與我們編寫的SAX解析器結合起來?我們修改了Content Handler中的endElement方法,將包含文章標題和文本的值的字典,發送到通過指定模板搜索文章文本的函數中。如果函數找到了我們想要的文章,它會從文章中提取信息,然后返回給handler。首先,我將展示更新后的endElement 。</p>
<p style="text-indent: 2em;">
def endElement(self, name): """Closing tag of element""" if name == self._current_tag: self._values[name] = ' '.join(self._buffer) if name == 'page': self._article_count += 1 # Send the page to the process article function book = process_article(**self._values, template = 'Infobox book') # If article is a book append to the list of books if book: self._books.append(book)</p>
<p style="text-indent: 2em;">
一旦解析器到達文章的末尾,我們將文章傳遞到函數process_article,如下所示:</p>
<p style="text-indent: 2em;">
def process_article(title, text, timestamp, template = 'Infobox book'): """Process a wikipedia article looking for template""" # Create a parsing object wikicode = mwparserfromhell.parse(text) # Search through templates for the template matches = wikicode.filter_templates(matches = template) if len(matches) >= 1: # Extr<a target="_blank"><u>ac</u></a>t information from infobox properties = {pa<a href="http://www.xsypw.cn/tags/ram/" target="_blank"><u>ram</u></a>.name.strip_code().strip(): param.value.strip_code().strip() for param in matches[0].params if param.value.strip_code().strip()} # Extract internal wikilinks</p>
<p style="text-indent: 2em;">
雖然我正在尋找有關書籍的文章,但是這個函數可以用來搜索維基百科上任何類別的文章。只需將模板替換為指定類別的模板(例如Infobox language是用來尋找語言的),它只會返回符合條件的文章信息。</p>
<p style="text-indent: 2em;">
我們可以在一個文件上測試這個函數和新的ContentHandler。</p>
<p style="text-indent: 2em;">
Searched through 427481 articles.Found 1426 books in 1055 seconds.</p>
<p style="text-indent: 2em;">
讓我們看一下查找一本書的結果:</p>
<p style="text-indent: 2em;">
books[10]['War and Peace', {'name': 'War and Peace', 'author': 'Leo Tolstoy', 'language': 'Russian, with some French', 'country': 'Russia', 'genre': 'Novel (Historical novel)', 'publisher': 'The Russian Messenger (serial)', 'title_orig': 'Война и миръ', 'orig_lang_code': 'ru', 'translator': 'The first translation of War and Peace into English was by American Nathan Haskell Dole, in 1899', 'image': 'Tolstoy - War and Peace - first edition, 1869.jpg', 'caption': 'Front page of War and Peace, first edition, 1869 (Russian)', 'release_date': 'Serialised 1865–1867; book 1869', 'media_type': 'Print', 'pages': '1,225 (first published edition)'}, ['Leo Tolstoy', 'Novel', 'Historical novel', 'The Russian Messenger', 'Serial (publishing)', 'Category:1869 Russian novels', 'Category:Epic novels', 'Category:Novels set in 19th-century Russia', 'Category:Russian novels <a target="_blank"><u>ad</u></a>apted into films', 'Category:Russian philosophical novels'], ['https://books.google.com/?id=c4HEAN-ti1MC', 'https://www.britannica.com/art/English-literature', 'https://books.google.com/books?id=xf7umXHGDPcC', 'https://books.google.com/?id=E5fotqsglPEC', 'https://books.google.com/?id=9sHebfZIXFAC'], '2018-08-29T02:37:35Z']</p>
<p style="text-indent: 2em;">
對于維基百科上的每一本書,我們把信息框中的信息整理為字典、書籍在維基百科中的wikilinks信息、書籍的外部鏈接和<a href="http://www.xsypw.cn/article/zt/" target="_blank"><u>最新</u></a>編輯的時間戳。(我把精力集中在這些信息上,為我的下一個項目建立一個圖書<a href="http://www.xsypw.cn/v/" target="_blank"><u>推薦</u></a>系統)。你可以修改process_article函數和WikiXmlHandler類,以查找任何你需要的信息和文章!</p>
<p style="text-indent: 2em;">
如果你看一下只處理一個文件的時間,1055秒,然后乘以55,你會發現處理所有文件的時間超過了15個小時!當然,我們可以在一夜之間運行,但如果可以的話,我不想浪費額外的時間。這就引出了我們將在本項目中介紹的最后一種技術:使用多處理和多線程進行并行化。</p>
<p style="text-indent: 2em;">
并行操作</p>
<p style="text-indent: 2em;">
與其一次一個解析文件,不如同時處理其中的幾個(這就是我們下載分區的原因)。我們可以使用并行化,通過多線程或多處理來實現。</p>
<p style="text-indent: 2em;">
多線程與多處理</p>
<p style="text-indent: 2em;">
多線程和多處理是同時在計算機或多臺計算機上執行許多任務的方法。我們磁盤上有許多文件,每個文件都需要以相同的方式進行解析。一個簡單的方法是一次解析一個文件,但這并沒有充分利用我們的資源。因此,我們可以使用多線程或多處理同時解析多個文件,這將大大加快整個過程。</p>
<p style="text-indent: 2em;">
通常,多線程對于輸入/輸出綁定任務(例如讀取文件或發出請求)更好(更快)。多處理對于<a href="http://www.xsypw.cn/v/tag/132/" target="_blank"><u>cpu</u></a>密集型任務更好(更快)。對于解析文章的過程,我不確定哪種方法是最優的,因此我再次用不同的<a target="_blank"><u>參數</u></a>對這兩種方法進行了基準測試。</p>
<p style="text-indent: 2em;">
學習如何進行測試和尋找不同的方法來解決一個問題,你將會在數據科學或任何技術的職業生涯中走得更遠。</p>
<p style="text-indent: 2em;">
相關報道:</p>
<p style="text-indent: 2em;">
https://toward<a target="_blank"><u>sd</u></a>atascience.com/wikipedia-data-science-working-with-the-worlds-largest-encyclopedia-c08efbac5f5c</p>
<p style="text-indent: 2em;">
【今日機器學習概念】</p>
<p style="text-indent: 2em;">
Have a Great Definition</p>
<p align="center">
</p>
</div>
<div id="a5mgapgs4i" class="statement2">
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
<a class="complaint handleJumpBy" href="/about/tousu.html" target="_blank">舉報投訴</a>
</div>
<ul class="hot-main clearfix" style="text-align: right; ">
<li data-href="http://www.xsypw.cn/tags/編程/">
<span>編程</span>
<div id="a5mgapgs4i" class="hot-des">
<div id="a5mgapgs4i" class="detail">
<div id="a5mgapgs4i" class="top clearfix">
<div id="a5mgapgs4i" class="lf title">
<a href="http://www.xsypw.cn/tags/編程" target="_blank">編程</a>
</div>
<div id="a5mgapgs4i" class="lf attend advertTagId" data-id="5440">+關注</div>
</div>
<div class="a5mgapgs4i" id="tag_desc_button5440"></div>
<div id="a5mgapgs4i" class="clearfix des-detail">
<div id="a5mgapgs4i" class="lf">
<p>關注</p>
<span>88</span>
</div>
<div id="a5mgapgs4i" class="lf">
<p>文章</p>
<span>3628</span>
</div>
<div id="a5mgapgs4i" class="lf">
<p>瀏覽量</p>
<span>93812</span>
</div>
</div>
</div>
</div>
</li><li data-href="http://www.xsypw.cn/tags/python/">
<span>python</span>
<div id="a5mgapgs4i" class="hot-des">
<div id="a5mgapgs4i" class="detail">
<div id="a5mgapgs4i" class="top clearfix">
<div id="a5mgapgs4i" class="lf title">
<a href="http://www.xsypw.cn/tags/python" target="_blank">python</a>
</div>
<div id="a5mgapgs4i" class="lf attend advertTagId" data-id="42127">+關注</div>
</div>
<div class="a5mgapgs4i" id="tag_desc_button42127"></div>
<div id="a5mgapgs4i" class="clearfix des-detail">
<div id="a5mgapgs4i" class="lf">
<p>關注</p>
<span>56</span>
</div>
<div id="a5mgapgs4i" class="lf">
<p>文章</p>
<span>4799</span>
</div>
<div id="a5mgapgs4i" class="lf">
<p>瀏覽量</p>
<span>84817</span>
</div>
</div>
</div>
</div>
</li> </ul>
<!-- 廣告中臺 -->
<div id="a5mgapgs4i" class="articleContentFooterAD" style="display: none; margin: 20px 0 0 0;"></div>
<div id="a5mgapgs4i" class="wx_detail">
<p>原文標題:維基百科中的數據科學:手把手教你用Python讀懂全球最大百科全書</p>
<p>文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。</p>
</div> </div>
<div id="a5mgapgs4i" class="art-share-layout mt18" id="shareAddPcb">
<div id="a5mgapgs4i" class="clearfix">
<a href="javascript:;" class="art-collect J_bottom-coll J_coll-btn" style="visibility:visible">收藏</a>
<span id="a5mgapgs4i" class="ml15 fb"><span id="a5mgapgs4i" class="J_stownum"></span>人收藏</span>
<div id="a5mgapgs4i" class="bdsharebuttonbox fr">
<div id="a5mgapgs4i" class="share-web-qrcode--detail fl">
<i class="share-web-qrcode--share-icon"></i>
<div id="a5mgapgs4i" class="share-web-qrcode--bubble">
<div id="a5mgapgs4i" class="share-web-qrcode--bubble-inner">
<p class="qrcode-copy-title">掃一掃,分享給好友</p>
<div id="a5mgapgs4i" class="qrcode-image"></div>
<div id="a5mgapgs4i" class="qrcode-copy-link"><span>復制鏈接分享</span></div>
</div>
</div>
</div>
</div>
</div>
<a class="art-like-up J_bottom-like J_like-btn" href="javascript:;"></a>
<ul class="art-like-u"></ul>
</div>
<!-- comment Begin -->
<div id="a5mgapgs4i" class="comment-list detaildzs_list" id="comment">
<h2 class="title2">評論</h2>
</div><!-- comment End -->
<div id="a5mgapgs4i" class="c-form" id="cForm">
<!-- 未登錄 -->
<p class="c-login special-login">發布評論請先 <a href="javascript:;">登錄</a></p> </div>
<div id="a5mgapgs4i" class="article-list">
<p>相關推薦</p>
<div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/6417699.html" target="_blank" >
<b class='flag-5'>百</b>度<b class='flag-5'>百科</b>啟動“繁星計劃”</a>
</h2>
<div id="a5mgapgs4i" class="summary">近日,<b class='flag-5'>百</b>度<b class='flag-5'>百科</b>攜手中國科協、中國科學院大學共同舉辦了史記2024·科學<b class='flag-5'>百科</b>100詞發布會,并在此盛會上正式啟動了“繁星計劃”。這一計劃的核心目標在于利用前沿的AI技術,包括數字人、智能體等,以及</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 12-31 10:26 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">146</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/6357870.html" target="_blank" >
半導體術語小<b class='flag-5'>百科</b></a>
</h2>
<div id="a5mgapgs4i" class="summary">面對半導體行業的高速發展,掌握核心術語不僅是行業人的基本功,更是溝通無礙的關鍵。無論你是剛入行的新手,還是經驗豐富的達人,這份“半導體術語小<b class='flag-5'>百科</b>”將帶你走進從硅到微芯片、從前端到后端的每一環節。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 11-20 11:39 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">415</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/6347214.html" target="_blank" >
對比<b class='flag-5'>Python</b>與Java<b class='flag-5'>編程</b>語言</a>
</h2>
<div id="a5mgapgs4i" class="summary"><b class='flag-5'>Python</b>與Java都是目前非常流行的<b class='flag-5'>編程</b>語言,它們各有其獨特的優勢和適用場景。以下是對這兩種<b class='flag-5'>編程</b>語言的對比: 一、語法和易用性 <b class='flag-5'>Python</b> 語法簡潔,代碼更易讀,非常適合初學者。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 11-15 09:31 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">350</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" >
<h2 class="title">
<a href="http://www.xsypw.cn/d/6295440.html" target="_blank" >
鴻蒙智行再迎OTA升級,車載小藝化身私人用車顧問、<b class='flag-5'>百科</b>導師</a>
</h2>
<div id="a5mgapgs4i" class="summary">近期,鴻蒙智行迎來重磅OTA升級,此次升級的功能中,讓問界M5、M7車主們翹首以盼的大模型車載小藝全新“上車”,解鎖眾多寶藏語音技能。在盤古大模型賦能下,小藝化身“私人用車顧問”、“<b class='flag-5'>百科</b>小導師”等</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 10-30 14:41 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">242</span>次閱讀 </div>
<a href="http://www.xsypw.cn/d/6295440.html" class="thumb" target="_blank">
<img src="https://file1.elecfans.com//web1/M00/F3/F3/wKgaoWch1R2AKJDCAEADp0jog3Q69.jpeg" alt="鴻蒙智行再迎OTA升級,車載小藝化身私人用車顧問、<b class='flag-5'>百科</b>導師" /> </a>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a target="_blank" >
名單公布!【書籍評測活動NO.49】大模型啟示錄:一本AI應用<b class='flag-5'>百科</b>全書</a>
</h2>
<div id="a5mgapgs4i" class="summary">大家了解全球最領先的大模型場景。
本書像 一本AI應用<b class='flag-5'>百科</b>全書 ,給予讀者落地大模型時的啟發。
本書的作者來自大模型應用公司微軟Copilot的產品經理、最前沿的大模型研究員、國際對沖基金、云廠商前</div>
<div id="a5mgapgs4i" class="info">
<span id="a5mgapgs4i" class="fby">發表于</span> 10-28 15:34 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
</div>
</div> <div id="a5mgapgs4i" class="article" >
<h2 class="title">
<a href="http://www.xsypw.cn/soft/Mec/2024/202409145687770.html" target="_blank" >
可<b class='flag-5'>編程</b>邏輯控制器——安全威脅<b class='flag-5'>和解</b>決方案</a>
</h2>
<div id="a5mgapgs4i" class="summary">電子發燒友網站提供《可<b class='flag-5'>編程</b>邏輯控制器——安全威脅<b class='flag-5'>和解</b>決方案.pdf》資料免費<b class='flag-5'>下載</b></div>
<div id="a5mgapgs4i" class="info">
<span id="a5mgapgs4i" class="fby">發表于</span> 09-14 09:57 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">0</span>次下載 </div>
<a href="http://www.xsypw.cn/soft/Mec/2024/202409145687770.html" class="thumb" target="_blank">
<img src="https://file.elecfans.com/web1/M00/D9/4E/pIYBAF_1ac2Ac0EEAABDkS1IP1s689.png" alt="可<b class='flag-5'>編程</b>邏輯控制器——安全威脅<b class='flag-5'>和解</b>決方案" /> </a>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/5557779.html" target="_blank" >
自動售貨機MDB協議中文<b class='flag-5'>解析</b>(七)MDB-RS232控制紙幣器的詳細流程<b class='flag-5'>和解析</b></a>
</h2>
<div id="a5mgapgs4i" class="summary">自動售貨機MDB協議中文<b class='flag-5'>解析</b>(七)MDB-RS232控制紙幣器的詳細流程<b class='flag-5'>和解析</b></div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 09-09 10:04 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">629</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/soft/Mec/2024/202409075504592.html" target="_blank" >
Sony_TC-K333ESL_K970ES說明書<b class='flag-5'>英文版</b></a>
</h2>
<div id="a5mgapgs4i" class="summary">Sony_TC-K333ESL_K970ES ? 說明書<b class='flag-5'>英文版</b></div>
<div id="a5mgapgs4i" class="info">
<span id="a5mgapgs4i" class="fby">發表于</span> 09-07 11:37 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">2</span>次下載 </div>
</div> <div id="a5mgapgs4i" class="article" >
<h2 class="title">
<a href="http://www.xsypw.cn/d/5030969.html" target="_blank" >
自動售貨機MDB協議中文<b class='flag-5'>解析</b>(六)MDB-RS232控制硬幣器的流程<b class='flag-5'>和解析</b></a>
</h2>
<div id="a5mgapgs4i" class="summary">自動售貨機MDB協議中文<b class='flag-5'>解析</b>(六)MDB-RS232控制硬幣器的流程<b class='flag-5'>和解析</b></div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 08-19 15:53 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">703</span>次閱讀 </div>
<a href="http://www.xsypw.cn/d/5030969.html" class="thumb" target="_blank">
<img src="https://file1.elecfans.com/web2/M00/04/46/wKgaombC-D2AdROZAAFowlDeR0g563.png" alt="自動售貨機MDB協議中文<b class='flag-5'>解析</b>(六)MDB-RS232控制硬幣器的流程<b class='flag-5'>和解析</b>" /> </a>
</div> <div id="a5mgapgs4i" class="article" >
<h2 class="title">
<a href="http://www.xsypw.cn/d/2889768.html" target="_blank" >
《科技日報》<b class='flag-5'>英文版</b>頭版頭條:“本源悟空”開啟中國量子計算新時代</a>
</h2>
<div id="a5mgapgs4i" class="summary">《科技日報》<b class='flag-5'>英文版</b>頭版頭條:“本源悟空”開啟中國量子計算新時代</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 05-19 08:22 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">688</span>次閱讀 </div>
<a href="http://www.xsypw.cn/d/2889768.html" class="thumb" target="_blank">
<img src="https://file.elecfans.com/web2/M00/3F/9D/poYBAGJo-maAOH8MAAIB_hk2Mno583.png" alt="《科技日報》<b class='flag-5'>英文版</b>頭版頭條:“本源悟空”開啟中國量子計算新時代" /> </a>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/2841294.html" target="_blank" >
廣東云<b class='flag-5'>百科</b>技致力于推動智能車聯網行業的創新與發展</a>
</h2>
<div id="a5mgapgs4i" class="summary">“ 2024年5月14日廣東省物聯網協會在廣州市組織并主持了由廣東云<b class='flag-5'>百科</b>技有限公司為主要完成單位完成的《標準化車聯網接入服務關鍵技術》科技成果評價會。評價委員會由廣州大學、華南師范大學、華南理工大學、廣東技術師范學院、廣東省物聯網協會等專家組成。”</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 05-16 10:23 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">1244</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/2798559.html" target="_blank" >
OpenAI發布全新搜尋引擎,引領搜索體驗新高度</a>
</h2>
<div id="a5mgapgs4i" class="summary">據彭博社報道,OpenAI正在研發一款新型搜索引擎,利用生成式AI實現更人性化的問答互動。據悉,此項產品將于不久后正式上線,用戶只需以自然語言提問,ChatGPT即可根據<b class='flag-5'>維基百科</b>及博客文章等資源進行解答。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 05-09 10:40 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">526</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/2798371.html" target="_blank" >
OpenAI或將挑戰谷歌,推出基于ChatGPT的搜索引擎</a>
</h2>
<div id="a5mgapgs4i" class="summary">據悉,此項功能將允許用戶向ChatGPT提問,獲取包括<b class='flag-5'>維基百科</b>內容及博客文章在內的互聯網信息。此外,部分版本的產品還將提供文字、圖片結合的回答方式。OpenAI還計劃擴展現有ChatGPT功能,以容納新的搜索功能。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 05-09 10:00 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">404</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/2613589.html" target="_blank" >
容<b class='flag-5'>百科</b>技宣布與SK On簽訂《合作備忘錄》</a>
</h2>
<div id="a5mgapgs4i" class="summary">本周,容<b class='flag-5'>百科</b>技宣布與SK On簽訂《合作備忘錄》,雙方將圍繞三元和磷酸錳鐵鋰正極開展深度合作。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 03-29 09:56 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">472</span>次閱讀 </div>
</div> <div id="a5mgapgs4i" class="article" style="padding-left: 0px;">
<h2 class="title">
<a href="http://www.xsypw.cn/d/2395154.html" target="_blank" >
容<b class='flag-5'>百科</b>技攜手韓國LGES共探新能源技術先機</a>
</h2>
<div id="a5mgapgs4i" class="summary">據悉,此次簽約時雙方優勢互補的有力體現。作為全球領先的新能源材料研發制造商,容<b class='flag-5'>百科</b>技在鋰離子電池材料方面具有深厚的技術儲備;而韓國LG能源解決方案公司則擁有豐富的項目管理經驗和前沿科研實力。</div>
<div id="a5mgapgs4i" class="info">
<a class="face s" href="" target="_blank" rel="nofollow">
<img src="" alt="的頭像"/>
</a> <span id="a5mgapgs4i" class="fby">發表于</span> 02-03 14:19 <!-- <span id="a5mgapgs4i" class="art_click_count" data-id=""></span>次閱讀 -->
<span id="a5mgapgs4i" class="sp">?</span><span id="a5mgapgs4i" class="" data-id="">730</span>次閱讀 </div>
</div> </div> </div><!-- .main-wrap -->
</article>
<aside class="aside">
<!-- 非專欄 -->
<input type="hidden" name="zl_mp" value="0"> <div class="a5mgapgs4i" id="new-adsm-berry" ></div>
<div class="a5mgapgs4i" id="new-company-berry"></div>
<!-- 推薦文章【主站文章顯示這個】 -->
<div id="a5mgapgs4i" class="aside-section">
<div id="a5mgapgs4i" class="aside-section-head">
<h3 class="aside-section-name">精選推薦</h3>
<a class="aside-section-more" id="recMore" href="http://www.xsypw.cn/d/">更多<i class="arrow_right"></i></a>
</div>
<div id="a5mgapgs4i" class="aside-section-body">
<ul class="article-rec-tabs">
<li data-index="0" class="is-active">文章</li> <li data-index="2" >資料</li> <li data-index="3" >帖子</li> </ul>
<!-- 文章默認展示 start -->
<ul class="article-rec-content is-active">
<li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/d/6430684.html" target="_blank">
<span>eIQ Time Series Studio工具使用攻略(三)-工程創建</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" href="http://www.xsypw.cn/d/user/4782250/" target="_blank">恩智浦MCU加油站</a>
<div id="a5mgapgs4i" class="text-date">12小時前</div>
<div id="a5mgapgs4i" class="text-view">207 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/d/6430616.html" target="_blank">
<span>采用MPS 可變關斷時間控制器HFC0300實現反激變換器的設計指南</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" href="http://www.xsypw.cn/d/user/1052410/" target="_blank">eeDesigner</a>
<div id="a5mgapgs4i" class="text-date">12小時前</div>
<div id="a5mgapgs4i" class="text-view">245 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/d/6430473.html" target="_blank">
<span>LabVIEW運動控制(一):EtherCAT運動控制器的SCARA機械手應用</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">正運動技術</a>
<div id="a5mgapgs4i" class="text-date">16小時前</div>
<div id="a5mgapgs4i" class="text-view">125 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/d/6430460.html" target="_blank">
<span>基于物聯網的人工淡水湖養殖系統設計</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" href="http://www.xsypw.cn/d/user/1710892/" target="_blank">DS小龍哥-嵌入式技術</a>
<div id="a5mgapgs4i" class="text-date">16小時前</div>
<div id="a5mgapgs4i" class="text-view">223 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/d/6430457.html" target="_blank">
<span>基于華為云人臉識別服務(FRS)開發體驗</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" href="http://www.xsypw.cn/d/user/1710892/" target="_blank">DS小龍哥-嵌入式技術</a>
<div id="a5mgapgs4i" class="text-date">16小時前</div>
<div id="a5mgapgs4i" class="text-view">240 閱讀</div>
</div>
</div>
</li> </ul> <!-- 文章 end -->
<!-- 方案默認展示 start -->
<!-- 方案 end -->
<ul class="article-rec-content"> <li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-left">
<div id="a5mgapgs4i" class="icon-type rar"></div>
</div>
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/soft/22/163/2010/2010112495968.html" target="_blank">
<span>CADENCE PCB設計:布局與布線</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">羅技快修</a>
<div id="a5mgapgs4i" class="text-date">2580</div>
<div id="a5mgapgs4i" class="text-date">免費</div>
<div id="a5mgapgs4i" class="text-down">0下載</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-left">
<div id="a5mgapgs4i" class="icon-type zip"></div>
</div>
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/soft/Mec/2022/202205251840222.html" target="_blank">
<span>Damon Nomad終端用戶界面</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">早知</a>
<div id="a5mgapgs4i" class="text-date">0.12 MB</div>
<div id="a5mgapgs4i" class="text-date">免費</div>
<div id="a5mgapgs4i" class="text-down">0下載</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-left">
<div id="a5mgapgs4i" class="icon-type zip"></div>
</div>
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/soft/Mec/2022/202205261840611.html" target="_blank">
<span>wsshOps基于django開發的webssh堡壘機</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">吳湛</a>
<div id="a5mgapgs4i" class="text-date">45.55 MB</div>
<div id="a5mgapgs4i" class="text-date">免費</div>
<div id="a5mgapgs4i" class="text-down">1下載</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-left">
<div id="a5mgapgs4i" class="icon-type zip"></div>
</div>
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/soft/Mec/2022/202208081873127.html" target="_blank">
<span>簡單的arduino游戲機設計案例</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">李超</a>
<div id="a5mgapgs4i" class="text-date">0.01 MB</div>
<div id="a5mgapgs4i" class="text-date">2積分</div>
<div id="a5mgapgs4i" class="text-down">1下載</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-left">
<div id="a5mgapgs4i" class="icon-type zip"></div>
</div>
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a href="http://www.xsypw.cn/soft/49/52/2022/202209261898325.html" target="_blank">
<span>RK3588全套硬件設計資料 含原理圖 pcb源文件 數據手冊</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">jf_70971093</a>
<div id="a5mgapgs4i" class="text-date">1.92 MB</div>
<div id="a5mgapgs4i" class="text-date">1積分</div>
<div id="a5mgapgs4i" class="text-down">385下載</div>
</div>
</div>
</li> </ul> <!-- 資料 end -->
<!-- 帖子默認展示 start -->
<ul class="article-rec-content"> <li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a target="_blank">
<span>尋找DC/DC 4.5-60V同步降壓芯片</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">254712S</a>
<div id="a5mgapgs4i" class="text-date">1天前</div>
<div id="a5mgapgs4i" class="text-view">227 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a target="_blank">
<span>恒流源無法正常工作</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">jf_44622885</a>
<div id="a5mgapgs4i" class="text-date">1天前</div>
<div id="a5mgapgs4i" class="text-view">227 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a target="_blank">
<span>imx6ull 和 lan8742 工作起來不正常, ping 老是丟包</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">jf_38496317</a>
<div id="a5mgapgs4i" class="text-date">1天前</div>
<div id="a5mgapgs4i" class="text-view">264 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a target="_blank">
<span>AD7923的DOUT引腳一直是高電平,求助!</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">jf_02320428</a>
<div id="a5mgapgs4i" class="text-date">1天前</div>
<div id="a5mgapgs4i" class="text-view">216 閱讀</div>
</div>
</div>
</li><li id="a5mgapgs4i" class="article-rec-item">
<div id="a5mgapgs4i" class="col-right">
<h4 class="text-title">
<a target="_blank">
<span>HarmonyOS NEXT 原生應用開發:社交通訊錄界面實現</span>
</a>
</h4>
<div id="a5mgapgs4i" class="text-content">
<a class="text-name" target="_blank">李洋水蛟龍</a>
<div id="a5mgapgs4i" class="text-date">1天前</div>
<div id="a5mgapgs4i" class="text-view">159 閱讀</div>
</div>
</div>
</li> </ul> <!-- 帖子 end -->
<!-- 視頻 start -->
<!-- 視頻 end -->
<!-- 話題 start -->
<!-- 話題 end -->
</div>
</div>
<!-- <div class="a5mgapgs4i" id="new-company-zone"></div> -->
<div class="a5mgapgs4i" id="new-course-berry" ></div>
<!-- 推薦專欄 -->
<div id="a5mgapgs4i" class="aside-section dzs-article-column">
<div id="a5mgapgs4i" class="aside-section-head">
<h3 class="aside-section-name">推薦專欄</h3>
<a class="aside-section-more" href="http://www.xsypw.cn/d/column">更多<i class="arrow_right"></i></a>
</div>
<div id="a5mgapgs4i" class="aside-section-body">
<ul class="dzs-article-column-list"></ul>
</div>
</div> <div class="a5mgapgs4i" id="new-webinar-berry"></div>
<div class="a5mgapgs4i" id="IndexRightBottom"></div>
</aside>
</section>
<!-- Page #content End -->
<input type="hidden" name="aid" id="webID" value="808775">
<!-- $article['store_flag'] = 15 為企業號 -->
<input type="hidden" class="store_flag" value="0">
<input type="hidden" class="evip_type" value="0">
<!--企業號文章id -->
<input type="hidden" class="evip_article_id" value="">
<!-- 企業號id -->
<input type="hidden" class="evip_id" value="">
<!--- 企業號是否付費1-是 0-否 --->
<input type="hidden" name="isPayEvip" class="isPayEvip" value="0">
<input type="hidden" class="vip-limit-read" value="0">
<input type="hidden" id="headerType" value="data">
<input type="hidden" id="details_right_hero" value="true">
<input type="hidden" id="currentUserID" value="" />
<div id="a5mgapgs4i" class="gather-bottom"></div>
<link rel="stylesheet" href="/static/footer/footer.css?20230919" />
<div id="a5mgapgs4i" class="public-footer">
<div id="a5mgapgs4i" class="public-footer__hd">
<dl>
<dt>華秋(原“華強聚豐”):</dt>
<dd>電子發燒友</dd>
<dd>華秋開發</dd>
<dd>華秋電路(原"華強PCB")</dd>
<dd>華秋商城(原"華強芯城")</dd>
<dd>華秋智造</dd>
</dl>
<dl>
<dd><a target="_blank" rel="nofollow">My ElecFans </a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/app/"> APP </a></li>
<dd><a target="_blank" href="http://www.xsypw.cn/about/sitemap.html">網站地圖</a></dd>
</dl>
</div>
<div id="a5mgapgs4i" class="public-footer__main">
<dl>
<dt>設計技術</dt>
<dd><a href="http://www.xsypw.cn/pld/" target="_blank">可編程邏輯</a></dd>
<dd><a href="http://www.xsypw.cn/article/83/" target="_blank">電源/新能源</a></dd>
<dd><a href="http://www.xsypw.cn/article/88/142/" target="_blank">MEMS/傳感技術</a></dd>
<dd><a href="http://www.xsypw.cn/article/85/" target="_blank">測量儀表</a></dd>
<dd><a href="http://www.xsypw.cn/emb/" target="_blank">嵌入式技術</a></dd>
<dd><a href="http://www.xsypw.cn/article/90/155/" target="_blank">制造/封裝</a></dd>
<dd><a href="http://www.xsypw.cn/analog/" target="_blank">模擬技術</a></dd>
<dd><a href="http://www.xsypw.cn/tongxin/rf/" target="_blank">RF/無線</a></dd>
<dd><a href="http://www.xsypw.cn/emb/jiekou/" target="_blank">接口/總線/驅動</a></dd>
<dd><a href="http://www.xsypw.cn/emb/dsp/" target="_blank">處理器/DSP</a></dd>
<dd><a href="http://www.xsypw.cn/bandaoti/eda/" target="_blank">EDA/IC設計</a></dd>
<dd><a href="http://www.xsypw.cn/consume/cunchujishu/" target="_blank">存儲技術</a></dd>
<dd><a href="http://www.xsypw.cn/xianshi/" target="_blank">光電顯示</a></dd>
<dd><a href="http://www.xsypw.cn/emc_emi/" target="_blank">EMC/EMI設計</a></dd>
<dd><a href="http://www.xsypw.cn/connector/" target="_blank">連接器</a></dd>
</dl>
<dl>
<dt>行業應用</dt>
<dd><a href="http://www.xsypw.cn/led/" target="_blank">LEDs </a></dd>
<dd><a href="http://www.xsypw.cn/qichedianzi/" target="_blank">汽車電子</a></dd>
<dd><a href="http://www.xsypw.cn/video/" target="_blank">音視頻及家電</a></dd>
<dd><a href="http://www.xsypw.cn/tongxin/" target="_blank">通信網絡</a></dd>
<dd><a href="http://www.xsypw.cn/yiliaodianzi/" target="_blank">醫療電子</a></dd>
<dd><a href="http://www.xsypw.cn/rengongzhineng/" target="_blank">人工智能</a></dd>
<dd><a href="http://www.xsypw.cn/vr/" target="_blank">虛擬現實</a></dd>
<dd><a href="http://www.xsypw.cn/wearable/" target="_blank">可穿戴設備</a></dd>
<dd><a href="http://www.xsypw.cn/jiqiren/" target="_blank">機器人</a></dd>
<dd><a href="http://www.xsypw.cn/application/Security/" target="_blank">安全設備/系統</a></dd>
<dd><a href="http://www.xsypw.cn/application/Military_avionics/" target="_blank">軍用/航空電子</a></dd>
<dd><a href="http://www.xsypw.cn/application/Communication/" target="_blank">移動通信</a></dd>
<dd><a href="http://www.xsypw.cn/kongzhijishu/" target="_blank">工業控制</a></dd>
<dd><a href="http://www.xsypw.cn/consume/bianxiedianzishebei/" target="_blank">便攜設備</a></dd>
<dd><a href="http://www.xsypw.cn/consume/chukongjishu/" target="_blank">觸控感測</a></dd>
<dd><a href="http://www.xsypw.cn/iot/" target="_blank">物聯網</a></dd>
<dd><a href="http://www.xsypw.cn/dianyuan/diandongche_xinnenyuan/" target="_blank">智能電網</a></dd>
<dd><a href="http://www.xsypw.cn/blockchain/" target="_blank">區塊鏈</a></dd>
<dd><a href="http://www.xsypw.cn/xinkeji/" target="_blank">新科技</a></dd>
</dl>
<dl>
<dt>特色內容</dt>
<dd><a href="http://www.xsypw.cn/d/column/" target="_blank">專欄推薦</a></dd>
<dd><a target="_blank" >學院</a></dd>
<dd><a target="_blank" >設計資源</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/technical/">設計技術</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/baike/">電子百科</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/dianzishipin/">電子視頻</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/yuanqijian/">元器件知識</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/tools/">工具箱</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/vip/#choose">VIP會員</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/article/special/">最新技術文章</a></dd>
</dl>
<dl>
<dt>社區</dt>
<dd><a target="_blank" >小組</a></dd>
<dd><a target="_blank" >論壇</a></dd>
<dd><a target="_blank" >問答</a></dd>
<dd><a target="_blank" >評測試用</a></dd>
<dt><a target="_blank" >企業服務</a></dt>
<dd><a target="_blank" >產品</a></dd>
<dd><a target="_blank" >資料</a></dd>
<dd><a target="_blank" >文章</a></dd>
<dd><a target="_blank" >方案</a></dd>
<dd><a target="_blank" >企業</a></dd>
</dl>
<dl>
<dt>供應鏈服務</dt>
<dd><a target="_blank" href="http://www.xsypw.cn/kf/">硬件開發</a></dd>
<dd><a target="_blank" >華秋電路</a></dd>
<dd><a target="_blank" >華秋商城</a></dd>
<dd><a target="_blank" >華秋智造</a></dd>
<dd><a target="_blank" >nextPCB</a></dd>
<dd><a target="_blank" >BOM配單</a></dd>
<dt>媒體服務</dt>
<dd><a target="_blank" href="http://www.xsypw.cn/about/service.html">網站廣告</a></dd>
<dd><a target="_blank" >在線研討會</a></dd>
<dd><a target="_blank" >活動策劃</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/news/">新聞發布</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/xinpian/ic/">新品發布</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/quiz/">小測驗</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/contest/">設計大賽</a></dd>
</dl>
<dl>
<dt>華秋</dt>
<dd><a target="_blank" href="http://www.xsypw.cn/about/" rel="nofollow">關于我們</a></dd>
<dd><a target="_blank" rel="nofollow">投資關系</a></dd>
<dd><a target="_blank" rel="nofollow">新聞動態</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/about/zhaopin.html" rel="nofollow">加入我們</a></dd>
<dd><a target="_blank" href="http://www.xsypw.cn/about/contact.html" rel="nofollow">聯系我們</a></dd>
<dd><a target="_blank" href="/about/tousu.html" rel="nofollow">舉報投訴</a></dd>
<dt>社交網絡</dt>
<dd><a target="_blank" rel="nofollow">微博</a></dd>
<dt>移動端</dt>
<dd><a target="_blank" href="http://www.xsypw.cn/app/">發燒友APP</a></dd>
<dd><a target="_blank" >硬聲APP</a></dd>
<dd><a target="_blank" >WAP</a></dd>
</dl>
<dl>
<dt>聯系我們</dt>
<dd class="small_tit">廣告合作</dd>
<dd>王婉珠:<a href="mailto:wangwanzhu@elecfans.com">wangwanzhu@elecfans.com</a></dd>
<dd class="small_tit">內容合作</dd>
<dd>黃晶晶:<a href="mailto:huangjingjing@elecfans.com">huangjingjing@elecfans.com</a></dd>
<dd class="small_tit">內容合作(海外)</dd>
<dd>張迎輝:<a href="mailto:mikezhang@elecfans.com">mikezhang@elecfans.com</a></dd>
<dd class="small_tit">供應鏈服務 PCB/IC/PCBA</dd>
<dd>江良華:<a href="mailto:lanhu@huaqiu.com">lanhu@huaqiu.com</a></dd>
<dd class="small_tit">投資合作</dd>
<dd>曾海銀:<a href="mailto:zenghaiyin@huaqiu.com">zenghaiyin@huaqiu.com</a></dd>
<dd class="small_tit">社區合作</dd>
<dd>劉勇:<a href="mailto:liuyong@huaqiu.com">liuyong@huaqiu.com</a></dd>
</dl>
<ul class="qr-code">
<li>
<p>關注我們的微信</p>
<img src="/static/main/img/elecfans_code.jpg" alt="關注我們的微信" />
</li>
<li>
<p>下載發燒友APP</p>
<img src="/static/main/img/elec_app_code.jpg" alt="下載發燒友APP" />
</li>
<li>
<p>電子發燒友觀察</p>
<img src="/static/main/img/elec_focus_code.jpg" alt="電子發燒友觀察" />
</li>
</ul>
</div>
<div id="a5mgapgs4i" class="public-footer__ft">
<div id="a5mgapgs4i" class="public-footer__ft-inner">
<a target="_blank" class="public-footer__ft-logo">
<img class="is-default" src="/static/footer/image/footer-01-default.png" alt="華秋電子" />
<img class="is-hover" src="/static/footer/image/footer-01.png" alt="華秋電子" />
</a>
<div id="a5mgapgs4i" class="public-footer__ft-right">
<div id="a5mgapgs4i" class="public-footer__ft-item public-footer__ft-elecfans">
<div id="a5mgapgs4i" class="hd">
<a href="http://www.xsypw.cn/" target="_blank">
<!-- <img class="is-default" src="/static/footer/image/footer-02-default.png" alt="華秋發燒友">
<img class="is-hover" src="/static/footer/image/footer-02.png" alt="華秋發燒友"> -->
<div id="a5mgapgs4i" class="site_foot_img">
<img src="/static/footer/image/elecfans-logo.svg" alt="華秋發燒友">
</div>
<div id="a5mgapgs4i" class="site_foot_text">電子工程師社區</div>
</a>
</div>
</div>
<div id="a5mgapgs4i" class="public-footer__ft-item public-footer__ft-hqpcb">
<div id="a5mgapgs4i" class="hd">
<a target="_blank">
<div id="a5mgapgs4i" class="site_foot_img">
<img src="/static/footer/image/hqpcb-logo.svg" alt="華秋電路">
</div>
<div id="a5mgapgs4i" class="site_foot_text">1-32層PCB打樣·中小批量</div>
</a>
</div>
</div>
<div id="a5mgapgs4i" class="public-footer__ft-item public-footer__ft-hqchip">
<div id="a5mgapgs4i" class="hd">
<a target="_blank">
<div id="a5mgapgs4i" class="site_foot_img">
<img src="/static/footer/image/hqchip-logo.svg" alt="華秋商城">
</div>
<div id="a5mgapgs4i" class="site_foot_text">元器件現貨·全球代購·SmartBOM</div>
</a>
</div>
</div>
<div id="a5mgapgs4i" class="public-footer__ft-item public-footer__ft-smt">
<div id="a5mgapgs4i" class="hd">
<a target="_blank">
<div id="a5mgapgs4i" class="site_foot_img">
<img src="/static/footer/image/smt-logo.svg" alt="華秋智造">
</div>
<div id="a5mgapgs4i" class="site_foot_text">SMT貼片·PCBA加工</div>
</a>
</div>
</div>
<div id="a5mgapgs4i" class="public-footer__ft-item public-footer__ft-nextpcb">
<div id="a5mgapgs4i" class="hd">
<a href="javascript:void(0)" class="next-pck-link">
<div id="a5mgapgs4i" class="site_foot_img">
<img src="/static/footer/image/nextpcb-logo.svg" alt="NextPCB">
</div>
<div id="a5mgapgs4i" class="site_foot_text">PCB Manufacturer</div>
</a>
</div>
</div>
<ul class="public-footer__ft-text">
<li><a target="_blank">華秋簡介</a></li>
<li><a target="_blank">企業動態</a></li>
<li><a target="_blank">聯系我們</a></li>
<li><a target="_blank">企業文化</a></li>
<li><a target="_blank">企業宣傳片</a></li>
<li><a target="_blank">加入我們</a></li>
</ul>
</div>
</div>
</div>
<div id="a5mgapgs4i" class="public-footer__copyright">
<p>版權所有 ? 湖南華秋數字科技有限公司 </p>
<p>長沙市望城經濟技術開發區航空路6號手機智能終端產業園2號廠房3層(0731-88081133)</p>
<a href="http://www.xsypw.cn/">電子發燒友</a>
<a href="http://www.xsypw.cn/" target="_blank"><strong>(電路圖)</strong></a>
<a target="_blank" rel="nofollow">湘公網安備43011202000918</a>
<!-- <a href="http://www.xsypw.cn/about/edi.html" target="_blank">電信與信息服務業務經營許可證:合字B2-20210191</a> -->
<a target="_blank" rel="nofollow">
<img src="http://skin.elecfans.com/images/ebsIcon.png" alt="工商網監認證">工商網監
</a>
<a target="_blank" rel="nofollow">湘ICP備2023018690號-1</a>
</div>
<div><input type="hidden" value="0" name="arc_relate_vid"></div>
</div>
<link rel="stylesheet" href="/webapi/public/project/idt/iconfont/iconfont.css">
<script src="https://skin.elecfans.com/js/elecfans_jquery.js"></script>
<script src="https://staticd.elecfans.com/js/plugins.js"></script>
<script>
(function () {
postmessageScript()
function postmessageScript() {
/*
* postmessage
*/
var con_net = ""
if (window.location.href.indexOf(".net") > -1) {
con_net = "net"
} else {
con_net = "com"
}
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = 'https://passport.elecfans.' + con_net + '/public/pc/plugin/postmessage.js';
var body = document.getElementsByTagName("body").item(0);
body.appendChild(script);
}
/*
* 推薦文章無圖時樣式修改
* */
$(".article .thumb").each(function () {
if ($(this).find('img').attr('src') == "") {
$(this).find('img').remove();
$(this).parent().css('padding-left', '0px');
}
});
/*百度分享*/
window._bd_share_config = {
common: {
bdText: '', //自定義分享內容
bdDesc: '', //自定義分享摘要
bdPic: ''
},
share: [{
"bdSize": 60
}]
}
with(document) 0[(getElementsByTagName('head')[0] || body).appendChild(createElement('script')).src = ''];
})();
var add_url = '/d/article/write/';
var check_allow = "/d/api/iscantalk.html";
var click_items_length = $('.art_click_count').length;
if (click_items_length > 0) {
var id_str = '';
$('.art_click_count').each(function () {
id_str += $(this).attr('data-id') + ',';
})
var url = "/d/api/getclickbyids.html";
var id_data = 'id_str=' + id_str;
$.ajax({
url: url,
data: id_data,
type: 'post',
dataType: 'json',
success: function (re) {
if (re.list.length >= 1) {
var list = re.list;
for (var i in list) {
var temp_id = list[i]['id'];
var temp_span = $(".art_click_count[data-id=" + temp_id + "]")
temp_span.html(list[i]['click']);
}
}
}
})
}
function CheckLogin() {
//alert(11)
now_uid = '';
var ElecfansApi_checklogin = '/webapi/passport/checklogin';
var logout_url = "/d/login/logout.html";
var logout_url = 'https://bbs.elecfans.com/member.php?mod=logging&action=logout&refer=front';
$.get(ElecfansApi_checklogin, function (data, textStatus) {
if (data != "") {
EchoLoginInfo(data);
CheckEmailInfo(data);
data = $.parseJSON(data);
now_uid = data.uid;
/*var login_content = '<a href="/d/article/write/" class="btn write-article"><i class="icon-new-message"></i> 寫文章</a><div id="a5mgapgs4i" class="mine" id="mine"><a class="item user" href="/d/user/'+now_uid+'/"><img src="'+data.avatar+'" width="33" height="33" /> <strong>'+data.username+'</strong></a><div class="a5mgapgs4i" id="mymenu" class="my-menu"><a class="logout" href="'+logout_url+'" ><i class="icon-switch"></i> 退出</a></div></div>';*/
var login_content =
'<a href="javascript:;" class="btn write-article" id="write_btn"><i class="icon-new-message"></i> 寫文章</a><div id="a5mgapgs4i" class="mine" id="mine"><a class="item user" href="/d/user/' +
now_uid + '/"><img src="' + data.avatar + '" width="33" height="33" /> <strong>' + data
.username +
'</strong></a><div class="a5mgapgs4i" id="mymenu" class="my-menu"><a class="setting" target="_blank" ><i class="icon-cog"></i> 設置</a><a class="logout" href="' +
logout_url + '" ><i class="icon-switch"></i> 退出</a></div></div>';
$('#login_area').html(login_content);
var win_width = $(window).width();
if (win_width > 1000) {
$("#mine").mouseDelay(200).hover(function () {
$("#mymenu").show();
}, function () {
$("#mymenu").hide();
});
};
$('.newheader2021_tip_msg .tip_msg_num').text(data.msgnum).css({
'display': 'inline'
});
$('.no_login_2021').hide();
$('.yes_login_2021_more').css({
'display': 'flex'
});
$('.yes_login_2021').attr('href', 'https://bbs.elecfans.com/user/' + data.uid);
$('.yes_login_2021 .vtm').attr('src', data.avatar);
var yesLoginMoreBox = $('.yes_login_2021_more_box');
yesLoginMoreBox.find('.header_logo_2021').attr('href', 'https://bbs.elecfans.com/user/' + data
.uid);
yesLoginMoreBox.find('.header_logo_2021 img').attr('src', data.avatar);
yesLoginMoreBox.find('.header_logo_right_2021').attr('href', 'https://bbs.elecfans.com/user/' +
data.uid);
yesLoginMoreBox.find('.usename_href_2021').attr('href', 'https://bbs.elecfans.com/user/' + data
.uid).text(data.username);
$(".header_bottom_2021 .favorite_articles_2021").attr("href", "https://bbs.elecfans.com/user/" +
data.uid + "/favorite_articles?from=daohang");
$(".header_bottom_2021 .spacecp_2021").attr("href",
"https://bbs.elecfans.com/home.php?mod=space&uid=" + data.uid +
"&do=profile&from=daohang");
if (data.vip == 1) {
yesLoginMoreBox.find('.header_VIP_2021').hide();
yesLoginMoreBox.find('.vip_icon img').attr('src',
'https://skin.elecfans.com/images/2021-soft/vip_icon2.png');
};
} else {
remainLog();
var content =
'<a class="item special-login " href="javascript:;" title="">登錄</a><a class="item" target="_blank">注冊</a>';
$('#login_area').html(content);
//.send-write,.absolute-write
$(".special-login").click(function (e) {
$.tActivityLogin();
return false;
});
$('.no_login_2021').click(function () {
$.ssoDialogLogin();
})
}
});
}
function getCookie(name) {
var arr, reg = new RegExp("(^| )" + name + "=([^;]*)(;|$)");
if (arr = document.cookie.match(reg))
return unescape(arr[2]);
else
return null;
}
//添加提示注冊引導
function remainLog() {
if ($("#remainLogBox").length > 0) {
return false;
}
var getRemainShow = getCookie('REMAINSHOWLOG');
/*設置注冊框的主題內容*/
var content = '<div class="a5mgapgs4i" id="remainLogBox">' +
'<div id="a5mgapgs4i" class="sso_layer"></div>' +
'<div id="a5mgapgs4i" class="remain-log clearfix">' +
'<div id="a5mgapgs4i" class="fl LogBgPart">' +
'<h3>電子發燒友</h3> ' +
'<p>中國電子工程師最喜歡的網站</p> ' +
'<ul>' +
'<li>與<span id="downNum">2931785</span>位工程師會員交流學習</li>' +
'<li>獲取您個性化的科技前沿技術信息</li> ' +
'<li>參加活動獲取豐厚的禮品</li> ' +
'</ul>' +
'</div>' +
'<div id="a5mgapgs4i" class="fr LogRightPart">' +
'<div class="a5mgapgs4i" id="colseRemainLog"><img src="https://skin.elecfans.com/images/remain_log_colse.png"></div>' +
'<div class="a5mgapgs4i" id="ssoScrollLog"></div>' +
'</div>' +
'</div>' +
'</div>';
$("body").append(content);
$("#colseRemainLog").click(function () {
var Days = 1;
var exp = new Date();
exp.setTime(exp.getTime() + Days * 24 * 60 * 60 * 1000);
/*存儲cookie 用于點擊關閉后一天不顯示*/
document.cookie = 'REMAINSHOWLOG' + "=" + '1' + ";path= " + "/" + ";expires=" + exp.toGMTString();
$("#remainLogBox").remove();
$("html").css('overflow-y', 'auto');
});
setTimeout(function () {
var netHost = window.location.host.split(".");
$.ajax({
url: 'https://www.elecfans.' + netHost[2] + '/webapi/passport/totalaccount',
dataType: 'json',
success: function (data) {
if (data.status == "successed") {
$("#downNum").html(data.data.num);
}
}
})
}, 1000);
var getPathHref = location.pathname;
/*判斷是否是首頁*/
if (getPathHref.length > 1 && getPathHref != "/index.html" && ($(".side-box.author-article").length > 0 || $(
".article .article-content").length > 0)) {
var getLoadPageNum = getCookie('LoadPageNum');
if (getLoadPageNum) {
var LoadPageUrl = getCookie('LoadPageUrl');
if (LoadPageUrl != location.pathname) {
$(window).scroll(function () {
/*滾動一屏頁面后顯示*/
if ($(window).scrollTop() > ($(window).height() / 2)) {
if (getRemainShow != 1) {
if ($("#remainLogBox").length > 0) {
$("#remainLogBox").show();
$("html").css('overflow-y', 'hidden');
}
}
}
})
}
} else {
var Days = 1;
var exp = new Date();
exp.setTime(exp.getTime() + Days * 24 * 60 * 60 * 1000);
/*存儲cookie 用于點擊關閉后一天不顯示*/
document.cookie = 'LoadPageNum' + "=" + '1' + ";path= " + "/" + ";expires=" + exp.toGMTString();
var LoadPageUrl = getCookie('LoadPageUrl');
if (!LoadPageUrl) {
document.cookie = 'LoadPageUrl' + "=" + location.pathname + ";path= " + "/" + ";expires=" + exp
.toGMTString();
}
}
}
}
$(function () {
var follow_wrap = $(".author-collect");
var now_uid = "";
var face_src = "";
var getFollowNum = $(".followNum strong").html();
//關注
$(window).on('click', '.author-collect', function () {
if (now_uid == '') {
$.tActivityLogin();
return false;
}
if($(".store_flag").val() == 15){ //企業號文章
if($(".evip_id").length == 0){return false}
if ($(this).attr('id') == 'follow') {
$.post('/webapi/home/evipArticle/followEvip', {
evip_id : $(".evip_id").val(),
action:'follow'
}, function (data) {
//返回的數據格式:
if (data.code == "0") {
follow_wrap.html('已關注').attr('id', 'cancelFollow').addClass(
'is-active');
}else{
alert(data.msg);
}
});
}else{
$.post('/webapi/home/evipArticle/followEvip',{
evip_id : $(".evip_id").val(),
action:'cancel' }, function (data) {
//返回的數據格式:
if (data.code == "0") {
follow_wrap.html('關注').attr('id', 'follow').removeClass(
"is-active");
}else{
alert(data.msg);
}
});
}
}else{
if ($(this).attr('id') == 'follow') {
$.post('/d/user/follow', {
tuid: article_user_id
}, function (data) {
//返回的數據格式:
if (data.status == "successed") {
$(".followNum strong").html(++getFollowNum);
// follow_wrap.html('已關注').attr('id','cancelFollow').css('background','#999');
follow_wrap.html('已關注').attr('id', 'cancelFollow').addClass(
'is-active');
var follow_user = '<a href="/d/user/' + now_uid + '/" data-uid="' +
now_uid + '" class="face" rel="nofollow"><img src="' + face_src +
'"></a>';
$('#follow_list').append(follow_user);
}
if (data.status == "failed") {
alert(data.msg);
}
});
}else{
$.post('/d/user/cancelFollow',{tuid: article_user_id }, function (data) {
//返回的數據格式:
if (data.status == "successed") {
// follow_wrap.html('關注').attr('id', 'follow').css('background', '#f90');
follow_wrap.html('關注').attr('id', 'follow').removeClass(
"is-active");
$(".followNum strong").html(--getFollowNum);
$('#follow_list .face').each(function () {
var target_uid = $(this).attr('data-uid');
if (target_uid == now_uid) {
$(this).remove();
}
})
}
if (data.status == "failed") {
alert(data.msg);
}
});
}
}
});
});
// 綁定手機號
$(".send-write").click(function () {
$.ajax({
url: '/webapi/passport/checklogin',
type: "get",
dataType: 'json',
success: function (login) {
if (login == null) {
$.ssoDialogLogin();
} else {
isVerification(function () {
window.open("/d/article/write/")
})
}
}
})
});
/*
* ********: 驗證手機號
* callback: 驗證成功的回調函數
*/
// isVerification(function(){
// //完成手機號驗證 后判斷是否完善資料
// isPerfectInfo($,document,function(){},false,true)
// })
function isVerification_d(callback, article_write) {
var passport = null;
var bbs_host = null;
if (location.host.indexOf(".com") > 0) {
passport = window.location.protocol + "http://passport.elecfans.com";
www_host = window.location.protocol + "http://www.xsypw.cn";
} else {
passport = window.location.protocol + "http://passport.elecfans.net";
www_host = window.location.protocol + "http://www.elecfans.net";
}
$.ajax({
url: www_host + '/webapi/passport/checklogin',
type: "get",
dataType: 'json',
success: function (login) {
if (login) {
$.ajax({
url: www_host + '/webapi/Mcenter/sms/getvalidstatus',
type: "post",
dataType: 'json',
success: function (res) {
var phoneTxt =
"<p style='text-indent: 20px;margin-bottom: 10px;'>您好!為確保您賬戶的安全及正常使用,依《網絡安全法》相關要求,4月22日起賬戶需綁定手機,如您還未綁定,請盡快完成,感謝您的理解及支持!</p>"
var setHtml = function () {
var _iframe = null;
if (article_write === "article_write") {
_iframe =
'<div id="a5mgapgs4i" class="pop_verification_mask"><div id="a5mgapgs4i" class="pop_verification phone_verification">' +
'<h6>請驗證手機<i class="close_icon_d close_verification">╳</i></h6>' +
'<div id="a5mgapgs4i" class="desc_txt">尊敬的用戶:<br>' + phoneTxt +
'</div>' +
'<iframe class="phone_iframe" width="520" height="580" src="' +
passport +
'/Security/validatePhone/siteid/14.html"></iframe>' +
'</div></div>'
$('body').append(_iframe).ready(function () {
$(".close_verification:eq(0)").click(
function (e) {
e.stopPropagation();
$.ajax({
url: www_host +
'/webapi/Mcenter/sms/getvalidstatus',
type: "post",
dataType: 'json',
success: function (
res) {
if (res.data
.phonestatus ==
0) {
layer
.msg(
"請先驗證手機號"
)
} else {
$(".pop_verification_mask")
.remove()
}
}
})
})
})
} else {
_iframe =
'<div id="a5mgapgs4i" class="pop_verification_mask"><div id="a5mgapgs4i" class="pop_verification phone_verification">' +
'<h6>請驗證手機<i class="close_icon_d close_verification">╳</i></h6>' +
'<div id="a5mgapgs4i" class="desc_txt">尊敬的用戶:<br>' + phoneTxt +
'</div>' +
'<iframe class="phone_iframe" id="verificationIframe" width="488" height="580" src="' +
passport +
'/Security/validatePhone/siteid/14.html"></iframe>' +
'</div></div>'
$('body').append(_iframe).ready(function () {
$(".close_verification:eq(0)").click(
function (e) {
e.stopPropagation();
$(".pop_verification").remove()
if ($(".pop_verification_mask")
.length >= 1) {
$(".pop_verification_mask")
.remove()
}
});
})
}
}
//已經驗證手機號
if (res.data.phonestatus == 1) {
if (typeof callback === "function") {
callback()
}
} else {
setHtml(); //沒有完成驗證先彈出手機驗證
// 接受數據
// $.receiveMessage(function(msg){
// // 接收到純數字時設置iframe的高度
// if($.isNumeric(msg.data)){
// }else if(typeof(msg.data)=="string"){
// }
// }, passport);
}
}
})
} else {
//調用登錄
$.ssoDialogLogin(); //單點登錄
return false; //彈出登錄
}
}
})
}
$('body').css({
'background-color': '#fff'
});
$('.newheader2021').css({
'border-bottom': 'solid 1px #e5e5e5'
});
</script>
<script src="https://staticd.elecfans.com/js/common.js?20230818"></script>
<script src="https://staticd.elecfans.com/plugins/layer/layer.js"></script>
<script src="https://skin.elecfans.com/js/elecfans/road_ad.js?20230818" defer></script>
<script src="https://skin.elecfans.com/js/elecfans/organizing/js/organizing.js?20230710"></script>
<script src="https://skin.elecfans.com/js/elecfans/interview.js?20230724"></script>
<script type="text/javascript" src="https://staticd.elecfans.com/plugins/layer/layer.js"></script>
<script type="text/javascript" src="/static/vendor/clipboard.min.js"></script>
<script type="text/javascript" src="https://staticd.elecfans.com/js/share-web.js?20220223"></script>
<script>
var myface = "https://bbs.elecfans.com/uc_server/data/avatar/000/00/00/00_avatar_small.jpg";
var myname = "";
var article_title = '如何用Python編程下載和解析英文版維基百科';
var article_id = 808775;
var article_user_id = 2788889;//文章作者ID
var article_user_name = 'MqC7_CAAI_1981';
var rightHeightChange = false;
//專欄用戶數據獲取
var zlMp = $('input[name="zl_mp"]').val();
//是專欄用戶
if (zlMp) {
$.ajax({
url:"/d/Column/getUserCount",
type:'get',
data:{uid:article_user_id},
success:function(res){
if(res.code === 0){
//修改數量
$('.column-article-count').text(res.data.article);
$('.column-view-count').text(res.data.view);
$('.column-follow-count').text(res.data.follow_count);
$('.column-praise-count').text(res.data.all_click);
} else {
console.log(res);
}
}
})
}
if(article_id) {
dIsOriginal()
}
//原創標識接口
function dIsOriginal() {
$.ajax({
url:"/webapi/arcinfo/isOriginal",
type:'get',
data:{aid:article_id},
success:function(re){
var res=JSON.parse(re)
if(res.status==="successed"){
//1原創標識
if(res.data.is_original==1){
$(".yuanchuan_images").show()
}else{
$(".yuanchuan_images").remove()
}
}else{
$(".yuanchuan_images").remove()
}
}
});
}
$('#delete_art').click(function(){
var art_id = $(this).attr('data-id');
var url = '/d/article/delete';
var data = "id="+art_id;
layer.confirm('確定要刪除?', {
btn: ['取消','確定'] //按鈕
}, function(){
layer.msg('已經取消', {icon: 1});
}, function(){
$.ajax({
url:url,
type:'post',
data:data,
success:function(re){
if(re.error_code==200){
var uid = re.uid;
var lurl = '/d/user/'+uid+'/';
layer.msg('已經刪除', {icon: 1});
window.location.href = lurl;
}else{
layer.msg(re.msg,{icon:1});
}
}
})
});
});
</script>
<script src="https://staticd.elecfans.com/js/xgPlayer.js"></script>
<script src="https://staticd.elecfans.com/js/article.js?v=20240328"></script>
<script src="https://staticd.elecfans.com/js/column_article.js?v=c202307271023"></script>
<script>
$(document).ready(()=>{
/**推薦文章 */
$.ajax({
url: "/d/article/getArcList",
type: "get",
data: { type: "recommend", page: 1, size: 5 },
success: function (res) {
if (res.code == 0) {
renderArticle(res.data);
rightHeightChange = true
} else {
$(".dzs-article-recom").hide();
}
},
});
/**推薦企業號 */
if($(".store_flag").val() == 15){
$.ajax({
url: "/webapi/home/evip/getRecommendFollow",
type: "get",
success: function (res) {
if(res.code == 0 && Array.isArray(res.data)){
var qyStr = ''
for(var r = 0;r<res.data.length;r++){
var qyItem =res.data[r];
var jumpUrl = window.location.origin + '/d/c' + qyItem.apply_uid;
var itemIcon = '';
var tagsArr = (qyItem.belong_to_industry || []).split(",")
tagsArr = tagsArr.splice(0,3)
var is_follow = qyItem.is_follow == 1?'focus':'unFocus'
if(qyItem.ver_id == 1 || qyItem.ver_id == 2){
itemIcon= '/static/main/img/qyh/pro_vip_sm.png'
}else if(qyItem.ver_id == 3){
itemIcon= '/static/main/img/qyh/enjoy_vip_sm.png'
} else {
itemIcon= '/static/main/img/qyh/common_vip_sm.png'
}
qyStr +='<li><a href="'+jumpUrl+'" target="_blank" class="block" >';
qyStr += '<div id="a5mgapgs4i" class="enterInfo">'
qyStr += '<div id="a5mgapgs4i" class="enterImg">'
qyStr += '<img src="'+qyItem.enterprise_head_url+'" class="companyImg objectFit"/>'
qyStr += '</div>'
qyStr += '<div id="a5mgapgs4i" class="enterDes">'
qyStr += '<div id="a5mgapgs4i" class="name">'
qyStr +='<img src="'+itemIcon+'" alt="">'
qyStr +='<h5>'+qyItem.enterprise_name +'</h5>'
qyStr +='</div>'
qyStr +='<div id="a5mgapgs4i" class="companyName">'+qyItem.company_name +'</div>'
qyStr += '<div id="a5mgapgs4i" class="tags">'
for(var t = 0;t<tagsArr.length;t++){
qyStr += '<span>'+tagsArr[t]+'</span>'
}
qyStr += '</div>'
qyStr += '</div>'
qyStr += '</div>'
qyStr += '<div id="a5mgapgs4i" class="industry">'
qyStr += '<div id="a5mgapgs4i" class="view">'
qyStr += '<span>'+qyItem.archives_count+'內容</span>'
qyStr += '<span>'+ qyItem.view_count +'瀏覽量</span>'
qyStr += '<span>'+qyItem.follow_count +'粉絲</span>'
qyStr += '</div>'
if(qyItem.is_follow == 1){
qyStr += '<span id="a5mgapgs4i" class="qyhFocus focus" data-qyId="'+qyItem.id +'"></span>'
}else{
qyStr += '<span id="a5mgapgs4i" class="qyhFocus unFocus" data-qyId="'+qyItem.id +'">+關注</span>'
}
qyStr += '</div>'
qyStr += '</a>'
qyStr += '</li>'
}
$(".enterWrap-qyh").append(qyStr)
}
}
})
//企業號關注和取消關注
$(".enterWrap-qyh").on("click",".qyhFocus",function(){
if($(".is-login").length>0 && $(".is-login").attr("data-uid")){
var hasFocus = $(this).hasClass("focus");
var qyId = $(this).attr("data-qyId")
var that = $(this)
$.post('/webapi/home/evipArticle/followEvip', {
evip_id : qyId,
action:hasFocus?'cancel':'follow'
}, function (data) {
//返回的數據格式:
if (data.code == "0") {
if(hasFocus){
that.removeClass("focus").addClass("unFocus").text("+關注")
}else{
that.removeClass("unFocus").addClass("focus").text("")
}
}else{
alert(data.msg);
}
});
}else{
$.ssoDialogLogin();
}
return false
})
}else{
/**推薦專欄 */
$.ajax({
url: "/d/article/getZlList",
type: "get",
data: { type: "recommend", page: 1, size: 5 },
success: function (res) {
if (res.code == 0) {
renderColumn(res.data,"");
rightHeightChange = true
} else {
$(".dzs-article-column").hide();
}
},
});
}
})
</script>
<script src="https://staticd.elecfans.com/js/artilePartjs.js?20230906"></script>
<footer>
<div class="friendship-link">
<p>感谢您访问我们的网站,您可能还对以下资源感兴趣:</p>
<a href="http://www.xsypw.cn/" title="在线观看www成人影院|在线观看www日本免费网站|在线观看www视频|在线观看操|欧美18在线|欧美1级">在线观看www成人影院|在线观看www日本免费网站|在线观看www视频|在线观看操|欧美18在线|欧美1级</a>
<div class="friend-links">
</div>
</div>
</footer>
主站蜘蛛池模板:
<a href="http://www.800376.cn" target="_blank">国产精品久久久久网站</a>|
<a href="http://www.ldoc.com.cn" target="_blank">久久思re热9一区二区三区</a>|
<a href="http://www.hzbyq.cn" target="_blank">久久伊人网站</a>|
<a href="http://www.v13856.cn" target="_blank">午夜丁香婷婷</a>|
<a href="http://www.wapcai.cn" target="_blank">五月天婷婷一区二区三区久久</a>|
<a href="http://www.carwiki.com.cn" target="_blank">欧美成人eee在线</a>|
<a href="http://www.elonline.cn" target="_blank">奇米7777第四色</a>|
<a href="http://www.lezdwc.com.cn" target="_blank">欧美在线视频看看</a>|
<a href="http://www.shaitujx.cn" target="_blank">国产精品理论</a>|
<a href="http://www.s21941.cn" target="_blank">欧美三级午夜伦理片</a>|
<a href="http://www.lzjpk.cn" target="_blank">久热国产在线</a>|
<a href="http://www.ueua.com.cn" target="_blank">婷婷爱五月天</a>|
<a href="http://www.dgfx.com.cn" target="_blank">久久99久久精品97久久综合</a>|
<a href="http://www.lnsfemh.cn" target="_blank">久久综合九色欧美综合狠狠</a>|
<a href="http://www.5016385.cn" target="_blank">好吊操免费视频</a>|
<a href="http://www.29518.com.cn" target="_blank">免费的日本网站</a>|
<a href="http://www.leqa.com.cn" target="_blank">三级视频网站在线观看</a>|
<a href="http://www.yangkin.cn" target="_blank">亚洲成a人片在线观看中</a>|
<a href="http://www.qkhk.com.cn" target="_blank">久久精品国产免费观看99</a>|
<a href="http://www.pyyb.com.cn" target="_blank">在线天堂中文字幕</a>|
<a href="http://www.ferd.net.cn" target="_blank">天堂中文在线观看</a>|
<a href="http://www.888336.cn" target="_blank">亚洲bbbbbxxxxx精品三十七</a>|
<a href="http://www.yanzyue.cn" target="_blank">四虎影院久久</a>|
<a href="http://www.jumingxuan.com.cn" target="_blank">午夜影院一级片</a>|
<a href="http://www.qi0766.cn" target="_blank">一区二区三区国模大胆</a>|
<a href="http://www.lsmy168.cn" target="_blank">被公侵犯肉体中文字幕一区二区</a>|
<a href="http://www.dg0573.cn" target="_blank">中文字幕不卡一区</a>|
<a href="http://www.haizhinuocw.cn" target="_blank">男人操女人在线观看</a>|
<a href="http://www.xoz.net.cn" target="_blank">在线视频91</a>|
<a href="http://www.cnjinmin.com.cn" target="_blank">中文字幕一区二区三区四区五区人
</a>|
<a href="http://www.z1utv4s.cn" target="_blank">国产黄色在线视频</a>|
<a href="http://www.xf-nissan.com.cn" target="_blank">美欧毛片</a>|
<a href="http://www.dpmgcv.cn" target="_blank">99精品久久99久久久久久</a>|
<a href="http://www.sg234.com.cn" target="_blank">亚洲成人免费在线</a>|
<a href="http://www.101698.cn" target="_blank">免费视频爰爱太爽了</a>|
<a href="http://www.vrfp.com.cn" target="_blank">9色网站</a>|
<a href="http://www.1bgi6.cn" target="_blank">国产伦精一区二区三区</a>|
<a href="http://www.chenaici.cn" target="_blank">热99精品视频</a>|
<a href="http://www.wjjinhai.cn" target="_blank">www.狠狠干</a>|
<a href="http://www.zhio.com.cn" target="_blank">日本在线www</a>|
<a href="http://www.truebest.cn" target="_blank">六月丁香婷婷激情</a>|
<script>
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https') {
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
</body><div id="j9ft3" class="pl_css_ganrao" style="display: none;"><ins id="j9ft3"><optgroup id="j9ft3"></optgroup></ins><thead id="j9ft3"><video id="j9ft3"></video></thead><ol id="j9ft3"><ins id="j9ft3"><legend id="j9ft3"><thead id="j9ft3"></thead></legend></ins></ol><pre id="j9ft3"></pre><tt id="j9ft3"><label id="j9ft3"></label></tt><video id="j9ft3"><sup id="j9ft3"></sup></video><strong id="j9ft3"><legend id="j9ft3"></legend></strong><listing id="j9ft3"><pre id="j9ft3"><rp id="j9ft3"><label id="j9ft3"></label></rp></pre></listing><em id="j9ft3"></em><small id="j9ft3"><style id="j9ft3"><progress id="j9ft3"><optgroup id="j9ft3"></optgroup></progress></style></small><legend id="j9ft3"><thead id="j9ft3"><video id="j9ft3"><legend id="j9ft3"></legend></video></thead></legend><track id="j9ft3"><style id="j9ft3"><address id="j9ft3"><u id="j9ft3"></u></address></style></track><u id="j9ft3"><dl id="j9ft3"></dl></u><th id="j9ft3"><big id="j9ft3"></big></th><menuitem id="j9ft3"><strong id="j9ft3"></strong></menuitem><tt id="j9ft3"><nobr id="j9ft3"><address id="j9ft3"><ruby id="j9ft3"></ruby></address></nobr></tt><ruby id="j9ft3"><dl id="j9ft3"></dl></ruby><p id="j9ft3"><tt id="j9ft3"></tt></p><output id="j9ft3"></output><strong id="j9ft3"><legend id="j9ft3"><ruby id="j9ft3"><video id="j9ft3"></video></ruby></legend></strong><thead id="j9ft3"></thead><dfn id="j9ft3"><thead id="j9ft3"><video id="j9ft3"><pre id="j9ft3"></pre></video></thead></dfn><pre id="j9ft3"><b id="j9ft3"><pre id="j9ft3"><sub id="j9ft3"></sub></pre></b></pre><mark id="j9ft3"></mark><legend id="j9ft3"></legend><font id="j9ft3"><var id="j9ft3"><thead id="j9ft3"><track id="j9ft3"></track></thead></var></font><var id="j9ft3"><i id="j9ft3"><output id="j9ft3"><var id="j9ft3"></var></output></i></var><em id="j9ft3"><i id="j9ft3"></i></em><pre id="j9ft3"><b id="j9ft3"><pre id="j9ft3"><pre id="j9ft3"></pre></pre></b></pre><listing id="j9ft3"><p id="j9ft3"><mark id="j9ft3"><label id="j9ft3"></label></mark></p></listing><dfn id="j9ft3"></dfn><form id="j9ft3"><thead id="j9ft3"></thead></form><div id="j9ft3"><rp id="j9ft3"></rp></div><rp id="j9ft3"><acronym id="j9ft3"></acronym></rp><listing id="j9ft3"><sub id="j9ft3"></sub></listing><address id="j9ft3"><u id="j9ft3"></u></address><output id="j9ft3"><var id="j9ft3"></var></output><style id="j9ft3"><address id="j9ft3"></address></style><u id="j9ft3"><strike id="j9ft3"></strike></u><u id="j9ft3"></u><pre id="j9ft3"></pre><meter id="j9ft3"><th id="j9ft3"></th></meter><strike id="j9ft3"><ins id="j9ft3"></ins></strike><meter id="j9ft3"><var id="j9ft3"></var></meter><sub id="j9ft3"><rp id="j9ft3"></rp></sub><big id="j9ft3"></big><dfn id="j9ft3"></dfn><thead id="j9ft3"></thead><mark id="j9ft3"><strong id="j9ft3"></strong></mark><track id="j9ft3"><style id="j9ft3"></style></track><meter id="j9ft3"></meter><sup id="j9ft3"></sup><u id="j9ft3"><dl id="j9ft3"><em id="j9ft3"><i id="j9ft3"></i></em></dl></u><strike id="j9ft3"></strike><b id="j9ft3"><p id="j9ft3"><sub id="j9ft3"><listing id="j9ft3"></listing></sub></p></b><i id="j9ft3"><meter id="j9ft3"><th id="j9ft3"><thead id="j9ft3"></thead></th></meter></i><output id="j9ft3"><i id="j9ft3"></i></output><progress id="j9ft3"><optgroup id="j9ft3"></optgroup></progress><sub id="j9ft3"><form id="j9ft3"></form></sub><thead id="j9ft3"><progress id="j9ft3"></progress></thead><div id="j9ft3"><nobr id="j9ft3"><legend id="j9ft3"><menuitem id="j9ft3"></menuitem></legend></nobr></div><mark id="j9ft3"><strong id="j9ft3"></strong></mark><form id="j9ft3"><label id="j9ft3"></label></form><strong id="j9ft3"></strong><label id="j9ft3"></label><strike id="j9ft3"></strike><sub id="j9ft3"><pre id="j9ft3"><acronym id="j9ft3"><u id="j9ft3"></u></acronym></pre></sub><span id="j9ft3"><ins id="j9ft3"><dfn id="j9ft3"><thead id="j9ft3"></thead></dfn></ins></span><meter id="j9ft3"><th id="j9ft3"></th></meter><pre id="j9ft3"><form id="j9ft3"><label id="j9ft3"><sub id="j9ft3"></sub></label></form></pre><small id="j9ft3"><strike id="j9ft3"></strike></small><video id="j9ft3"></video><em id="j9ft3"><th id="j9ft3"><big id="j9ft3"><em id="j9ft3"></em></big></th></em><strike id="j9ft3"><ins id="j9ft3"></ins></strike><style id="j9ft3"></style><sup id="j9ft3"><thead id="j9ft3"><video id="j9ft3"><p id="j9ft3"></p></video></thead></sup><legend id="j9ft3"><menuitem id="j9ft3"><u id="j9ft3"><dl id="j9ft3"></dl></u></menuitem></legend><thead id="j9ft3"></thead><dfn id="j9ft3"></dfn><listing id="j9ft3"><div id="j9ft3"></div></listing><dfn id="j9ft3"><big id="j9ft3"></big></dfn><track id="j9ft3"><ol id="j9ft3"><font id="j9ft3"><dfn id="j9ft3"></dfn></font></ol></track><i id="j9ft3"><output id="j9ft3"></output></i><form id="j9ft3"></form><ol id="j9ft3"><ins id="j9ft3"></ins></ol><label id="j9ft3"><form id="j9ft3"></form></label><track id="j9ft3"><style id="j9ft3"></style></track><em id="j9ft3"><label id="j9ft3"><form id="j9ft3"><dfn id="j9ft3"></dfn></form></label></em><sup id="j9ft3"></sup><ruby id="j9ft3"><optgroup id="j9ft3"><sup id="j9ft3"><b id="j9ft3"></b></sup></optgroup></ruby><thead id="j9ft3"></thead><u id="j9ft3"><legend id="j9ft3"><address id="j9ft3"><label id="j9ft3"></label></address></legend></u><output id="j9ft3"><var id="j9ft3"></var></output><dfn id="j9ft3"><big id="j9ft3"></big></dfn><strong id="j9ft3"></strong><pre id="j9ft3"></pre><big id="j9ft3"><video id="j9ft3"></video></big><strong id="j9ft3"><thead id="j9ft3"><font id="j9ft3"><style id="j9ft3"></style></font></thead></strong><progress id="j9ft3"><optgroup id="j9ft3"></optgroup></progress><strike id="j9ft3"><video id="j9ft3"><sup id="j9ft3"><mark id="j9ft3"></mark></sup></video></strike><big id="j9ft3"><video id="j9ft3"></video></big><tt id="j9ft3"><pre id="j9ft3"></pre></tt><label id="j9ft3"><form id="j9ft3"><dfn id="j9ft3"><i id="j9ft3"></i></dfn></form></label><nobr id="j9ft3"><acronym id="j9ft3"></acronym></nobr><span id="j9ft3"><small id="j9ft3"></small></span><var id="j9ft3"><form id="j9ft3"></form></var><strong id="j9ft3"><ol id="j9ft3"></ol></strong><font id="j9ft3"></font><pre id="j9ft3"><b id="j9ft3"><label id="j9ft3"><sub id="j9ft3"></sub></label></b></pre><menuitem id="j9ft3"></menuitem><form id="j9ft3"><p id="j9ft3"><tt id="j9ft3"><pre id="j9ft3"></pre></tt></p></form><ol id="j9ft3"><acronym id="j9ft3"><tt id="j9ft3"><strike id="j9ft3"></strike></tt></acronym></ol><mark id="j9ft3"><listing id="j9ft3"><div id="j9ft3"><tt id="j9ft3"></tt></div></listing></mark><var id="j9ft3"></var><optgroup id="j9ft3"><strike id="j9ft3"><thead id="j9ft3"><pre id="j9ft3"></pre></thead></strike></optgroup><var id="j9ft3"><thead id="j9ft3"><font id="j9ft3"><strong id="j9ft3"></strong></font></thead></var><dfn id="j9ft3"></dfn><u id="j9ft3"><strong id="j9ft3"><legend id="j9ft3"><u id="j9ft3"></u></legend></strong></u><dfn id="j9ft3"><var id="j9ft3"><form id="j9ft3"><dfn id="j9ft3"></dfn></form></var></dfn><sup id="j9ft3"></sup><i id="j9ft3"><meter id="j9ft3"></meter></i><em id="j9ft3"><var id="j9ft3"><mark id="j9ft3"><dfn id="j9ft3"></dfn></mark></var></em><mark id="j9ft3"><strong id="j9ft3"><ol id="j9ft3"><font id="j9ft3"></font></ol></strong></mark><ol id="j9ft3"></ol><video id="j9ft3"></video><font id="j9ft3"><track id="j9ft3"><ol id="j9ft3"><small id="j9ft3"></small></ol></track></font><form id="j9ft3"><p id="j9ft3"></p></form><pre id="j9ft3"></pre><pre id="j9ft3"></pre><legend id="j9ft3"><tt id="j9ft3"><nobr id="j9ft3"><legend id="j9ft3"></legend></nobr></tt></legend><thead id="j9ft3"></thead><video id="j9ft3"></video><label id="j9ft3"><dl id="j9ft3"><output id="j9ft3"><i id="j9ft3"></i></output></dl></label><pre id="j9ft3"><big id="j9ft3"><dfn id="j9ft3"><var id="j9ft3"></var></dfn></big></pre><legend id="j9ft3"></legend><th id="j9ft3"><i id="j9ft3"><font id="j9ft3"><strong id="j9ft3"></strong></font></i></th><sup id="j9ft3"><big id="j9ft3"><video id="j9ft3"><p id="j9ft3"></p></video></big></sup><mark id="j9ft3"></mark><mark id="j9ft3"><listing id="j9ft3"><pre id="j9ft3"><rp id="j9ft3"></rp></pre></listing></mark><b id="j9ft3"><label id="j9ft3"></label></b><sub id="j9ft3"><pre id="j9ft3"></pre></sub><dl id="j9ft3"><output id="j9ft3"></output></dl><strong id="j9ft3"></strong><legend id="j9ft3"></legend><ins id="j9ft3"><pre id="j9ft3"></pre></ins><track id="j9ft3"><thead id="j9ft3"><progress id="j9ft3"><dfn id="j9ft3"></dfn></progress></thead></track><menuitem id="j9ft3"><u id="j9ft3"><dl id="j9ft3"><em id="j9ft3"></em></dl></u></menuitem><label id="j9ft3"></label><div id="j9ft3"><rp id="j9ft3"></rp></div><u id="j9ft3"><dl id="j9ft3"><em id="j9ft3"><i id="j9ft3"></i></em></dl></u></div>
</html>  如何用Python編程下載和解析英文版維基百科
如何用Python編程下載和解析英文版維基百科