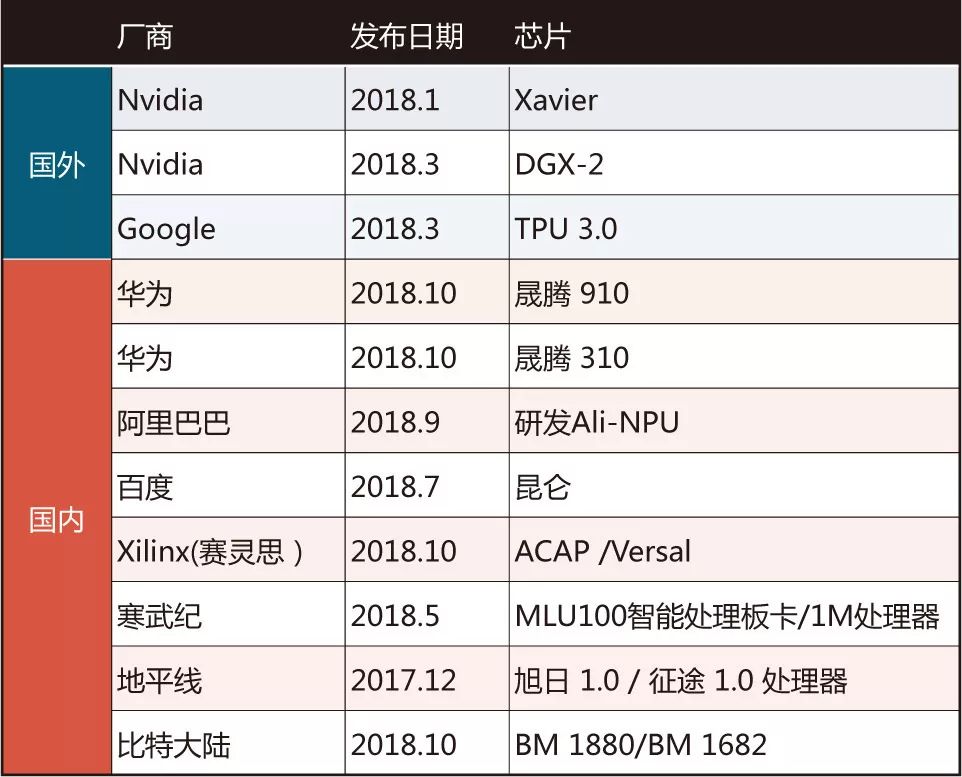
 探討影響AI芯片未來發展趨勢的主要因素
探討影響AI芯片未來發展趨勢的主要因素
人工智能應用的蓬勃發展對算力提出了非常迫切的要求。由于摩爾定律已經失效, 定制計算將成為主流方向,因而新型的 AI 芯片開始層出不窮,競爭也日趨白熱。參與這一競爭的不光是傳統的半導體芯片廠商,大型的互聯網和終端設備企業依托于自身龐大的應用規模,直接從自身業務需求出發,參與到 AI 芯片的開發行列。這其中以英偉達為代表的 GPU 方案已經形成規模龐大的生態體系,谷歌的 TPU 則形成了互聯網定義 AI 芯片的標桿,其余各家依托各自需求和優勢,提出了多類解決方案。本文將簡要梳理目前各家技術進展狀態,結合人工智能應用的發展趨勢,對影響 AI 芯片未來發展趨勢的主要因素做出一個粗淺探討。
AI 計算芯片現狀
目前 AI 芯片領域主要的供應商仍然是英偉達,英偉達保持了極大的投入力度,快速提高 GPU 的核心性能,增加新型功能,保持了在 AI 訓練市場的霸主地位,并積極拓展嵌入式產品形態,推出 Xavier 系列。互聯網領域,谷歌推出 TPU3.0,峰值性能達到 100pflops,保持了專用加速處理器的領先地位。同時華為、百度、阿里、騰訊依托其龐大應用生態,開始正式入場,相繼發布其產品和路線圖。此外,FPGA 技術,因其低延遲、計算架構靈活可定制,正在受到越來越多的關注,微軟持續推進在其數據中心部署 FPGA,Xilinx 和 Intel 倆家不約而同把 FPGA 未來市場中心放到數據中心市場。Xilinx 更是推出了劃時代的 ACAP,第一次將其產品定位到超越 FPGA 的范疇。相較云端高性能 AI 芯片,面向物聯網的 AI 專用芯片門檻要低很多,因此也吸引了眾多小體量公司參與。
▌NVIDIA:Xavier
2018 年 1 月,英偉達發布了首個自動駕駛處理器——Xavier。這款芯片具有非常復雜的結構,內置六種處理器,超過 90 億個晶體管,可以處理海量數據。Xavier 的 GMSL(千兆多媒體串行鏈路)高速 IO 將其與迄今為止最大陣列的激光雷達、雷達和攝像頭傳感器連接起來。
圖:Xavier 的內部結構
▌NVIDIA:DGX-2
2018 年 3 月,NVIDIA 發布首款 2-petaFLOPS 系統——DGX-2。它整合了 16 個完全互聯的 GPU,使深度學習性能提升 10 倍。有了 DGX-2 ,模型的復雜性和規模不再受傳統架構限制的約束。與傳統的 x85 架構相比,DGX-2 訓練 ResNet-50 的性能相當于 300 臺配備雙英特爾至強 Gold CPU 服務器的性能,后者的成本超過 270 美元。
圖:DGX-2 的內部結構
▌Google:TPU
自 2016 年首次發布 TPU 以來,Google 持續推進,2017 年發布 TPU 2.0,2018 年 3 月 Google I/O 大會推出 TPU 3.0。其每個 pod 的機架數量是TPU 2.0的兩倍;每個機架的云 TPU 數量是原來的兩倍。據官方數據,TPU 3.0 的性能可能是 TPU2.0 的八倍,高達 100 petaflops。
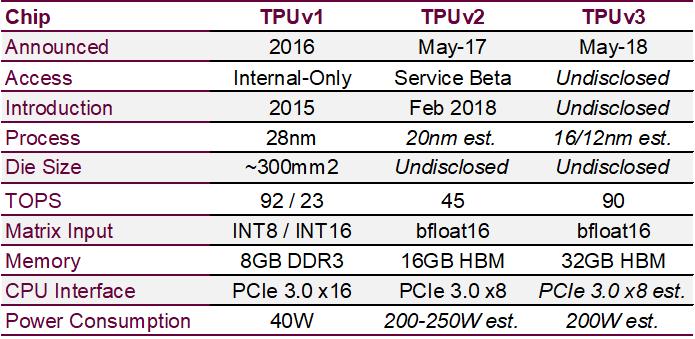
圖:TPU 1 & 2 & 3 參數對比圖
▌華為:晟騰 910 & 晟騰 310
2018 年 10月,華為正式發布兩款 AI 芯片:昇騰 910 和昇騰 310。預計下一年第二季度正式上市。華為昇騰 910 采用 7nm 工藝,達芬奇架構,半精度(FP16)可達 256TeraFLOPS,整數精度(INT8)可達 512TeraOPS,自帶 128 通道全高清視頻解碼器 H.264/265,最大功耗350W。華為昇騰 310 采用 12nmFFC 工藝,達芬奇架構,半精度(FP16)可達8TeraFLOPS,整數精度(INT8)可達 16 TeraOPS,自帶 16 通道全高清視頻解碼器H.264/265,最大功耗 8W。
圖:華為晟騰性能數據圖
▌寒武紀:MLU100
2018 年 5 月,寒武紀推出第一款智能處理板卡——MLU100。搭載了寒武紀 MLU100 芯片,為云端推理提供強大的運算能力支撐。等效理論計算能力高達 128 TOPS,支持 4 通道 64 bit ECCDDR4 內存,并支持多種容量。1M 是第三代機器學習專用芯片,使用 TSMC 7nm 工藝生產,其 8 位運算效能比達 5Tops/watt(每瓦 5 萬億次運算)。寒武紀 1M 處理器延續了前兩代 IP 產品(1H/1A)的完備性,可支持 CNN、RNN、SOM 等多種深度學習模型,此次又進一步支持了 SVM、K-NN、K-Means、決策樹等經典機器學習算法的加速。這款芯片支持幫助終端設備進行本地訓練,可為視覺、語音、自然語言處理等任務提供高效計算平臺。
圖:MLU 100 參數數據表
▌地平線:旭日 1.0 & 征程 1.0
2017 年 12 月,地平線自主設計研發了中國首款嵌入式人工智能視覺芯片——旭日 1.0 和征程 1.0。旭日 1.0 是面向智能攝像頭的處理器,具備在前端實現大規模人臉檢測跟蹤、視頻結構化的處理能力,可廣泛用于智能城市、智能商業等場景。征程 1.0是面向自動駕駛的處理器,可同時對行人、機動車、非機動車、車道線交通標識等多類目標進行精準的實時監測和識別,實現 FCW/LDW/JACC 等高級別輔助駕駛功能。
▌比特大陸:BM1880 & BM1682
2018 年 10 月,比特大陸正式發布邊緣計算人工智能芯片 BM1880,可提供 1 TOPS@INT8 算力。推出面向深度學習領域的第二代張量計算處理器 BM 1682,峰值性能達 3 TFLOPS FP32。
BM1682 VS BM1680 性能對比
BM1682 的算豐智能服務器SA3、嵌入式 AI 迷你機 SE3、3D 人臉識別智能終端以及基于 BM1880 的開發板、AI 模塊、算力棒等產品。BM1682 芯片量產發布,峰值算力達到 3TFlops,功耗為 30W。
▌百度:昆侖芯片
2018 年 7 月,百度AI開發者大會上李彥宏正式宣布研發 AI 芯片——昆侖。這款 AI 芯片適合對 AI、深度學習有需求的廠商、機構等。借助著昆侖 AI 芯片強勁的運算性能,未來有望應用到無人駕駛、圖像識別等場景中去。
▌阿里:研發 Ali-NPU、成立平頭哥半導體芯片公司
2018 年 4 月,阿里巴巴達摩院宣布正在研發的一款神經網絡芯片——Ali-NPU。其主要用途是圖像視頻分析、機器學習等 AI 推理計算。9 月,在云棲大會上,阿里巴巴正式宣布合并中天微達摩院團隊,成立平頭哥半導體芯片公司。
▌Xilinx:ACAP、收購深鑒科技
2018 年 3 月,賽靈思宣布推出一款超越 FPGA 功能的新產品——ACAP(自適應計算加速平臺)。其核心是新一代的 FPGA 架構。10月,發布最新基于 7nm 工藝的 ACAP 平臺的第一款處理器——Versal。其使用多種計算加速技術,可以為任何應用程序提供強大的異構加速。Versal Prime 系列和 Versal AI Core 系列產品也將于 2019 年推出。
2018 年 7 月,賽靈思宣布收購深鑒科技。
賽靈思ACAP框圖
AI 芯片發展面臨的矛盾、問題、挑戰
目前AI芯片發展面臨4大矛盾:圍繞這些矛盾,需要解決大量相關問題和挑戰。
▌大型云服務商與AI芯片提供商的矛盾
技術路線上,面向通用市場的英偉達持續推進 GPU 技術發展,但是大型云服務商也不愿陷入被動,結合自身規模龐大的應用需求,比較容易定義一款適合的 AI 芯片,相應的應用打磨也比較好解決。同時,新的芯片平臺都會帶來生態系統的分裂。但是對于普通用戶,競爭會帶來價格上的好處。由于 AI 算力需求飛速提升,短期內 AI 芯片市場還會進一步多樣化。
▌中美矛盾
中國依托于龐大市場規模,以及 AI 應用技術的大力投資,非常有機會在 AI 相關領域取得突破。但是受到《瓦森那協議》以及近期中美貿易戰等因素影響,中美在集成電路產業層面展開了激烈的競爭。AI 芯片有機會為中國帶來破局的機會,因此后期可以預期,國內會有更多的資金投入到 AI 芯片領域。
▌專用與通用間的矛盾
云端市場由于各大巨頭高度壟斷,會形成多個相對封閉的 AI 芯片方案。而邊緣端市場由于高度分散,局部市場難以形成完整的技術生態體系,生態建設會圍繞主流核心技術拓展,包括ARM、Risc-V、NVDLA 等。各大掌握核心技術的廠商,也會迎合這一趨勢,盡可能占領更大的生態份額,積極開放技術給中小企業開發各類 AI 芯片。
▌AI 芯片創新與設計工具及生態之間的矛盾
以 FPGA 為例,學界和業界仍然沒有開創性的方法簡化 FPGA 的開發,這是現階段制約 FPGA 廣泛使用的最大障礙。和 CPU 或 GPU 成熟的編程模型和豐富的工具鏈相比,高性能的 FPGA 設計仍然大部分依靠硬件工程師編寫 RTL 模型實現。RTL 語言的抽象度很低,往往是對硬件電路進行直接描述,這樣,一方面需要工程師擁有很高的硬件專業知識,另一方面在開發復雜的算法時會有更久的迭代周期。因此,FPGA 標榜的可編程能力與其復雜的編程模型之間,形成了鮮明的矛盾。近五到十年來,高層次綜合(High Level Synthesis - HLS)一直是 FPGA 學術界研究的熱點,其重點就是希望設計更加高層次的編程模型和工具,利用現有的編程語言比如 C、C++ 等,對 FPGA 進行設計開發。
在工業界,兩大 FPGA 公司都選擇支持基于 OpenCL 的 FPGA 高層次開發,并分別發布了自己的 API 和 SDK 等開發工具。這在一定程度上降低了 FPGA 的開發難度,使得 C 語言程序員可以嘗試在 FPGA 平臺上進行算法開發,特別是針對人工智能的相關應用。盡管如此,程序員仍然需要懂得基本的 FPGA 體系結構和設計約束,這樣才能寫出更加高效的 OpenCL/HLS 模型。因此,盡管有不少嘗試 OpenCL/HLS 進行產品開發的公司,但是目前國內實際能夠掌握這類設計方法的公司還是非常稀缺。各家專用 AI 芯片廠商,都需要建立自己相對獨立的應用開發工具鏈,這個投入通常比開發芯片本身還要龐大,成熟周期也慢很多。Xilinx 對深鑒的收購有效補充了其在 AI 應用開發方面的工具短板。近期 Intel 開源了 OpenVINO,也是在推動其 AI 及 FPGA 生態。也有少數在 FPGA 領域有長期積累的團隊,例如深維科技在為市場提供定制 FPGA 加速方案,可以對應用生態產生有效促進作用。
面對不同的需求,AI計算力最終將會駛向何方?
主要云服務商以及終端提供商都會圍繞自家優勢產品平臺發展 AI 芯片,云端 AI 芯片投入巨大,主流技術快速進化,國內企業需要重視 AI 芯片的隱性投入:設計開發工具、可重用資源和生態伙伴。不過近期不大可能迅速形成整合的局面,競爭會進一步加劇。在端上,基于 DSA/RISC-V 的 AI 芯片更多出現在邊緣端 AI+IoT,百花齊放。
三大類技術路線各有優劣,長期并存。
GPU 具有成熟的生態,在 AI 領域具有顯著的先發優勢,目前保持高速增長態勢。
以 Google TPU 為代表的專用 AI 芯片在峰值性能上較 GPU 有一定優勢。確定性是 TPU 另一個優勢。CPU 和 GPU 需要考慮各種任務上的性能優化,因此會有越來越復雜的機制,帶來的副作用就是這些處理器的行為非常難以預測。而使用 TPU 能輕易預測運行一個神經網絡并得出模型與推測結果需要多長時間,這樣就能讓芯片以吞吐量接近峰值的狀態運行,同時嚴格控制延遲。不過,TPU 的性能優勢使得它的靈活性較弱,這也是 ASIC 芯片的常見屬性。充分針對性優化的架構也可以得到最佳的能效比。但是開發一款高性能專用芯片的投入是非常高昂的,通常周期也需要至少 15 個月。
FPGA 以及新一代 ACAP 芯片,則具備了高度的靈活性,可以根據需求定義計算架構,開發周期遠遠小于設計一款專用芯片。但是由于可編程資源必不可少的冗余,FPGA 的能效比以及價格通常比專用芯片要差很多。但是 ACAP 的出現,引入了 AI 核的優點,勢必會進一步拉近與專用芯片的差距。隨著 FPGA 應用生態的逐步成熟,FPGA 的優勢也會逐漸為更多用戶所了解。
總而言之,AI 芯片的“戰國時代”大幕已經拉開,各路“諸侯”爭相割據一方,謀求霸業,大家難以獨善其身,合縱連橫、百家爭鳴將成為常態。這也必定會是一個英雄輩出的時代。
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238513 -
AI芯片
+關注
關注
17文章
1887瀏覽量
35027
發布評論請先 登錄
相關推薦
富士通預測2025年AI領域的發展趨勢
未來物流發展趨勢與TMS的關系
邊緣計算的未來發展趨勢
未來AI大模型的發展趨勢
變阻器的未來發展趨勢和前景如何?是否有替代品出現?
影響服務器托管費用的主要因素
影響焊接質量的主要因素有哪些?
中國網絡交換芯片市場發展趨勢
影響放大電路高頻特性的主要因素是什么
什么是熱電偶穩定性?影響熱電偶穩定性的主要因素

影響晶振振蕩頻率的主要因素有哪些

配網故障定位裝置:未來發展趨勢與挑戰






 工商網監
工商網監
評論