") 如何用單獨的GPU,在CIFAR-10圖像分類數(shù)據(jù)集上高效地訓(xùn)練殘差網(wǎng)絡(luò)
如何用單獨的GPU,在CIFAR-10圖像分類數(shù)據(jù)集上高效地訓(xùn)練殘差網(wǎng)絡(luò)
在這一系列文章中,我們主要研究如何用單獨的GPU,在CIFAR-10圖像分類數(shù)據(jù)集上高效地訓(xùn)練殘差網(wǎng)絡(luò)(Residual networks)。
為了記錄這一過程,我們計算了網(wǎng)絡(luò)從零開始訓(xùn)練到94%的精確度所需的時間。這一基準來自最近的DAWNBench競賽。在競賽結(jié)束后,單個GPU上的最好成績是341秒,八個GPU上最好成績是174秒。
Baseline
在這部分中,我們復(fù)制了一個基線,在6分鐘內(nèi)訓(xùn)練CIFAR10,之后稍稍加速。我們發(fā)現(xiàn),在GPU的FLOPs計算完之前,仍有很大的提升空間。
過去幾個月,我一直在研究如何能更快度訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)。這個想法是從今年年初萌生的,當時我正和Myrtle的Sam Davis進行一個項目。我們將用于自動語音識別的大型循環(huán)神經(jīng)網(wǎng)絡(luò)壓縮后,部署到FPGAs上,重新訓(xùn)練模型。來自Mozilla的基線在16個GPU上訓(xùn)練了一個星期。后來,經(jīng)過Sam的努力,我們在英偉達的Volta GPUs上進行混淆精度訓(xùn)練,得以將訓(xùn)練時間縮短了100倍,迭代時間在單個GPU上只需要不到一天的時間。
這一結(jié)果讓我思考還有什么可以實現(xiàn)加速?幾乎與此同時,斯坦福大學(xué)的研究人員們開啟了DAWNBench挑戰(zhàn)賽,比較多個深度學(xué)習(xí)基線上的訓(xùn)練速度。最受人關(guān)注的就是訓(xùn)練圖像分類模型在CIFAR10上達到94%的測試精確度,在ImageNet上達到93%、top5的成績。圖像分類是深度學(xué)習(xí)研究的熱門領(lǐng)域,但是訓(xùn)練速度仍需要數(shù)小時。
到了四月份,挑戰(zhàn)賽接近尾聲,CIFAR10上最快的單個GPU訓(xùn)練速度來自fast.ai的一名學(xué)生Ben Johnson,他在不到6分鐘(341秒)的時間里訓(xùn)練出了94%的精確度。這一創(chuàng)新主要是混淆精度的訓(xùn)練,他選擇了一個較小的網(wǎng)絡(luò),有足夠的能力處理任務(wù)并且可以用更高的學(xué)習(xí)速率加速隨機梯度下降。
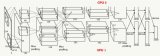
這時我們不禁提出一個問題:這種341秒訓(xùn)練出來的94%測試精度,在CIFAR10上的表現(xiàn)怎么樣?該網(wǎng)絡(luò)的架構(gòu)是一個18層的殘差網(wǎng)絡(luò),如下所示。在這個案例中,圖層的數(shù)量表示卷積(紫色)和完全連接層(藍色)的序列深度:
網(wǎng)絡(luò)通過隨機梯度下降訓(xùn)練了35個epoch,學(xué)習(xí)速率圖如下:
現(xiàn)在我們假設(shè)在一個英偉達Volta V100 GPU上用100%的計算力,訓(xùn)練將需要多長時間。網(wǎng)絡(luò)在一張32×32×3的CIFAR10圖像上進行前向和后向傳遞時需要大約2.8×109FLOPs。假設(shè)參數(shù)更新不耗費計算力,那么在50000張圖像訓(xùn)練35個epoch應(yīng)該會在5×1015FLOPs以內(nèi)完成。
Tesla V100有640個Tensor Cores,能支持125 TeraFLOPS的深度學(xué)習(xí)性能。
假設(shè)我們能發(fā)揮100%的計算力,那么訓(xùn)練會在40秒內(nèi)完成,這么看來341秒的成績還有很大的提升空間。
有了40秒這個目標,我們就開始了自己的訓(xùn)練。首先是用上方的殘差網(wǎng)絡(luò)重新復(fù)現(xiàn)基線CIFAR10的結(jié)果。我用PyTorch創(chuàng)建了一個網(wǎng)絡(luò),重新復(fù)制了學(xué)習(xí)速率和超參數(shù)。在AWS p3.2的圖像上用單個V100 GPU訓(xùn)練,3/5的運行結(jié)果在356秒內(nèi)達到了94%的精確度。
基線建好后,下一步是尋找可以立即使用的簡單改進方法。首先我們觀察到:網(wǎng)絡(luò)開頭是由黃色和紅色的兩個連續(xù)norm-ReLU組成的,在紫色卷積之后,我們刪去重復(fù)部分,同樣在epoch 15也發(fā)生了這樣的情況。進行調(diào)整后,網(wǎng)絡(luò)架構(gòu)變得更簡單,4/5的運行結(jié)果在323秒內(nèi)達到了94%的精確度!刷新了記錄!
另外我們還觀察到,圖像處理過程中的一些步驟(填充、標準化、位移等等)每經(jīng)過訓(xùn)練集一次就要重新處理一遍,會浪費很多時間。雖然提前預(yù)處理可以用多個CPU處理器減輕這一結(jié)果,但是PyTorch的數(shù)據(jù)下載器會從每次數(shù)據(jù)迭代中開始新一次的處理。這一配置時間是很短的,尤其在CIFAR10這樣的小數(shù)據(jù)集上。只要在訓(xùn)練前做了準備,減少預(yù)處理壓力,就能減少處理次數(shù)。遇到更復(fù)雜的任務(wù),需要更多預(yù)處理步驟或多個GPU時,就會在每個epoch之間保持數(shù)據(jù)下載器的處理。溢出了重復(fù)工作、減少了數(shù)據(jù)下載器后,訓(xùn)練時間達到了308秒。
繼續(xù)研究后我們發(fā)現(xiàn),大部分預(yù)處理時間都花在了召集隨機數(shù)字生成器,選擇數(shù)據(jù)增強而不是為它們本身增強。在完全訓(xùn)練時期,我們對隨機數(shù)字生成器執(zhí)行了幾百萬個單獨命令,把它們結(jié)合在一個較小的命令中,每個epoch可以省去7秒訓(xùn)練時間。最終的訓(xùn)練時間縮短到了297秒。這一過程的代碼可以點擊:github.com/davidcpage/cifar10-fast/blob/master/experiments.ipynb
-
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129130 -
圖像分類
+關(guān)注
關(guān)注
0文章
90瀏覽量
11943 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5510瀏覽量
121334
原文標題:如何訓(xùn)練你的ResNet(一):復(fù)現(xiàn)baseline,將訓(xùn)練時間從6分鐘縮短至297秒
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
計算機視覺/深度學(xué)習(xí)領(lǐng)域常用數(shù)據(jù)集匯總
線性分類器
使用CIFAR-10彩色圖片訓(xùn)練出現(xiàn)報錯信息及解決
當AI遇上FPGA會產(chǎn)生怎樣的反應(yīng)
【ELT.ZIP】OpenHarmony啃論文俱樂部—gpu上高效無損壓縮浮點數(shù)
如何進行高效的時序圖神經(jīng)網(wǎng)絡(luò)的訓(xùn)練
用AlexNet對cifar-10數(shù)據(jù)進行分類
信息保留的二值神經(jīng)網(wǎng)絡(luò)IR-Net,落地性能和實用性俱佳
改進多尺度三維殘差卷積神經(jīng)網(wǎng)絡(luò)的高光譜圖像方法

改進多尺度三維殘差卷積神經(jīng)網(wǎng)絡(luò)的高光譜圖像方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論